复习: Transformer、GPT1 https://blog.csdn.net/Citroooon/article/details/130048167?spm=1001.2014.3001.5501
GPT2
论文
gpt1 + larger dataset + more params + zero shot
gpt2在预训练模型结构上几乎没有变化,用了更大的数据集、更大的模型:
· 新的百万级数据集WebText, 比之前Bert用的book Corpus和Wikipedia要更大;
· 15亿参数的transformer解码器模型,之前Bert large是3亿+
目前语言模型的通病是泛化能力、迁移能力差,在一个数据集上训练出来的模型很难用于其他任务。所以提出了zero-shot的思想:不需要下游任务标注的任何信息来训练模型, 直接用与训练的模型对子任务做预测
什么是prompt?提示
(translate to french, english text, french text)
(answer the question, documents, questions, answer)
GPT3
技术报告
- 模型参数:
175 billion param
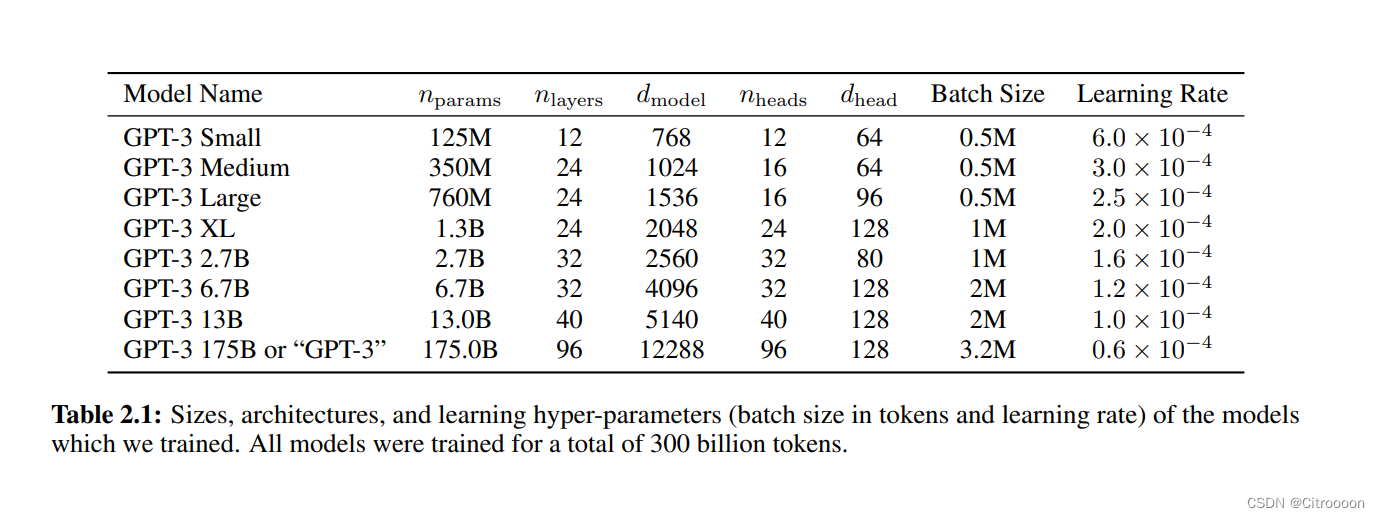
随着模型参数的增加,batch size增加,学习率下降 - 模型结构
预训练模型结构基本不变:GPT2 + Sparse Transformer
few shots : 给几个子任务的样本(10-100),模拟人类的学习,但是不做梯度更新和微调,而是通过给example的方式(in-context learning)。
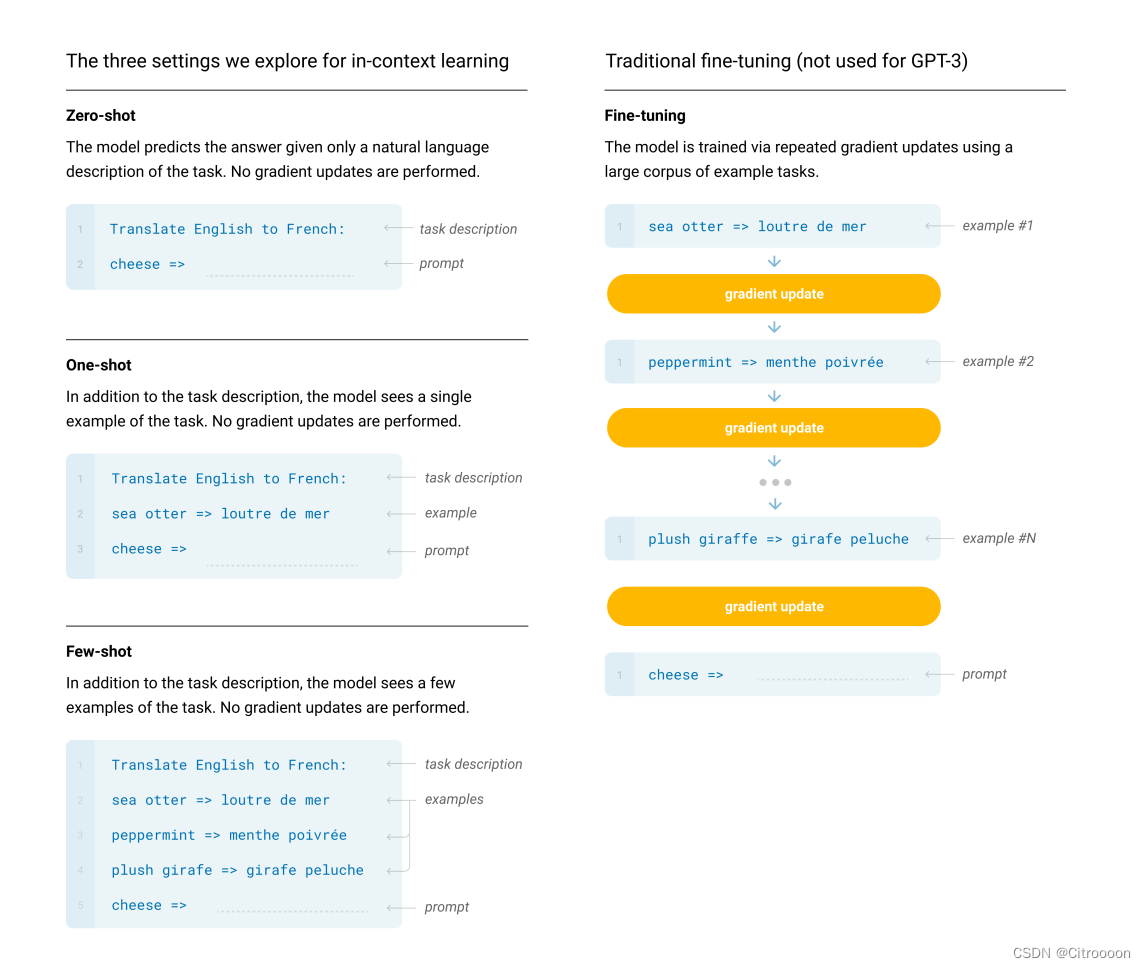
- 数据集:
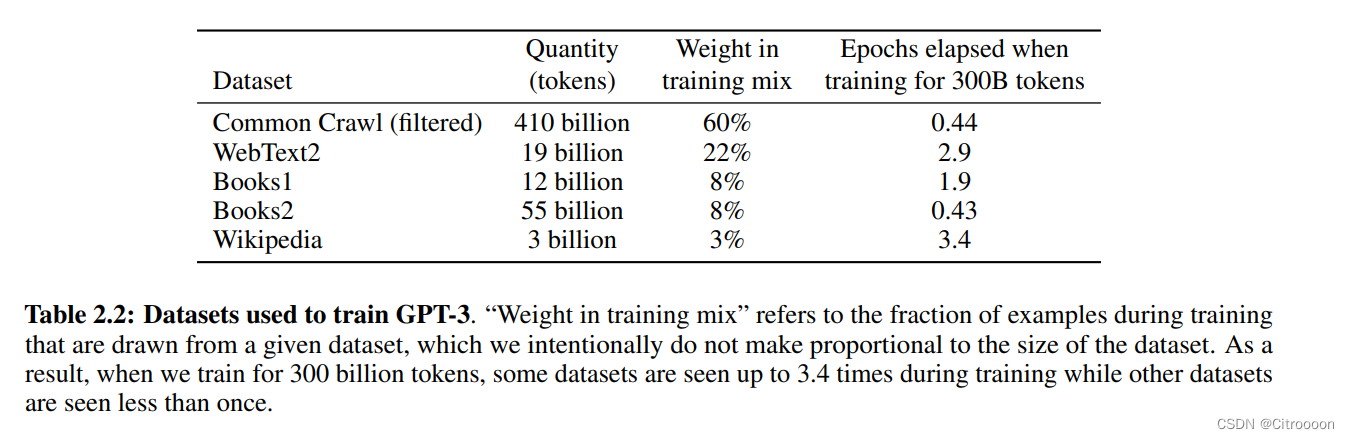
线性降低损失 需要指数增加数据量
- 局限性:
长文本生成的困难:很长的文本后面可能会重复前面的话
每一次预测下一个词重要性是均匀的
不可解释性
gpt是在历史训练数据中找出与问题相似的文本吗
InstructGPT(GPT3.5)
技术报告 训练语言模型以服从人类的指示
1.背景:
大语言模型的安全性 有效性还是有待提高,不能很好地和人类align(拉齐?), 会有一些toxic的回答。语言模型的loss是预测下一词的概率分布,这个与我们的目标是misalign的
-
核心方法:
fine-tuning with human feedback 强化学习, 人工标注了一个答案打分排名的数据集
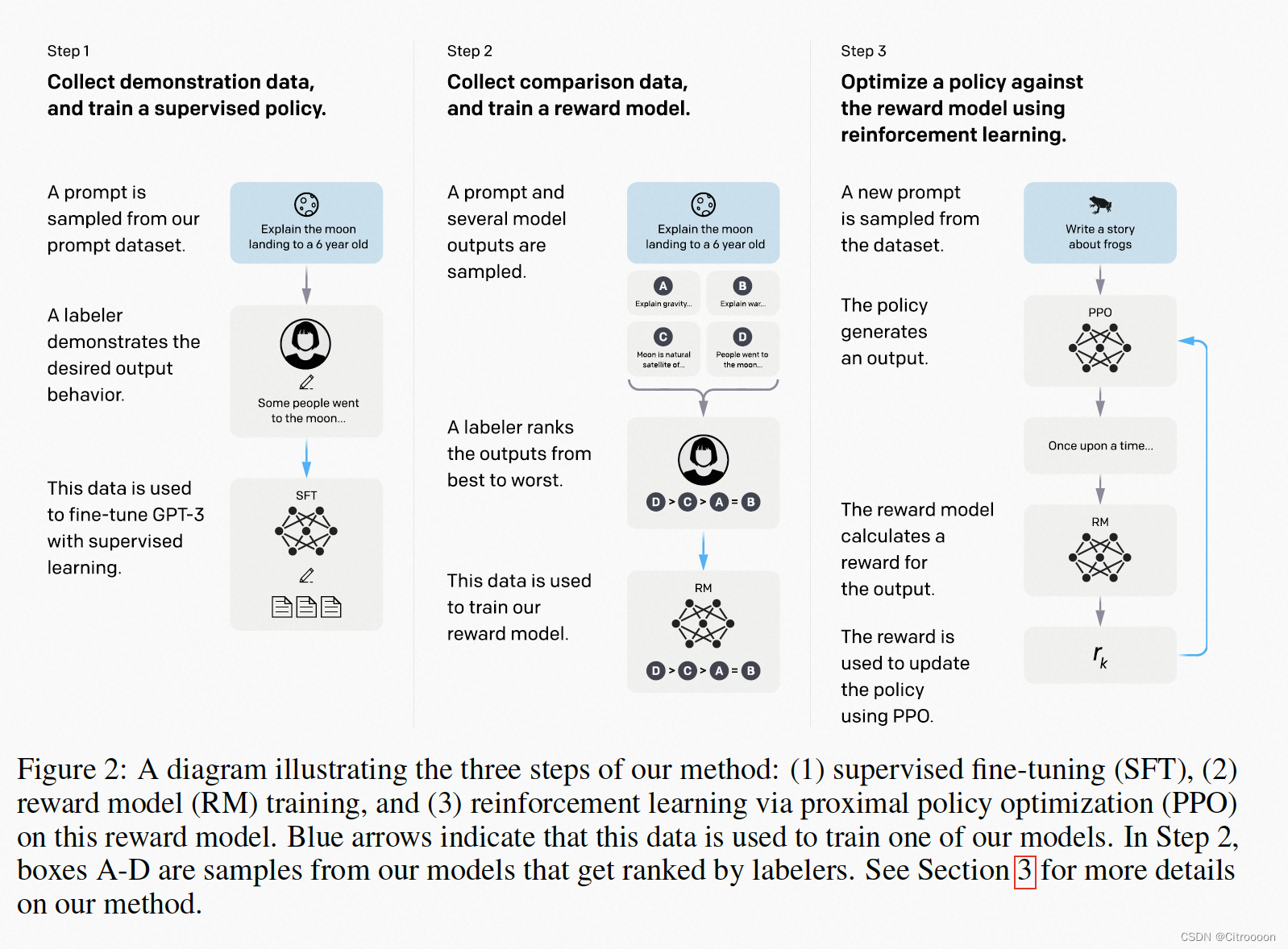
step1: SFT 有监督的微调,用人类的问题和人类写好的答案来微调GPT3 (这个在模型看来是和学习文本一样的)
step2: RM 奖励模型,把gpt生成的答案人工标注好坏的顺序
step3: RLPPO 让SFT生成的答案获得尽可能高的分数
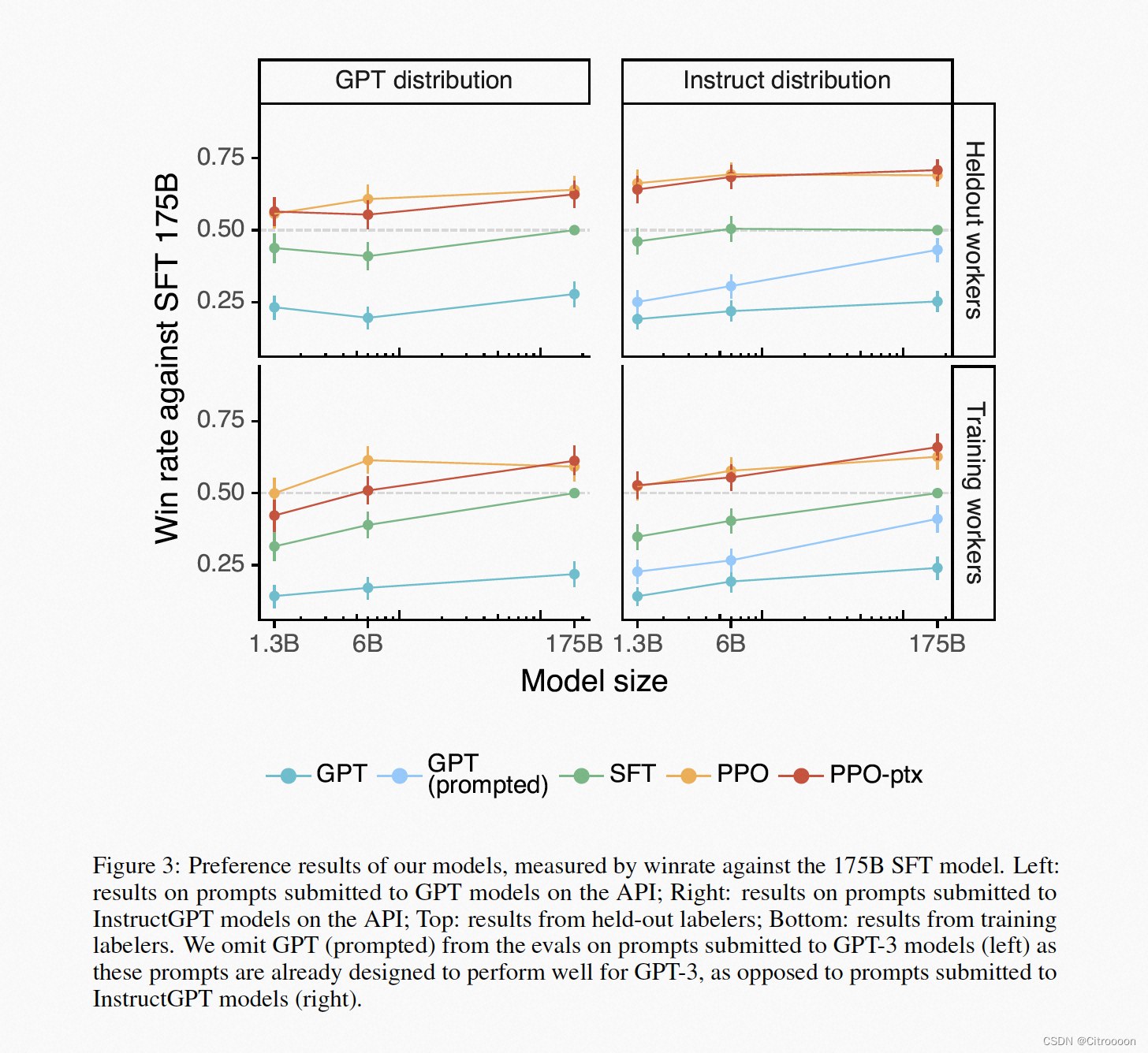
效果:instructGPT模型比GPT3小100倍,但是效果更好 -
如何标注的数据集:略
-
模型
SFT: 有监督的微调, 把GPT3的prompt重新训练一遍,过拟合也没关系
RM:排序问题的loss: pairwise ranking loss

K= 9 , 9 个答案,选出36个pair来计算loss
如果y_w比y_l的排序高,要最大化他们之间奖励分数的差距
RL: PPO目标函数

· prompt x 输入到 π R L \pi_{RL} πRL 输出reward y , 最大化这个reward ,policy参数会更新
· 最小化 π R L \pi_{RL} πRL 和 π S F T \pi_{SFT} πSFT 的KL散度,不要让更新跑太远
· γ \gamma γ控制的是 模型要更偏向原始数据 D p r e t r a i n D_{pretrain} Dpretrain一些
- 效果