目录
前言
ChatGPT是什么?
ChatGPT为什么这么强
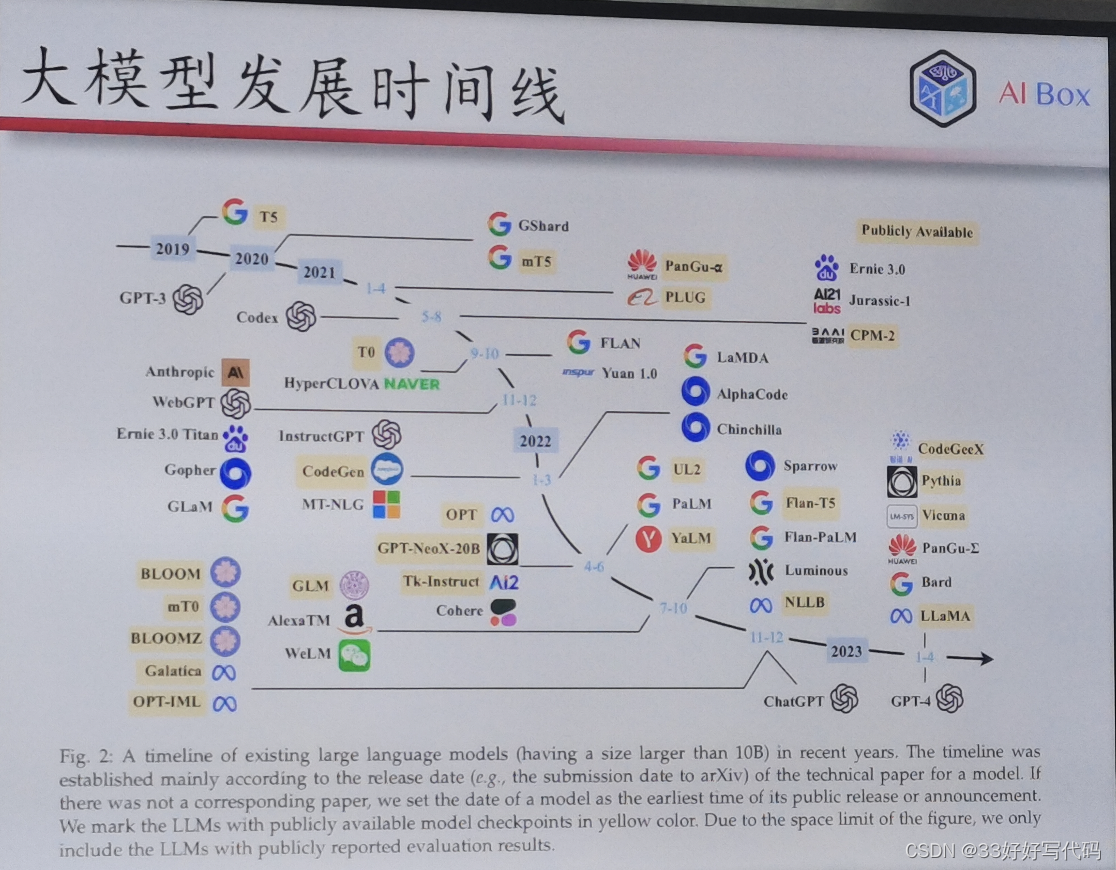
GPT系列发展历程
能力诱导微调
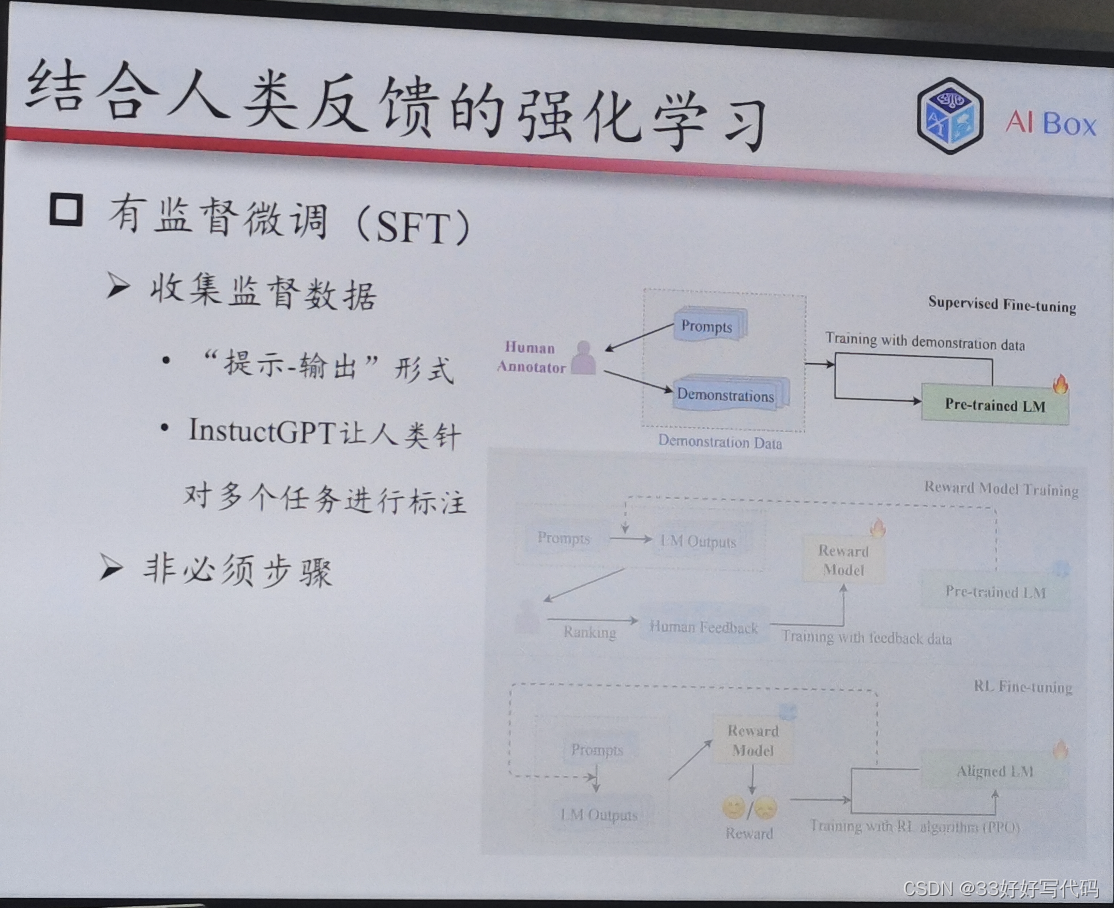
结合人类反馈的强化学习(RLHF)
编辑
大模型使用范式
情境学习编辑
思维链 编辑
Zero-shot Cot编辑
Planning
大模型关键技术
仍存在问题编辑
Q&A
写在最后
前言
写在前面···作为半个曾经的NLPer,我一直很想从原理,从Transformer开始然后从GPT1-4然后RLHF介绍ChatGPT。但是就是在实验室听了来自人大高瓴的赵鑫老师的分享之后,感觉老师是从一个很宏观很大的一个角度去思考ChatGPT,可能对技术了如指掌的人才可能跳出技术去往大方面想,而像我这种对技术不了解的人满眼都是技术实现细节,有点一叶障目不见泰山的感觉。
听了赵老师的分享后收获颇丰,打算记录下来也给大家分享一下,希望能给大家带来一些启发。
转侵删。
ChatGPT是什么?
浅模仿老师做了一个ppt
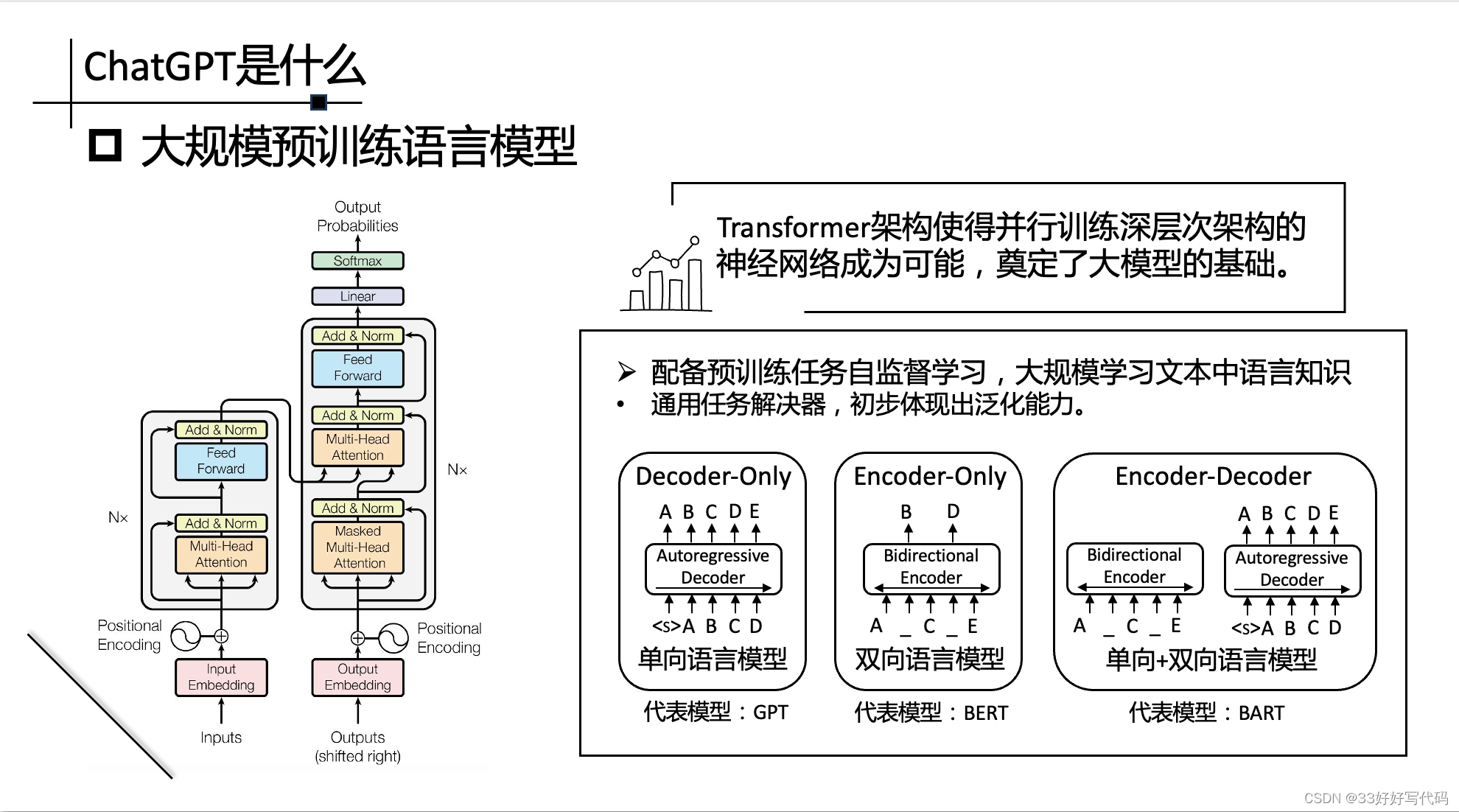
背后是大语言模型背后支撑的人工智能技术
ChatGPT为什么这么强
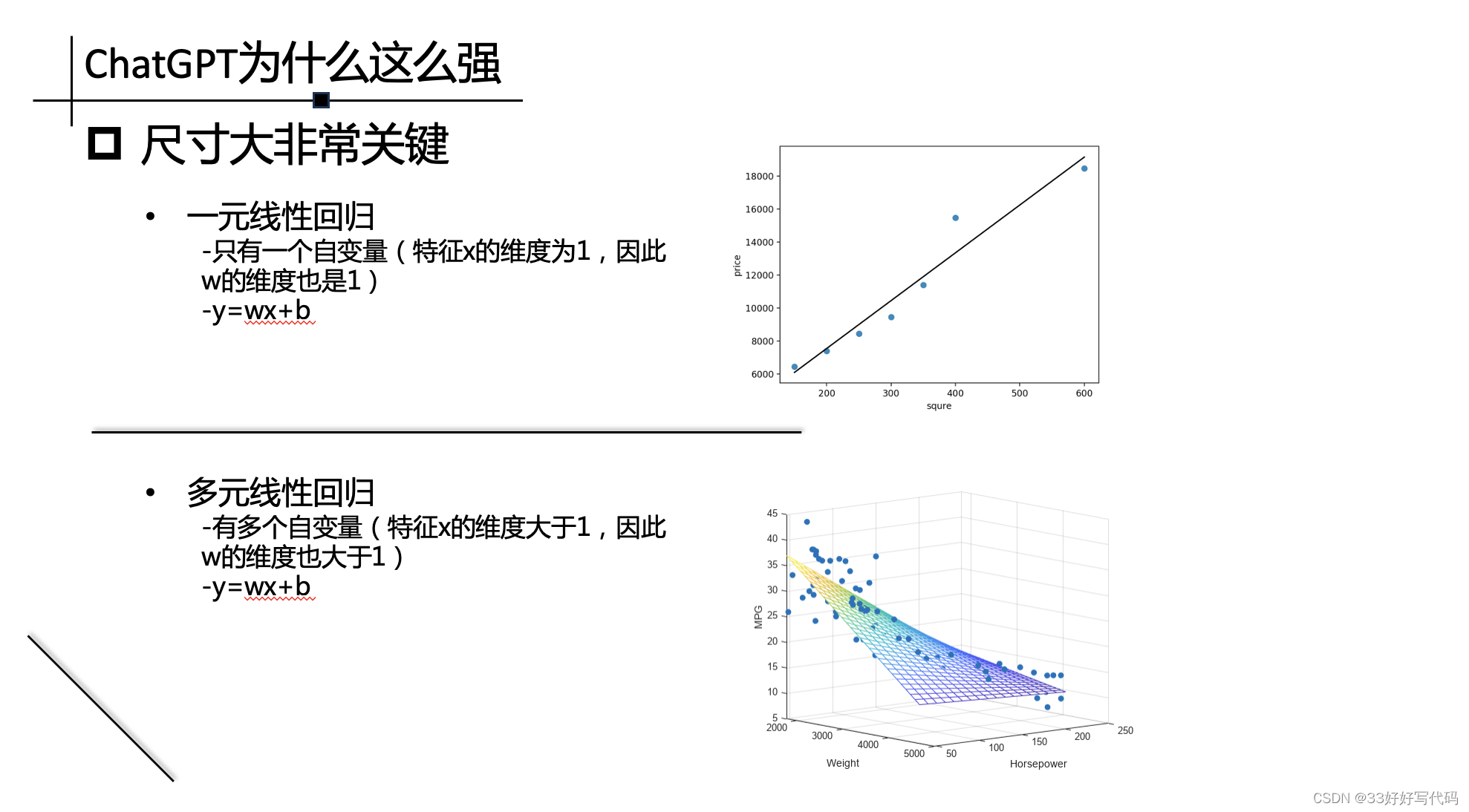
 Nlp model 做加大,有动机,增大算力数据量
Nlp model 做加大,有动机,增大算力数据量
大模型的涌现能力

多付出一些,有额外的收益,对于指数模型,最后都会出现边际递减
一开始加的他有很大收益,后边就小了,后期要付出很多
只有拓展法则收益不多,
20年有人做的paper,但没人去做
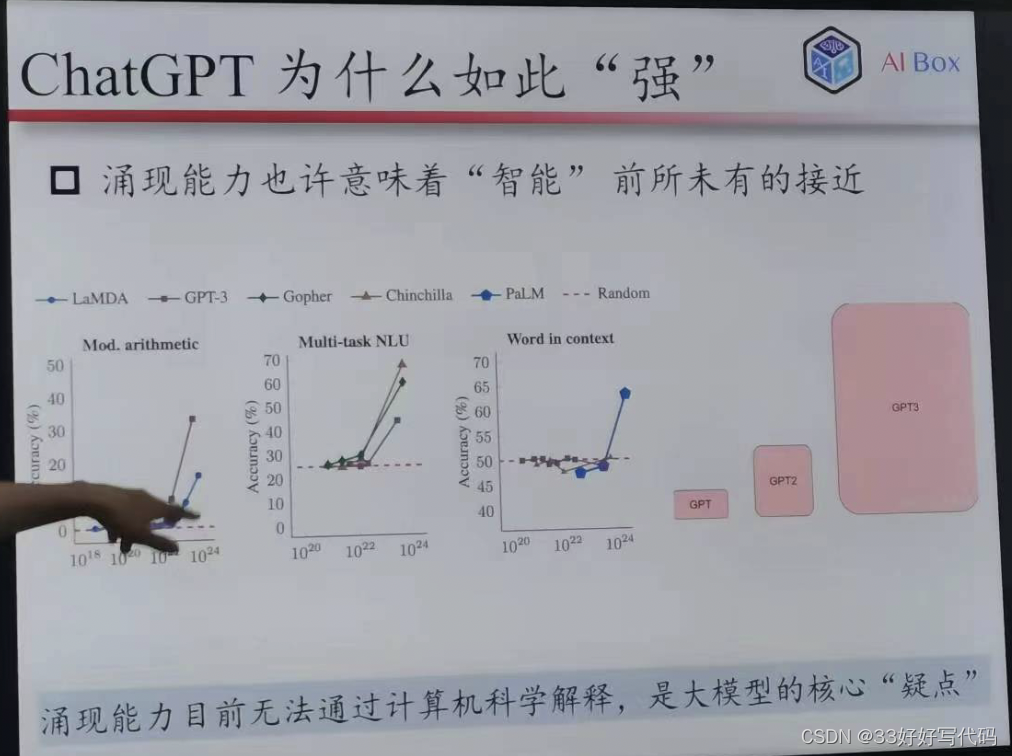
涌现能力——任务对模型困难
使大力就能干
有些任务把模型尺寸加大,就能做了
把模型加大能够解决一批无法解决的问题

你不知道最后会发生什么,不知道上限

多跳Q- A任务,模型至少不少于两层
任务很怪,取模运算啥的,很多无聊的任务
大模型就是能解决很多解决不了的东西,不论为什么

解释一下这个块。就是普通RNN对于大量数据的处理能力是不足的,举个例子🌰,给RNN一大堆数据,RNN可能只能吃掉了20%,剩下的它吃不下。因此大模型很多都是基于Transformer的Encoder- Decoder架构(Encoder- Only或者Decoder-Only也算),因为Transformer吃得下!
原始定义不太学术
代码差不多,喂的数据决定了模型的情况(喂多少,喂什么)
Token数量——要很多卡
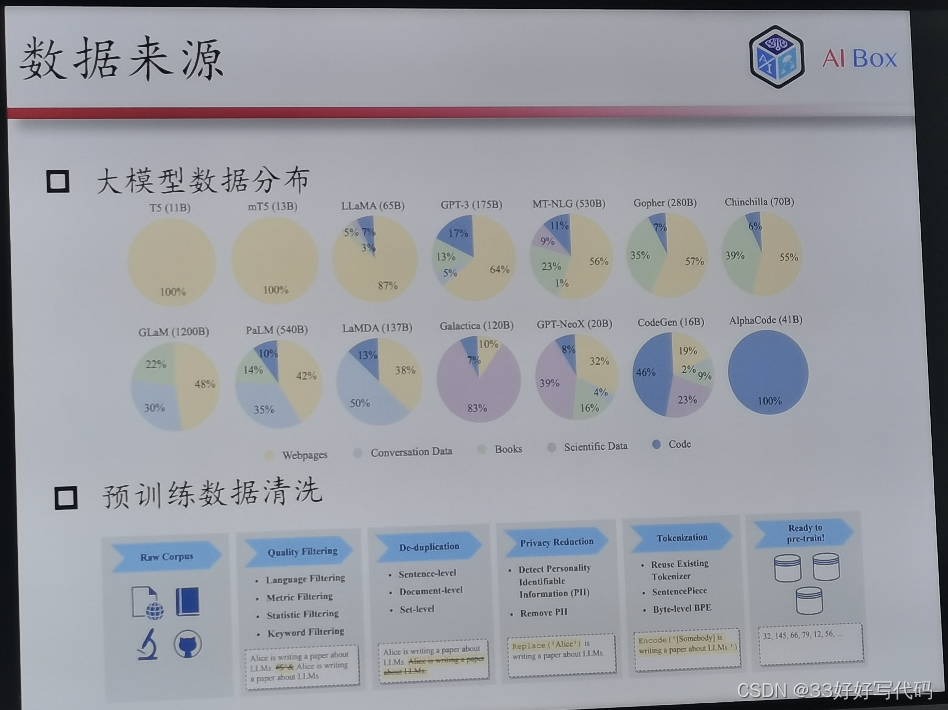
T5基于网页train,埃尔法code就全是代码
过滤低质量数据,去重,把隐私删掉
词云化,Token对应词典数大,tokenize不做有可能在下文遇见你不认识的词
GLM-6B-1.4T 的token

🌟在执行线上,gpt3没有训到位
不要把chatgpt当成模型,而是当成一个系统工——洗数据,分布式架构,36k16k(不是模型不止是炼丹和调参)

GPT系列发展历程

Openai2015成立
2016 在review上train 一个双向的lstm
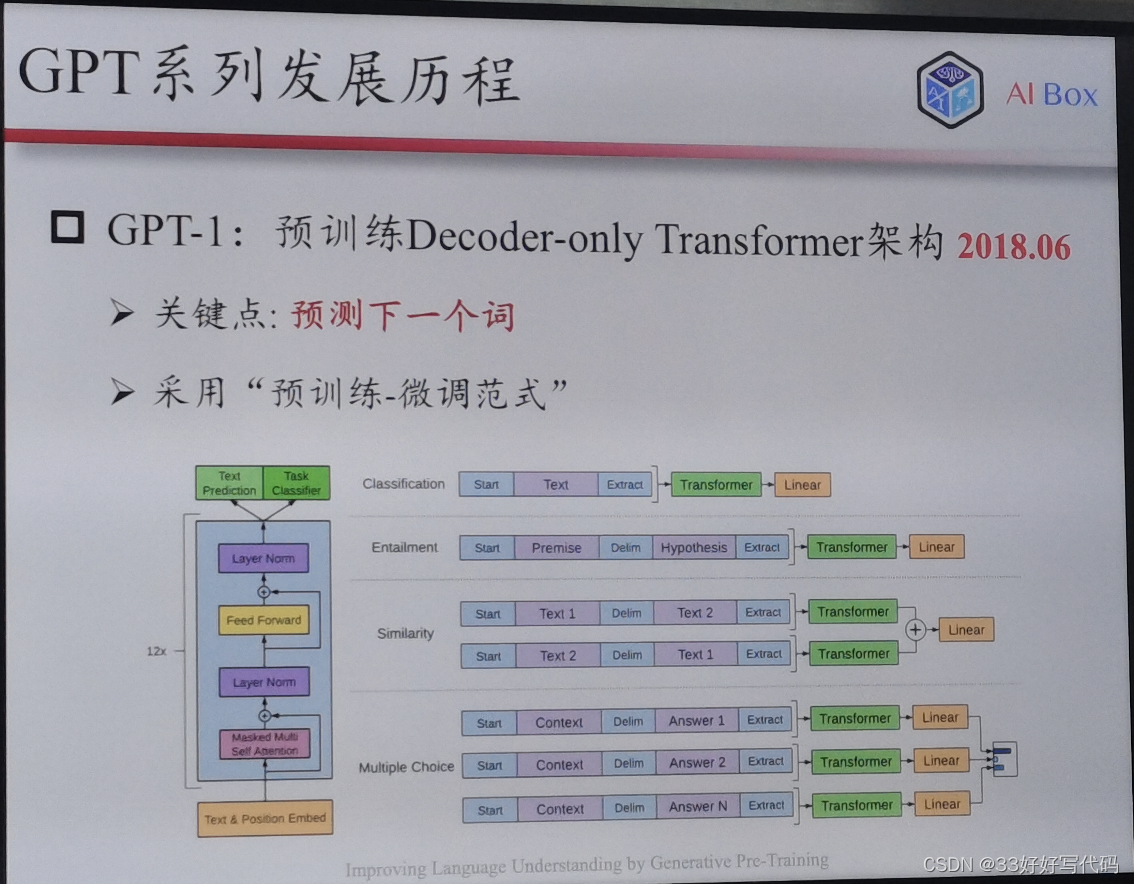

把decoder扣掉了,transformer说encoder- decoder是最好的。只有一个trick
Bert模式,下游比较丑陋
decoder-only管用
⚠️🌟!!!个人觉得全篇高光点!!!
这页PPT我愿意按字给钱!!!真的一语惊醒梦中人!!!

解决了多任务学习的问题,感觉这个是NLP领域得天独厚的优势。目前CV和图还未统一多任务学习的数据形式和任务目标,浅蹲未来三年的突破。(如果研究生有幸能做AI,浅浅许愿这个是我想出来的哈哈哈)

GPT2开通writing的,最好的一篇writing论文,虽然结果不惊艳
做scanning
一亿到十五亿参数
无监督多任务求解器
多任务学习(cnn也可做)
input,task刻画output
但是数据形式和目标难以统一(情感分类,识别)
全部自然语言表达
如果我pretrain预料覆盖度强,下游都是pretrain优化目标
子任务都是pretrain语料的优化目标
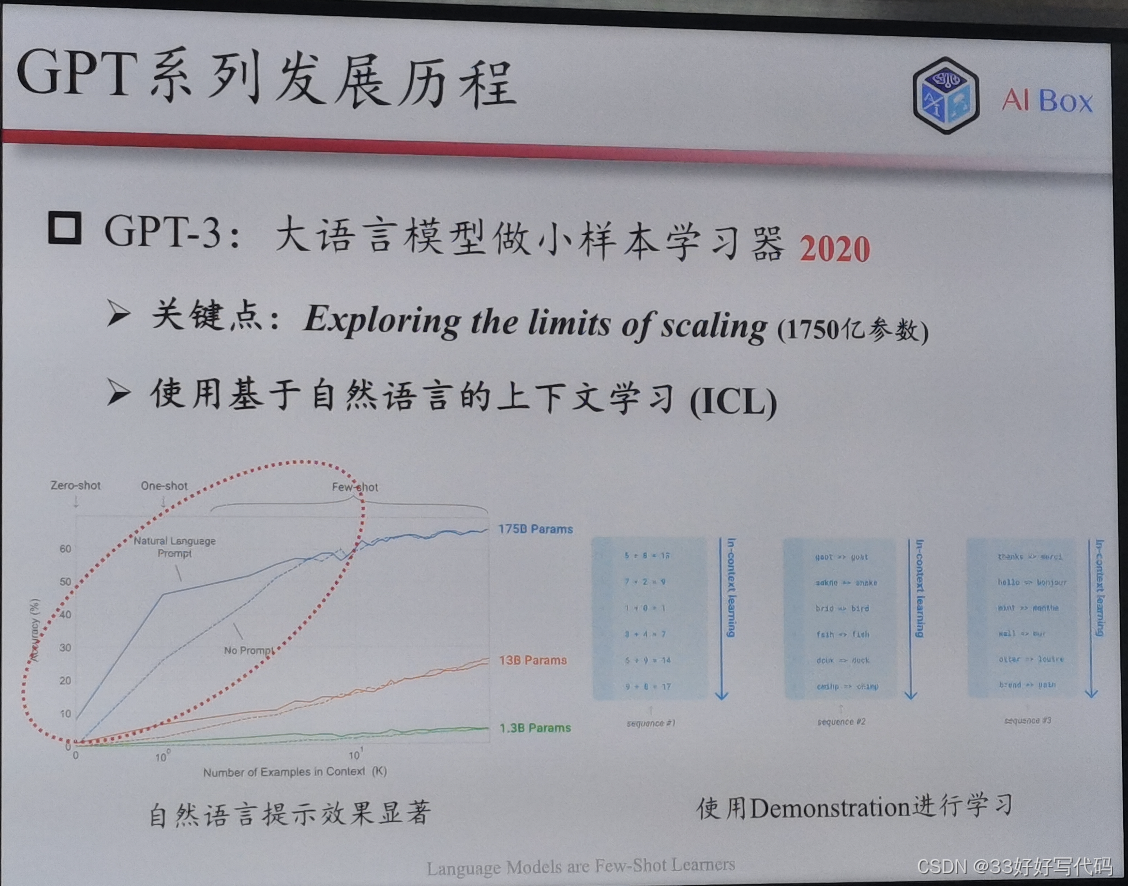
GPT3(few-shot learning)
能力强,但不能解决很多任务
样例放在提示里给模型去学

Codex:解数学题特别强,推理能力显著提升。
初代的不强,通过类似于code几轮训得越来越好


instructgpt和chatgpt同胞模型
Ins是一问一答,chat是用dialog进行优化。


Gpt3.5和gpt4平时一般,但题目一难,gpt4就强了

Scanning loss 用一点数据估计整个模型的参数,就很简便
预测下一个词的重要性(预测下一个词相当于把上述多任务学习的目标进行了一个统一)
相当于玩剧本杀,看完自己的剧本和已知知识推知凶手的名字。(不仅仅是预测一个词的生成任务,更可以进行逻辑分析作为解答)
能力诱导微调

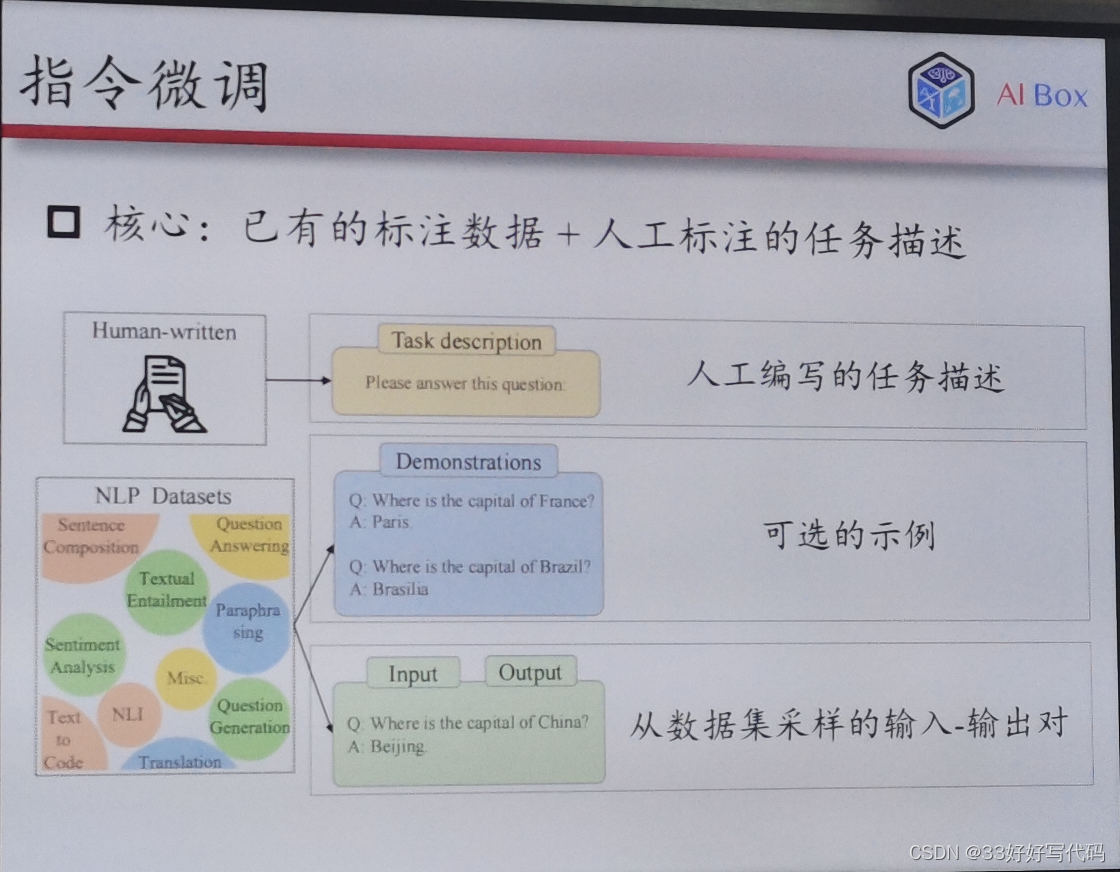
指令微调救不了模型推理差——文本
预测output拟合
让语言模型理解任务,输入输出去执行



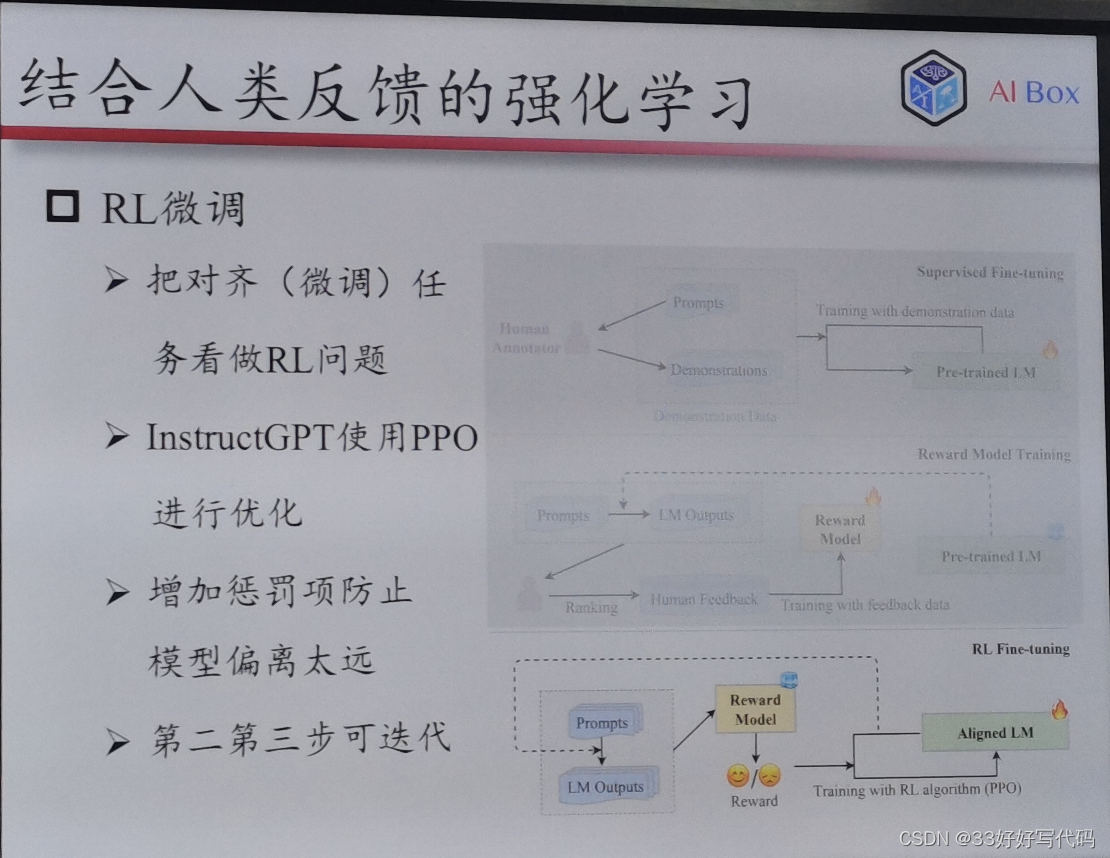
结合人类反馈的强化学习(RLHF)
老师这个RLHF的PPT做得太好了www等我有时间一定对标老师的这个PPT做一个我自己的www


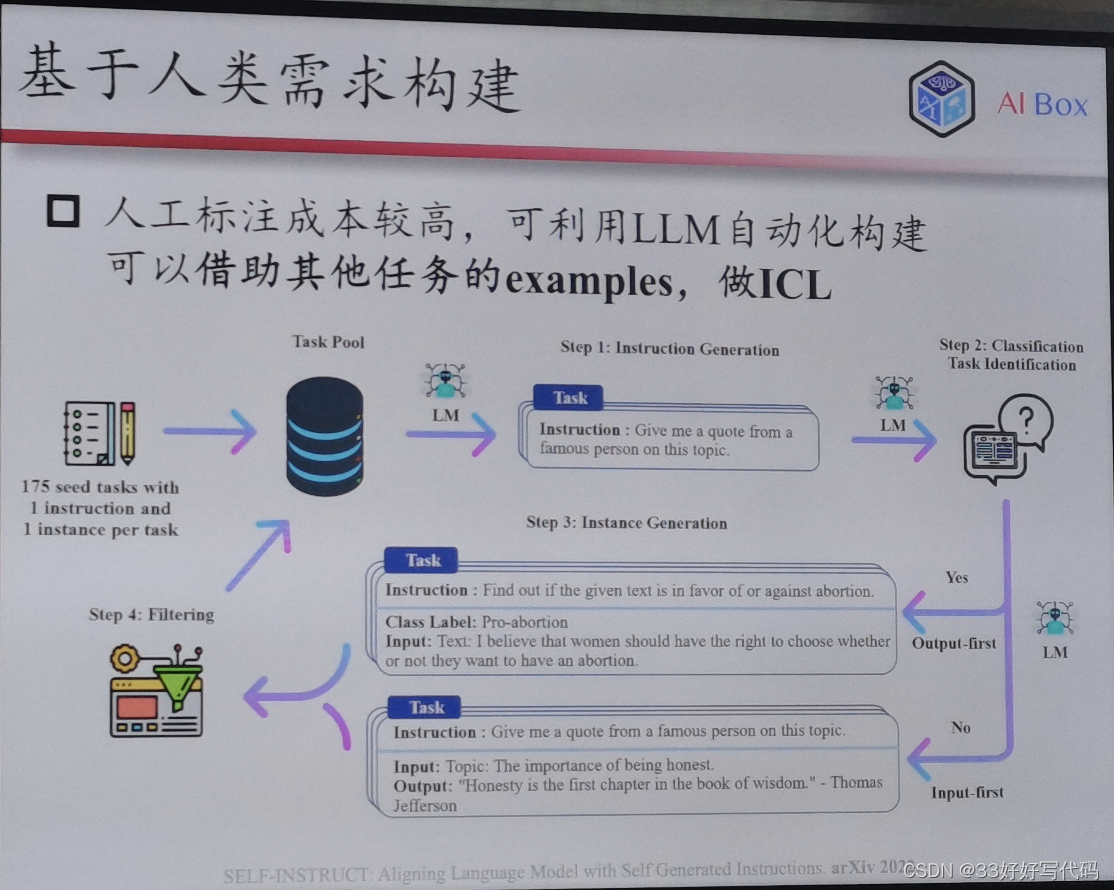
大模型可以给自己生成任务描述——self instruct
RLHF:2015年成立的做强化学习的,如何ppo(openai自研发的算法)
怎么让人在这个链路中发挥作用

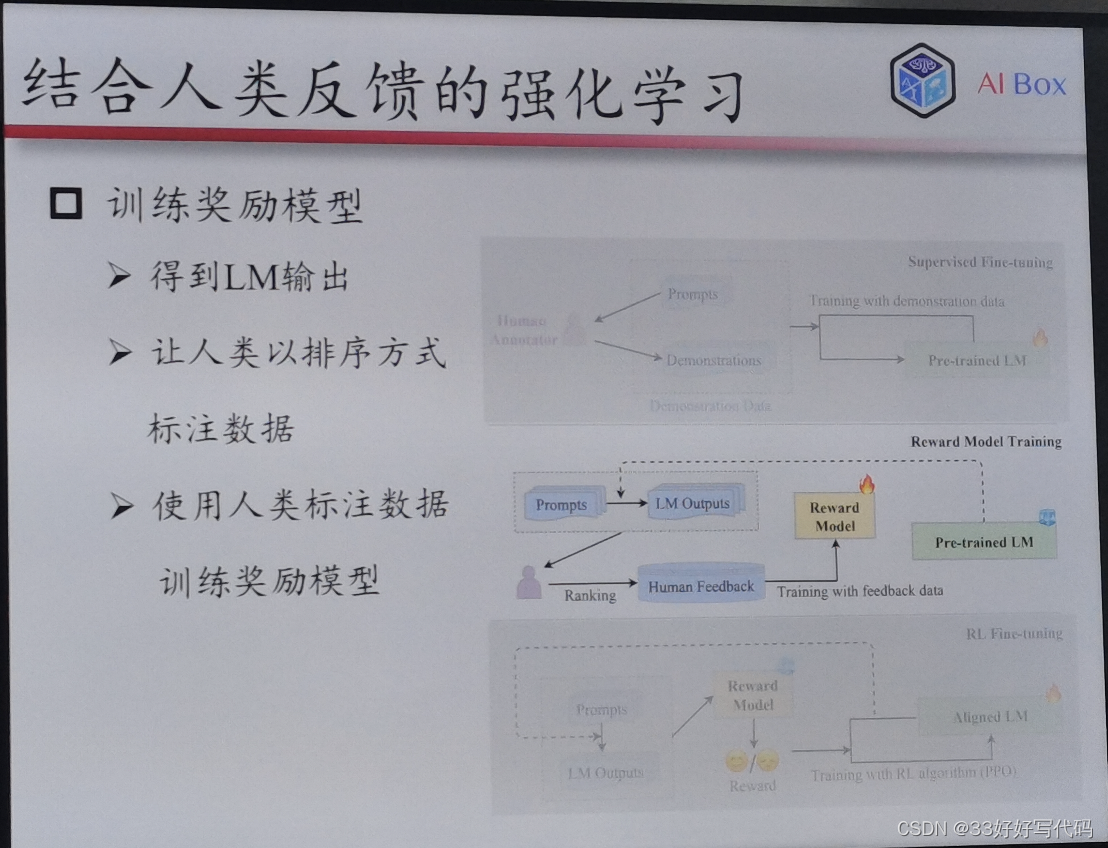
instruct tuning
Sft——指令微调
不是必须
大模型使用范式

情境学习
思维链 

Rlhf模型很少,难整
给的QA并不直接相关,大概懂得输入输出关系
隐式更新
Zero-shot Cot
zero shot:魔法咒语
有时候输出错的能对
大模型自己生成cot然后自己研究自己的cot
Planning

planning
一次搞不定
多次调用
任务规划生成plan执行修正plan
大模型关键技术

仍存在问题
底层理论:没有理论支撑
幻象:生成一些不正确的事实,也很难识别自己的幻象
评测方法:评的都是选择填空的榜,衡量知识维度是有帮助,但是gpt就没法比了,选项只会拉大和gpt的差距
知识更新困难:硬性扩展成中文,不合适
结构化生成:插件、数据库接口
Lama:生成推理弄没了
轻量化部署:还是比较困难
最后推荐一下赵老师实验室的大模型综述文章~

Q&A
最终范式:预测下一次会不会是最好的,可能会有优势,有限参数用于生成一件事上,e-d也有他的优势。本来算力就不够也不太会做探索,会持续比较久。
关于encoder作用:
Glm-130b就是前缀encoder
有很多问题,错了停不下来了,没法控制
对于深度学习来说,数据还是模型更重要?
不是所有模型可以把知识都吃住,图尽管很多,但是架构不一定能全吃进去,transforemer可以吃更多,rnn会丢。
解一堆任务——必是数据重要的,光靠模型非常难。alphago最多下个围棋
幻象:是自回归decoder原因?幻象原理不好解释,但是小模型几百兆模型比较弱,也和创造力有关。
没有解决幻象,控制不住!
但是存在幻象并不是评价一个模型的主要因素。正因为模型本身具有创造力,才会导致幻象的出现。小模型根本连出现幻象的机会都没有。
做量化,稀疏transformer做一些稀疏架构,不容易做成,剪枝简单,并行难。稀疏化做更深一点
Nlp暂时领先,会有一堆mini模型以语言为基础,大模型和图接口,没有统一方式去建模。多任务多种数据形式用文本搞定了,图片视频很困难。cv没有大模型,图也没有大模型,不一定会绑定,比较吃力。
推荐领域:窗口有限,ide文本化会丢掉很多信息,噪音多,只认文本,不认id,设计预训练
人类知道现实和幻象,都是隐式存在,回到确定性发展。大模型很不自主,不知道什么时候用的是对的什么是错的。随机生成的好,但是会有幻象。但他自己识别不出幻象。加指令微调可以,但能固化的知识有限。
能做的:领域适配,知识更新。
小模型没有全参数大模型好。
特定任务超过他
为什么做大,做大有什么好处都没想清楚。
数据多能记得住,语义性差一点,内在逻辑是什么,结构知识的迁移性是很弱的。
任务的通用性,用什么模式可以解决通用问题
对一个问题设定优化目标,其他任务用其他优化目标。但是他针对了多任务(我觉得是语言模型最本质的特点)
找到本质任务大图就做出来了
人大大模型是指令微调,耗卡,全自主做基座
真正做学术探索很少 百亿规模
写细节
写在最后
本来想好好总结一下写这篇博客的,但是最近太忙太忙了。只能把分享会上的ppt截图和分享会时的零碎感想放上来,并没有做自己的总结以及自己的ppt。
等我闲下来一定好好总结一下做一个自己的介绍,最好能兼顾赵老师的这些思路以及部分实现细节(毕竟大家也不都是NLP大佬),希望我的NLP学习之路不会烂尾。
最后一句话写给自己,不论最后能不能学AI,也不要放弃心中对AI的热爱🫶,努力更上技术迭代,即使作为旁观者。