目录
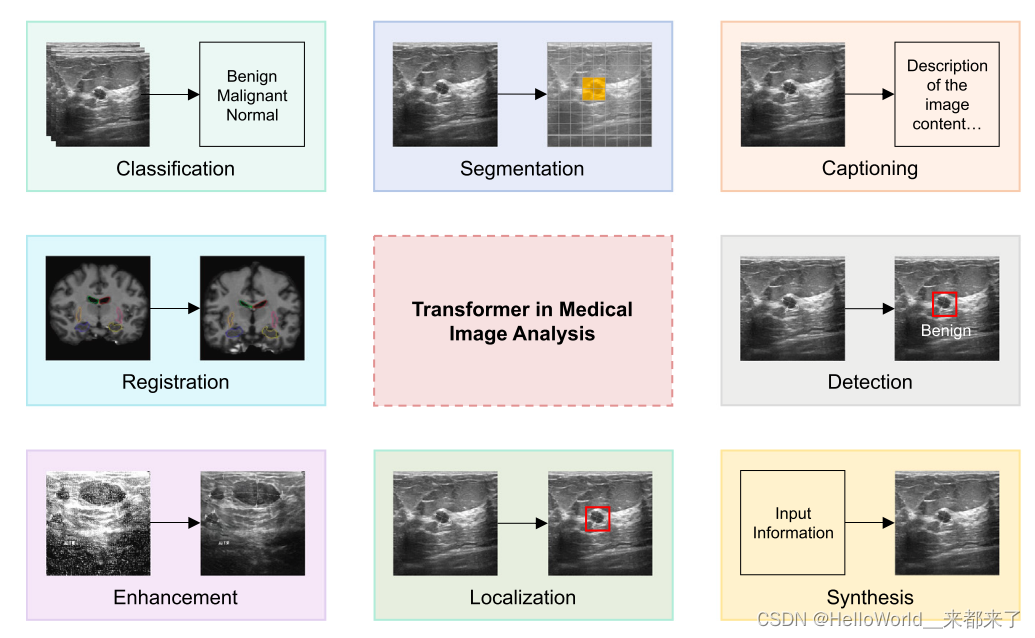
神经网络-卷积层 torch.nn.Conv2d
神经网络-最大池化的使用 torch.nn.MaxPool2d
神经网络-卷积层 torch.nn.Conv2d
torch.nn.Conv2d的官方文档地址
CLASS torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True, padding_mode=‘zeros’, device=None, dtype=None)
卷积动画的链接:https://github.com/vdumoulin/conv_arithmetic/blob/master/README.md![]() https://github.com/vdumoulin/conv_arithmetic/blob/master/README.md
https://github.com/vdumoulin/conv_arithmetic/blob/master/README.md
注意:
- 默认
bias=True,这说明PyTorch中Con2d是默认给卷积操作加了偏置的。 - 还有一些默认值:stride=1,padding=0等。
- out_channels输出通道数,相当于就是卷积核的个数。
- dilation:需要使用空洞卷积时再进行设置。
import torch from torch import nn from torch.nn import Conv2d from torch.utils.data import DataLoader from torch.utils.tensorboard import SummaryWriter from torchvision import datasets from torchvision.transforms import transforms# 1. 加载数据 dataset = datasets.CIFAR10('./dataset', train=False, transform=transforms.ToTensor(), download=True) dataloader = DataLoader(dataset, batch_size=64, shuffle=True, num_workers=0, drop_last=False)# 2. 构造模型 class Model(nn.Module):def __init__(self):super(Model, self).__init__()self.conv1 = Conv2d(in_channels=3, out_channels=6, kernel_size=3, stride=1)def forward(self, x):return self.conv1(x)writer = SummaryWriter('./logs/Conv2d')# 3. 实例化一个模型对象,进行卷积 model = Model() step = 0for data in dataloader:imgs, targets = datawriter.add_images('imgs_ch3', imgs, step)# 4. 用tensorboard打开查看图像。但是注意,add_images的输入图像的通道数只能是3 # 所以如果通道数>3,则可以先采用小土堆的这个不严谨的做法,在tensorboard中查看一下图片outputs = model(imgs)outputs = torch.reshape(outputs, (-1, 3, 30, 30))writer.add_images('imgs_ch6', outputs, step)step += 1writer.close()神经网络-最大池化的使用 torch.nn.MaxPool2d
池化也可成为下采样(就是缩小输入图像尺寸,但是不会改变输入图像的通道数)。常见的有MaxPool2d、AvgPool2d等。相反有上采样MaxUnPool2d。
MaxPool2d的官方文档地址:MaxPool2d — PyTorch 2.0 documentation
CLASS torch.nn.MaxPool2d(kernel_size, stride=None, padding=0, dilation=1, return_indices=False, ceil_mode=False)
注意:
- stride默认=kernel_size
- ceil_mode默认是False,也就是说事向下取整
pool和conv后的图像尺寸N计算公式是一样的:N = ( W − F + 2 ∗ P ) / S + 1 N=(W-F+2*P)/S+1N=(W−F+2∗P)/S+1,且都是默认N向下取整。
- 在构造tensor的时候,最好指定元素的数据类型是float,即在最后加上
dtype=torch.float32,这样后面有些操作才不会出错。 - 池化的作用:保持输入图像的特征,且减小输入量,能加快训练。(就类似于B站视频有10080P的也会有720P的,720P虽然不如1080P那么高清,但是仍然能够看出视频中物体的特征信息,有点像打了马赛克一样)
import torch import torchvision.datasets from torch import nn from torch.utils.data import DataLoader from torch.utils.tensorboard import SummaryWriterclass Model(nn.Module):def __init__(self):super(Model, self).__init__()self.maxpool1 = nn.MaxPool2d(kernel_size=3) # 默认:stride=kernel_size,ceil_mode=Falseself.maxpool2 = nn.MaxPool2d(kernel_size=3, ceil_mode=True)def forward(self, x):return self.maxpool1(x), self.maxpool2(x)model = Model()# -------------1.上图例子,查看ceil_mode为True或False的池化结果--------------- # input = torch.tensor([[1, 2, 0, 3, 1],[0, 1, 2, 3, 1],[1, 2, 1, 0, 0],[5, 2, 3, 1, 1],[2, 1, 0, 1, 1]], dtype=torch.float32)input = torch.reshape(input, (-1, 1, 5, 5)) out1, out2 = model(input) print('out1={}\nout2={}'.format(out1, out2))# --------------2.加载数据集,并放入tensorboard查看图片----------------------- # dataset = torchvision.datasets.CIFAR10('dataset', train=False, transform=torchvision.transforms.ToTensor(),download=True) dataloader = DataLoader(dataset, batch_size=64, shuffle=True)writer = SummaryWriter('./logs/maxpool') step = 0 for data in dataloader:imgs, targets = datawriter.add_images('imgs', imgs, step)imgs, _ = model(imgs)writer.add_images('imgs_maxpool', imgs, step)step += 1writer.close()