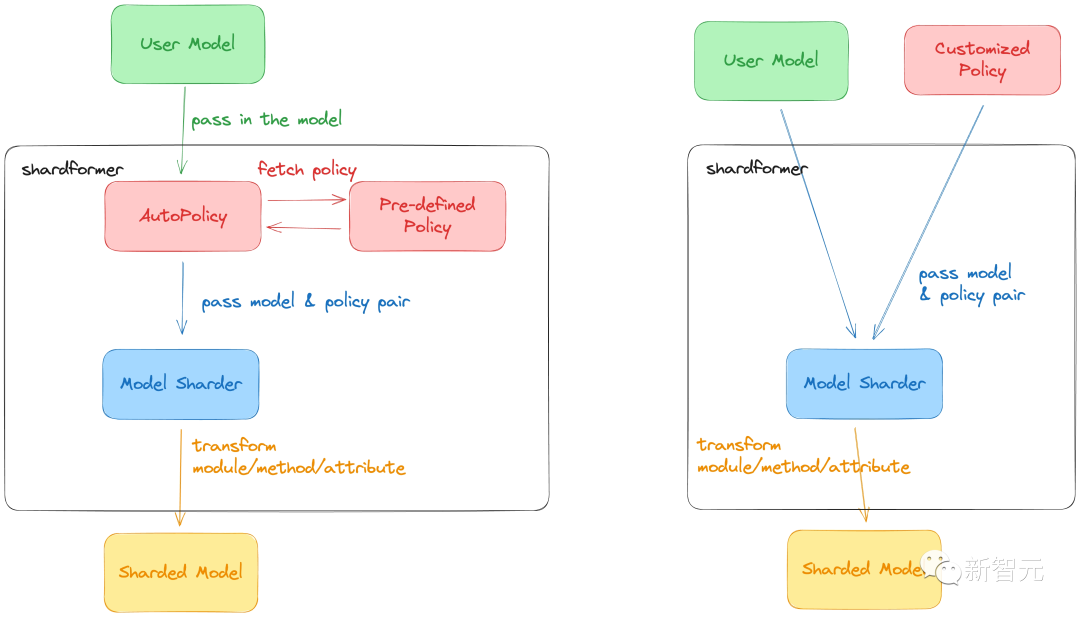
3. 分析好评与差评的关键信息
依靠绘制词云图,来分析好评与差评的关键信息的区别
数据预处理
依靠上一篇爬取到的csv文件,来进行分析,首先导入文件,重点是短评正文的信息。
首先是使用结巴库来进行分词,然后去除停用词(停用词是网上公开的,可以自己去找。
代码:
import pandas as pd
import jiebadata = pd.read_csv("doubanliulangdiqiu.csv", encoding='GB18030') # 读取数据
with open('stopword.txt','r') as f:stopWords = f.read() # 读取停用词
stopWords = ["\n",""," "]+ stopWords.split() # 把可能用的停用词加载进去data_cut = data['短评正文'].apply(jieba.lcut) # 结巴分词
data_after = data_cut.apply(lambda x: [i for i in x if i not in stopWords])# 去除停用词
数据预处理结束
统计词频
使用list()把数据转换成列表,然后使用_flatten()来展平,使用pd.Series()来转换成序列,使用value_counts()统计频率
from tkinter import _flatten
pd.Series(_flatten(list(data_after))).value_counts()
绘制词云
把词频命名为wordFre,背景偷懒一下,直接导入一个图片进去
import matplotlib.pyplot as plt
from wordcloud import WordCloud
mask = plt.imread('aixin.jpg')
wc = WordCloud(font_path='simkai.ttf',# 设置字体mask=mask,background_color='white')
wc.fit_words(wordFre)
plt.imshow(wc) # 词云
plt.axis('off') # 关闭坐标
最后看看效果图

最后封装成函数:
def my_word_cloud(data=None.stopWords=None, img=None):data_cut = data.apply(jieba.lcut) # 结巴分词data_after = data_cut.apply(lambda x: [i for i in x if i not in stopWords]) # 去除停用词# 统计词频wordFre = pd.Series(_flatten(list(data_after))).value_counts()# 设置背景mask = plt.imread('aixin.jpg')wc = WordCloud(font_path='simkai.ttf',# 设置字体mask=mask,background_color='white')# 词云绘制wc.fit_words(wordFre)plt.imshow(wc) # 词云plt.axis('off') # 关闭坐标plt.show()
把评分三星以下为差评,三星及三星以上为好评,做个词云:
index_negative = data['评分'] < 30.0
index_positive = data['评分'] >= 30.0my_word_cloud(data['短评正文'][index_negative],stopWords,'aixin.jpg') # 差评词云
my_word_cloud(data['短评正文'][index_positive],stopWords,'aixin.jpg') # 好评词云
最后的词云: