目录
算法概述
图示
伪代码
选主元
子集划分
小规模数据的处理
算法实现
算法概述
图示
快速排序和归并排序有一些相似,都是用到了分而治之的思想:
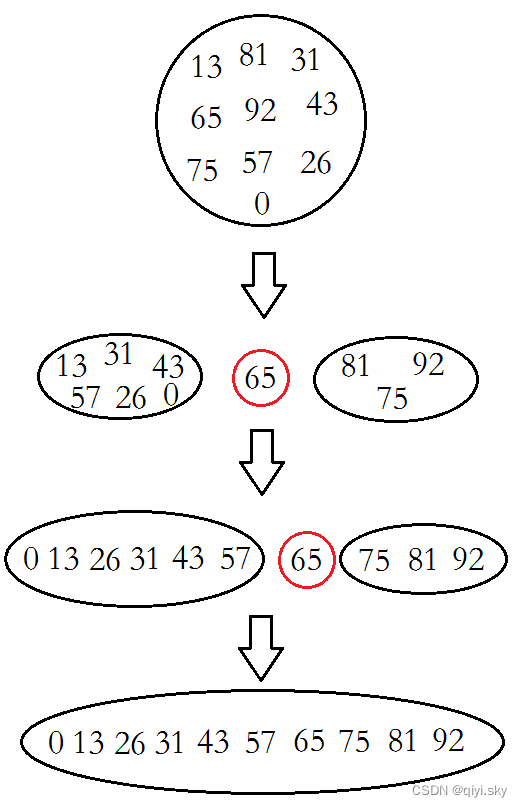
伪代码
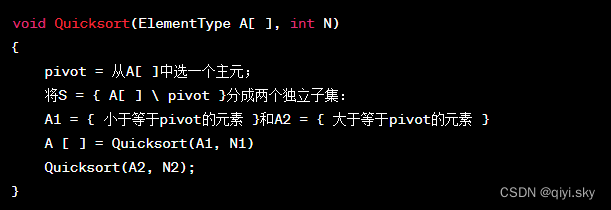
通过初步的认识,我们能够知道快速排序算法最好的情况应该是:
每次都正好中分,即每次选主元都为元素的中位数的位置。
最好情况的时间复杂度为
选主元
假设我们把第一个元素设为主元,看以下的一种特殊情况:
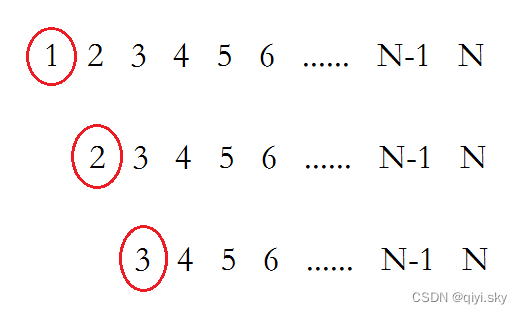
选了第一个元素为主元之后,扫描所有元素所用时间复杂度为O(N),然后还有N-1个元素要进行递归,时间复杂度记为T(N-1),所以最终它的时间复杂度为:
既然这种方法不行,那如果我们随机取pivot呢?
很显然,rand()函数的时间效率是很低的,当然也不考虑。
所以我们就想,
取头、中、尾的中位数,例如取三个数的中位数:8、12、3的中位数就是8;或者五个数选取中位数等等。
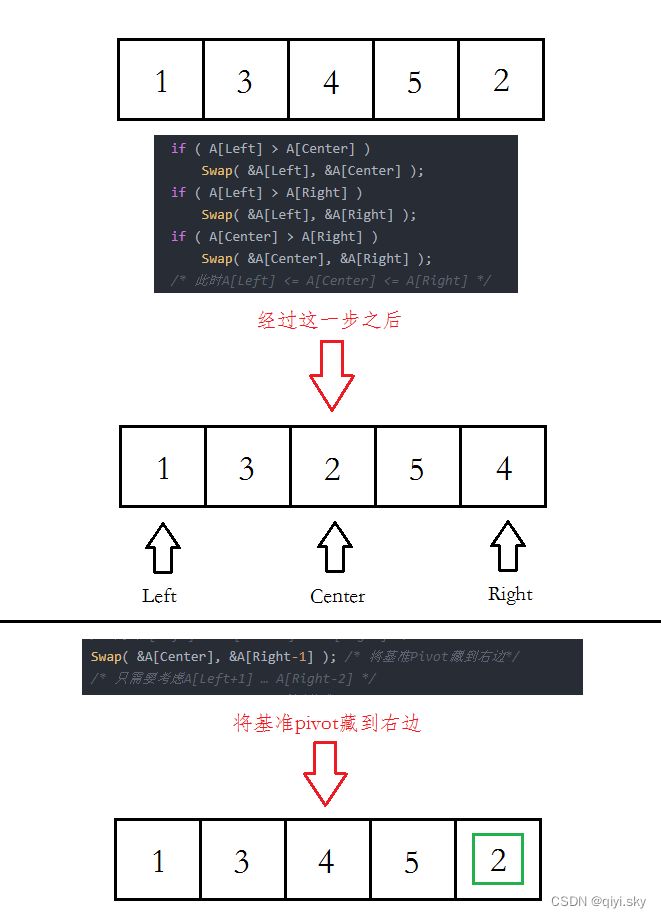
下面就是三个数中选取中位数的算法:
ElementType Median3( ElementType A[], int Left, int Right )
{ int Center = (Left+Right) / 2;if ( A[Left] > A[Center] )Swap( &A[Left], &A[Center] );if ( A[Left] > A[Right] )Swap( &A[Left], &A[Right] );if ( A[Center] > A[Right] )Swap( &A[Center], &A[Right] );/* 此时A[Left] <= A[Center] <= A[Right] */Swap( &A[Center], &A[Right-1] ); /* 将基准Pivot藏到右边*//* 只需要考虑A[Left+1] … A[Right-2] */return A[Right-1]; /* 返回基准Pivot */
}
选好基准之后,我们就进入子集的划分。
子集划分
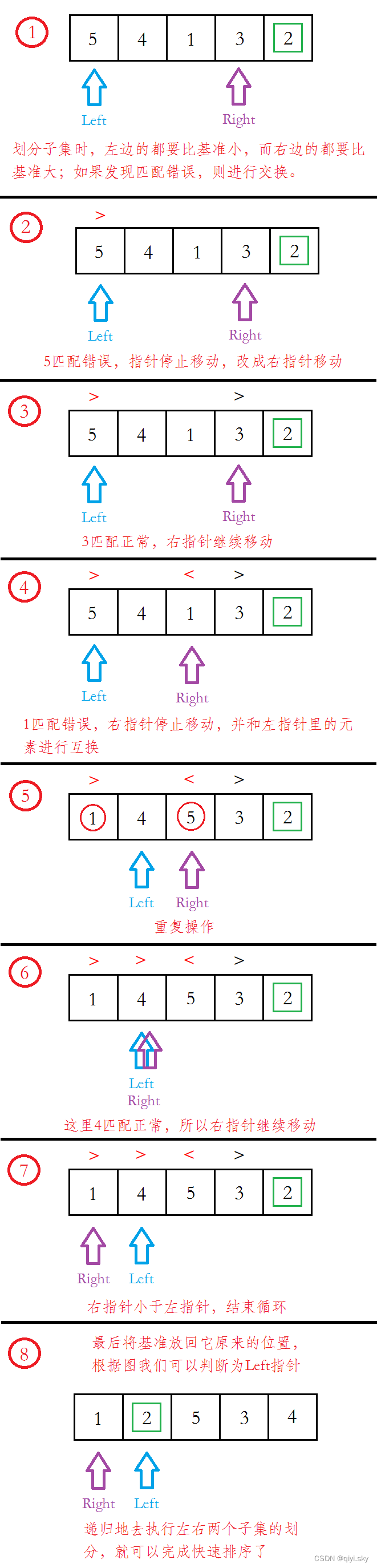
注意:如果有元素正好等于pivot时,则停下来进行交换。
小规模数据的处理
快速排序有一个比较明显的问题,那就是用递归,而递归需要频繁地调用栈;在小规模数据的处理上不占优势。
也就是说,对小规模的数据(例如N不到100)可能还不如插入排序快。
解决方案
- 当递归的数据规模充分小时,则停止递归,直接调用简单排序(例如插入排序)
- 在程序中定义一个Cutoff的阈值
算法实现
ElementType Median3( ElementType A[], int Left, int Right )
{ int Center = (Left+Right) / 2;if ( A[Left] > A[Center] )Swap( &A[Left], &A[Center] );if ( A[Left] > A[Right] )Swap( &A[Left], &A[Right] );if ( A[Center] > A[Right] )Swap( &A[Center], &A[Right] );/* 此时A[Left] <= A[Center] <= A[Right] */Swap( &A[Center], &A[Right-1] ); /* 将基准Pivot藏到右边*//* 只需要考虑A[Left+1] … A[Right-2] */return A[Right-1]; /* 返回基准Pivot */
}void Qsort( ElementType A[], int Left, int Right )
{ /* 核心递归函数 */ int Pivot, Cutoff, Low, High;if ( Cutoff <= Right-Left ) { /* 如果序列元素充分多,进入快排 */Pivot = Median3( A, Left, Right ); /* 选基准 */ Low = Left; High = Right-1;while (1) { /*将序列中比基准小的移到基准左边,大的移到右边*/while ( A[++Low] < Pivot ) ;while ( A[--High] > Pivot ) ;if ( Low < High ) Swap( &A[Low], &A[High] );else break;}Swap( &A[Low], &A[Right-1] ); /* 将基准换到正确的位置 */ Qsort( A, Left, Low-1 ); /* 递归解决左边 */ Qsort( A, Low+1, Right ); /* 递归解决右边 */ }else InsertionSort( A+Left, Right-Left+1 ); /* 元素太少,用简单排序 */
}void QuickSort( ElementType A[], int N )
{ /* 统一接口 */Qsort( A, 0, N-1 );
}end
学习自:MOOC数据结构——陈越、何钦铭
![自然语言处理从入门到应用——LangChain:模型(Models)-[聊天模型(Chat Models):基础知识]](/images/no-images.jpg)