©PaperWeekly 原创 · 作者 | 崔万云、蔡树阳
单位 | 上海财经大学
研究方向 | 大语言模型
2023 年 5 月,《纽约时报》报道了一位经验丰富的律师 Steven A. Schwartz 在对一家航空公司的诉讼中使用了 ChatGPT 生成的六个案例。尽管 ChatGPT 确认这些案例真实无误,但法官 Castel 发现所有案例均包含错误的引述和内部引用。这可能会导致 Schwartz 受到处罚。这成为了 AI 生成内容滥用的典型案例。
ChatGPT 为社会创造了巨大价值,但同时也引发了一系列紧迫问题。AI 生成的内容可能含有错误、侵犯性、偏见,甚至泄露个人隐私。ChatGPT 滥用可能涉及教育、医疗、学术等多个领域,甚至大规模语言模型训练本身也可能受到 AI 生成内容的负面影响。
2019 年的一份 OpenAI 报告显示,人类很难分辨一篇文章是由 AI 还是人类所写,而且容易轻信 AI 生成的内容。因此,研究者们已将自动化检测方法应用于区分人类生成和 AI 生成的内容。
这些检测方法通常基于人类生成和 AI 生成内容之间的分布差异。然而,上海财经大学崔万云研究团队的发现挑战了关于分布差异的传统理解。他们发现,检测器并非主要依赖语义和风格方面的差异。研究者揭示,检测器实际依赖细微的内容差异,如额外的空格。论文提出了一个简单的规避检测策略:在 AI 生成的内容中,随机在一个逗号前添加一个空格字符(如图 1 所示)。这一策略显著降低了白盒和黑盒检测器的检测率。对于 GPTZero(白盒)和 HelloSimpleAI(黑盒)检测器,AI 生成内容的检测率从约 60%-80% 降至几乎 0%。
这些发现强调了研究开发更强大、更可靠检测方法的重要性,以应对AI生成内容所带来的挑战和风险。在技术不断发展的今天,我们需要更好地确保AI的安全和可靠性,为社会带来真正的价值。

论文链接:
https://arxiv.org/pdf/2307.02599

Space Infiltratione
作者提出了一种空格字符攻击方法,用以规避 AI 内容检测器。具体来说,该方法在文本中的一个随机逗号前添加一个空格字符。例如,在图 1 中,对于问题"描述原子的结构",首先使用 ChatGPT 生成一个回答。这个的回答很可能被检测为AI生成的。然后使用 SpaceInfi 策略,在一个随机逗号前添加一个新的空格。在这种情况下,'charge,' 变成了 'charge⎵,'。这会使该回答有很高的概率被检测为人类生成的。
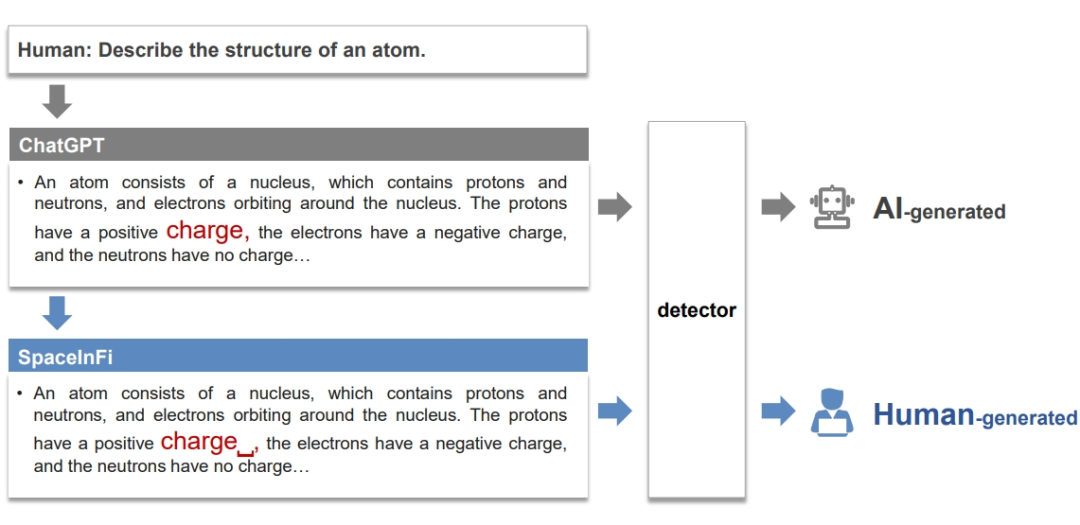
▲ 图1:为了规避检测器,SpaceInfi 在 ChatGPT 生成的内容中随机选择的逗号前添加了一个空格字符
除了简单,该方法还具有以下特性:(1)免费,无需额外成本;(2)无质量损失,不易被察觉。新的文本具有与原始文本相同的质量。由于修改只涉及增加一个空格,因此不易被人类察觉,因而不降低质量。(3)攻击与模型无关,不需要知道 LLMs 或检测器的内部状态。在论文中,这种策略被称为 SpaceInfi。

实验
2.1 Baselines
除了 SpaceInfi,论文还考虑了以下几个 baselines。
(像人一样回答)Act like a human:首先,论文感兴趣的是 ChatGPT 是否知道如何自行躲避检测。该策略明确指示 ChatGPT 像人类一样做出反应,并试图避免被检测器检测到。具体来说,使用的提示如下:
Question: QUESTION
Requirement: Answer the question like a human and avoid being found that the answer was generated by chatGPT.
(风格迁移)Style transfer:ChatGPT 能根据不同的角色切换不同的回答风格,使得它们的分布也不同。由于检测器利用 AI 生成和人生成内容之间的分布差异,论文利用回答风格生成不同的分布,从而研究是否可以通过切换风格制造分布差异,来躲避检测器。研究者考虑了三种不同风格的转换,按照它们的强度排序如下:口语风格,俚语风格,莎士比亚风格。目标是通过风格的强度控制分布差距的程度,从而验证分布差距和检测器性能之间的关系。完整的 prompt 如下:
Question: QUESTION
Requirement: Using more colloquial expressions in the response.
Question: QUESTION
Requirement: Answer the question in slang style.
Question: QUESTION
Requirement: Answer the question in Shakespearean style.
2.2 实验设定
Benchmarks:
Alpaca[17] 是一个基于 ChatGPT 和 self-instruction [21] 生成的 instruction 数据集。它最初由 175 个种子 instructions 组成,并扩展到使用 ChatGPT 的 52k 个 instructions。在扩展过程中,Alpaca 旨在确保问题集的多样性。实验中随机选择了 100 个 instructions 作为测试集。
Vicuna-eval 是 Vicuna [2] 使用的测试集。它包含 80 个问题,涵盖了九个类别,如写作,角色扮演,数学,编程和知识。这些问题比 Alpaca 更加多样化。该数据集被用来来验证 SpaceInfi 在更多样化的问题和回答上的效果。
WizardLM-eval 是 WizardLM [23] 使用的测试集。这个测试集包括 218 个道具有挑战性的题目,涵盖了面向用户的各种指令,包括高难度的编码生成和调试、数学、推理、复杂格式、学术写作和广泛的学科。
Alpaca-GPT4 [13] 是 Alpaca 的 GPT-4 版本,被认为具有更高的质量。这个 Benchmark 被用来验证 SpaceInfi 对 GPT-4 生成文本的影响。
评估指标:实验使用 ChatGPT(turbo-3.5)为 Alpaca、Vicuna-eval 和 WizardLM-eval 数据集生成回答。通过不同的规避检测策略,获取 ChatGPT 生成的文本。对于 Alpaca-GPT4,则直接使用其发布的 GPT-4 回答 [13],然后应用 SpaceInfi 策略。在收集到所有回答之后,要求每个检测器将这些回答分类为 AI-generated 或 human-generated。为了评估规避策略的性能,统计使用 AI 生成的文本被识别为 human-generated 的比例,被称为规避策略的规避率。
检测器:论文研究了一些已公开的 ChatGPT 检测器 [7, 12, 18,19]。截至 2023 年 6 月 16 日,公开的检测器包括 GPTZero、HelloSimpleAI 和 MPU。
GPTZero [18] 是一个依赖于文本统计信息的白盒检测器。其检测基于文本的困惑度(perplexity)和突发度(burstiness)。复杂度度量文本的随机性,而突发度量化复杂度的变化。实验使用了 GPTzero 为 ChatGPT 定制的版本。
HelloSimpleAI[7] 是一个基于分类器的黑盒检测器。它使用 AI 生成的文本和人类生成的文本来训练一个使用 RoBERTa 的文本分类器。实验使用了它的英文版本。
MPU[19] 是一个基于多尺度正向-未标记(MPU)框架的 AI 文本检测器。它将文本分类视为正向未标记(PU)问题。实验使用了它的英文版本。
2.3 结果
图 2 中展示了不同 baselines 和检测器的结果。
SpaceInfi 在所有基准以及 ChatGPT-3.5、GPT-4 上都表现出了很好的性能。在四个数据集上,SpaceInfi 展现出了出色的规避性能。对于 GPTZero 和 HelloSimpleAI,原始的 no-prompt 策略的规避率约为 20%。使用 SpaceInfi 后,规避率接近 100%。这证明了在 SpaceInfi 中添加一个空格字符可以规避 ChatGPT 的检测器。作者还观察到 SpaceInfi 无法规避 MPU 的检测。
ChatGPT 本身并不知道如何规避检测。作者观察到,act-like-a-human 策略并没有增加被识别为人类生成内容的比例。相反,在大多数情况下,内容更有可能被识别为 AI 生成的。这表明 ChatGPT 本身并不具备逃避检测的能力。这一观察结果是符合预期的,因为 ChatGPT 的训练语料库并不包含如何逃避检测的知识。
通过风格来制造分布差异规避检测需要强烈的风格转换。如图 2 所示,在大多数情况下,相对温和的口语风格并不能明显提高规避率,需要使用更强烈的俚语或莎士比亚风格才能有效规避检测。显然,风格越强烈,人类就越难接受其内容。俚语和莎士比亚风格在现实生活中几乎是不可被接受的。因此,在实际应用中,通过风格切换来规避检测并不可行。
与通过风格转换来产生分布差异相比,通过 SpaceInfi 产生微小差异能规避检测更为有效。显然,只插入一个空格字符的 SpaceInfi 策略对回答内容几乎没有影响。另一方面,即使是最轻微的口语风格表达也会对文本(例如词分布)产生明显影响。因此,通过 SpaceInfi 产生分布差异比通过风格转换更有效。表 1 中提供了更详细的案例分析。

▲ 图二:不同 benchmark 和检测器的结果。检测进行于于 2023 年 6 月 16 日。
2.4 规避策略对生成内容的影响
表 1 展示了具体使用不同策略生成的文本示例。这些文本揭示了 ChatGPT 检测器的一些有趣行为。
首先,检测器未能利用明确的语义信息进行检测。注意到 no-prompt 和 SpaceInfi 的回答都包含 "As an AI language model"。有趣的是,SpaceInfi 策略仍然成功规避了检测器。这证实了检测器对内容的语义不敏感。因此,检测器不依赖于语义差距来区分人类生成和 AI 生成的内容。

▲ 表1:不同规避策略生成的内容。
其次,不同策略对回答的质量有不同的影响。显而易见,只添加了一个空格的 SpaceInfi 策略不会影响原始回答的质量。实验中也没有发现 act-like-a-human 策略对回答质量有明显影响。然而,style transfer 策略确实会影响回答的质量。尽管答案仍然正确,但其表述的可接受性却降低了。随着 style 的加强,回答格式的可接受性也会下降。根据内容来看,SpaceInfi 是唯一保持了回答质量和规避率的策略。

解释
SpaceInfi 为什么有效?
以往的研究认为,检测器拥有分类效果是因为它们识别出了 AI 生成的内容与人类生成的内容之间的差异。而作者则发现 SpaceInfi 在极小的分布差距(即单个空间)上成功躲过了检测器的检测,这一点非常有趣。本节将针对不同类型的检测器解释这一现象,包括白盒检测器(即 GPTZero)和黑盒检测器(即HelloSimpleAI)。
为什么 SpaceInfi 对基于困惑度的 GPTZero 有效?作者从困惑度的数学公式来解释原因。困惑度是衡量语言模型对自然语言句子的预测能力的指标。句子的困惑度计算公式如下:

在这里, 表示句子,由单词 组成, 是句子中的单词数。 表示给定前面 个单词的条件下,单词 的条件概率。
由于 SpaceInfi 插入了一个额外的空格,困惑度包含了一个项

假设 AI 生成的文本总是格式良好的。在计算困惑度时,这些文本不存在多余空格的情况。因此,⎵。这最终导致 Perplexity(W) 的值较高,从而使检测器认为该文本不是人工智能生成的。
这解释了为什么 SpaceInfi 适用于基于困惑度的 GPTZero。这也揭示了为什么基于困惑度的检测器的鲁棒性较低:可以轻松地修改 AI 生成的文本以获得非常高的困惑度。
为什么 SpaceInfi 对基于分类器的 HelloSimpleAI 有效?
HelloSimpleAI 使用 RoBERTa 模型 [11] 作为分类器的主干。RoBERTa 因其强大的泛化能力而广为人知。因此,添加一个空格就改变分类结果似乎是违反直觉的。研究者认为在检测器的训练语料库中,AI 生成的内容和人类生成的内容都表现出高多样性。因此,基于明确的单词分布差距或语义差距进行检测是困难的。另一方面,一些典型的细微差异(例如 SpaceInfi 中添加的额外空格、小的语法错误等)是人类生成内容的独特其常见特征。因此,基于分类器的检测器将这些细微差别作为关键特征。这种行为模式,使得通过引入如 SpaceInfi 这样的细小扰动很容易规避检测器。
防御 SpaceInfi 攻击:有人可能会认为可以轻松防御 SpaceInfi,例如修剪输入文本中的空格。然而,事实上,SpaceInfi 可以轻易产生不同的变种。正如上面讨论的,SpaceInfi 的规避能力来自于细微差异。而这些细微差异可是各种形式的,而不仅仅是一个多余的空格。例如,随机添加一个句号或改变一个词的单数或复数形式。这些不同的策略都可以以极小的修改来规避检测。这样的变化是多样的,因此,对该策略及其变体的防御是具有挑战性的。

结论
本文的研究结果挑战了传统对人类生成和 AI 生成内容之间分布差距的理解,揭示了检测器可能并不主要依赖于语义和风格上的差异。
本文展示了一种简单的规避策略,即在 AI 生成内容中的随机逗号前添加一个额外的空格字符,这显著降低了检测率。实验在多个基准和检测器上验证了这一策略有效性。这些发现指出了在开放环境中开发有效的 AI 检测器所具有的挑战,并进一步促进未来更鲁棒、有效的 ChatGPT 检测器的开发。

参考文献
[1] Biyang Guo, Xin Zhang, Ziyuan Wang, Minqi Jiang, Jinran Nie, Yuxuan Ding, Jianwei Yue, and Yupeng Wu. How close is chatgpt to human experts? comparison corpus, evaluation, and
detection. arXiv preprint arXiv:2301.07597, 2023.
[2] Robin Jia and Percy Liang. Adversarial examples for evaluating reading comprehension systems. In EMNLP, 2017.
[3] Irene Solaiman, Miles Brundage, Jack Clark, Amanda Askell, Ariel Herbert-Voss, Jeff Wu, Alec Radford, Gretchen Krueger, Jong Wook Kim, Sarah Kreps, et al. Release strategies and the social impacts of language models. arXiv preprint arXiv:1908.09203, 2019.
[4] Edward Tian. GPTZero. Website, 2022.
[5] Yuchuan Tian, Hanting Chen, Xutao Wang, Zheyuan Bai, Qinghua Zhang, Ruifeng Li, Chao Xu, and Yunhe Wang. Multiscale positive-unlabeled detection of ai-generated texts. arXiv preprint arXiv:2305.18149, 2023.
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
·
·