用Python进行俄语文本的词频统计
如果你正在学习俄语或者需要处理俄语文本,词频统计是一个非常有用的工具。Python是一个非常流行的编程语言,对于数据处理和文本挖掘也有很好的支持。在本文中,我们将介绍如何使用Python处理俄语文本,并进行词频统计。
准备工作
在开始之前,我们需要安装一些必要的Python库。首先,我们需要安装 pandas 库来处理文本数据。你可以使用以下命令来安装:
pip install pandas
我们还需要一个叫做 nltk 的库来处理自然语言。你可以使用以下命令来安装:
pip install nltk
在安装完后,我们需要下载一些俄语特定的数据集来进行自然语言处理工作。我们可以使用以下命令来下载:
import nltknltk.download('punkt')
nltk.download('stopwords')
加载文本数据
要进行词频统计,我们需要有一些俄文文本数据。在这里,我们使用一个样例文本文件 sample.txt,你可以替换成自己的文件路径。我们可以使用以下代码来读取文本文件:
with open('sample.txt', 'r', encoding='utf-8') as f:text = f.read()
文本预处理
在进行词频统计之前,我们需要对文本进行预处理。这个过程包括一些操作,如去掉标点符号、停用词以及将文本转换为小写字母。我们可以使用以下代码来进行文本预处理:
import string
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize# 去掉标点符号,并将文本转换为小写字母
processed_text = text.lower().translate(str.maketrans('', '', string.punctuation))# 分词
words = word_tokenize(processed_text)# 去掉停用词
stop_words = set(stopwords.words('russian'))
words = [word for word in words if word not in stop_words]
计算词频
我们现在拥有了准备好的文本数据,可以开始计算词频了。我们可以使用 pandas 库来创建一个词频数据框,方便我们进行词频统计:
import pandas as pd# 计算词频
word_freq = pd.Series(words).value_counts()# 将词频数据框转换为数据帧
df = pd.DataFrame({'words': word_freq.index, 'freq': word_freq.values})
展示结果
最后,我们可以使用 matplotlib 库来展示结果。以下是完整的代码:
import string
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
import pandas as pd
import matplotlib.pyplot as plt# 加载文本数据
with open('sample.txt', 'r', encoding='utf-8') as f:text = f.read()# 文本预处理
processed_text = text.lower().translate(str.maketrans('', '', string.punctuation))
words = word_tokenize(processed_text)
stop_words = set(stopwords.words('russian'))
words = [word for word in words if word not in stop_words]# 计算词频
word_freq = pd.Series(words).value_counts()
df = pd.DataFrame({'words': word_freq.index, 'freq': word_freq.values})# 展示结果
plt.figure(figsize=(20, 10))
plt.bar(df['words'][:50], df['freq'][:50])
plt.title('俄语文本的前50个高频词')
plt.xlabel('词语')
plt.ylabel('出现次数')
plt.xticks(rotation=90)
plt.show()
运行代码后,你将会得到一个展示前50个高频俄语单词的条形图。
结论
在本文中,我们介绍了如何使用Python进行俄语文本的词频统计。我们预处理了文本数据并使用 pandas 库创建了一个词频数据框。最后,我们使用 matplotlib 库展示了前50个高频词在俄语文本中的出现次数。通过本文的介绍,你现在可以更好地了解如何在Python中处理俄语文本并进行词频统计。
最后的最后
本文由chatgpt生成,文章没有在chatgpt生成的基础上进行任何的修改。以上只是chatgpt能力的冰山一角。作为通用的Aigc大模型,只是展现它原本的实力。
对于颠覆工作方式的ChatGPT,应该选择拥抱而不是抗拒,未来属于“会用”AI的人。
🧡AI职场汇报智能办公文案写作效率提升教程 🧡 专注于AI+职场+办公方向。
下图是课程的整体大纲
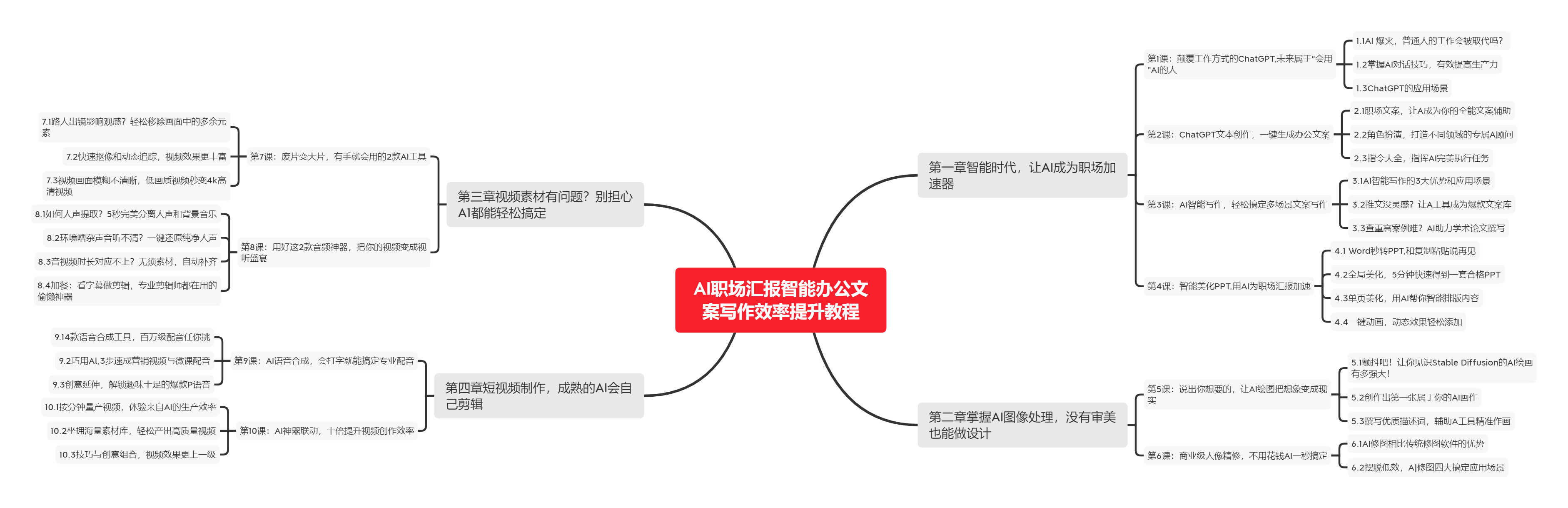

下图是AI职场汇报智能办公文案写作效率提升教程中用到的ai工具

🚀 优质教程分享 🚀
- 🎄可以学习更多的关于人工只能/Python的相关内容哦!直接点击下面颜色字体就可以跳转啦!
| 学习路线指引(点击解锁) | 知识定位 | 人群定位 |
|---|---|---|
| 🧡 AI职场汇报智能办公文案写作效率提升教程 🧡 | 进阶级 | 本课程是AI+职场+办公的完美结合,通过ChatGPT文本创作,一键生成办公文案,结合AI智能写作,轻松搞定多场景文案写作。智能美化PPT,用AI为职场汇报加速。AI神器联动,十倍提升视频创作效率 |
| 💛Python量化交易实战 💛 | 入门级 | 手把手带你打造一个易扩展、更安全、效率更高的量化交易系统 |
| 🧡 Python实战微信订餐小程序 🧡 | 进阶级 | 本课程是python flask+微信小程序的完美结合,从项目搭建到腾讯云部署上线,打造一个全栈订餐系统。 |




