![]()
随着更高生产力和更健康的人群寿命更长,医疗保健将成为社会最重要的方面之一。 COVID-19 大流行加速了现代技术的采用,并凸显了患者体验的重要性。 随着越来越多的消费者开始控制他们的数据,医疗保健系统变得捉襟见肘。 根据德勤和斯科茨代尔研究所发布的一项研究,92% 的医疗保健技术领导者将数字能力视为实现更好患者体验的途径。
在这篇博文中,我们将探讨 Elastic 的搜索功能如何帮助解决健康公平的潜在障碍,正如医疗保险和医疗补助服务中心 (CMS) 战略支柱中概述的那样 — 特别是如何向受益人提供医疗信息的相关结果英语水平有限,无法理解消费者正在搜索或询问的内容。
到最后,你将能够通过以实用的方式合并以下元素来开发自己的搜索应用程序:
- 应用自然语言处理 (NLP) 机器学习模型
- 在不增加存储空间的情况下使用语义搜索进行多语言查询
- 引入用户分析
- 调整分析以持续改善最终用户体验
使用 Elastic GitHub 存储库提供的代码,你无需费力编写代码 — 一切尽在其中! 此外,如果你想亲身体验,还有更多关于如何设置的详细信息。你可以使用如下的命令来下载代码:
git clone https://github.com/liu-xiao-guo/app-search-nlp-insurance在本演示中,我将使用最新的 Elastic Stack 8.5.4 来进行演示。
安装
Elasticsearch 及 Kibana
如果你还没安装好自己的 Elasticsearch 及 Kibana,请参阅如下的文章来进行安装:
- 如何在 Linux,MacOS 及 Windows 上进行安装 Elasticsearch
- Kibana:如何在 Linux,MacOS 及 Windows上安装 Elastic 栈中的 Kibana
请注意文章中的 8.x 的安装部分。由于使用 eland 上传模型是白金版或者是企业版的功能,在我们的演示中,我们需要启动白金版试用功能:


Eland
Eland 可以通过 pip 从 PyPI 安装。在安装之前,我们需要安装好自己的 Python。
$ python --version
Python 3.10.2可以使用 Pip 从 PyPI 安装 Eland:
python -m pip install eland也可以使用 Conda 从 Conda Forge 安装 Eland:
conda install -c conda-forge eland希望在不安装 Eland 的情况下使用它的用户,为了只运行可用的脚本,可以构建 Docker 容器:
git clone https://github.com/elastic/eland
cd eland
docker build -t elastic/eland .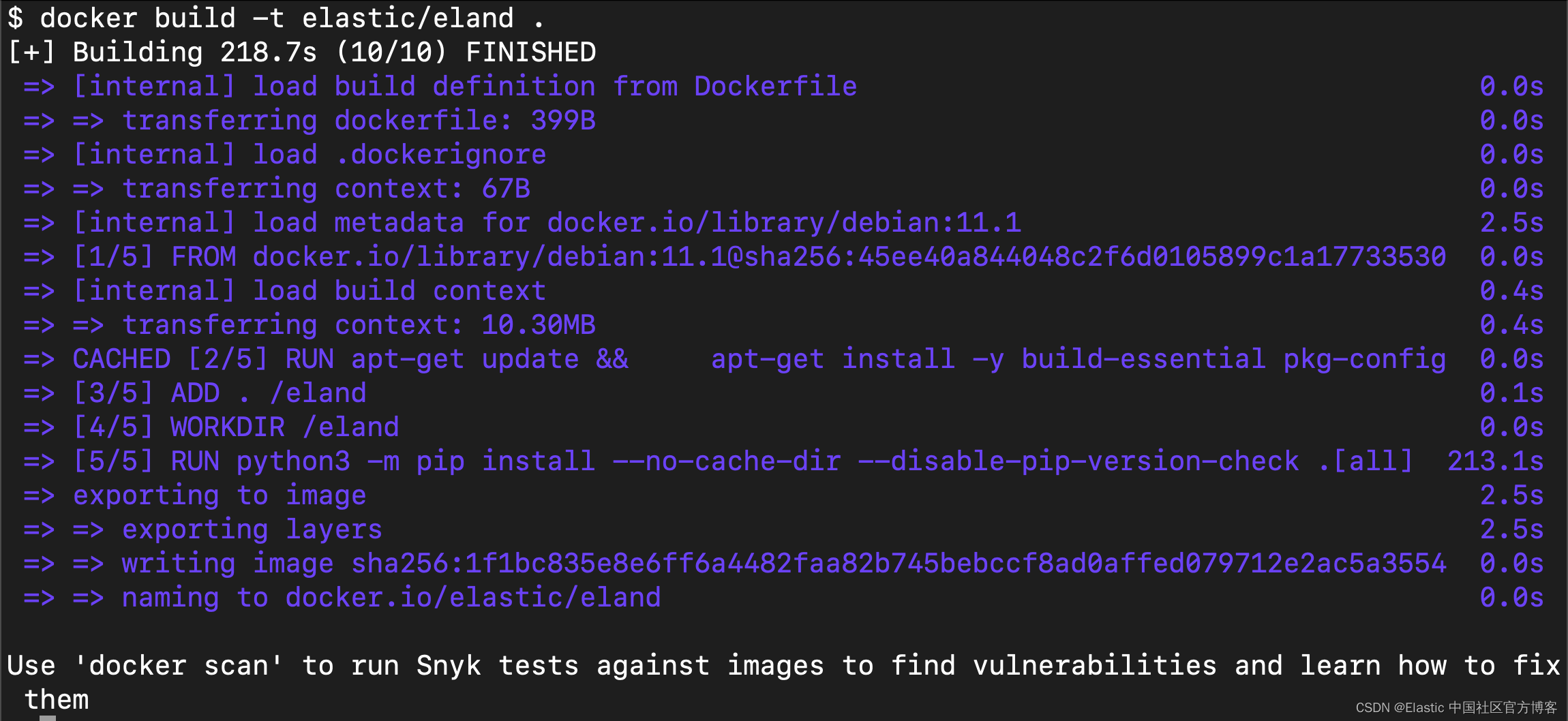
Eland 将 Hugging Face 转换器模型到其 TorchScript 表示的转换和分块过程封装在一个 Python 方法中; 因此,这是推荐的导入方法。
- 安装 Eland Python 客户端。
- 运行 eland_import_hub_model 脚本。 例如:
eland_import_hub_model --url <clusterUrl> \
--hub-model-id elastic/distilbert-base-cased-finetuned-conll03-english \
--task-type ner - 指定 URL 以访问你的集群。 例如,https://<user>:<password>@<hostname>:<port>。
- 在 Hugging Face 模型中心中指定模型的标识符。
- 指定 NLP 任务的类型。 支持的值为 fill_mask、ner、text_classification、text_embedding, question_answering 和 zero_shot_classification。
上传 QA model
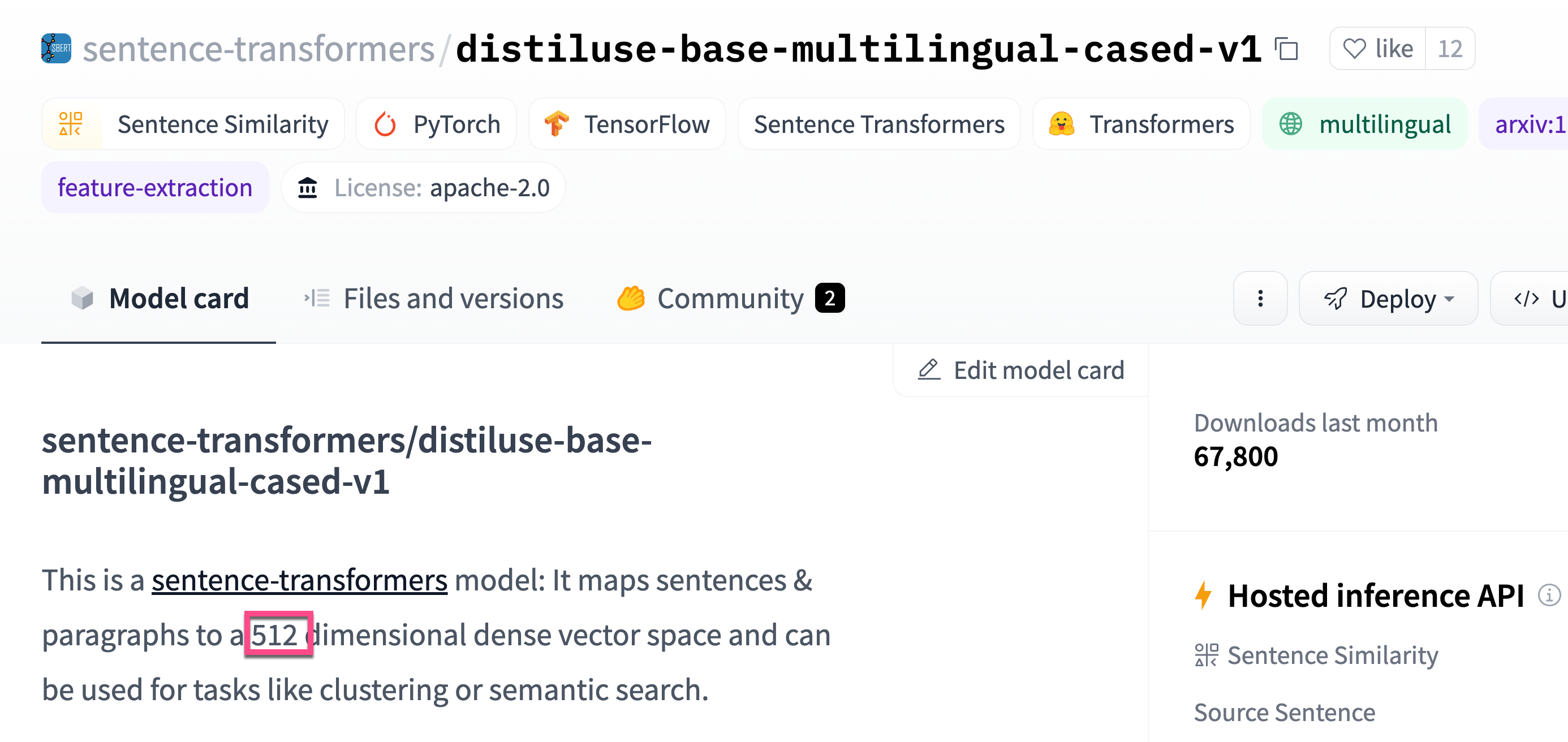
针对我们的用例,我们使用在 Models - Hugging Face 发布的 sentence-transformers/distiluse-base-multilingual-cased-v1 模型。根据介绍,这个 model 支持 Arabic, Chinese, Dutch, English, French, German, Italian, Korean, Polish, Portuguese, Russian, Spanish, Turkish 等语言。我们可以在网上进行搜索:
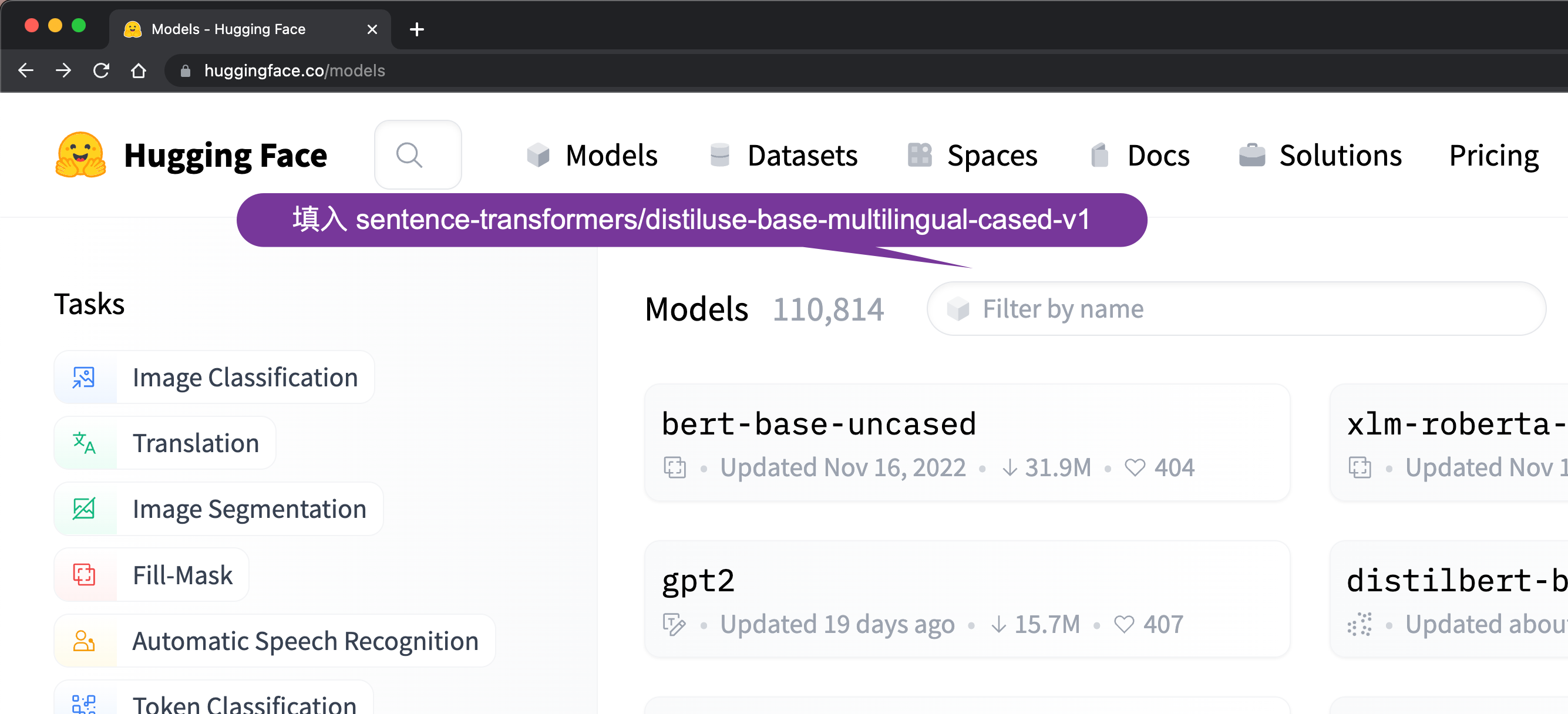
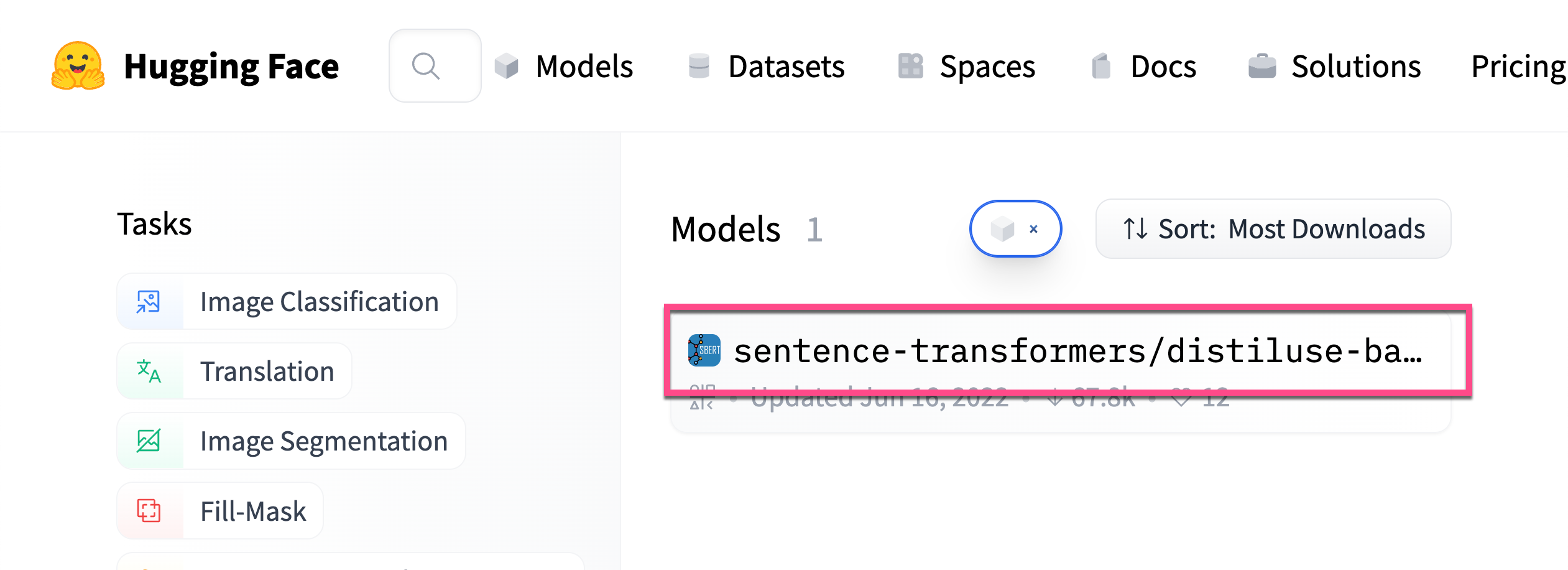
我们先做如下的一些练习来了解这个 model 是如何使用的:

我们输入的两个句子中,我们可以从输出的结果中看出来:I like Beijing a lot 和 Beijing is a wonderful place 更为匹配。 基本上这个是语义匹配。它和我们之前的那种文字匹配还是不一样的。这个是我们必须明白的一点。
接下来,我们来上传这个模型。打开我们的终端并使用我们的端点和 model 名称更新以下命令:
eland_import_hub_model --url https://<user>:<password>@<hostname>:<port> \
--hub-model-id <model_name> \
--task-type <task_type>针对我的情况,我使用如下的命令:
eland_import_hub_model --url https://elastic:7nb2W-HRb*DxTPN=Xi=K@localhost:9200 \--hub-model-id sentence-transformers/distiluse-base-multilingual-cased-v1 \--task-type text_embedding \--ca-cert /Users/liuxg/elastic/elasticsearch-8.5.3/config/certs/http_ca.crt \--start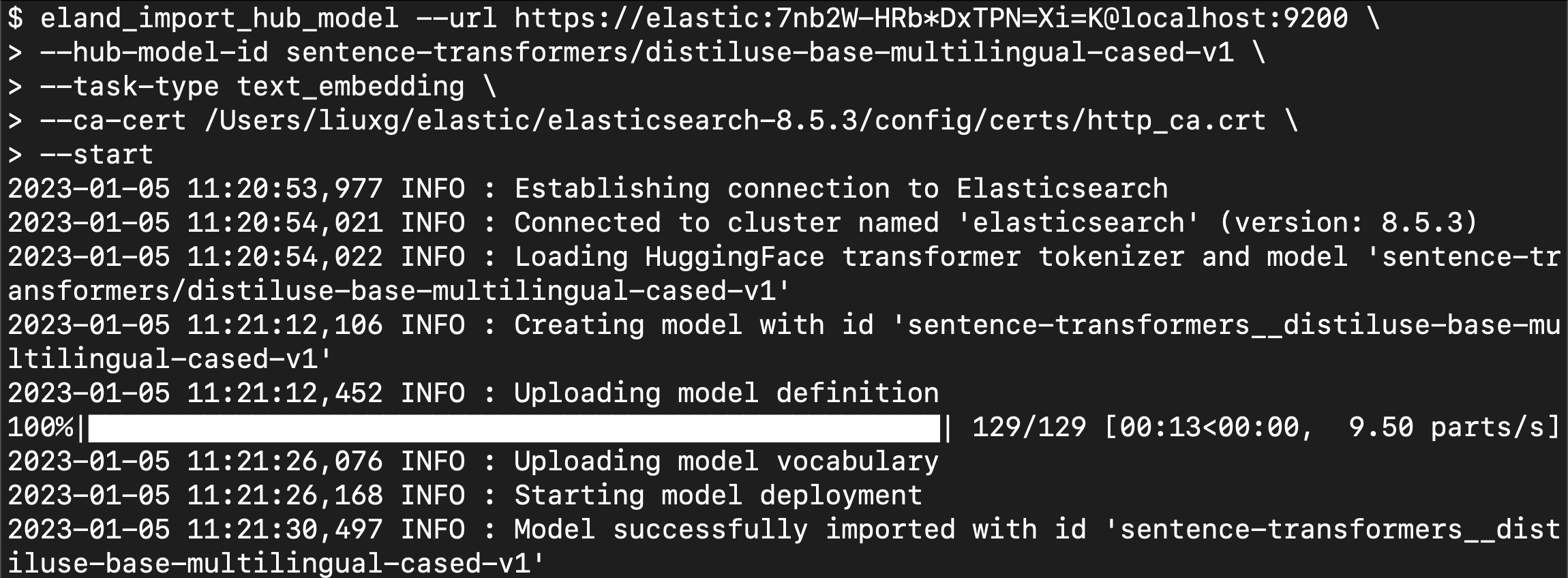
从上面,我们可以看出来 model 已经成功地上传到我们的 Elasticsearch 中了。
我们可以到机器学习的页面来进行查看:
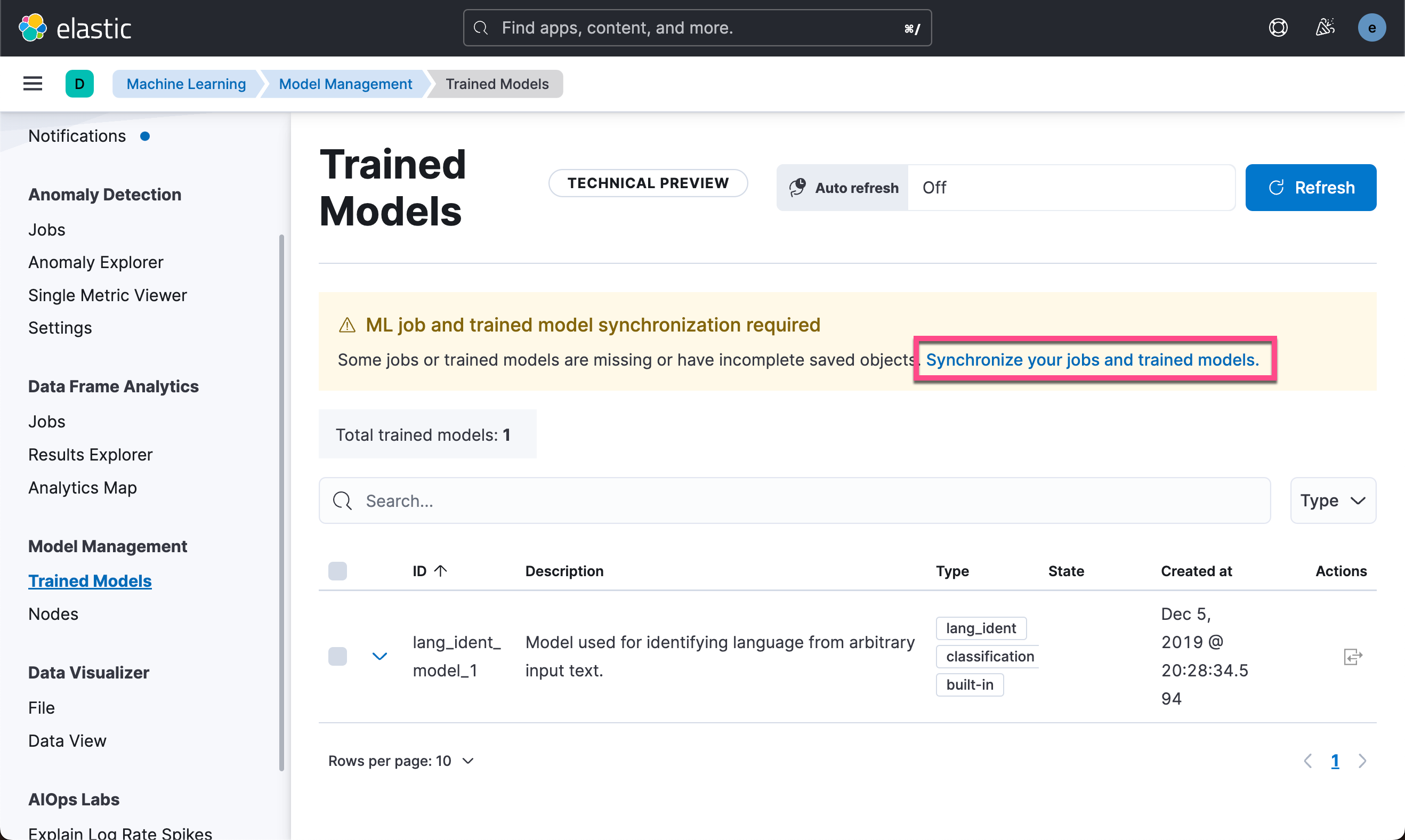

从上面的输出中,我们可以看到模型已经被上传并成功地启动了。
上传数据
在上面我们已经成功地上传了模型。接下来我们来上传数据到 Elasticsearch 中。我们打开之前下载的代码:
$ pwd
/Users/liuxg/demos/app-search-nlp-insurance
$ tree -L 2
.
├── LICENSE
├── README.md
├── back-end
│ ├── README.MD
│ ├── config
│ ├── package-lock.json
│ ├── package.json
│ └── server
├── front-end
│ ├── README.md
│ ├── angular.json
│ ├── package-lock.json
│ ├── package.json
│ ├── src
│ ├── tsconfig.app.json
│ ├── tsconfig.json
│ └── tsconfig.spec.json
└── insurance-questions├── README.MD└── insurance_corpus.csv从上面的输出中,我们可以看到一个叫做 insurance_corpus.csv 的文件。我们可以使用 Kibana 的 Upload a file 功能来进行上传。
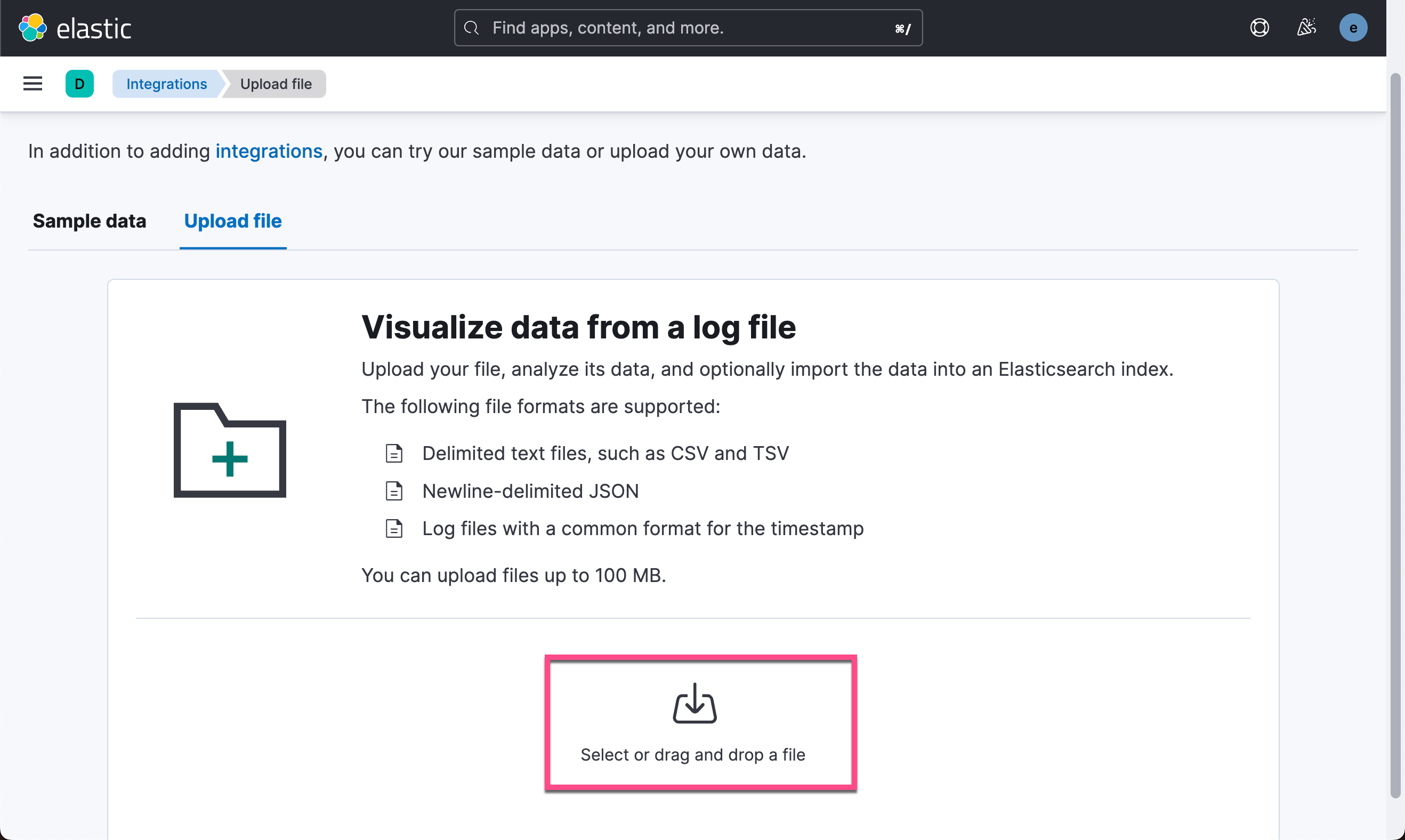
在上面,我们选择 insurance_corpus.csv 做为上传文件:

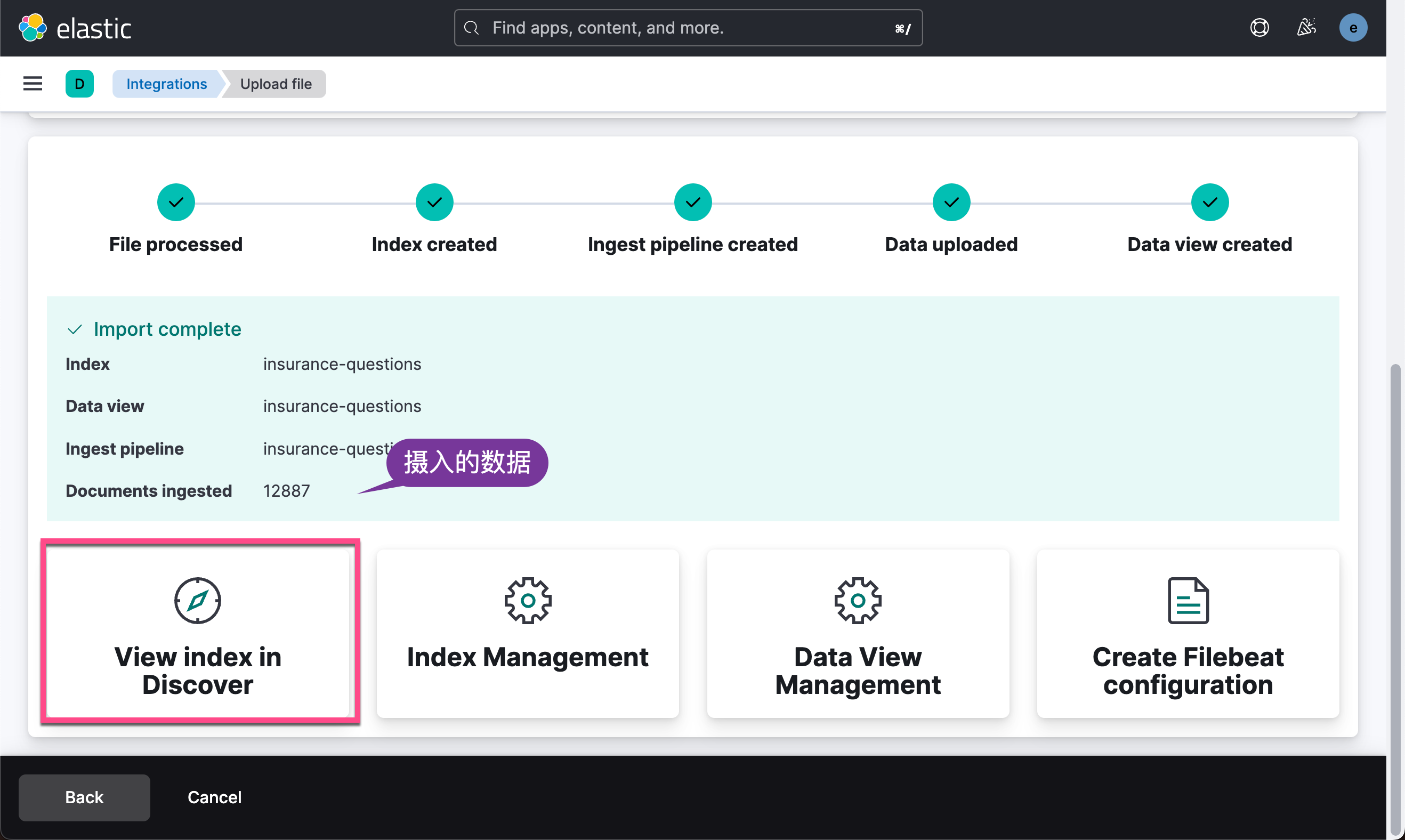
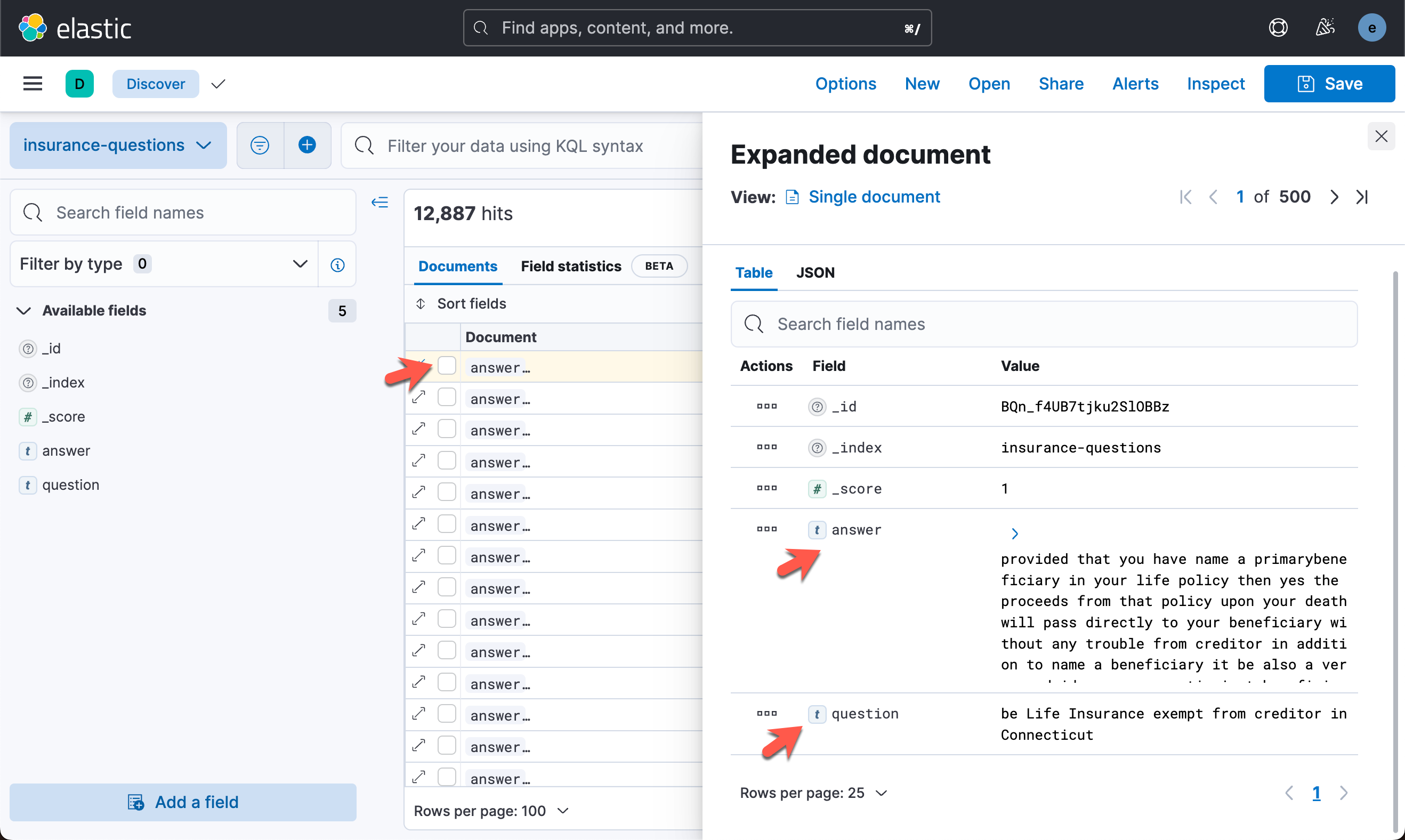
从显示的输出中,我们可以看出来是一个 question 及 answer 的索引文档。在我们的应用中,我们希望输入一个句子和 question 进行语义匹配,从而找到与之想匹配的 answer。
创建 text embedding
为了准备向量搜索的问题集,我们需要使用刚刚导入的 ML 模型为每个问题创建 text embedding(即向量表示)。为此,我们将创建一个单独的索引来存储这些文本嵌入。 从 Stack Management > Dev Tools,运行以下请求:
PUT insurance-questions-embeddings
{"mappings": {"properties": {"qa_text_embedding.predicted_value": {"type": "dense_vector","dims": 512,"index": true,"similarity": "cosine"}}}
}在上面,我们创建了一个叫做 insurance-questions-embeddings 的索引。在这个索引中,我们定义了一个叫做 qa_text_embedding.predicted_value 的字段。它是 512 维的数值。这个我们可以从 sentence-transformers/distiluse-base-multilingual-cased-v1 文档中可以查看到。
我们接下来创建一个 inferenece ingest pipeline。它可以针对我们上传的数据进行处理,并得到 512 维的向量。
PUT _ingest/pipeline/insurance-question-embeddings
{"description": "Text embedding pipeline","processors": [{"inference": {"model_id": "sentence-transformers__distiluse-base-multilingual-cased-v1","target_field": "qa_text_embedding","field_map": {"question": "text_field"}}}],"on_failure": [{"set": {"description": "Index document to 'failed-<index>'","field": "_index","value": "failed-{{{_index}}}"}},{"set": {"description": "Set error message","field": "ingest.failure","value": "{{_ingest.on_failure_message}}"}}]
}我们是针对 question 这个字段做 text embedding。
Reindex 那些保险问题并得到 text embedding
我们现在准备重新索引我们的问题,以便它们通过 ML 推理管道创建文本嵌入,然后将其存储在我们名为 insurance-questions-embeddings 的新索引中:
POST _reindex?wait_for_completion=false
{"source": {"index": "insurance-questions"},"dest": {"index": "insurance-questions-embeddings","pipeline": "insurance-question-embeddings"}
}在上面,我们使用 insurance-question-embeddings 管道以在 reindex 的过程中生成 text embedding。上述命令返回一个 task id:
{"task": "H571b6jHSU62a7Z_uadftQ:63943"
}我们可以通过如下的命令来查看它的进度:
{"completed": false,"task": {"node": "H571b6jHSU62a7Z_uadftQ","id": 63943,"type": "transport","action": "indices:data/write/reindex","status": {"total": 12887,"updated": 0,"created": 1000,"deleted": 0,"batches": 2,"version_conflicts": 0,"noops": 0,"retries": {"bulk": 0,"search": 0},"throttled_millis": 0,"requests_per_second": -1,"throttled_until_millis": 0},"description": "reindex from [insurance-questions] to [insurance-questions-embeddings]","start_time_in_millis": 1672895336864,"running_time_in_nanos": 39568264875,"cancellable": true,"cancelled": false,"headers": {"trace.id": "fc749fefa948de2a1a65a5cd39d34d10"}}
}我们可以查看上面的 completed 状态直至它为 true:
{"completed": true,"task": {"node": "H571b6jHSU62a7Z_uadftQ","id": 63943,"type": "transport","action": "indices:data/write/reindex","status": {"total": 12887,"updated": 0,"created": 12887,"deleted": 0,"batches": 13,"version_conflicts": 0,"noops": 0,"retries": {"bulk": 0,"search": 0},"throttled_millis": 0,"requests_per_second": -1,"throttled_until_millis": 0},"description": "reindex from [insurance-questions] to [insurance-questions-embeddings]","start_time_in_millis": 1672895336864,"running_time_in_nanos": 295440517291,"cancellable": true,"cancelled": false,"headers": {"trace.id": "fc749fefa948de2a1a65a5cd39d34d10"}},"response": {"took": 295433,"timed_out": false,"total": 12887,"updated": 0,"created": 12887,"deleted": 0,"batches": 13,"version_conflicts": 0,"noops": 0,"retries": {"bulk": 0,"search": 0},"throttled": "0s","throttled_millis": 0,"requests_per_second": -1,"throttled_until": "0s","throttled_until_millis": 0,"failures": []}
}我们可以查看索引的文档个数:
GET insurance-questions-embeddings/_count{"count": 12887,"_shards": {"total": 1,"successful": 1,"skipped": 0,"failed": 0}
}很显然这个是和我们之前摄入的数量是一直的。我们进而可以查看 text embedding:
GET insurance-questions-embeddings/_search?filter_path=**.hits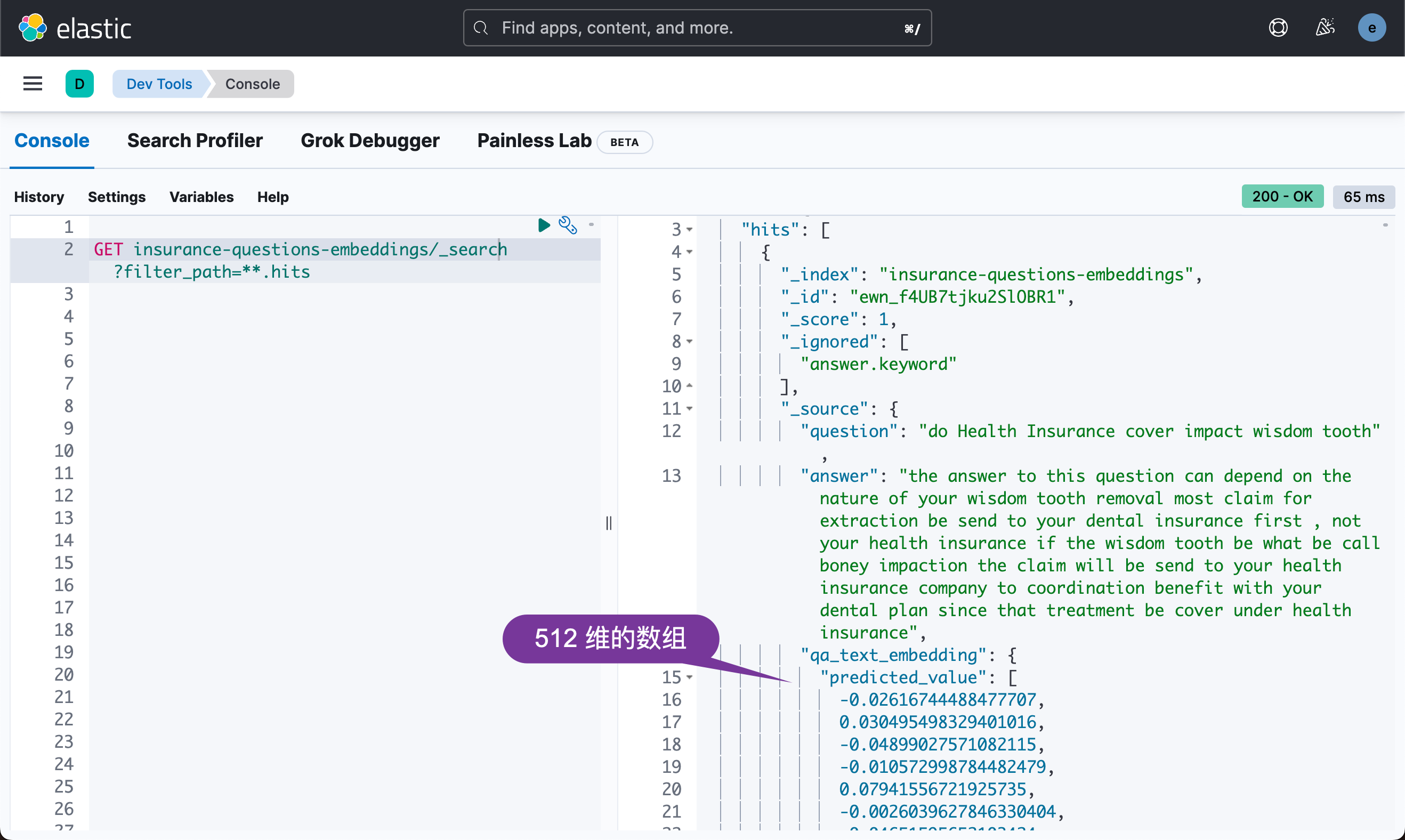
上面的 qa_text_embedding.predicted_value 含有针对当前 question "do Health Insurance cover impact wisdom tooth" 而创建的 text embedding。它可以被用于语义搜索,尽管不必要文字匹配。
Vector Similarity Search
目前我们不支持在搜索请求期间从查询词隐式生成嵌入,因此我们的语义搜索被组织为一个两步过程:
- 从文本查询中获取文本嵌入。 为此,我们使用模型的 _infer API。
- 使用向量搜索来查找与查询文本语义相似的文档。 在 Elasticsearch v8.0 中,我们引入了一个新的 _knn_search 端点,它允许在索引的 dense_vector 字段上进行有效的近似最近邻搜索。 我们使用 _knn_search API 来查找最近的文档。
例如,给一个文本查询 “necesito un seguro de inquilino”,我们首先运行 _infer API 以得到一个密集向量的 embedding:
POST /_ml/trained_models/sentence-transformers__distiluse-base-multilingual-cased-v1/deployment/_infer
{"docs": {"text_field": "necesito un seguro de inquilino"}
}在上面,我们使用的是一个西班牙语来进行的搜索,尽管我们的 question 是英文的。上述命令将生成一个 text embedding:
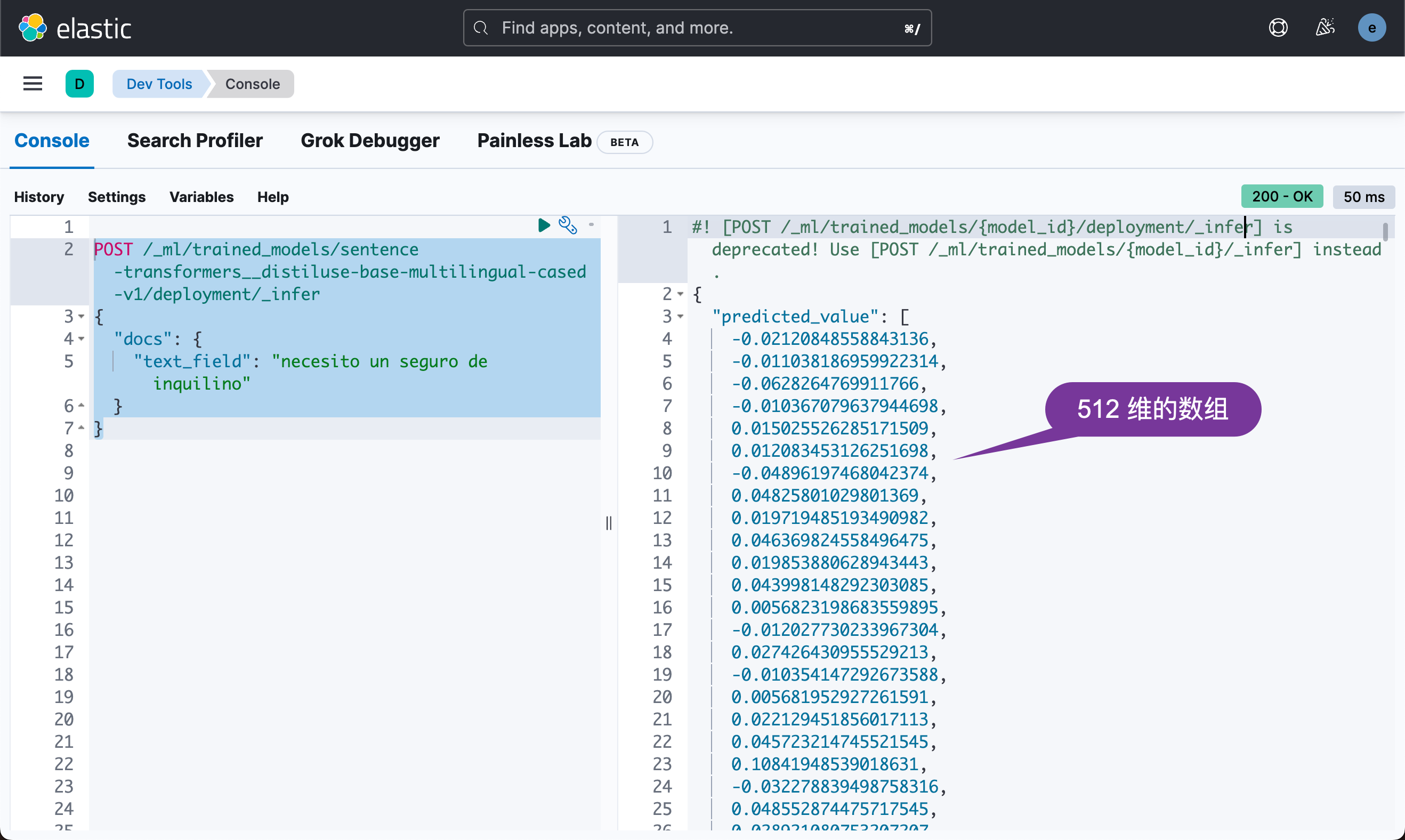
上面的 predicted_value 是一个512 维的向量。之后,我们将生成的密集向量(dense vector)插入到 _knn_search 中,如下所示:
GET insurance-questions-embeddings/_knn_search
{"_source": ["question"],"knn": {"field": "qa_text_embedding.predicted_value","k": 10,"num_candidates": 100,"query_vector": [-0.02120848558843136,-0.011038186959922314,-0.0628264769911766,-0.010367079637944698,...]}
}上面的搜索结果为:
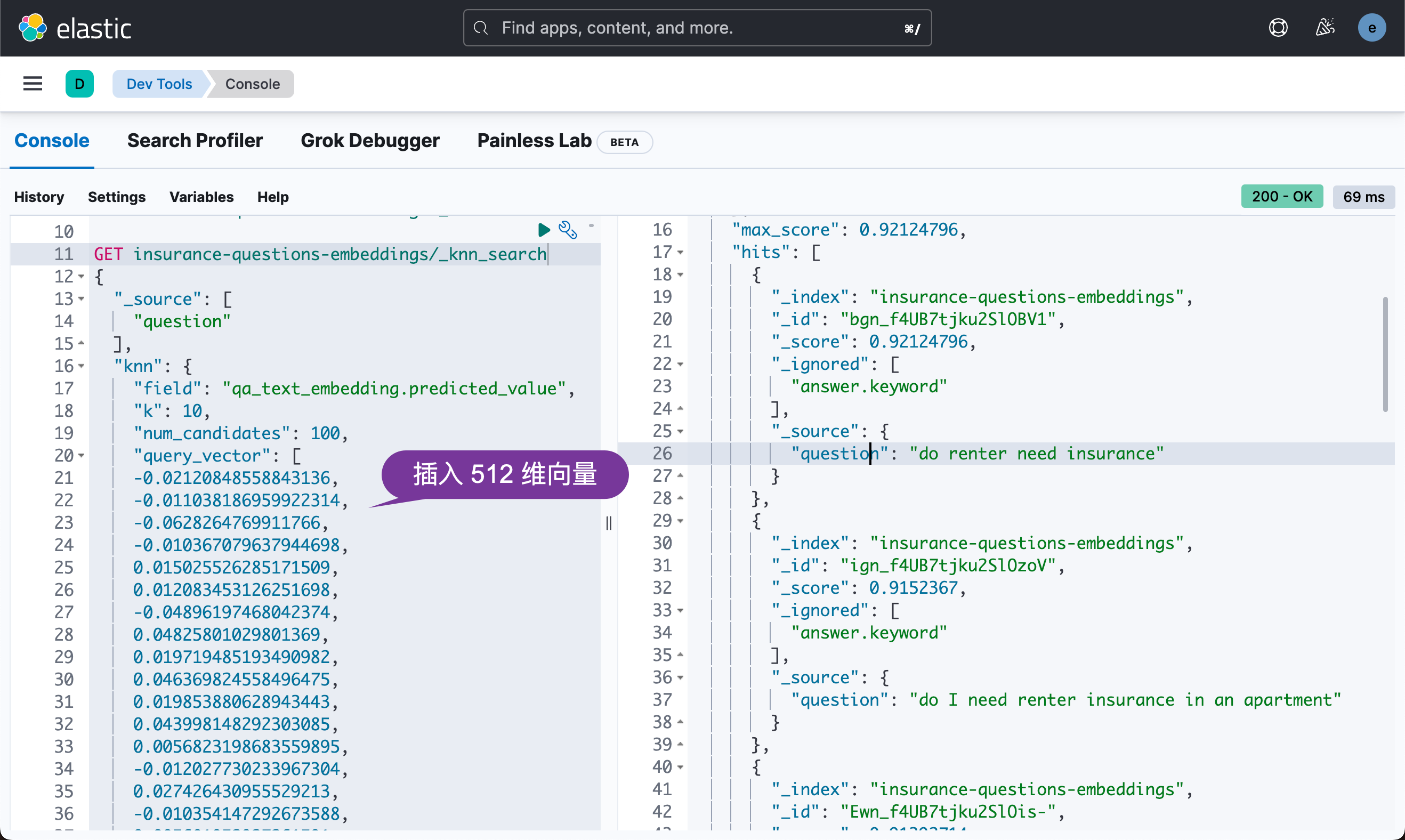
上面显示和西班牙语 necesito un seguro de inquilino 相匹配的英文问题。西班牙的语义是:我需要租客保险。这个是在谷歌翻译上找到的。我们可以看到上面的搜索结果还是蛮和我们的问题相关的。

创建一个 web 搜索应用
Elastic 平台附带一个名为 Discover 的分析用户界面,你可以立即使用它来探索和查询你的数据。 不过,我们的最终目标是构建一个由 Elastic 提供支持的搜索应用程序来处理我们的特定用例,因此我们将在以下小块中解决这个问题:
- 创建一个后端服务来查询 Elasticsearch 以获取我们通过 File Data Visualizer 导入的保险问题。 在这个原型中,我们使用 Express.js。
- 构建连接到后端服务的前端 UI,以呈现保险问题结果。 在这个原型中,我们使用 Angular。
Elastic 附带一组丰富的 API,使开发人员能够开始构建有趣的应用程序! 我们将通过创建一个端点来开始构建我们的后端服务,该端点使用搜索 API 返回查询的基本搜索结果。
app.get('/search-insurance', async (req, res) => {query = req.query.query;const response = axios.get('https://<ELASTICSEARCH_ENDPOINT>/insurance_questions/_search', {headers: {'Content-Type': 'application/json','Authorization': 'ApiKey ${api_key}'},data: {'query': {'match': {'question': {'query': query}}},'_source': ['question', 'answer']}}).then(response => {res.send(response.data.hits.hits)});
})如果我们尝试用英语搜索 “do I need renter's insurance”,我们会得到许多相关结果。
GET insurance-questions/_search?filter_path=**.hits
{"fields": ["question","answer"], "query": {"match": {"question": "do I need renter's insurance"}},"_source": false
}上面的命令返回的结果为:
{"hits": {"hits": [{"_index": "insurance-questions","_id": "Xgn_f4UB7tjku2SlOBnt","_score": 7.4738307,"fields": {"question": ["why do I need Medigap"],"answer": ["only you can decide if you need a Medigap plan original Medicare will only cover about 80% your approve Medicare part A and part b claim deductible , copay and coinsurance can leave you owe several 1,000 dollar in out of pocket expense Medigap plan can protect you from have pay thousand dollar in out of pocket expense shall you become seriously ill or have a major accident #GeorgiaMedigapPlanRates #GeorgiaMedicarePlans #GaMedigapQuotes"]}},{"_index": "insurance-questions","_id": "fgn_f4UB7tjku2SlOiw_","_score": 7.4738307,"fields": {"question": ["do I need Medigap coverage"],"answer": ["that be a question only you can answer consider this Medicare have 2 part part A ( hospital and part b ( outpatient Medicare only pay about 80% the cost of your care , you pay the other 20% your financial responsibility be unlimited if you be comfortable with pay large deductible for hospital admission and 20% outpatient charge you may not need a Medigap plan the per admission Medicare part A deductible be $1184 the Part B annual deductible be $147 follow 80% coinsurance Medicare pay 80% , you pay the balance #GeorgiaMedigapPlanRates #GeorgiaMedicarePlans #GaMedigapQuotes"]}}
...这对说英语的人来说很好,但让我们考虑一下我们如何支持非说英语的人。 正如 CMS 发布的那样,沟通和语言障碍与护理质量和结果的下降有关,因此帮助弥合这一差距是我们的目标。 看看英语水平有限的 Medicare 受益人使用的特定语言,西班牙语在美国和大多数州是最普遍的,超过一半的人将其确定为他们在家中使用的语言。
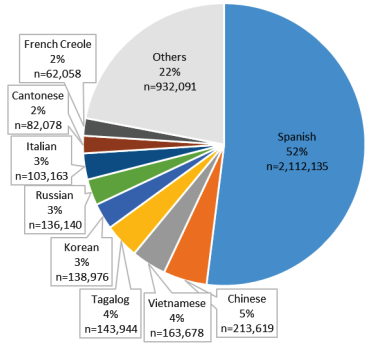
那么,如果我们用另一种语言(如西班牙语)尝试这样做会发生什么? 对于 “necesito un seguro de inquilino” 的问题,我们得到 0 个结果。 不足为奇,因为我们的 API 没有去学校学习其他语言。 然而,继续学习永远不会太晚,所以让我们看看我们如何做到这一点的方法。
GET insurance-questions/_search?filter_path=**.hits
{"query": {"match": {"question": "necesito un seguro de inquilino"}}
}上面的命令查询的结果为:
{"hits": {"hits": []}
}也就是说没有任何的结果。
学习新语言
我们可以用不同的方式来解决这个问题,例如让某人或某个程序将保险问题语料库翻译成不同的语言。 或者,如果我们有不同语言的数据源,我们可以应用语言识别,如之前关于多语言搜索的博客中所述,使用特定于语言的分析器来存储它。
在完成这些翻译之前,我们可以采用的一种并行方法是将 NLP 模型引入 Elastic,这是 8.0 版中引入的一项功能。 分解一下,基本上有3个步骤:
- 导入经过训练的 NLP 模型:我们将使用的模型是支持 15 种语言的多语言模型:阿拉伯语、中文、荷兰语、英语、法语、德语、意大利语、韩语、波兰语、葡萄牙语、俄语、西班牙语、土耳其语。
- 将我们的保险问题转换为向量表示:我们通过 NLP 模型运行问题并将这些向量存储到 Elasticsearch 中来实现
- 现在我们搜索:当我们 得到一个搜索查询时,它也会得到 NLP 处理以表示为一个向量,然后我们可以使用最近邻搜索来找到相关的匹配项

我们现在要做的搜索类型有几个名字 — 语义搜索、kNN 搜索、向量搜索。 让我们快速浏览一些代码以进行此搜索。
执行搜索
我们的保险问题现在带有一个文本嵌入值,它是从我们导入的 NLP 模型创建的,我们现在可以进行搜索了。 首先,我们使用 Infer Trained Model API 获取我们的搜索查询并获得其密集向量表示。
async function infer_nlp_vectors(query) {const response = axios.post('https://<ELASTICSEARCH_ENDPOINT>/_ml/trained_models/sentence-transformers__distiluse-base-multilingual-cased-v1/_infer',{'docs': {'text_field': query}} return response;
}这个就是和我上面所讲述的 _infer API 来获取向量是一样的,只不过这里是使用 Node.js 代码来完成的。
然后,我们可以将搜索查询(以其矢量形式)提供给搜索 API,并使用 kNN 选项执行我们正在讨论的最近邻搜索。
async function semanticSearch(query_dense_vector) {const response = axios.get('https://<ELASTICSEARCH_ENDPOINT>/insurance-questions-embeddings/_search', data: {'knn': {'field': 'qa_text_embedding.predicted_value','query_vector': query_dense_vector,'k': 10,'num_candidates': 100},'_source': ['question','answer']}});return response;
}这个部分实际上面是和我上面描述的 _knn_search 搜索是一样的,只不过是另外一种表现的形式。这里是 Node.js 的代码。
我们现在无需将 12,000 个保险问题翻译成西班牙语即可获得结果!
创建 enterprise search
接下来我们来创建一个基于 angular 的 web 应用来实现我们的搜索界面。我们可以直接基于上面的 Node.js 代码来实现这个,但是 Elastic Stack 的 Enterprise search 为我们提供更加完美的解决方案。我们甚至直接可以从 Elasticsearch 中提取数据,并形成搜索引擎。Enterprise search 为我们定制搜索提供非常直观简洁的方案。下面,我们来针对 enterprise 来进行安装。
首先,我们从 Elastic 的官方网站 Download Elastic Enterprise Search | Elastic 下载和我们的平台及 Elasticsearch 版本相匹配的 enterprise search 来进行安装。在网站上有详细的安装步骤。详细的安装步骤可以参考文章 “Enterprise:使用 Elastic Stack 8.2 中的 Elasticsearch API 来定位 App Search 中的文档”。
Kibana
首先,我们停止 Kibana 的运行,并在 Kibana 的配置文件中加入如下的配置:
config/kibana.yml
enterpriseSearch.host: http://localhost:3002然后重新启动 Kibana。
Enterprise search
我们解压缩下载的 Enterpise search:
$ pwd
/Users/liuxg/elastic
$ tar xzf enterprise-search-8.5.3.tar.gz
$ cd enterprise-search-8.5.3
$ ls
LICENSE NOTICE.txt README.md bin config lib metricbeat
$ ls config/enterprise-search.yml
config/enterprise-search.yml如上所示,它含有一个叫做 config 的目录。我们在启动 Enterprise Search 之前,必须做一些相应的配置。我们需要修改 config/enterprise-search.yml 文件。在这个文件中添加如下的内容:
allow_es_settings_modification: true
elasticsearch.username: elastic
elasticsearch.password: 7nb2W-HRb*DxTPN=Xi=K
elasticsearch.host: https://127.0.0.1:9200
elasticsearch.ssl.enabled: true
elasticsearch.ssl.certificate_authority: /Users/liuxg/elastic/elasticsearch-8.5.3/config/certs/http_ca.crt
kibana.external_url: http://localhost:5601
在上面,请注意 elasticsearch.password 是我们在 Elasticsearch 安装过程中生成的密码。elasticsearch.ssl.certificate_authority 必须根据自己的 Elasticsearch 安装路径中生成的证书进行配置。在上面的配资中,我们还没有配置 secret_management.encryption_keys。我们可以使用上面的配置先运行,然后让系统帮我们生产。
./bin/enterprise-search 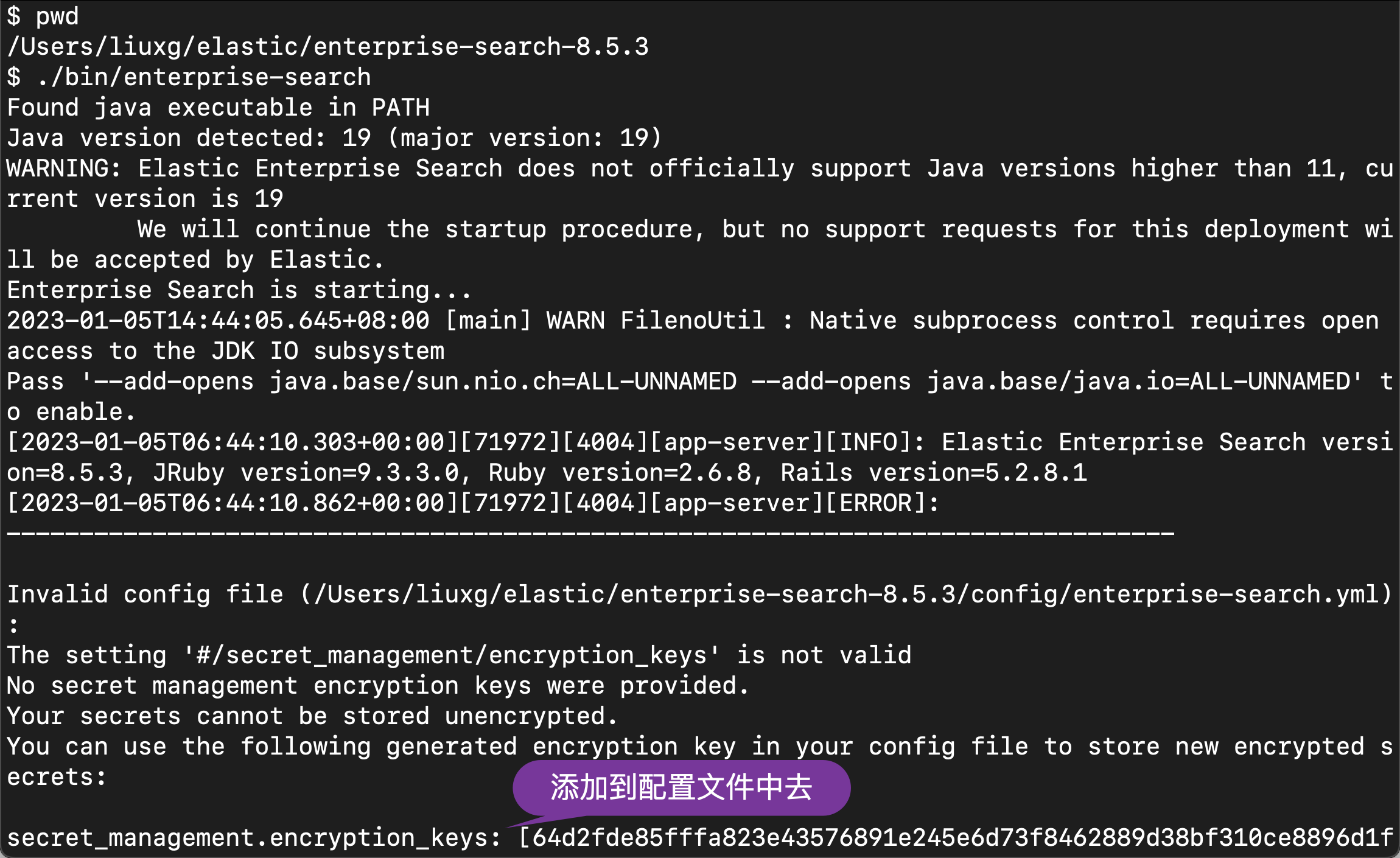
如上所示,当我们我们的配置中还没有配置 secret_management.encryption_keys 时,第一次启动它会帮我们生成一个 key。我们把上面生成的 key 拷贝到 config/enterprise-search.yml 文件中去。最终的配置文件如下:
config/enterprise-search.yml
allow_es_settings_modification: true
elasticsearch.username: elastic
elasticsearch.password: 7nb2W-HRb*DxTPN=Xi=K
elasticsearch.host: https://127.0.0.1:9200
elasticsearch.ssl.enabled: true
elasticsearch.ssl.certificate_authority: /Users/liuxg/elastic/elasticsearch-8.5.3/config/certs/http_ca.crt
kibana.external_url: http://localhost:5601
secret_management.encryption_keys: [64d2fde85fffa823e43576891e245e6d73f8462889d38bf310ce8896d1f2fb5e]这样我们就配置完毕了。我们再次运行 enterprise search:
./bin/enterprise-search 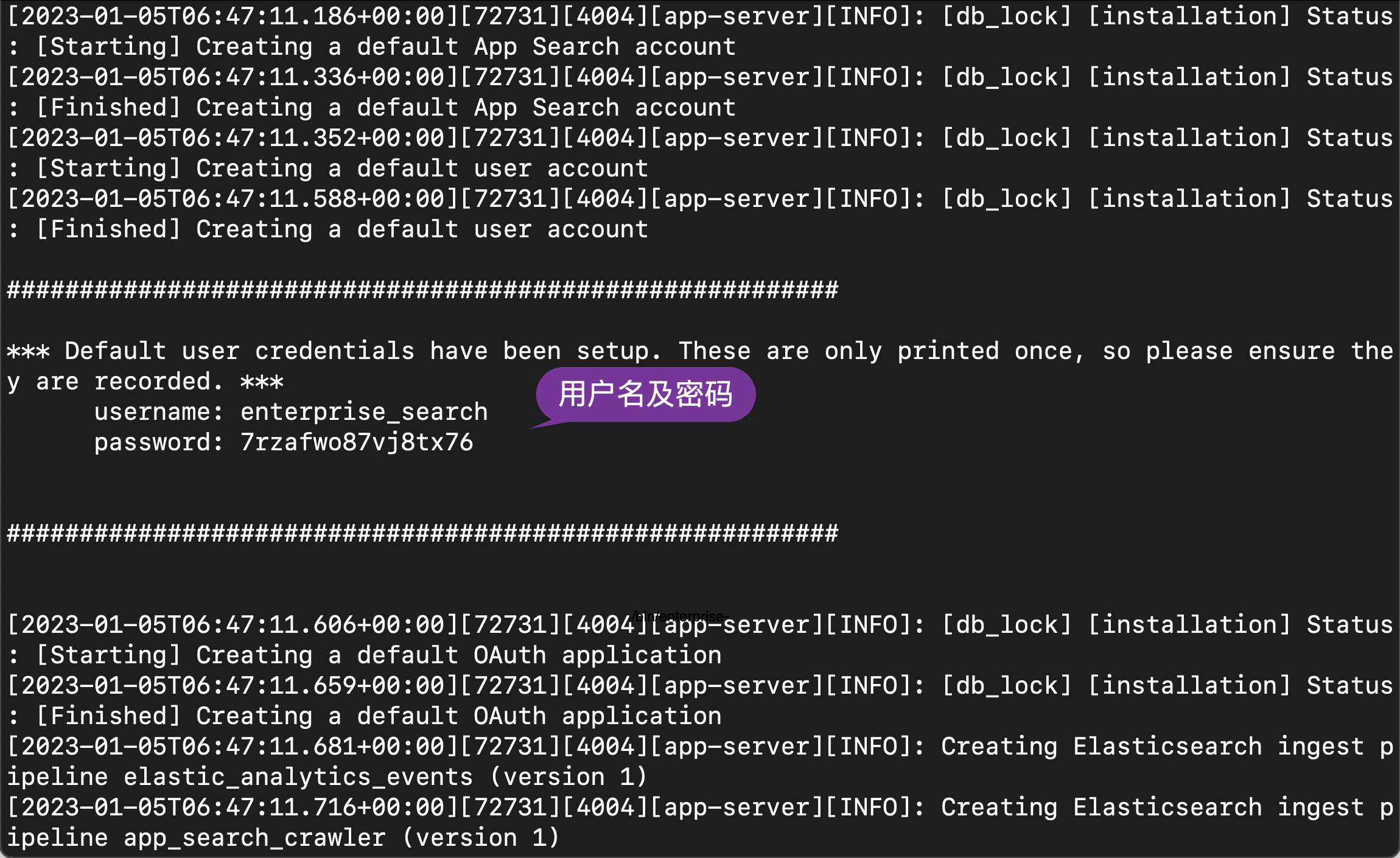
在启动的过程中,我们可以看到生成的用户名及密码信息:
username: enterprise_searchpassword: 7rzafwo87vj8tx76我们记下这个用户名及密码。在启动的过程中,我们还可以看到一个生成的 secret_session_key:
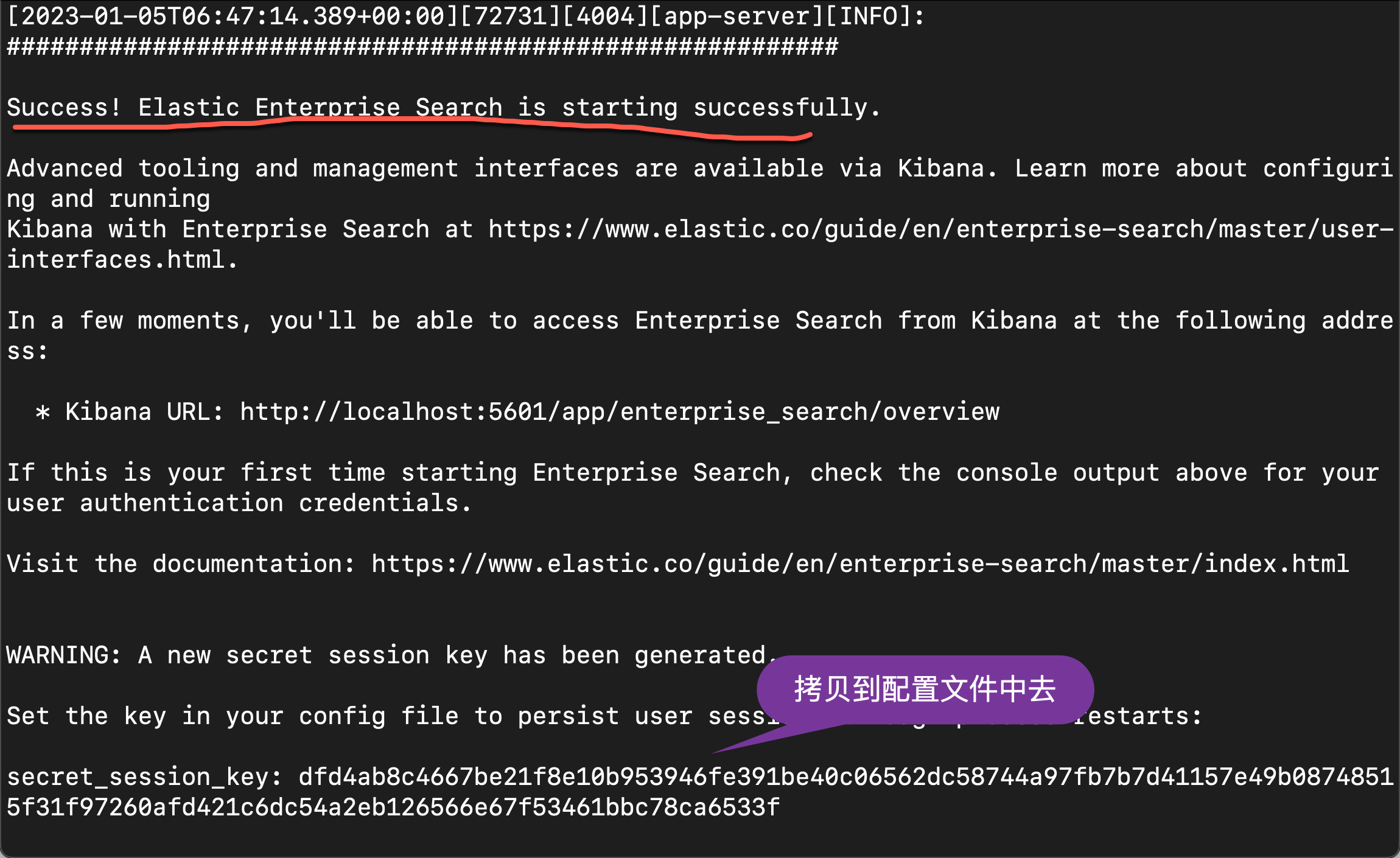
我们也把它拷贝下来,并添加到配置文件中去:
config/enterprise-search.yml
allow_es_settings_modification: true
elasticsearch.username: elastic
elasticsearch.password: 7nb2W-HRb*DxTPN=Xi=K
elasticsearch.host: https://127.0.0.1:9200
elasticsearch.ssl.enabled: true
elasticsearch.ssl.certificate_authority: /Users/liuxg/elastic/elasticsearch-8.5.3/config/certs/http_ca.crt
kibana.external_url: http://localhost:5601
secret_management.encryption_keys: [64d2fde85fffa823e43576891e245e6d73f8462889d38bf310ce8896d1f2fb5e]
secret_session_key: dfd4ab8c4667be21f8e10b953946fe391be40c06562dc58744a97fb7b7d41157e49b08748515f31f97260afd421c6dc54a2eb126566e67f53461bbc78ca6533ffeature_flag.elasticsearch_search_api: true为了能够使得我们能够在 App Search 中使用 Elasticsearch 搜索,我们必须设置
feature_flag.elasticsearch_search_api: true。 我们再次重新启动 enterprise search:
./bin/enterprise-search 这次启动后,我们再也不会看到任何的配置输出了。
创建 App Search Engine
我们回到 Kibana 的界面:

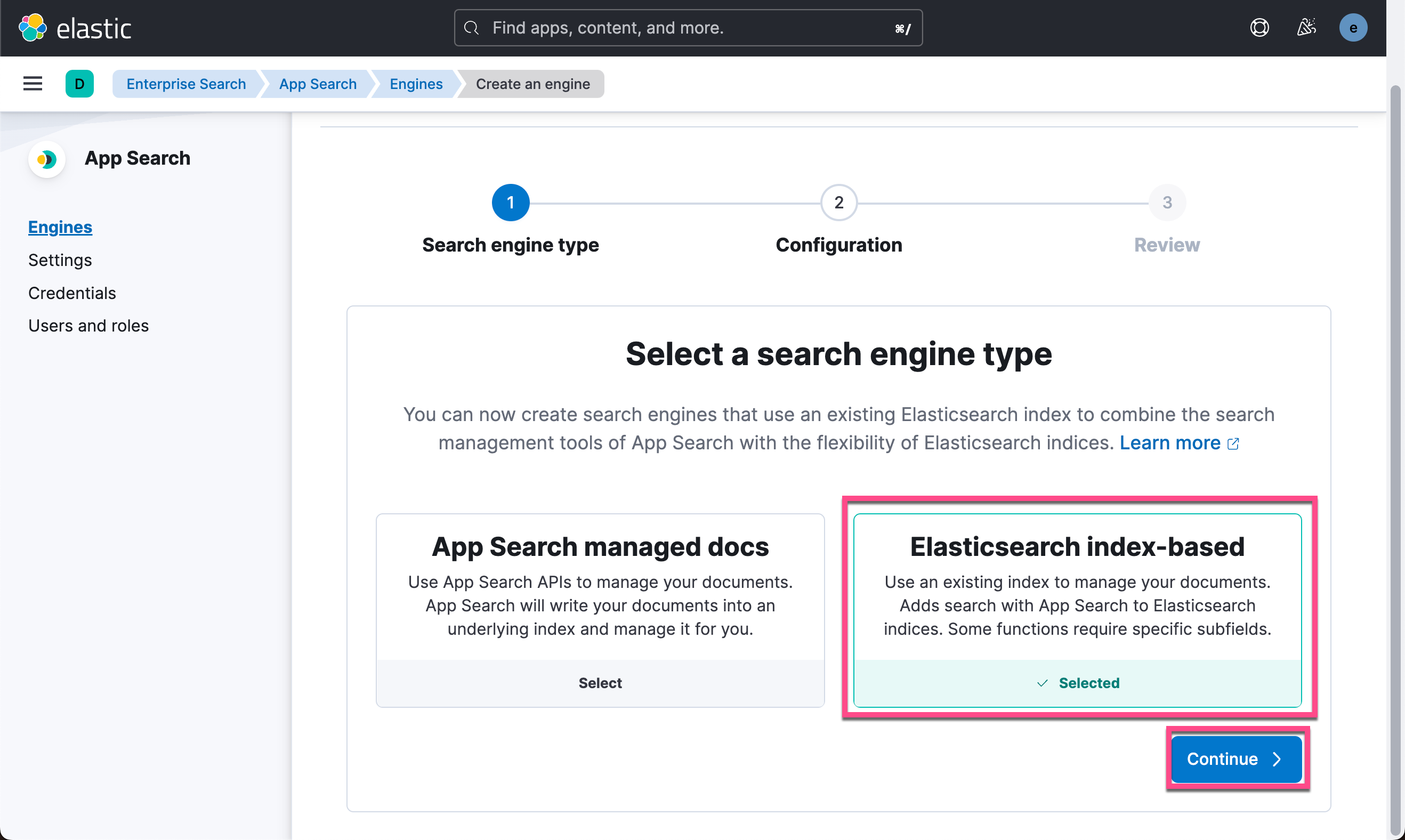
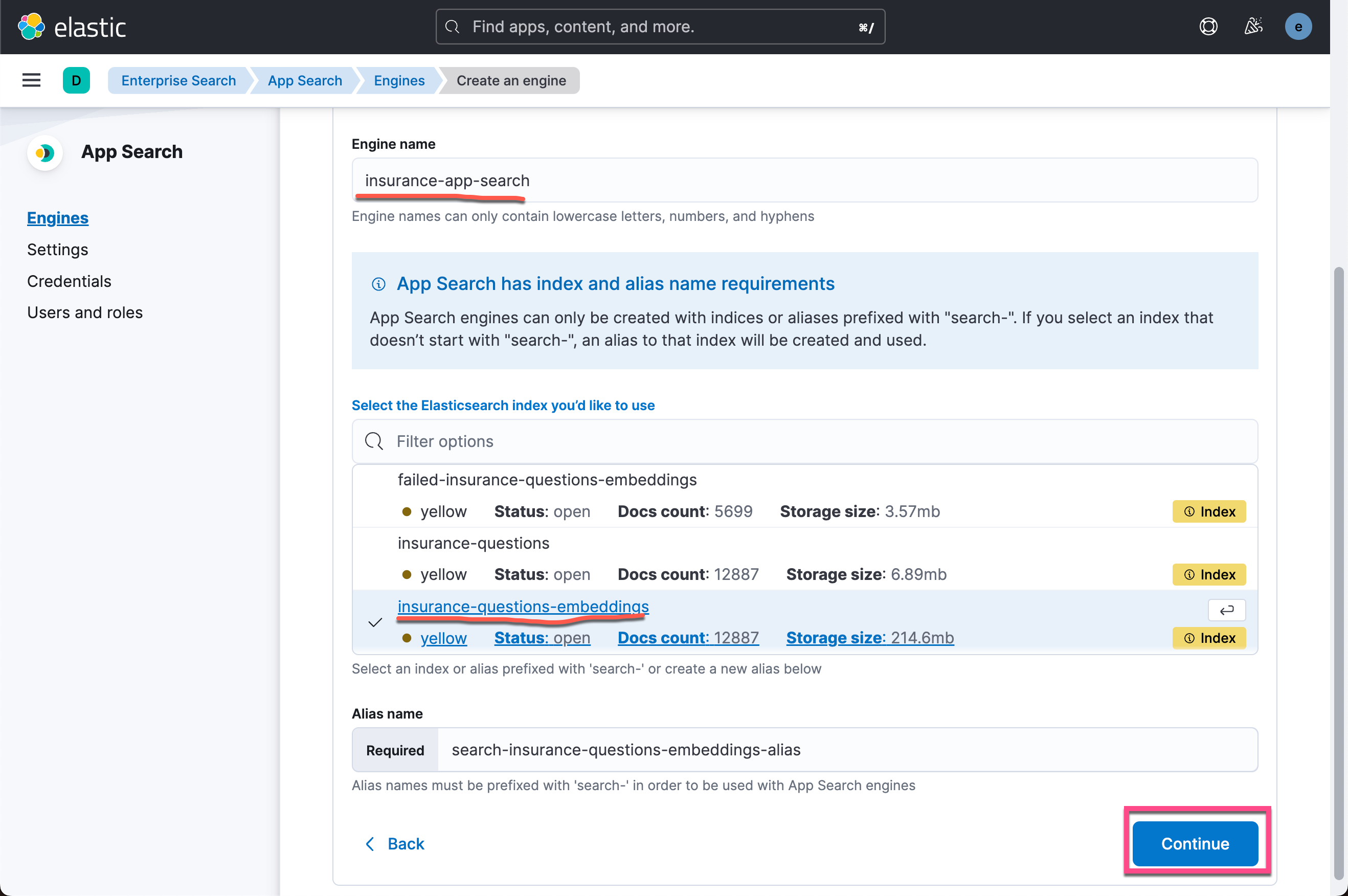
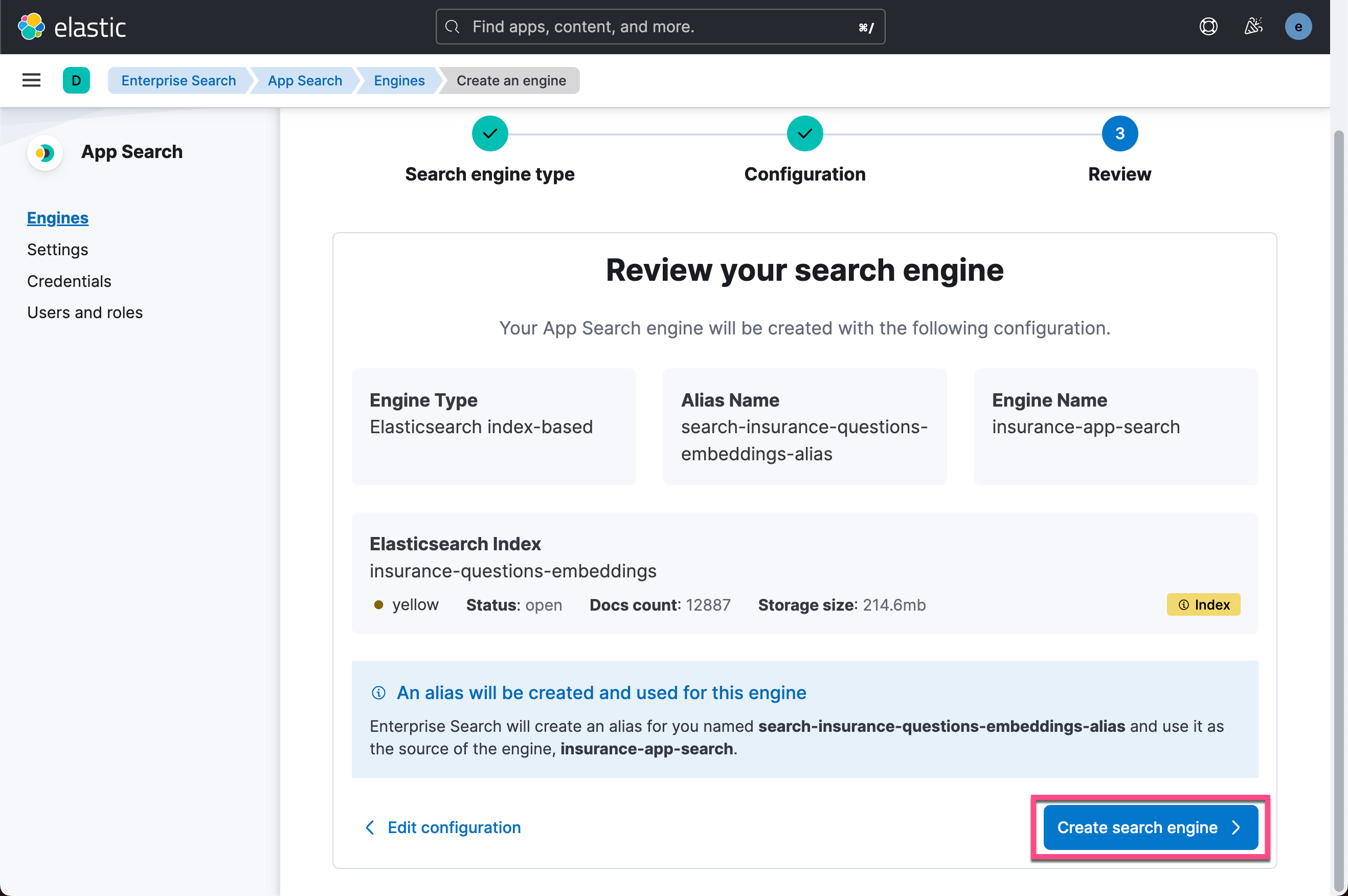
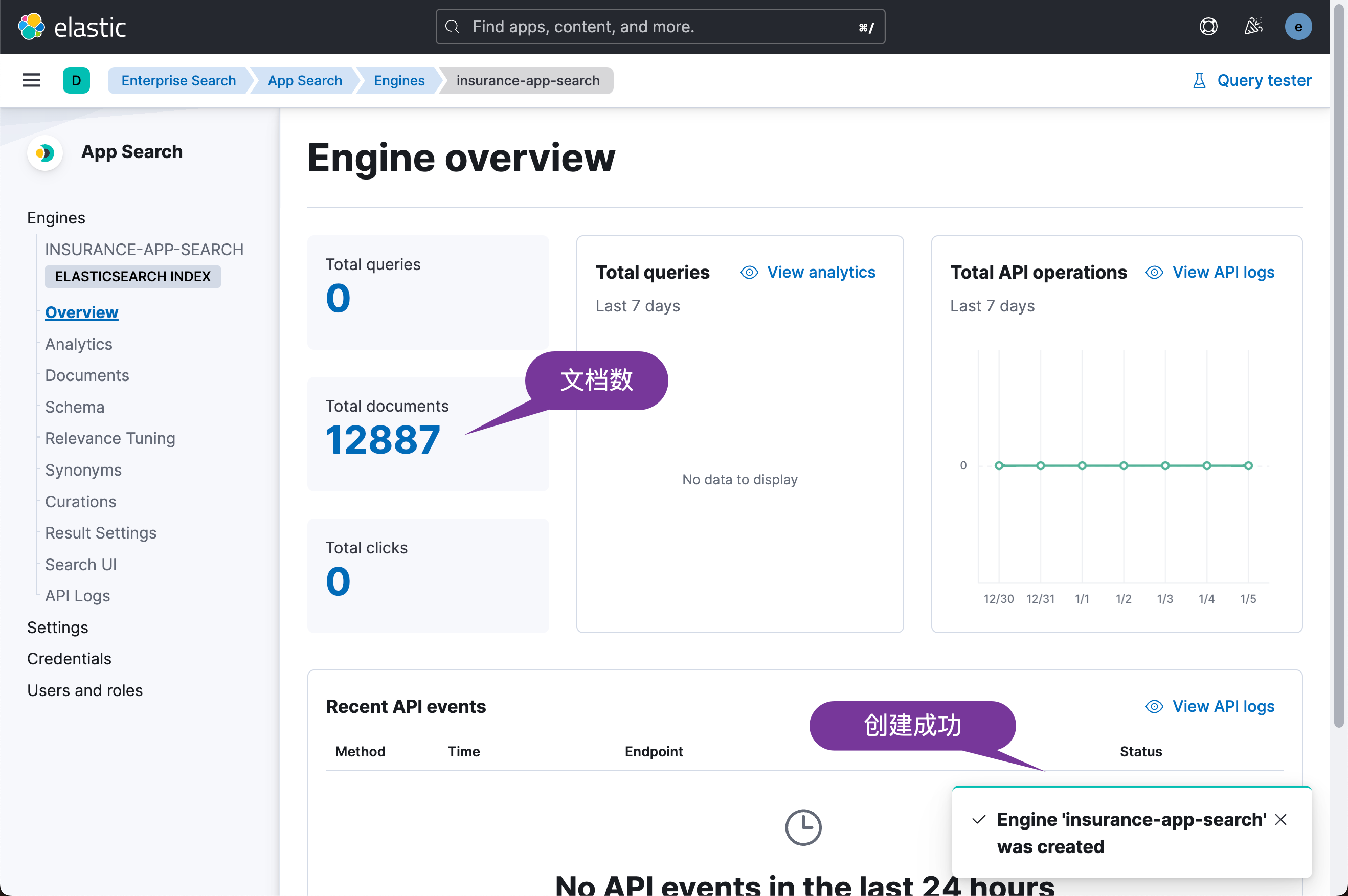
这样我们的搜索引擎已经被创建好了。在这个界面中,我们可以针对 enterprise 搜索做很多的定制。详细阅读请参阅我之前的文章 “Enterprise:Elastic App Search 入门 - Ruby”。
启动后端应用
我们现在回到之前我们下载的应用并进入到 back-end 目录中。我们
$ pwd
/Users/liuxg/demos/app-search-nlp-insurance
$ ls
LICENSE back-end insurance-questions
README.md front-end
$ cd back-end/
$ ls
README.MD config package-lock.json package.json server
$ cat config/default.json
{"elastic": {"username": "elastic","password": "7nb2W-HRb*DxTPN=Xi=K","certificate": "/Users/liuxg/elastic/elasticsearch-8.5.3/config/certs/http_ca.crt","apiKey": "ZWduaWdJVUI3dGprdTJTbDEwSm86Q3AyYjg2Q25UYnk0WVNicXlwX3hSQQ==","appSearchApiKey": "search-qg47imafckpwfbmrq6j7m3u5", "elasticEndpoint": "https://localhost:9200","entSearchEndpoint": "http://localhost:3002"}
}
关于这个部分的操作请详细阅读我之前的文章 “Elasticsearch:使用 Node.js 将实时数据提取到 Elasticsearch 中(一)”。我们需要对这个文件进行配置。
针对这些参数的说明:
- username:这个是超级用户 elastic 的用户名
- password:这个是超级用户 elastic 的密码。在 Elasticsearch 启动的时候,在启动过程中出现
- certificate:这个是 Elasticsearch 的证书位置
- elasticEndpoint:Elasticsearch 的终端地址
- entSearchEndpoint:这个是 enterprise search 的终端地址
- appSearchApiKey:这个是 app-search 的密码。我们可以通过如下的方式来得到
我们在 back-end 的目录下运行如下的命令:
npm install$ pwd
/Users/liuxg/demos/app-search-nlp-insurance/back-end
$ ls
README.MD config package-lock.json package.json server
$ npm install
npm notice Beginning October 4, 2021, all connections to the npm registry - including for package installation - must use TLS 1.2 or higher. You are currently using plaintext http to connect. Please visit the GitHub blog for more information: https://github.blog/2021-08-23-npm-registry-deprecating-tls-1-0-tls-1-1/
npm notice Beginning October 4, 2021, all connections to the npm registry - including for package installation - must use TLS 1.2 or higher. You are currently using plaintext http to connect. Please visit the GitHub blog for more information: https://github.blog/2021-08-23-npm-registry-deprecating-tls-1-0-tls-1-1/added 114 packages in 913ms11 packages are looking for fundingrun `npm fund` for details我们接下来运行如下的命令:
node server/create-api-key.js $ pwd
/Users/liuxg/demos/app-search-nlp-insurance/back-end
$ node server/create-api-key.js
You are connected to Elasticsearch!
ZWduaWdJVUI3dGprdTJTbDEwSm86Q3AyYjg2Q25UYnk0WVNicXlwX3hSQQ==上面表明我们的配置是成功的。它可以成功地连接到 Elasticsearch 并生成相应的 API key。我们把上面生成的 API key 拷贝下来,并粘贴到 default.json 文件的 apiKey 字段里:
back-end/config/default.json
{"elastic": {"es_host": "https://localhost:9200","username": "elastic","password": "7nb2W-HRb*DxTPN=Xi=K","certificate": "/Users/liuxg/elastic/elasticsearch-8.5.3/config/certs/http_ca.crt","apiKey": "ZWduaWdJVUI3dGprdTJTbDEwSm86Q3AyYjg2Q25UYnk0WVNicXlwX3hSQQ==","appSearchApiKey": "search-qg47imafckpwfbmrq6j7m3u5", "entSearchEndpoint": "http://localhost:3002"}
}由于我们是自签名的 Elasticsearch 集群,我们使用如下的命令来启动 server:
NODE_TLS_REJECT_UNAUTHORIZED="0" npm start 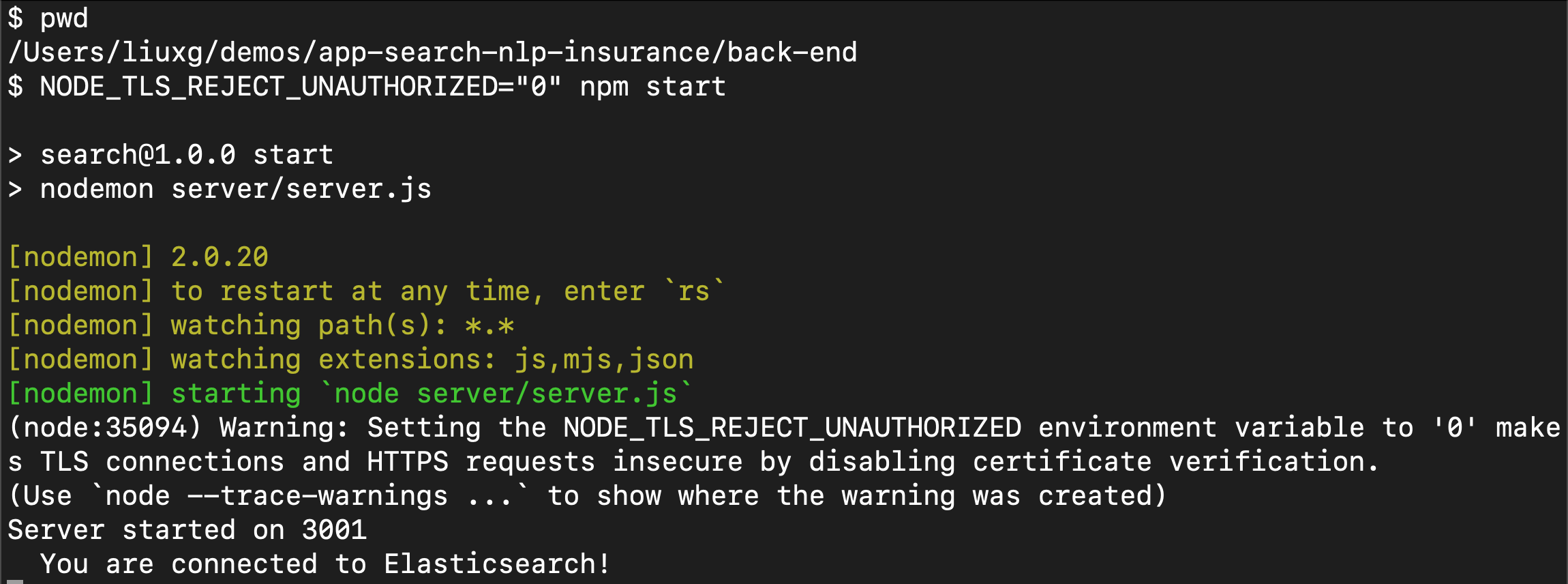
我们可以看到 server 运行在 localhost:3001 上。这个服务器的作用是作为一个 gateway 来访问 Elasticsearch。
启动前端应用
我们接下来进入到前端的应用中。我们按照如下的命令来安装并启动:
$ pwd
/Users/liuxg/demos/app-search-nlp-insurance/front-end
$ npm install
npm notice Beginning October 4, 2021, all connections to the npm registry - including for package installation - must use TLS 1.2 or higher. You are currently using plaintext http to connect. Please visit the GitHub blog for more information: https://github.blog/2021-08-23-npm-registry-deprecating-tls-1-0-tls-1-1/
npm WARN deprecated @npmcli/move-file@2.0.1: This functionality has been moved to @npmcli/fs
npm notice Beginning October 4, 2021, all connections to the npm registry - including for package installation - must use TLS 1.2 or higher. You are currently using plaintext http to connect. Please visit the GitHub blog for more information: https://github.blog/2021-08-23-npm-registry-deprecating-tls-1-0-tls-1-1/added 928 packages in 17s86 packages are looking for fundingrun `npm fund` for details编译项目:
ng build 
最后,我们运行开发服务器:
ng serve 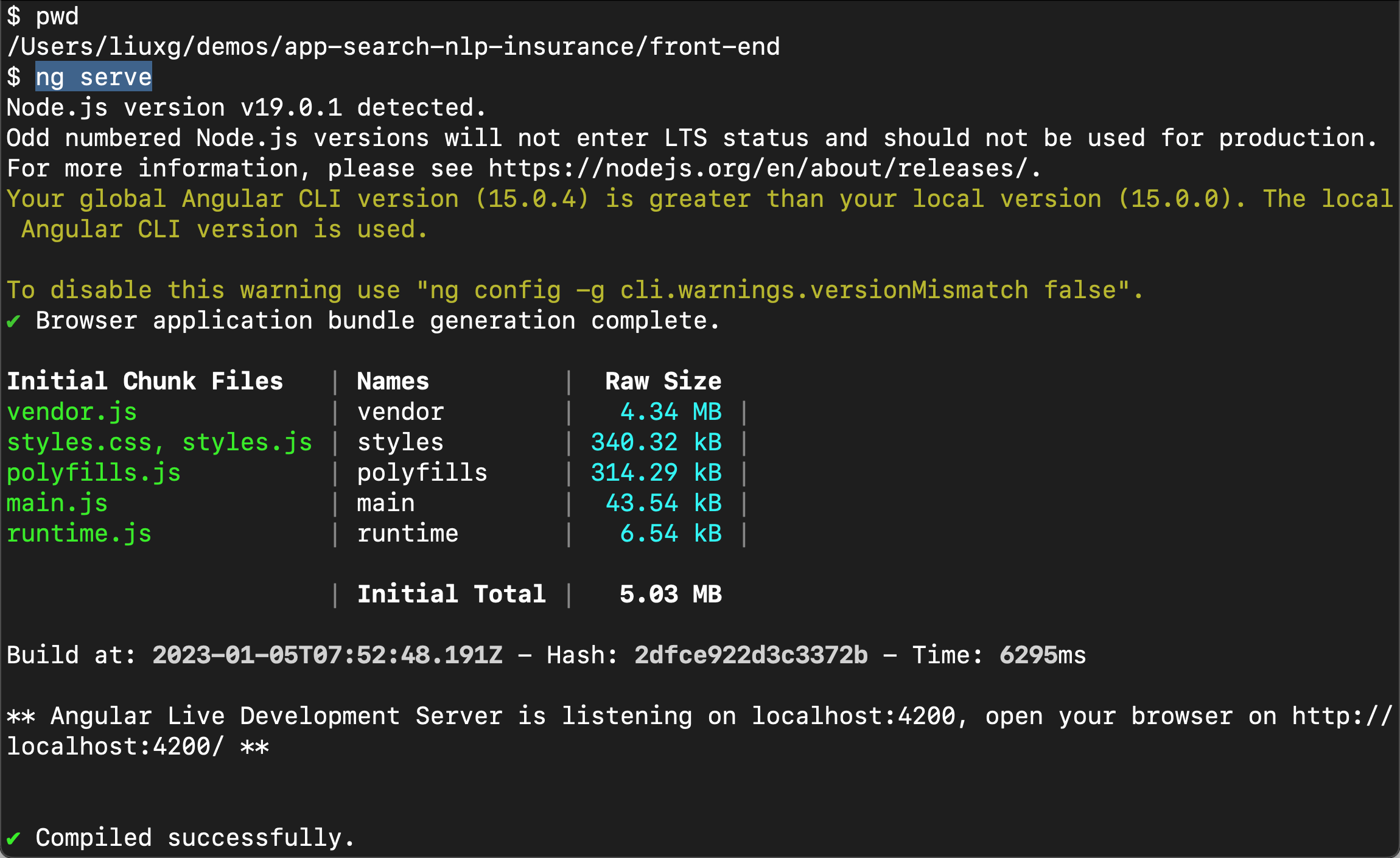
我们可以看到服务器已经成功地运行起来了。它运行于地址 http://localhost:4200/。
我们在浏览器中打开:

在上面,我输入了 necesito un seguro de inquilino。这个是西班牙文字,但是它显示很多相关的英文的 question。由于这个模型支持中文,我们也可以试一下中文的情况:
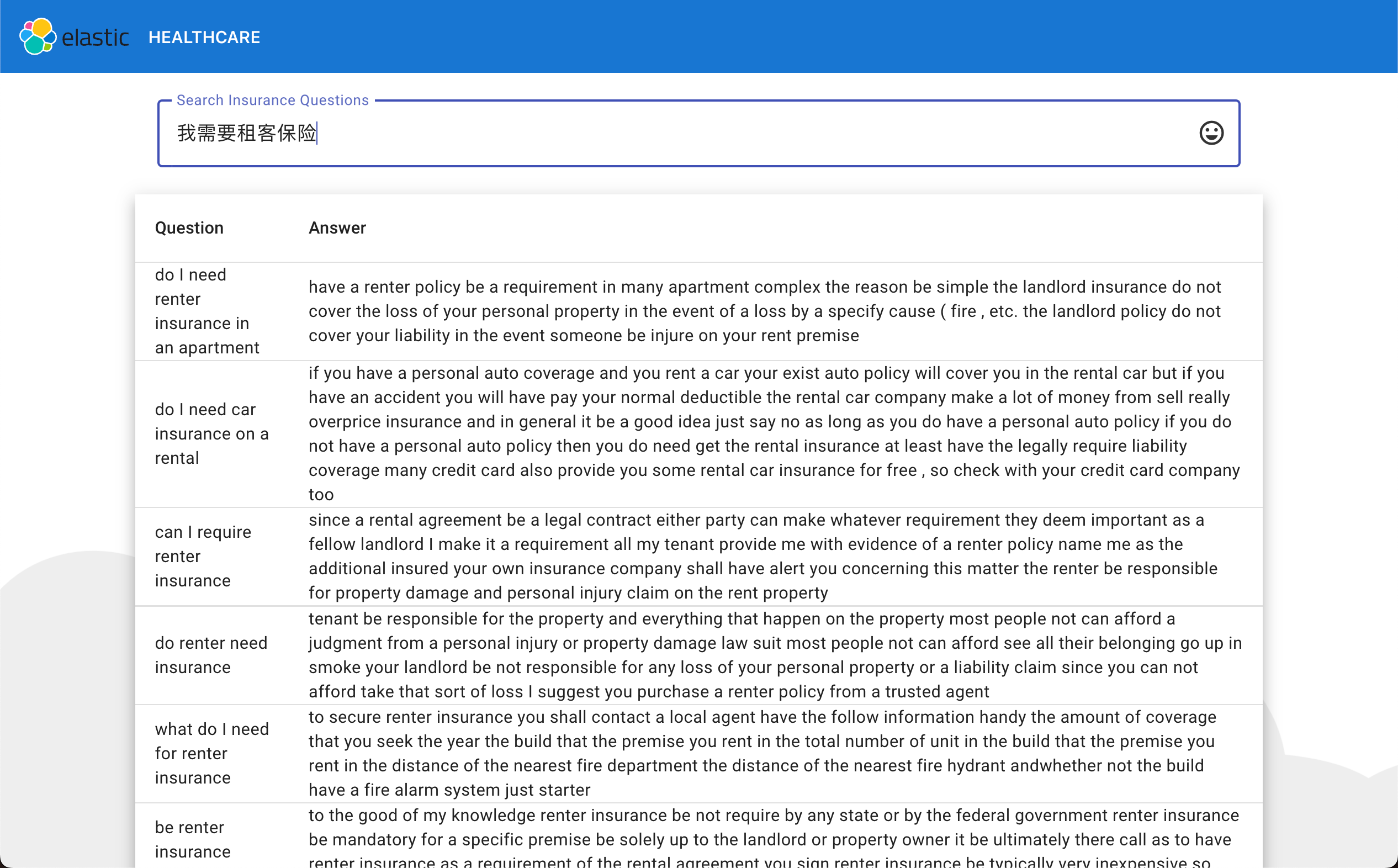
很显然它也显示了相关的中文搜索结果,虽然结果是以英文的形式来表达的。