前言
本周,笔者将之前的基于 Servlet 的个人博客项目进行了迭代,基于 SpringBoot + SpringMVC + Mybatis + Redis 进行实现。额外实现密码的明文加密处理(加盐算法)、修改随笔、随笔主页等功能,并将 session 存储到 Redis 中持久化,同时额外实现分页功能并使用对 AOP 思想对用户登录身份验证模块进行升级。升级成为随笔分享平台,当然目前还在迭代中。emmmm,具体后面会出文章详细介绍。这里先说说遇到的问题:
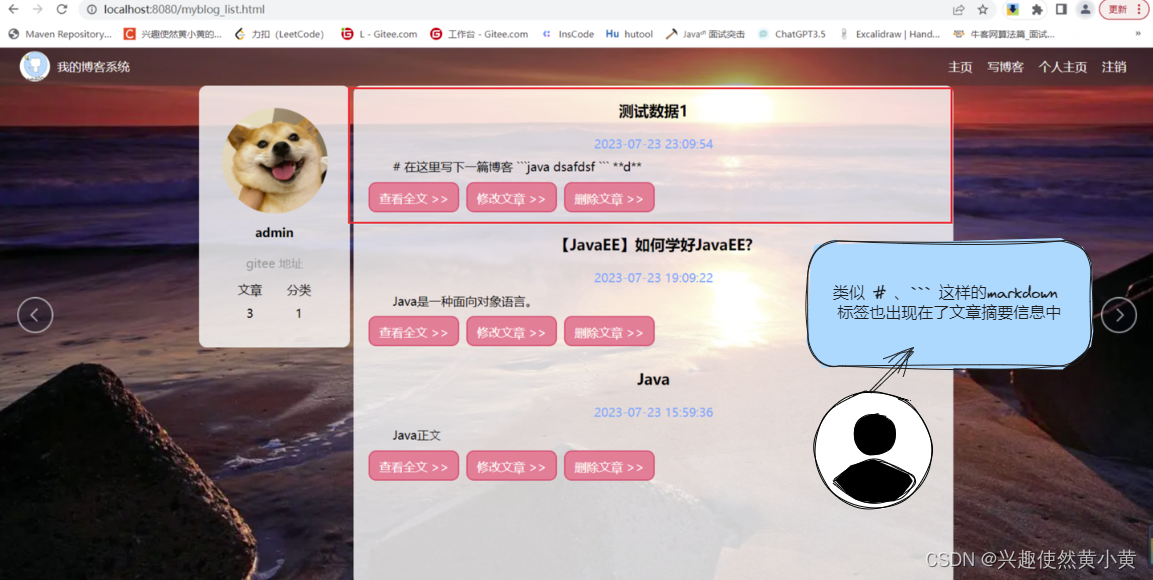
可以发现:在随笔的摘要信息中,形如 # 这样的 markdown 标签也一并展示在了随笔摘要信息中。
怎么解决呢? 很显然,一种是自己解决,一种是依赖 api:
- 使用正则表达式对文章正文中的所有 markdown 标签进行匹配,然后使用空字符进行替换;
- 使用 flexmark-java库来解析和转换 Markdown 文本。
下面,笔者将对两种方式分别进行讲解,并使用正则表达式的方式处理个人随笔系统中的该问题。我们接着往下看~
文章目录
- 前言
- 1 正则表达式替换 Markdown 文本
- 1.1 正则表达式简介
- 1.2 具体实现
- 2 flexmark-java库解析和转换 Markdown 文本
- 3 实战:对随笔系统中的摘要信息处理
1 正则表达式替换 Markdown 文本
1.1 正则表达式简介
正则表达式是一种强大的模式匹配工具,可以用于查找和替换文本中的特定模式。当涉及到在Java中使用正则表达式时,可以使用java.util.regex包提供的类来进行模式匹配、查找和替换操作。以下是一些常用的类和方法:
-
Pattern类:Pattern类用于表示正则表达式模式。可以使用Pattern.compile()方法将正则表达式编译为一个Pattern对象。String regex = "\\d+"; // 匹配一个或多个数字 Pattern pattern = Pattern.compile(regex); -
Matcher类:Matcher类用于进行模式匹配操作。可以使用Matcher.matches()方法检查整个输入字符串是否与模式匹配,或使用Matcher.find()方法在输入字符串中查找下一个匹配项。String input = "Hello 123 World"; Matcher matcher = pattern.matcher(input); if (matcher.find()) {System.out.println("匹配到数字:" + matcher.group()); } -
String类的正则表达式方法:String类提供了一些便捷的方法来处理正则表达式,如String.matches()、String.replaceAll()和String.split()。String input = "Hello 123 World"; if (input.matches("\\d+")) {System.out.println("输入字符串是一个数字"); }String replaced = input.replaceAll("\\d+", "###"); System.out.println("替换后的字符串:" + replaced);String[] parts = input.split("\\s+"); // 使用空白字符分割字符串 System.out.println("分割后的字符串数组:" + Arrays.toString(parts));
具体可参考Java官方文档中关于正则表达式的部分:Java 正则表达式
1.2 具体实现
import java.util.regex.Pattern;public class MarkdownUtils {public static String removeMarkdownTags(String markdown) {// 匹配Markdown标签的正则表达式String regex = "\\*\\*|__|\\*|_|~~|`|\\[\\]|\\(|\\)|\\{|\\}|\\[|\\]|#|\\+|-|\\.|!";// 使用空字符串替换Markdown标签String result = Pattern.compile(regex).matcher(markdown).replaceAll("");return result;}
}
在上面的示例中,removeMarkdownTags方法接受一个Markdown格式的字符串作为输入,并使用正则表达式将Markdown标签替换为空字符串,从而去除Markdown标签。
2 flexmark-java库解析和转换 Markdown 文本
首先,需要在项目中添加flexmark-java库的依赖。如果使用 Maven,可以在pom.xml文件中添加以下依赖项:
<dependencies><dependency><groupId>com.vladsch.flexmark</groupId><artifactId>flexmark-all</artifactId><version>0.62.2</version></dependency>
</dependencies>
然后就可以使用flexmark-java库来解析Markdown文本并获取纯文本内容,如下所示:
import com.vladsch.flexmark.html.HtmlRenderer;
import com.vladsch.flexmark.parser.Parser;public class MarkdownUtils {public static String removeMarkdownTags(String markdown) {Parser parser = Parser.builder().build();HtmlRenderer renderer = HtmlRenderer.builder().build();// 将Markdown文本解析为HTMLString html = renderer.render(parser.parse(markdown));// 使用Jsoup库从HTML中获取纯文本内容String plainText = org.jsoup.Jsoup.parse(html).text();return plainText;}public static void main(String[] args) {String markdown = "**Hello** _world_!";String plainText = removeMarkdownTags(markdown);System.out.println(plainText); // 输出: Hello world!}
}
在上面的示例中,使用flexmark-java库将Markdown文本解析为HTML,然后使用Jsoup库从HTML中提取纯文本内容。
3 实战:对随笔系统中的摘要信息处理
在这里,笔者使用正则表达式的方式对随笔摘要信息进行处理。
首先,创建一个 MarkdownUtils 工具类,该类就是专门用于处理 Markdown 文本的:
- 对摘要进行去除 markdown 标签处理;
- 摘要只截取文章正文前的 n 个字符;
MarkdownUtils.java
import java.util.regex.Pattern;/*** @author 兴趣使然黄小黄* @date 2023/7/23 23:18* 用于处理文章列表的文章摘要信息*/
public class MarkdownUtils {// 匹配Markdown标签的正则表达式private static String regex = "\\*\\*|__|\\*|_|~~|`|\\[\\]|\\(|\\)|\\{|\\}|\\[|\\]|#|\\+|-|\\.|!";/*** 对摘要进行去 markdown 标签处理*/public static String removeMarkdownTags(String markdown, int n) {// 先对 markdown 字符串进行截取markdown = preprocessingString(markdown, n);// 使用空字符串替换Markdown标签并返回return Pattern.compile(regex).matcher(markdown).replaceAll("");}/*** 截取正文的前 n 个字符作为摘要*/private static String preprocessingString(String s, int n) {if (s == null || s == "" || n <= 0) {return "";}String result = "";if (n >= s.length()) {result = s.substring(0, s.length());} else {result = s.substring(0, n);}return result;}
}
编写完代码后,我们进行简单的 单元测试:
@SpringBootTest
class MarkdownUtilsTest {@Testvoid removeMarkdownTags() {String markdown = "**Hello** _world_";String result = MarkdownUtils.removeMarkdownTags(markdown, 256);System.out.println(result);Assertions.assertEquals("Hello world", result);}
}
单元测试结果如下:
测试没问题后,我们可以着手对项目中的返回文章列表部分进行处理。
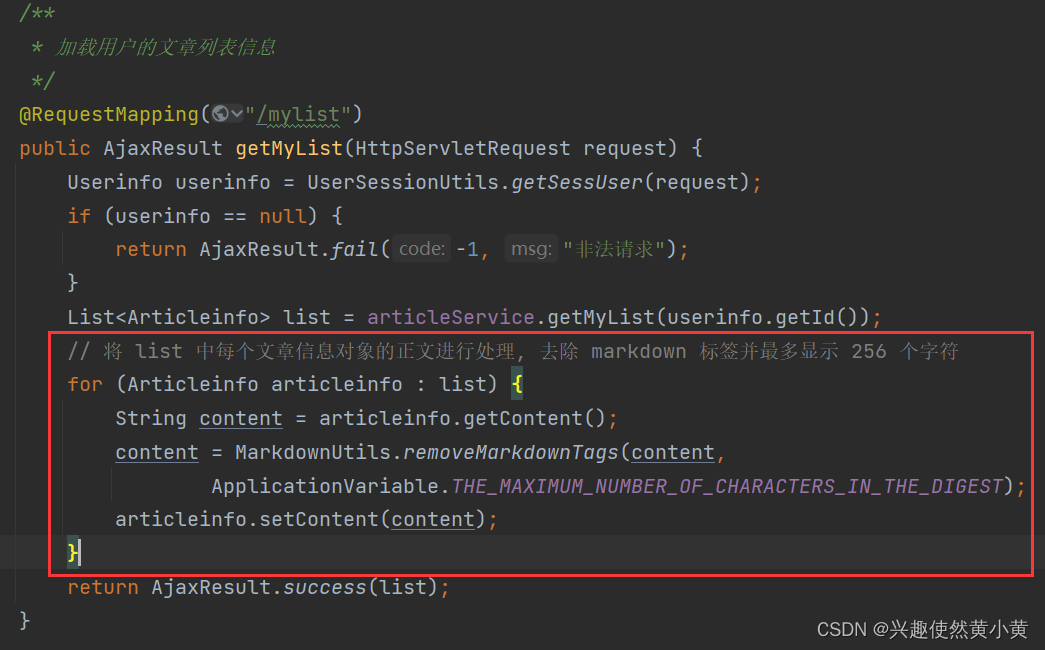
在项目中,获取个人随笔列表信息的 url 为 /art//mylist , 因此找到对应的 controller,只需要对获取的文章信息对象的列表的正文进行处理后再返回:
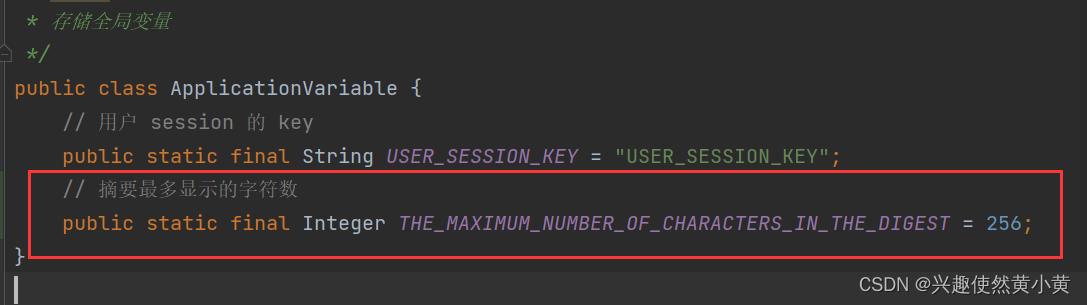
为了程序后期的维护,我们把摘要的最大字符长度放在了一个公共类进行保存:
最后,我们撰写一个很长很长的随笔来看看 # 是否会被处理,文章是否会被截取吧~结果如下: