可用性测试问卷
经过长期的研究和市场验证,目前已沉淀出很多标准化的可用性问卷,不同的问卷的评估针对性不一样,可以满足大部分用研需求。使用标准化的问卷是因为这些问卷是经过大量的使用后验证校准后产生的,是被认可具有通识性的衡量标准,这些问卷都具备客观性、重复性、量化、经济、沟通、科学的普适性的优质属性。
2.1 标准化的可用性测试问卷
问卷类型主要可以分为以下两大类: 列表中的问卷大部分是需要缴纳一定的费用后才能使用,但其中系统可用性整体评估问卷、软件可用性问卷、场景后问卷是标准可用性问卷中可以免费使用的。应用广泛且被专家推荐的测试问卷是:软件可用性问卷主要针对系统或功能进行整体评估,问题设计精炼清晰,使用快捷方便;单项难易度问题追求的是心理测试的简单和适用性,有5分和7分制,7分制的可靠性更高;主观脑力负荷问题是在线测试,灵敏性更好。综合评估下,软件可用性问卷(Software Usability Scale,SUS)是设计日常中最合适最经济实用的测试问卷。
列表中的问卷大部分是需要缴纳一定的费用后才能使用,但其中系统可用性整体评估问卷、软件可用性问卷、场景后问卷是标准可用性问卷中可以免费使用的。应用广泛且被专家推荐的测试问卷是:软件可用性问卷主要针对系统或功能进行整体评估,问题设计精炼清晰,使用快捷方便;单项难易度问题追求的是心理测试的简单和适用性,有5分和7分制,7分制的可靠性更高;主观脑力负荷问题是在线测试,灵敏性更好。综合评估下,软件可用性问卷(Software Usability Scale,SUS)是设计日常中最合适最经济实用的测试问卷。
2.2 软件可用性问卷(SUS)
软件可用性问卷是可用性测试结束时的主观性评估问卷,应用广泛,测试后该问卷使用占比约43%。整个问卷共10题,每题为5分制,奇数项为正面描述,偶数项为反面描述,可以通过修改问题文案聚焦测试范围;如有需要可以将偶数项的问题调整为正面描述,但数据验证调整为正面描述的问卷结果与包含负面描述的问卷差异不大,不影响问卷的测试结论。在完成测试任务后,用户需快速完成各个题目,不进行过多思考,若用户因某些原因无法完成其中某个题目,则视为选择中间值。
2.3 可用性、易用性抽取
问卷整体可以抽取部分题目作为子测量表来作为单独的问卷有针对性的进行可用性和易学性测量,可用性由问卷中1-3、5-9题构成,易学性由问卷中4、10题构成。研究表明使用子测量表对量表的可信度的减低可忽略不计(0.92 → 0.91),并且使用子测量表可减少答题时间。
2.4 分值计算
得分计算:范围在0-4,每题进行转化分值;奇数题(正面):原始分减去1,(x-1);偶数题(负面):5减去原始分,(5-x)
SUS总分= 所有转化过的分值相加 * 2.5, 多样本算SUS总分均值
可用性总分=所有转化过的可用性分数相加3.125
易用性总分=所有转化过的易用性分数相加12.5
统计学描述方法
可用性测试因为耗费时间较长,能够参与测试的用户资源稀缺,回收样本量小能够收集到的样本量一般会比较小。样本量小的情况下这个样本量所能概括的整体是范围比较大的,会存在较大误差,那么在较为严谨的报告中,可能需要对所得分数和除测试样本外的分值预期进行描述,这时候会涉及到统计学中常用的描述方式,即通过置信度及置信区间来描述,根据置信区间的下边界看软件是否低于行业标准。
3.1 相关概念
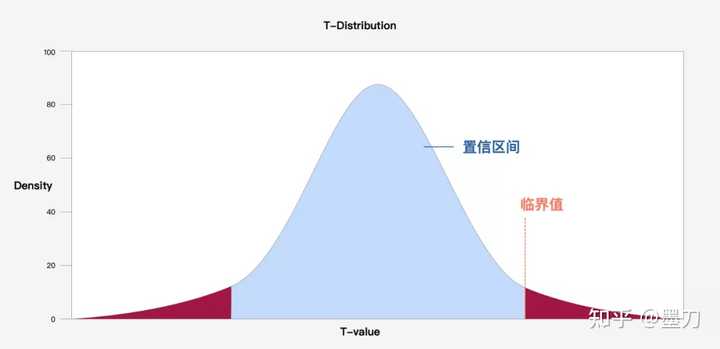 置信区间是指在一定概率下包含样本位置总体参数的这部分数值区间,通过计算置信区间来描述测试结果的概率。置信区间宽度和样本量之间是一个逆平方根的关系, 样本量越小,误差越大,未知样本数据可能所在的区间更大。
置信区间是指在一定概率下包含样本位置总体参数的这部分数值区间,通过计算置信区间来描述测试结果的概率。置信区间宽度和样本量之间是一个逆平方根的关系, 样本量越小,误差越大,未知样本数据可能所在的区间更大。
置信度就是说,你测得的均值,和总体真实情况的差距小于这个给定的值的概率,应该是1-α;换句话描述,即我们有1-α的信心认为,你测得的这个均值和总体的实际期望很接近了(测得的均值就是总体期望是很草率的,但是说,我有95%的把握认为我测得的均值,非常接近总体的期望了)。研究员可以选择0%-100%之间的任意数值的置信度,通常设为90%或95%(最常用)。
临界值是在原假设下,检验统计量在分布图上的点,这些点定义一组要求否定原假设的值。
3.2 置信区间计算
置信区间= (样本平均值-误差幅度)~(样本平均值+误差幅度)=(x -(x- μ))~(x +(x- μ))
x = 样本平均值
误差幅度=临界值(样本标准差/样本量的平方根),即:(x - μ) = α* (s / sqrt(n))
α=临界值(Excel函数=TINV(1-置信度,样本量-1))
μ=被检验的基准值(行业标准)
s=样本的标准差(Excel函数=STDEVP(N1,N2,…))
n=样本量*
tips:临界值可以通过所设置信度和样本量在t分布表中查找相应的值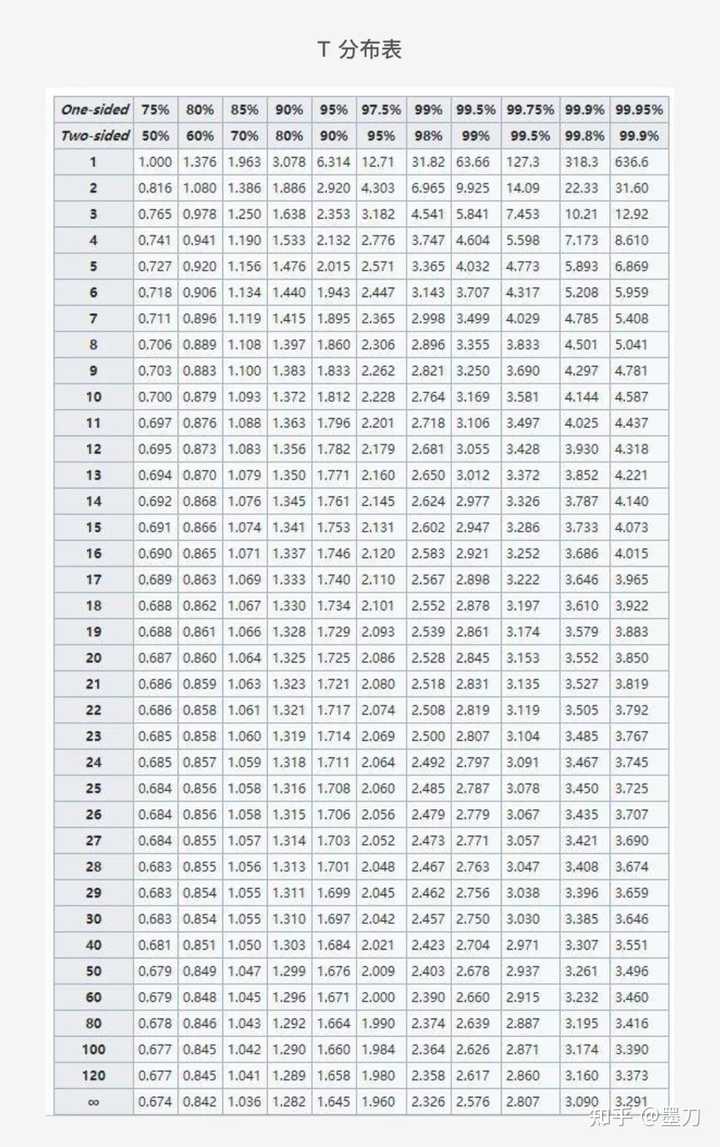



![[测试] 调查问卷相关测试](/images/no-images.jpg)