目录
1.协程切换原理理解
2.ucontext实现协程切换
2.1 实现流程
2.2 根据ucontext流程看协程实现
2.3 回答开头提出的问题
3.x86_64汇编实现协程切换
3.1libco x86_64汇编代码分析
3.2.保存程序返回代码地址流程
3.3.恢复程序地址以及上下文
4.实现简单协程框架
1.协程切换原理理解
协程可以实现在一个线程中调度并切换不同任务,参考了网上一些经典的协程实现,记录一下任务切换的原理。下文将实现一个对称协程切换的demo,相同流程先使用ucontext api实现,了解流程后再使用x86_64汇编实现,x86_64汇编直接拷贝了开源项目libco的代码,封装成类似ucontext api的方法调用。文章最后实现一个可以选择使用ucontext和汇编切换协程的简单demo。
对称协程的切换流程如下
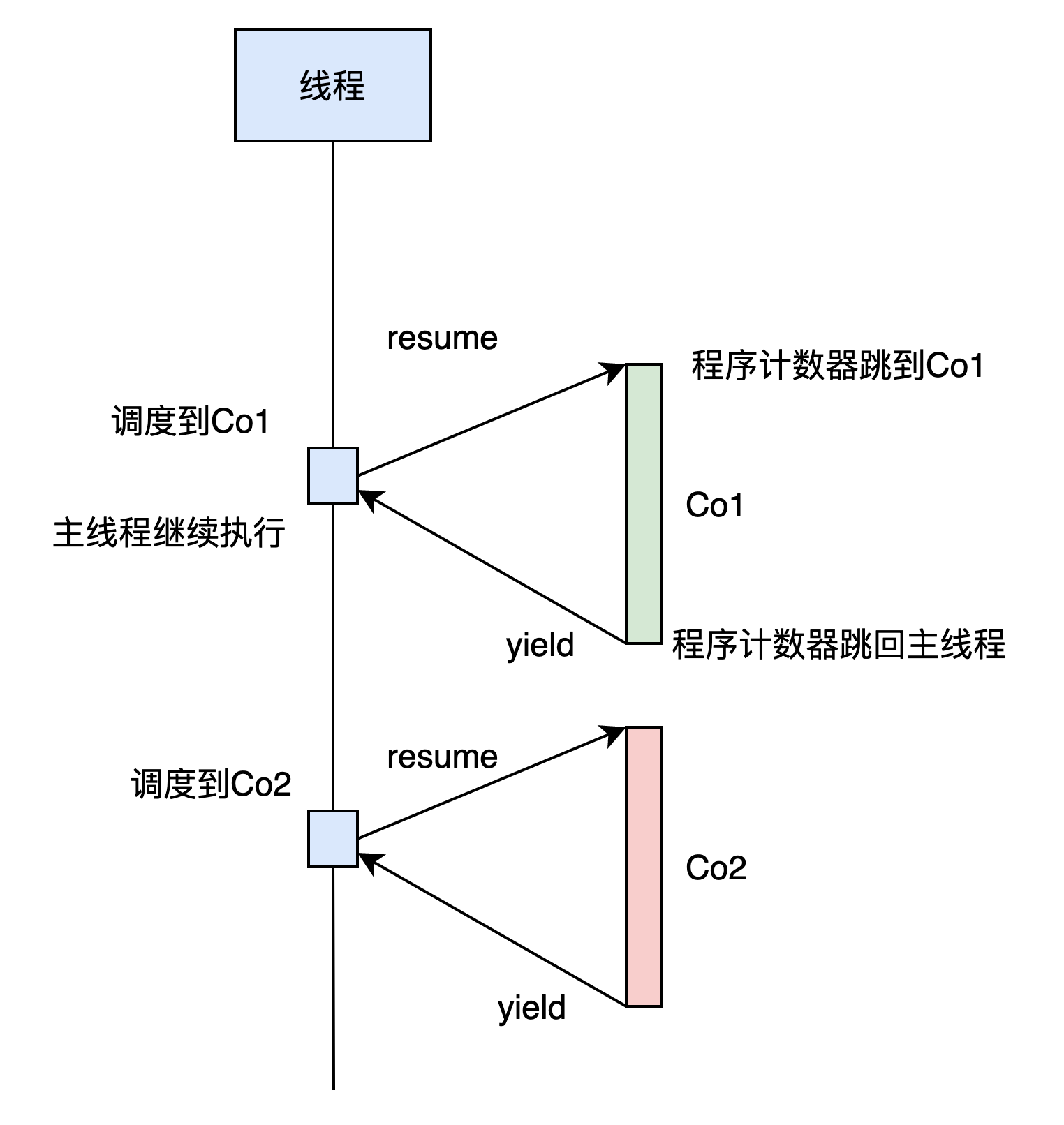
实现上述流程,直观上讲首先需要知道如何把程序计数器PC(IP)切到指定代码的位置,另外每个线程都有固定的堆栈来记录局部变量和程序返回地址,那么如何给协程执行的任务分配堆栈呢?总结一下,当前面临三个问题
1.如何修改程序计数器的位置,使程序能在不同位置跳转执行
2.如何给协程分配属于当前协程的堆栈
3.除了需要恢复对栈,切换协程后还需要恢复哪些东西(提前透露答案:还需要恢复其他通用寄存器 可以思考一下这些寄存器的内容如何存放)
解决了这三个问题,基本就完成了协程切换。
下面先使用ucontext实现一下,再借用libco提供的x86_64的汇编代码,封装一个类似ucontext api的实现,由浅入深理解协程切换。
2.ucontext实现协程切换
ucontext是posix提供的一套api,可以用于保存当前堆栈,头文件是<ucontext.h>。其中api很简单,只有四个接口,分别如下。
获得当前 CPU 上下文
int getcontext(ucontext_t *); 重置当前 CPU 上下文
int setcontext(const ucontext_t *);修改上下文信息,比如设置栈指针,需要执行的入口函数也是在这里作为函数指针传入。
void makecontext(ucontext_t *, (void *)(), int, ...); 执行makecontext设置的内容,也就实现协程切换
int swapcontext(ucontext_t *, const ucontext_t *);下面大致了解一下ucontext_t结构体,可以发现这里主要是是存放了栈空间和寄存器,也就是文章第一节中说的三个问题的后两个,这里看着都有关联。
typedef struct ucontext{unsigned long int uc_flags;struct ucontext *uc_link; //需要切换的下一个context stack_t uc_stack; //当前栈信息 如果使用自己分配的内存作为当前栈内存 需要修改这里mcontext_t uc_mcontext; // 保存寄存器信息__sigset_t uc_sigmask;struct _libc_fpstate __fpregs_mem; } ucontext_t;typedef struct{gregset_t gregs;/* Note that fpregs is a pointer. */fpregset_t fpregs;__extension__ unsigned long long __reserved1 [8];
} mcontext_t;2.1 实现流程
下面贴一下man中ucontext最基本的使用,网上引用这个代码的博客很多,咱这里也贴一下并简单分析,直观上理解ucontext的用法。这个demo虽然并非完整的协程框架,但是基本上讲明白了协程切换的流程,我理解协程框架是在这个基础上完善了堆栈管理的内容。补充一下,ucontext在Mac M1机器上比较新的操作系统版本下,使用Rosetta模式运行似乎也有问题,这里最好搞个X86_64的Linux机器运行。
#include <ucontext.h>
#include <stdio.h>
#include <stdlib.h>static ucontext_t uctx_main, uctx_func1, uctx_func2;#define handle_error(msg) \do { perror(msg); exit(EXIT_FAILURE); } while (0)static void
func1(void)
{printf("func1: started\n");printf("func1: swapcontext(&uctx_func1, &uctx_func2)\n");if (swapcontext(&uctx_func1, &uctx_func2) == -1)handle_error("swapcontext");printf("func1: returning\n");
}static void
func2(void)
{printf("func2: started\n");printf("func2: swapcontext(&uctx_func2, &uctx_func1)\n");if (swapcontext(&uctx_func2, &uctx_func1) == -1)handle_error("swapcontext");printf("func2: returning\n");
}int
main(int argc, char *argv[])
{char func1_stack[16384];char func2_stack[16384];if (getcontext(&uctx_func1) == -1)handle_error("getcontext");uctx_func1.uc_stack.ss_sp = func1_stack;uctx_func1.uc_stack.ss_size = sizeof(func1_stack);uctx_func1.uc_link = &uctx_main;makecontext(&uctx_func1, func1, 0);if (getcontext(&uctx_func2) == -1)handle_error("getcontext");uctx_func2.uc_stack.ss_sp = func2_stack;uctx_func2.uc_stack.ss_size = sizeof(func2_stack);/* Successor context is f1(), unless argc > 1 */uctx_func2.uc_link = (argc > 1) ? NULL : &uctx_func1;makecontext(&uctx_func2, func2, 0);printf("main: swapcontext(&uctx_main, &uctx_func2)\n");if (swapcontext(&uctx_main, &uctx_func2) == -1)handle_error("swapcontext");printf("main: exiting\n");exit(EXIT_SUCCESS);
}下面捡重要的流程简单分析一下。这里uctx_func1可以理解为一个协程的实例,先给这个实例安装我们自己分配的内存作为栈,并且安装一个回调函数func1作为协程入口。另外一个协程实例uctx_func1也是这样操作
char func1_stack[16384];...if (getcontext(&uctx_func1) == -1)handle_error("getcontext");uctx_func1.uc_stack.ss_sp = func1_stack;uctx_func1.uc_stack.ss_size = sizeof(func1_stack);//uctx_func1.uc_link = &uctx_func2;uctx_func1.uc_link = &uctx_main;makecontext(&uctx_func1, func1, 0);
下面代码,在main函数中,调用swapcontext完成协程切换,这里推测主要做了以下操作:
1.当前main函数执行的上下文环境,包括堆栈,堆栈栈顶指针,其他寄存器当前的状态,都被保存到了uctx_main。
2.当前程序寄存器的栈顶指针指向给uctx_func2分配的uc_stack.ss_sp,将func2函数指针作为返回地址入栈
3.swapcontext执行完毕后栈顶作为返回地址,返回func2,这样程序计数器会执行func2函数,由于sp栈顶指针寄存器在上一步已经指向了我们分配的内存,此时func2中函数调用和临时变量分配都会放到我们自己分配的内存
4.另外其他寄存器也会重新分配,如果uctx_func2不是第一次执行,那么swapcontext就会把其他通用寄存器恢复回uctx_func2之前离开时的样子。
printf("main: swapcontext(&uctx_main, &uctx_func2)\n");if (swapcontext(&uctx_main, &uctx_func2) == -1)handle_error("swapcontext");上面对swapcontext的解释是看了libco中的汇编代码猜的,属于提前剧透内容,下文还有具体分析,但是内核中不一定完全是这样的实现。
到这一步,func2就会被执行,也就是说ucontext协程切换已经完成了一次。
2.2 根据ucontext流程看协程实现
下面画了一个简图,描述了2.1小节中的流程以及剧透部分。
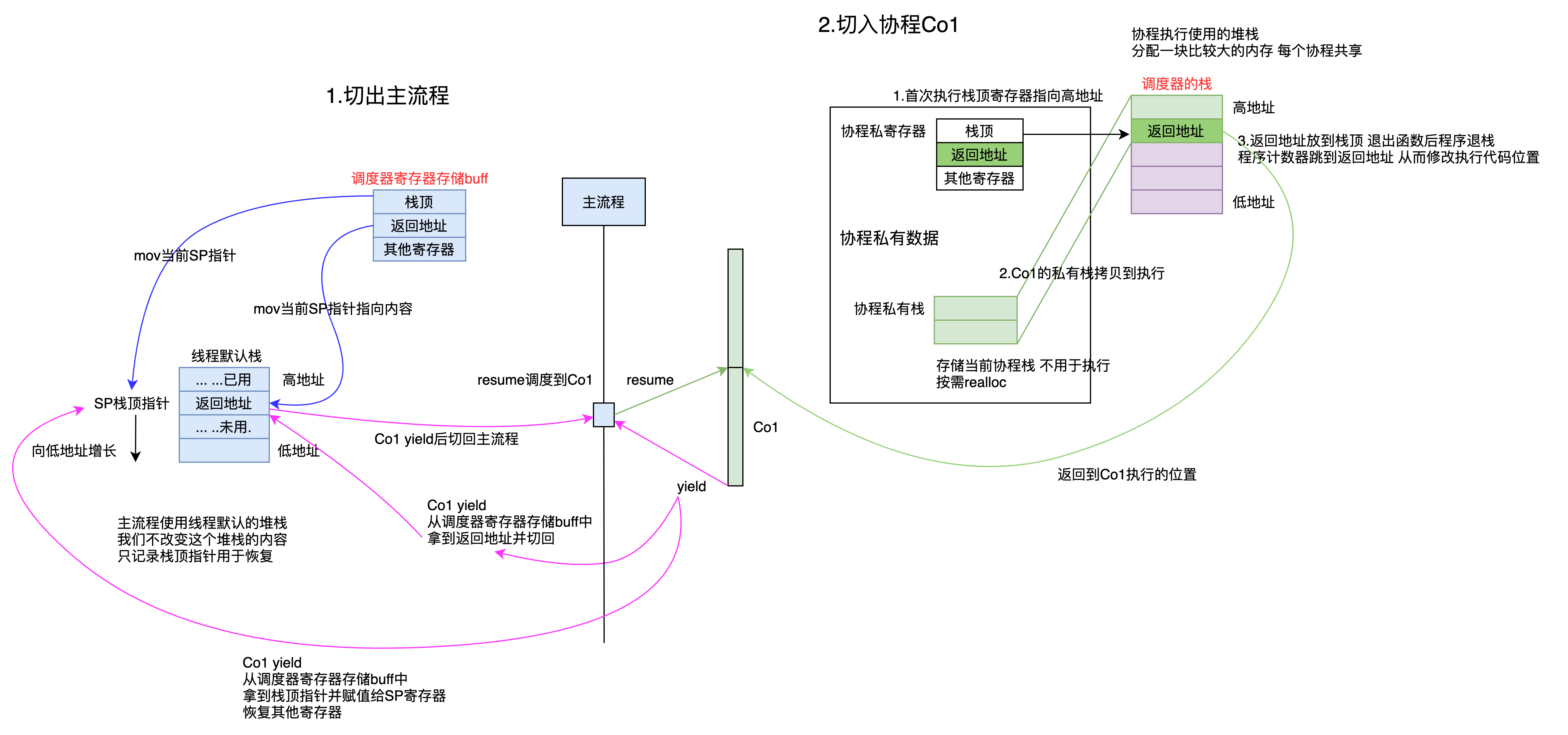 左边蓝色部分是主流程的堆栈和寄存器。
左边蓝色部分是主流程的堆栈和寄存器。
右边绿色部分是切到协程后,协程的状态。
洋红色箭头代表由协程切回主流程需要做的事情。
现在就可以看着这张图,加上提前剧透的知识,回顾一下开头提出的问题了。
2.3 回答开头提出的问题
这里比较重要,单独列了一个小节。
1.程序计数器的位置,是调用swapcontext进入时栈顶的值,这个值代表了函数的返回地址,如果需要切到其他线程,那么swapcontext函数退出前,将当前栈顶的值(长度为当前系统的sizeof(void*),64位系统这个值就是一个8byte的地址)修改为要跳转的程序地址。如果第一次设置那么这个地址就是makecontext时设置的回调函数的地址。
2.如何给自己的协程分配堆栈内存呢,先自己手动分配一块内存,然后将栈顶指针SP指向这块内存的末尾位置。简单点说就是通过汇编语言直接修改SP指针,指到我们分配的内存。
对于64位系统,栈内存和SP寄存器的关系如下
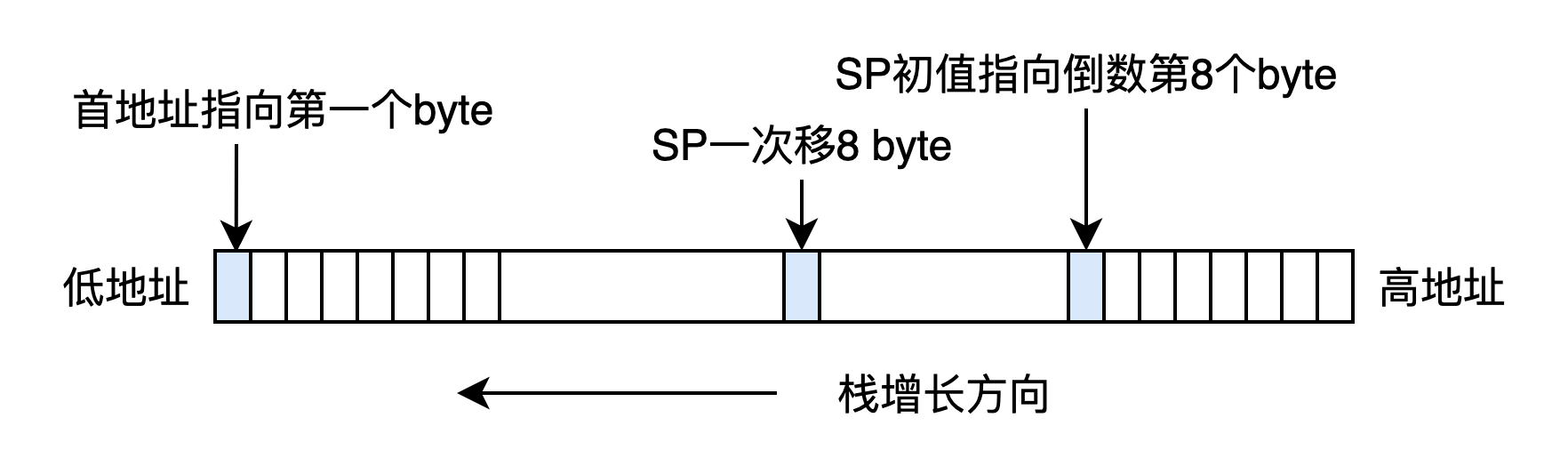
3.剩下其他寄存器,在swapcontext时,对于要切走的协程,需要存储的就存在协程context自己的内存中,然后把要切入协程的context中保存的寄存器从内存拿出,恢复到寄存器中。
3.x86_64汇编实现协程切换
截止到目前,协程切换的原理已经讲完,下面要做的是使用x86_64汇编,根据我们自己的理解,封装一个类似ucontext api的函数接口。这里汇编部分直接粘贴了libco的代码。
3.1libco x86_64汇编代码分析
这块网上已经有不少文章做过类似的分析,我们这里先贴出流程分析,主要代码都做了比较详细的注释,可以参考上文内容一起理解。最后使用Xcode进行了一次debug并做截图,验证我们的分析过程。完整代码工程在文章最后的下载链接中。
.globl simple_ctx_swap
#if !defined( __APPLE__ )
.type simple_ctx_swap, @function
#endif
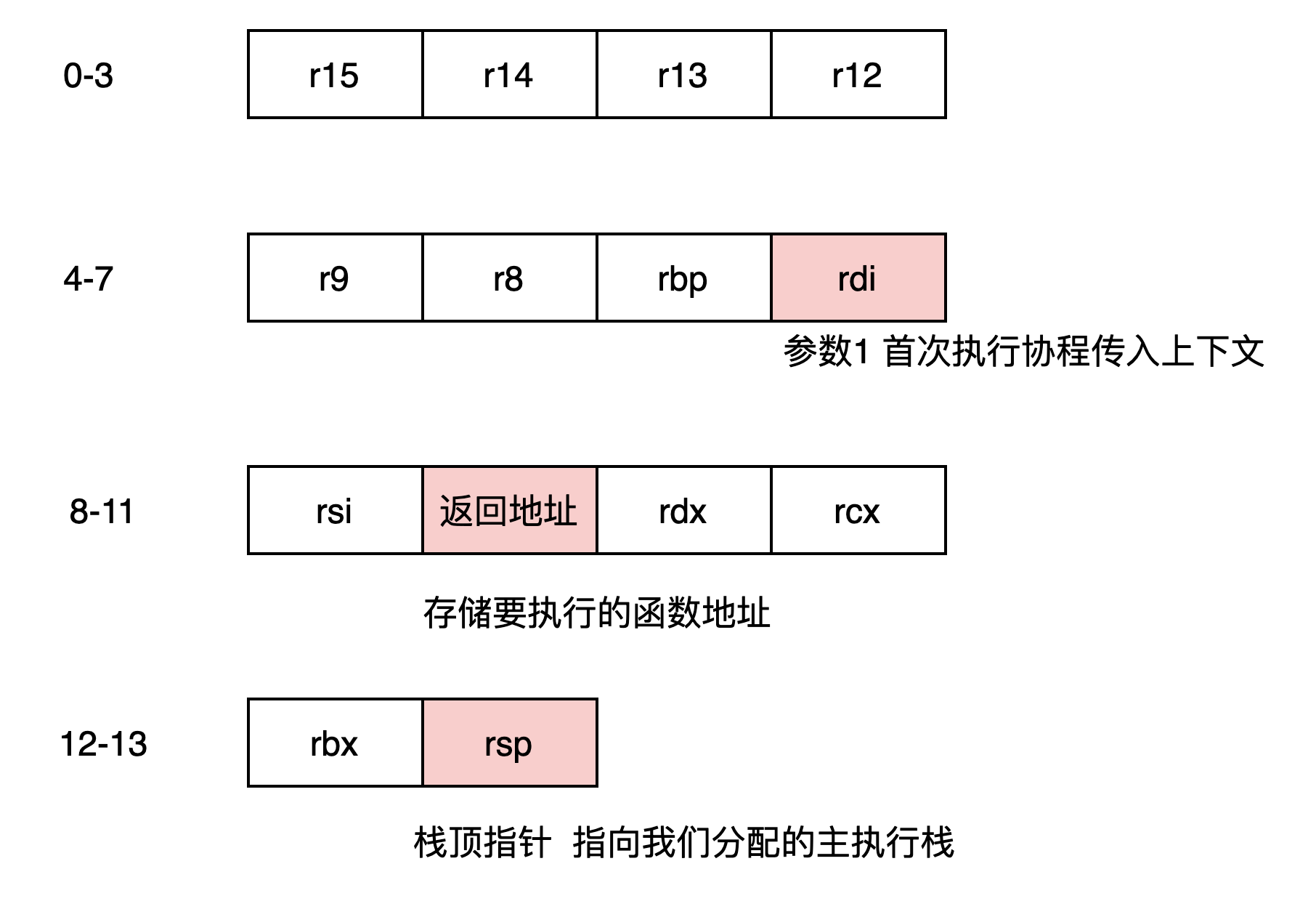
simple_ctx_swap:... ...#elif defined(__x86_64__)//leaq (%rsp),%rax //当前栈顶指针指向内存中存储的是 调用simple_ctx_swap的地址//栈顶指针(%rsp)地址 放到rax寄存器 rax存储了栈顶指针//栈顶指针指向当前simple_ctx_swap 存储在reg[9] 下次这个协程resume会走调用simple_ctx_swap的下一句//这样就可以完成协程的终端返回movq %rsp,%rax // 等效 leaq (%rsp),%rax//存当前寄存器 到给定的ctx rdi是参数1 当前co的buffer//rdi 指向当前ctx的寄存器buffer 要把当前寄存器的值存到这个buffer中movq %rax, 104(%rdi) //[14] 存栈顶 为什么不直接存rsp??????????//存储通用寄存器movq %rbx, 96(%rdi) //[13]movq %rcx, 88(%rdi) //[12]movq %rdx, 80(%rdi) //[11]movq 0(%rax), %rax //[10] rax的指向地址中的值 存入rax rax存储了栈顶值 也就是当前coctx_swap的返回值// movq 0(%rsp), %rax 为什么不直接这样movq %rax, 72(%rdi) //[9] 返回地址存入reg[9]movq %rsi, 64(%rdi) //[8]movq %rdi, 56(%rdi) //[7]movq %rbp, 48(%rdi) //[6]movq %r8, 40(%rdi) //[5]movq %r9, 32(%rdi) //[4]movq %r12, 24(%rdi) //[3]movq %r13, 16(%rdi) //[2]movq %r14, 8(%rdi) //[1]movq %r15, (%rdi) //[0]xorq %rax, %rax //通过抑或将rax置0//取 rsi表示新的要执行的co的buffer 首次就是coctx_make后的寄存器数组//rsi指向pending的ctx 要把这里的内容恢复到寄存器中//恢复通用寄存器movq 48(%rsi), %rbp //[6] x86_64 rbp用于通用寄存器 非栈底//恢复栈movq 104(%rsi), %rsp //[14] 更新栈顶指针 ctx->regs[kRSP] = sp; coctx_make强制将栈顶改成我们为每个协程分配的空间//恢复通用寄存器movq (%rsi), %r15 //[0]movq 8(%rsi), %r14 //[1]movq 16(%rsi), %r13 //[2]movq 24(%rsi), %r12 //[3]movq 32(%rsi), %r9 //[4]movq 40(%rsi), %r8 //[5]// r10 r11 不用管//恢复回调参数1 给rdimovq 56(%rsi), %rdi //[7] ctx->regs[kRDI] = (char*)s;//恢复通用寄存器movq 80(%rsi), %rdx //[10] rdx 参数3movq 88(%rsi), %rcx //[11] rcx 参数4movq 96(%rsi), %rbx //[13] rbx 通用寄存器//栈空间 | <- | rsp |-------------| 当前栈顶为函数返回地址//栈空间 | <- | rsp |-------| 将当前的栈顶推掉8字节leaq 8(%rsp), %rsp//将要执行的函数地址入栈 这样从coctx_swap返回后 出栈地址就是reg[9] ip寄存器跳到回调函数执行//栈空间 | <- | rsp |-------------|pushq 72(%rsi) //reg[9]存了回调地址 ctx->regs[kRETAddr] = (char*)pfn;//恢复回调参数2 给rsimovq 64(%rsi), %rsi //[8] ctx->regs[kRSI] = (char*)s1;ret
#endif3.2.保存程序返回代码地址流程
leaq (%rsp), %rax 执行前
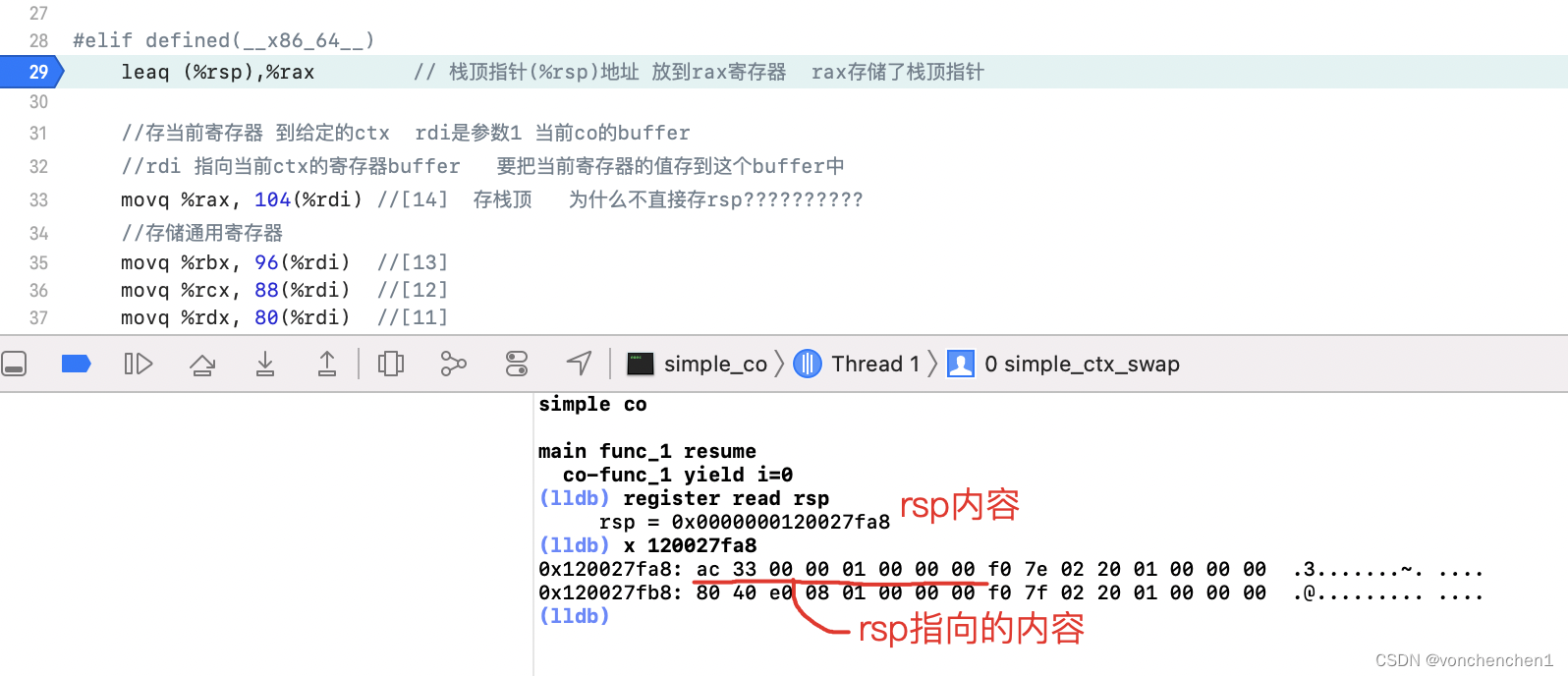
leaq (%rsp), %rax 这句话在这里基本等效于 movq %rsp, %rax ,将当前栈顶寄存器rsp中的值赋值给rax寄存器。 这里可以看到 rsp中的值 作为指针,指向地址为 0x01000033ac,记住这个值。
leaq (%rsp), %rax执行后
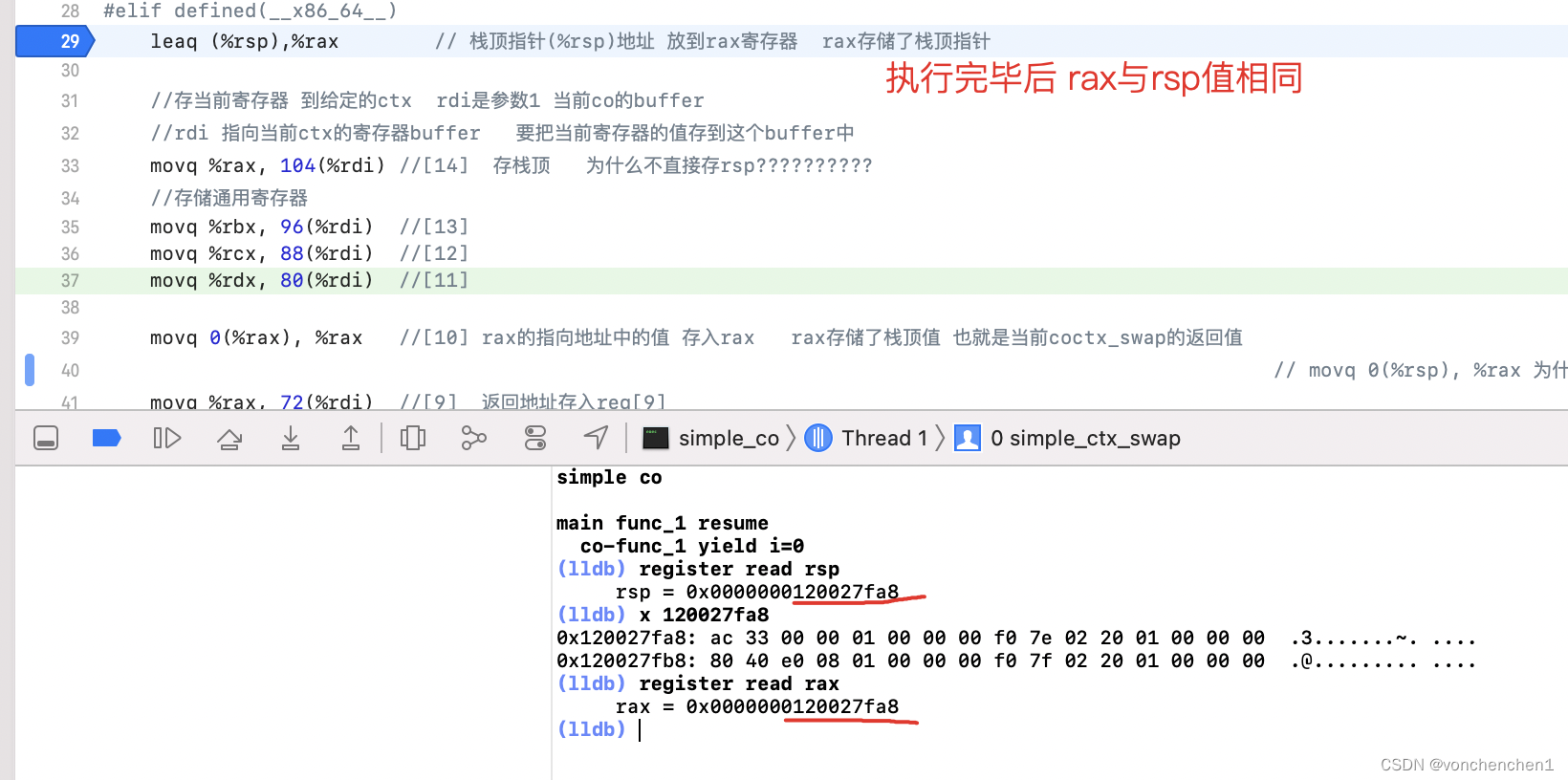
存储栈顶指针及栈顶值

这里看到, movq %rax, 104(%rdi) 将rax存储到rdi指向地址偏移104 byte,相当于栈顶置针rsp的值被存储到 缓存buffer的reg[14]。
movq 0(%rax), %rax 这句话把rax地址 0x120027fa8 中的值赋值给rax,也就是执行完这句话后,rax中的值变为 0x01000033ac。这里读一下寄存器,发现这个值指向一个地址,也就是我们说的程序返回地址。这个demo中所有的协程跳转都依赖于这个操作。读取一下rax,程序的代码地址就显示出来了,这里是 simple_co.c的130行。

看一下 ,这个地址就是我们执行完simple_ctx_swap的位置。
3.3.恢复程序地址以及上下文
下面放行这个程序,yield当前协程,直到下一次swapcontext调度到这个协程。

恢复栈
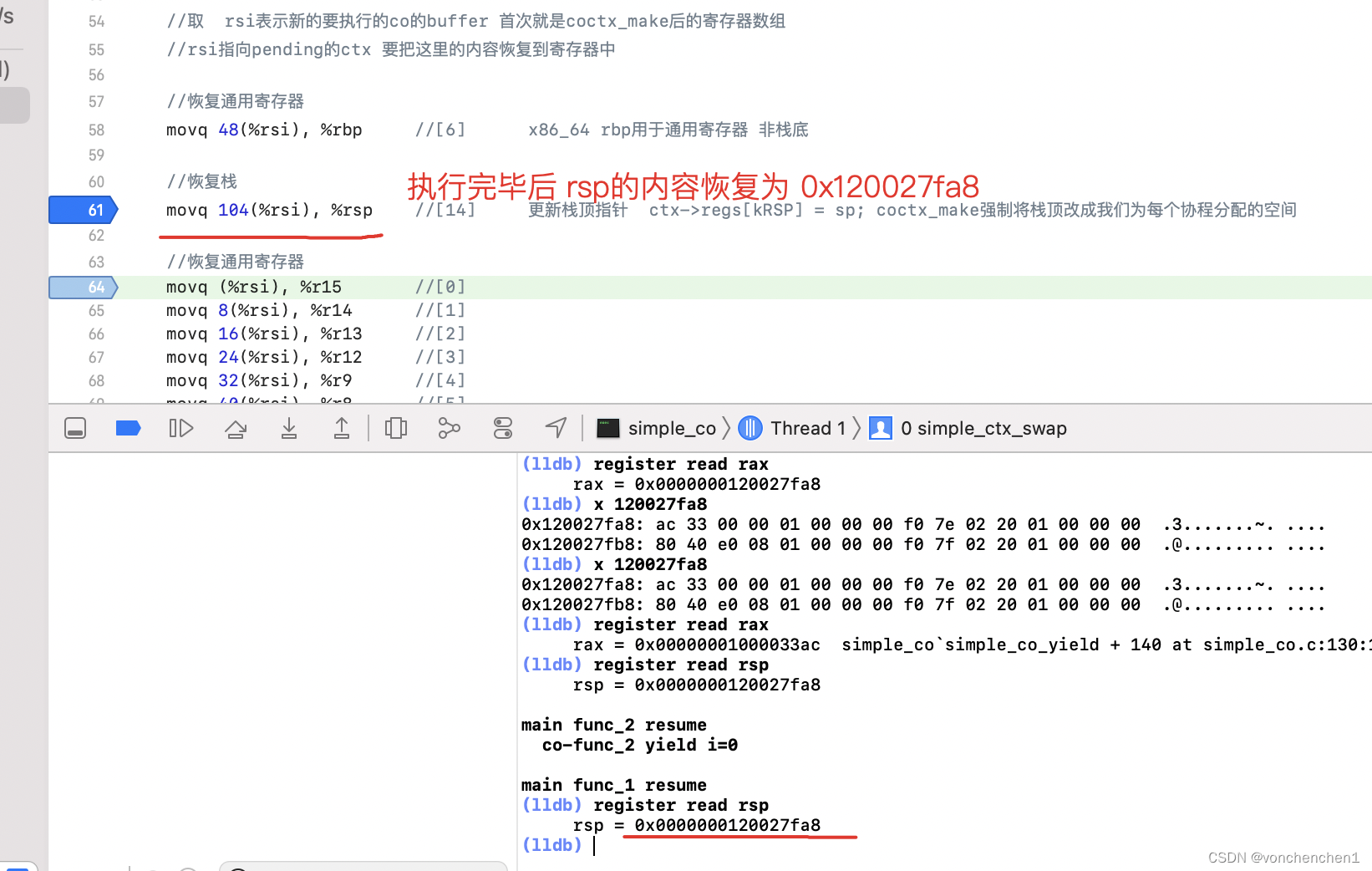 上文存储的栈指针在buffer偏移104的位置,这里将偏移104位置的值移动到栈顶指针,此时协程栈顶位置已经恢复。
上文存储的栈指针在buffer偏移104的位置,这里将偏移104位置的值移动到栈顶指针,此时协程栈顶位置已经恢复。
这一步恢复返回地址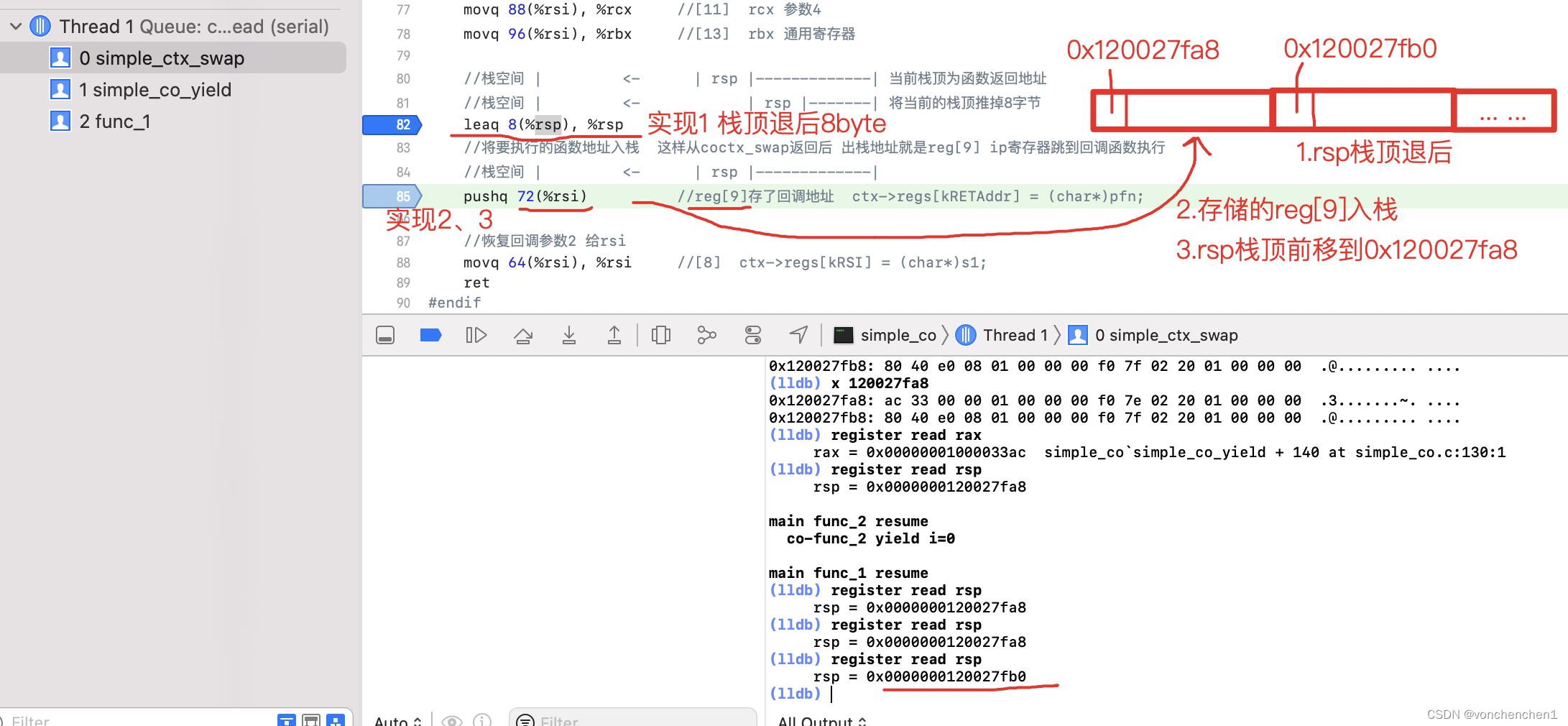
之前压入的返回地址存储的位置在 0x120027fa8,内容是0x01000033ac,也就是 simple_co.c的130行。这里把当前栈后退一格,把0x01000033ac push到栈顶,这样这个函数退出后,程序执行的位置就到了simple_co.c的130行。
下图是libco寄存器buffer的内存分布,有颜色的部分是本节上文提到需要操作的部分,其他寄存器和buffer内存直接存取即可恢复环境。
4.实现简单协程框架
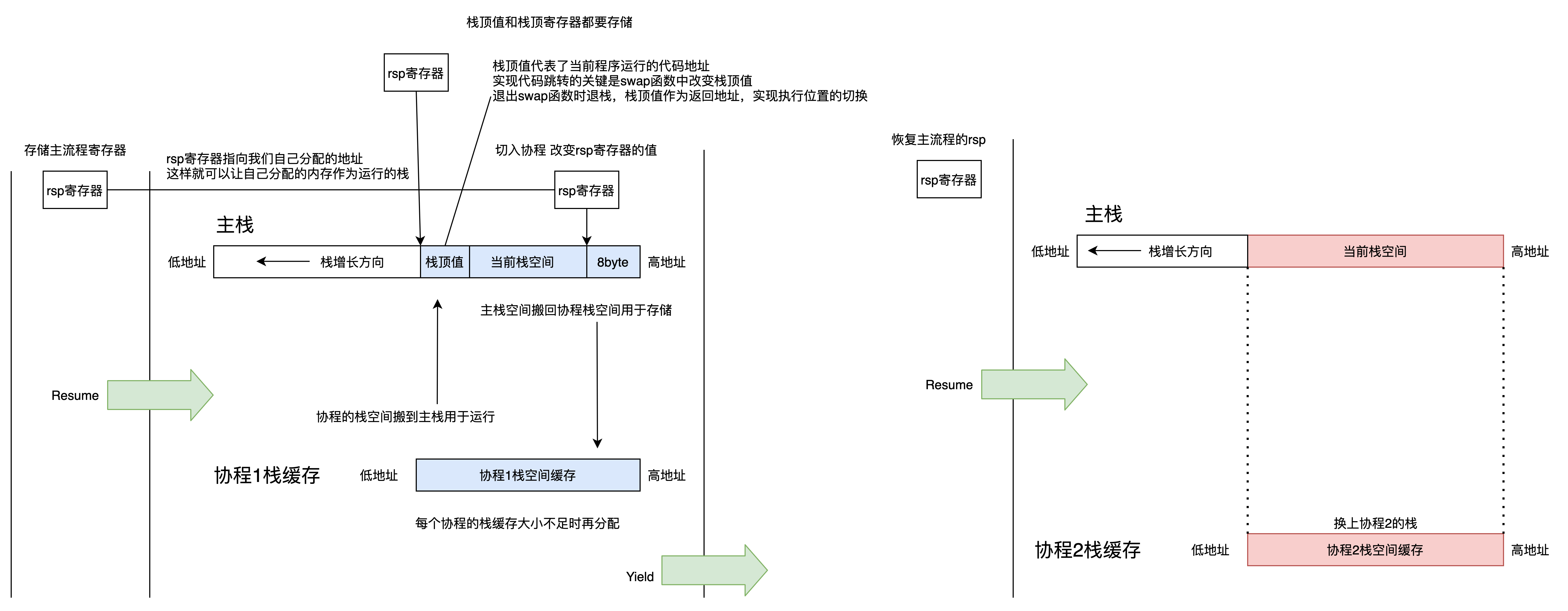
上图是demo中实现协程框架的原理,寄存器和栈切换的过程上文已经有较多的描述。下面说说demo中栈内存的分配与拷贝情况。
4.1栈内存管理
前提条件,主流程使用的是线程提供的栈空间,不是我们分配的,我们不直接操作这个栈。
1.对每个协程而言,运行使用的栈内存是一个公共的主栈,每次协程切换完环境后都要在主栈运行。
2.每个协程有自己的栈缓存,用于协程切出时保存当前主栈的内容,协程切入是恢复当前主栈的内容。这就需要切换协程时拷贝栈内存。
3.如何确认当前栈的长度?定一个临时变量dummy,&dummy就是下一行代码前的栈顶,栈底我们自己分配的内存自己可以根据内存长度获取,&dummy - 栈底的内容就是当前栈空间。
具体可以参考这段代码,在当前协程yield前,调用,将当前栈存储在协程的私有空间中
/*** @brief 保存当前执行状态 用于当前协程yield* 使用ucontext 在这里分配每个协程的堆栈* @param co * @param top */
static void _save_stack(simple_coroutine *co, char* top){//top = co->sched->stack + co->sched->stack_size;//dummy 的地址为当前函数_save_stack 重要// 程序执行到 "char dummy = 0;"时 sched中存储当前执行的栈的情况// |sched->stack|....| | top | // 低地址 |&dummy| <- 栈增长 - |sched->stack + sched->stack_size| 高地址// | co->stack_size |// |<----- SIMPLE_MAX_STACKSIZE ---->|////LOGI("_save_stack top=%p \n", top);char dummy = 0;//检查栈顶确认没有越界 top主栈最高地址 当前主栈栈顶&dummyassert(top - &dummy <= SIMPLE_MAX_STACKSIZE);//确保当前co的stack有足够的空间存储 当前执行栈的内容 //栈在高地址 向低地址增长 &dummy就是当前栈的首地址if (co->stack_size < top - &dummy) {//初始值为0 首次运行的co在这里分配栈空间co->stack = realloc(co->stack, top - &dummy);assert(co->stack != NULL);}// 执行完 memcpy 后每个协程co的栈保存了当前运行栈sched->stack// 等待下次执行时恢复// |co->stack|// |&dummy| <- 栈增长 - |sched->stack + sched->stack_size|co->stack_size = top - &dummy;memcpy(co->stack, &dummy, co->stack_size);//LOGI("_save_stack top=%p &dummy=%p co->stack_size=%d\n", top, &dummy, co->stack_size);
}
4.加载栈内存
在resume时加载栈内存。将协程co存储的栈,拷贝到主运行栈中。此时co中SP指针指向的应该就是真个栈的栈顶。栈内存和栈寄存器是分开恢复的。
// sched->stack_size 初始化的时候已经写死这个运行栈的长度// |sched->stack| <----- sched->stack_size ----> | // |sched->stack| <- 增长方向 | co->stack_size(准备执行栈内存) |// 当前执行栈 sched->stack 的内容变为co中栈的内容 这样下一步又开始执行co的上下文// |sched->stack| | co->stack_size(准备执行栈内存) |//将运行的协程memcpy(co->sched->stack + co->sched->stack_size - co->stack_size, co->stack, co->stack_size);co->status = SIMPLE_CO_STATUS_RUNNING;//char top;//LOGI("before simple_ctx_swap top=%p \n", &top);//当前参数保存到sched->ctx 执行co->ctx
#ifndef SIMPLE_SWAPswapcontext(&sched->ctx, &co->ctx);
#elsesimple_ctx_swap(co->sched->ctx.regs, co->ctx.regs);
#endif4.2 封装切换api
makecurrent实现
这里只保存函数执行地址,参数和栈地址。在swap的时候将这些值给对应寄存器
void simple_ctx_makecontext(simple_ctx *ctx, simple_ctx_func func, void* arg){//低 | <- |sp| | 高 栈顶指针指向协程堆栈的最高地址// | 8字节 |char *sp = ctx->ss_sp + ctx->ss_size - sizeof(void*);//对齐sp = (char*)((unsigned long)sp & -16LL);ctx->regs[kRSP] = sp;ctx->regs[kRETAddr] = func;ctx->regs[kRDI] = arg;
}swapcurrenet
上文汇编代码 simple_ctx_swap
至此,简单协程切换框架就完成了。
demo下载地址
https://download.csdn.net/download/lidec/87780929