版本信息:
jdk版本:jdk8u40
思想至上
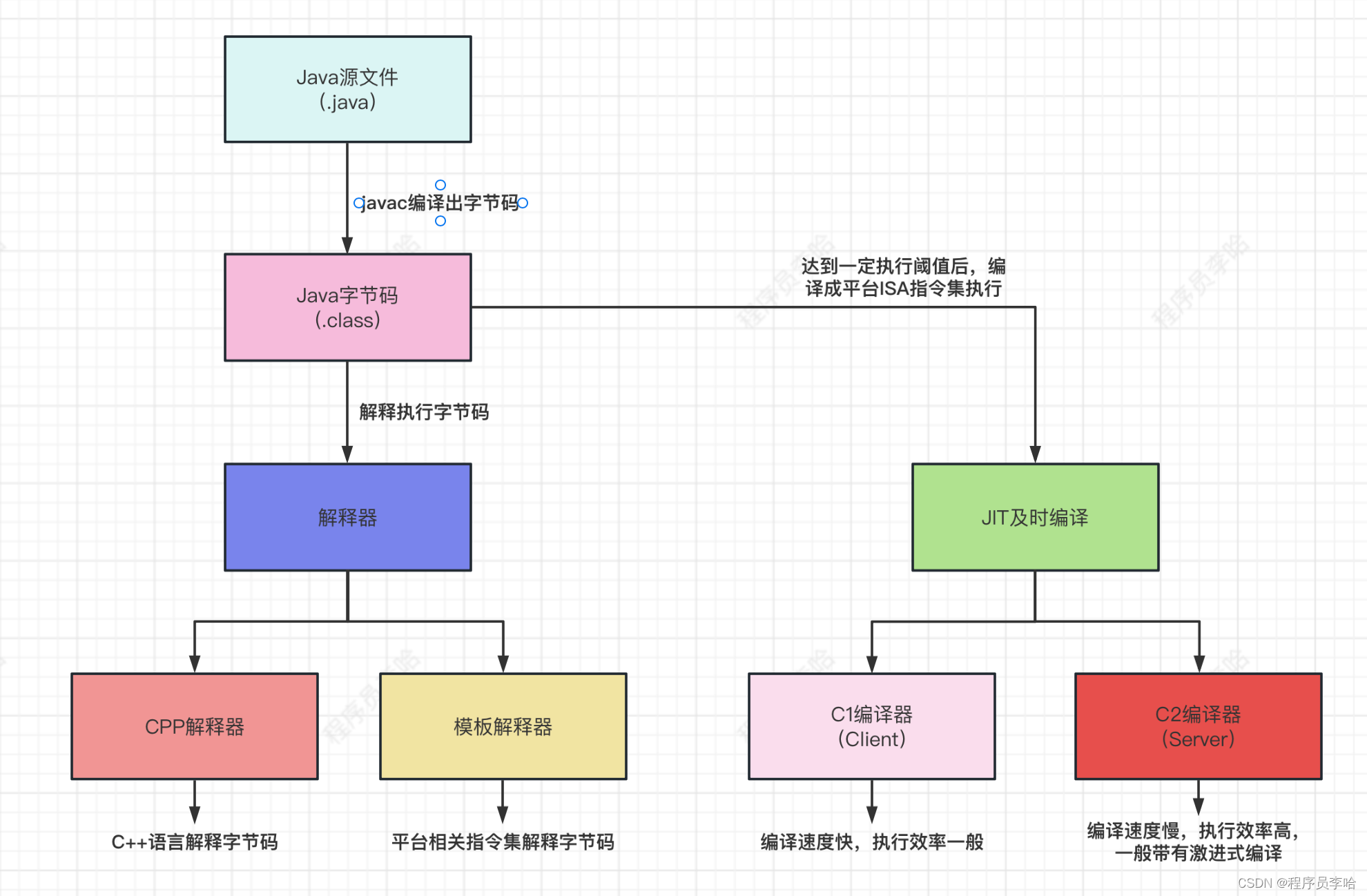
技术经过数百年的迭代,如今虚拟机中都存在JIT模块,JVM中Hotspot,Android虚拟机中dalvik、Art等等。并且存在一个共性,全部都是解释器和JIT共存。当然,如今都存在AOT编译(Ahead of Time Compiler)将Java文件直接编译成平台相关可执行文件,这并不是本文改论述的点。
在Hotspot虚拟机中执行引擎包括解释器、JIT及时编译器。从" Hotspot " 这个单词也能看出,此虚拟机为了热点而生。Hotspot虚拟机默认允许2大执行引擎同时进行工作,在正常情况下使用解释器进行工作,当达到一定阈值后从解释器转为JIT编译器工作(PS:当然,一切都可由开发者高度配置,比如:只允许解释器,比如转换阈值变低等等,为了篇幅,这里并不会把配置参数提供出来)
因为JIT编译器是在运行时编译,所以需要一定的编译时间,而解释器启动就可用,所以Hotspot中同时存在解释器和JIT、从解释器过度到JIT。并且在JIT中还分为c1编译器、c2编译器。为何同时存在c1、和c2编译器呢,原因也很简单,因为c1编译耗时少,但是编译出来的代码执行效率一般。而c2编译器编译耗时长,但是编译出来的代码执行效率高,并且会存在过激的编译。所以在Hotspot中同时存在c1和c2编译器,用于从c1过度到c2。所以在Hotspot中从解释器到编译器,一层一层的过度,其实是在编译时间和执行效率中做折中。
源码论证
从上文可以得知,在Hotspot 中默认是从解释器优化成JIT,所以在解释器执行过程中肯定存在一些值用于记录执行数据,并且达到一定的阈值就会开始进行JIT优化。而我们在思考,在Java代码中可以执行的代码都存在方法中,包括<init>和<clinit>,所以用于记录执行数据的变量是不是在方法中呢?
/src/share/vm/oops/method.hpp 文件中
class Method : public Metadata {
friend class VMStructs;…………// 用于记录方法的执行相关的次数,目的很简单,为了jit优化。MethodCounters* _method_counters;…………
}/src/share/vm/oops/methodCounters.hpp 文件中
class MethodCounters: public MetaspaceObj {friend class VMStructs;private:…………// 记录方法执行次数InvocationCounter _invocation_counter; // 记录方法中的跳转次数(if,while,for,switch等等)InvocationCounter _backedge_counter; …………
}从上述代码中可以得到在方法中存在MethodCounters类用于记录运行时的数据。而在MethodCounters类中定义了2个计数器。分别是方法执行计数器、回边计数器(记录方法中存在跳转相关的指令,比如if,while,for,switch)。而计数器达到JIT优化的阈值就会开启优化(如果是开启分层编译的话,此阈值会发生动态的变化,并不是固定的,此时将根据当前待编译的方法数以及编译线程数来动态调整)
方法执行计数器
在x86平台下,c1的阈值为1500,c2的阈值是10000。不过在分层编译开启的情况下此阈值会失效,从而变成动态阈值。
// /src/cpu/x86/vm/c1_globals_x86.hpp define_pd_global(intx, CompileThreshold, 1500 );// /src/cpu/x86/vm/c2_globals_x86.hpp define_pd_global(intx, CompileThreshold, 10000);回边计数器
在x86平台下,c1的阈值为100000,c2的阈值是100000。不过在分层编译开启的情况下此阈值会失效,从而变成动态阈值。
// /src/cpu/x86/vm/c1_globals_x86.hpp define_pd_global(intx, BackEdgeThreshold, 100000);// /src/cpu/x86/vm/c2_globals_x86.hpp define_pd_global(intx, BackEdgeThreshold, 100000);