在分布式系统中,事务的处理分布在不同组件、服务中,因此分布式事务的ACID保障面临着一些特殊难点。本系列文章介绍了21种分布式事务设计模式,并分析其实现原理和优缺点,在面对具体分布式事务问题时,可以选择合适的模式进行处理。原文: Exploring Solutions for Distributed Transactions (7)

在不同业务场景下,可以有不同的解决方案,常见方法有:
-
阻塞重试(Blocking Retry) -
二阶段和三阶段提交(Two-Phase Commit (2PC) and Three-Phase Commit (3PC)) -
基于后台队列的异步处理(Using Queues to Process Asynchronously in the Background) -
TCC补偿(TCC Compensation Matters) -
本地消息表(异步保证)/发件箱模式(Local Message Table (Asynchronously Ensured)/Outbox Pattern) -
MQ事务(MQ Transaction) -
Saga模式(Saga Pattern) -
事件驱动(Event Sourcing) -
命令查询职责分离(Command Query Responsibility Segregation, CQRS) -
原子提交(Atomic Commitment) -
并行提交(Parallel Commits) -
事务复制(Transactional Replication) -
一致性算法(Consensus Algorithms) -
时间戳排序(Timestamp Ordering) -
乐观并发控制(Optimistic Concurrency Control) -
拜占庭容错(Byzantine Fault Tolerance, BFT) -
分布式锁(Distributed Locking) -
分片(Sharding) -
多版本并发控制(Multi-Version Concurrency Control, MVCC) -
分布式快照(Distributed Snapshots) -
主从复制(Leader-Follower Replication)
本文将介绍MVCC、分布式快照以及主从复制三种模式。
19. 多版本并发控制(Multi-Version Concurrency Control, MVCC)
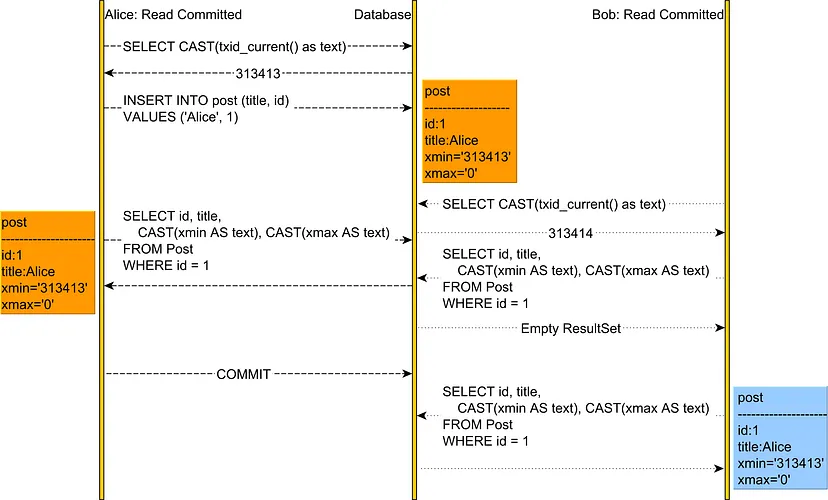
-
允许多个事务并发访问相同的数据,而不会相互干扰。 -
创建同一数据对象的多个版本,并允许事务同时访问不同的版本。通过这种方式,事务可以在非阻塞的情况下读取数据,并且可以在不产生冲突或不一致的情况下执行写操作。 -
涉及如下步骤: -
当事务想要读写数据时,首先检查系统事务表,以确定是否可以进行。如果事务可以继续,则为其分配唯一的事务ID。 -
当事务写入数据对象时,创建该对象的新版本,并且事务ID与该版本相关联,新版本被添加到系统版本表中。 -
当事务读取数据对象时,会在版本表中搜索该对象在事务开始之前创建的最新版本,并从对象的那个版本读取数据。 -
数据对象的每个版本都与事务ID、开始时间和结束时间相关联。开始时间为版本创建的时间,结束时间为版本被更新版本取代的时间。 -
当事务提交时,结束时间被记录在事务表中。与该事务关联的所有版本的数据对象都被标记为已提交,并且结束时间设置为事务的结束时间。 -
事务终止时,其结束时间记录在事务表中。与该事务关联的所有版本的数据对象都被标记为终止,并且结束时间设置为事务的结束时间。 -
当新的事务开始时,只能访问在它开始时间之前已经提交的数据对象,确保事务只读取一致的数据。
-
import sqlite3
import time
# Connect to the database
conn = sqlite3.connect('example.db')
# Create a table for testing MVCC
conn.execute('''CREATE TABLE test (
id INTEGER PRIMARY KEY,
name TEXT,
value INTEGER,
version INTEGER
)''')
# Insert some initial data
conn.execute("INSERT INTO test (name, value, version) VALUES ('foo', 42, 1)")
# Start a transaction
tx = conn.begin()
# Read the current value of 'foo'
cursor = tx.execute("SELECT value, version FROM test WHERE name = 'foo'")
value, version = cursor.fetchone()
# Increment the value of 'foo'
new_value = value + 1
# Insert a new version of the data
new_version = version + 1
tx.execute("INSERT INTO test (name, value, version) VALUES ('foo', ?, ?)", (new_value, new_version))
# Update the version of the original data
tx.execute("UPDATE test SET version = ? WHERE name = 'foo' AND version = ?", (new_version, version))
# Commit the transaction
tx.commit()
# Print the final value of 'foo'
cursor = conn.execute("SELECT value FROM test WHERE name = 'foo'")
value = cursor.fetchone()[0]
print(f"Final value of 'foo': {value}")
# Close the database connection
conn.close()
示例代码
-
事务可以根据自己的时间戳读取适当版本的数据,而不会影响其他事务。 -
涉及如下步骤: -
连接数据库SQLite3 -
创建测试MVCC的表 -
插入初始数据 -
启动事务 -
读取'foo'的当前值 -
将'foo'的值+1 -
插入版本号更高的数据新版本 -
更新原始数据版本号,使其与新版本相匹配 -
提交事务 -
输出'foo'的最终值 -
关闭数据库连接
-
优点
-
允许多个事务同时读写数据 -
避免使用锁 -
维护数据的多个版本 -
在事务之间提供高度隔离
缺点
-
增加了数据库设计的复杂性 -
由于需要存储多版本数据,增加了存储开销 -
由于需要扫描多版本数据,增加了查询执行时间
适用场景
-
具有高读写比率,并且大多数是只读事务的应用 -
需要同时执行许多事务 -
需要高并发性和一致性的联机事务处理(OLTP)系统 -
事务需要高度隔离的应用,例如金融应用程序
20. 分布式快照(Distributed Snapshots)

-
记录分布式系统在特定时间点的状态 -
可用于多种应用,如分布式数据库、分布式文件系统和分布式消息代理。 -
涉及如下步骤: -
选择启动快照的进程。该进程向系统中其他进程发送标记消息,当进程接收到标记消息时,获取其当前状态的快照,并将消息发送给相邻进程。 -
当进程接收到标记消息时,记录其本地状态,包括进程状态及其通信通道。 -
进程记录本地状态后,将标记消息发送给相邻进程,相邻进程启动快照进程。 -
进程等待来自相邻进程的所有标记消息完成快照。 -
进程接收到所有标记消息后,记录所有用于与其他进程通信的通道状态。 -
一旦进程记录了所有通道的状态,就向发起快照的进程发送确认消息。 -
发起快照的进程收到所有进程的确认消息后,结合本地状态和通道状态信息,构建分布式系统的快照。
-
from multiprocessing import Process, Queue
class ProcessNode(Process):
def __init__(self, pid, processes, markers):
super().__init__()
self.pid = pid
self.processes = processes
self.markers = markers
self.state = 0
def send_message(self, dest):
self.processes[dest].queue.put(self.pid)
def run(self):
while True:
if not self.queue.empty():
message = self.queue.get()
if message == 'marker':
self.markers[self.pid] = True
for i in range(len(self.processes)):
if i != self.pid:
self.send_message(i)
else:
self.state += message
for i in range(len(self.markers)):
if self.markers[i]:
self.send_message(i)
self.markers[i] = False
else:
# do some work
self.state += 1
示例代码
-
Chandy-Lamport算法是一种常用的分布式快照算法。
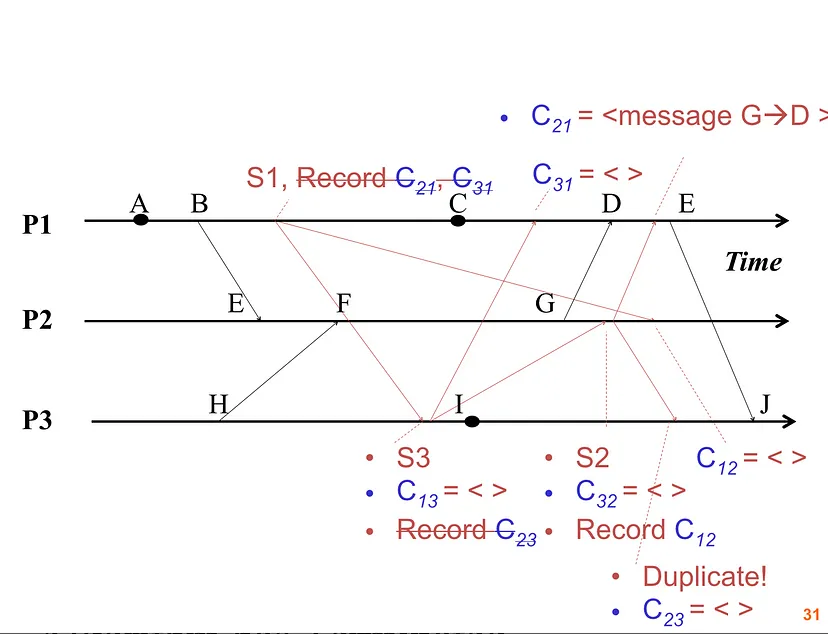
-
ProcessNode类 —— 扩展multiprocessing.Process类-
每个 ProcessNode实例代表分布式系统中的一个进程。 -
send_message方法 —— 将消息发送到另一个进程 -
run方法 —— 定义进程的主逻辑 -
如果接收到 marker消息,则进程将标记设置为True,并向所有其他进程发送marker消息,开始记录其状态。 -
如果接收到非 marker消息,则该进程将该消息添加到其状态,并向所有设置了标记的其他进程发送marker消息。 -
如果队列中没有消息,则进程执行自己的工作并改变其状态。 -
每个进程获取其本地状态的快照,并向其他进程发送消息以获取一致的全局状态。
-
优点
-
实现跨多个节点的数据一致性 -
实现容错机制,并能从故障中恢复
缺点
-
实现复杂 -
引入额外的网络流量和开销 -
难以调试和诊断问题 -
要求修改现有系统
适用场景
-
要求跨多个节点实现数据一致性的金融系统 -
需要跨多个节点实现数据一致性的库存管理和订单跟踪系统 -
需要容错性和一致性的可靠消息传递
21. 主从复制(Leader-Follower Replication)
-
在分布式系统中复制数据 -
一个节点充当领导者,其他节点充当追随者 -
领导者节点 —— 更新数据 -
跟随者节点 —— 复制领导者节点所做的更改 -
涉及如下步骤: -
领导者节点收到客户端的写请求 -
领导者节点更新其本地数据副本,并将更新发送给所有追随者节点 -
跟随者节点将更新应用到自己的本地数据副本 -
领导者节点向客户端发送写操作成功的确认信息 -
如果跟随者节点出现故障,领导者节点将更新信息发送给替代节点,以确保替代节点拥有最新的数据副本 -
客户端想要读取数据时,可以向领导者节点或任何跟随者节点请求数据。如果从跟随者节点请求数据,则跟随者节点需要检查是否拥有最新的数据副本。如果没有,则从领导者节点请求数据。
-
import threading
import time
class LeaderFollowerReplication:
def __init__(self, data):
self.data = data
self.leader_lock = threading.Lock()
self.follower_lock = threading.Lock()
self.leader = None
self.follower = None
def start_leader(self):
while True:
self.leader_lock.acquire()
self.follower_lock.acquire()
self.follower = self.data
time.sleep(0.5)
self.leader = self.data
self.follower_lock.release()
self.leader_lock.release()
def start_follower(self):
while True:
self.follower_lock.acquire()
if self.follower != self.data:
self.data = self.follower
self.follower_lock.release()
time.sleep(1)
if __name__ == "__main__":
lfr = LeaderFollowerReplication("original_data")
leader_thread = threading.Thread(target=lfr.start_leader)
follower_thread = threading.Thread(target=lfr.start_follower)
leader_thread.start()
follower_thread.start()
leader_thread.join()
follower_thread.join()
示例代码
-
LeaderFollowerReplication类 —— 存储要复制的数据并管理锁机制-
这个类有两个锁, leader_lock和follower_lock,以确保两个线程中一次只有一个可以访问数据。 -
start_leader方法 —— 运行领导者线程,首先获取leader_lock和follower_lock,以确保跟随者线程没有修改数据。然后将数据设置为与跟随者的数据相等,并在将数据设置为与自己的数据相等之前休眠0.5秒,最后释放锁。 -
start_follower方法 —— 运行跟随者线程,获取follower_lock并检查跟随者的数据是否与当前数据不同。如果是,将数据设置为等于跟随者的数据,然后释放follower_lock并休眠1秒。
-
-
创建 LeaderFollowerReplication实例,初始数据值为"original_data"。然后创建两个线程,一个用于领导者,一个用于跟随者。
优点
-
即使跟随者节点出现故障,领导者节点也可以继续处理写请求并保持数据的一致性 -
随着跟随者节点数量的增加,系统可以在不影响领导者节点性能的情况下处理大量读请求 -
确保所有节点都有一致的数据副本
缺点
-
如果领导者节点故障,系统将无法处理写请求,直到选出新的领导者节点 -
因为每次更新都必须广播到所有跟随者节点,因此会产生更多网络流量
适用场景
-
需要在多个地点保持一致库存的电子商务网站 -
需要在多个分支机构之间保持账户余额一致的金融机构 -
需要在多个服务器上保持用户资料一致的社交媒体平台
挑战
-
很难确保所有节点在任何时候都有相同的数据副本 -
如果领导者节点必须处理大量写请求,那么有可能成为瓶颈 -
系统必须能够检测并从节点故障中恢复,以保持数据一致性
参考文献
How does MVCC (Multi-Version Concurrency Control) work
What is MVCC? How multi-version concurrency control works
Chapter 13. Concurrency Control
Multiversion Concurrency Control (MVCC)
Setting Multi-Version Concurrency Control (MVCC)
Open Source Database (RDBMS) for the Enterprise
Distributed Snapshots
Distributed Snapshots
Distributed Snapshot Problem - Distributed Systems for Practitioners
Distributed Snapshots
Reading Group. Distributed Snapshots: Determining Global States of Distributed Systems
Distributed snapshots for YSQL
An example run of the Chandy-Lamport snapshot algorithm
DB Replication (I): Introduction to database replication
Chapter 5. Replication - Shichao's Notes
Leader and Followers
Understanding Database Replication
Leaders and Followers
Multi-master vs leader-follower
Data Replication - Grokking Modern System Design Interview for Engineers & Managers
Build software better, together
- END -你好,我是俞凡,在Motorola做过研发,现在在Mavenir做技术工作,对通信、网络、后端架构、云原生、DevOps、CICD、区块链、AI等技术始终保持着浓厚的兴趣,平时喜欢阅读、思考,相信持续学习、终身成长,欢迎一起交流学习。微信公众号:DeepNoMind
本文由 mdnice 多平台发布