本文仅作为个人阅读文献,做笔记记录。
<>
\usepackage[dvipsnames]{xcolor}
一、摘要部分:
我们发现,现有的数据集偏向于局部结构异常,如划痕、凹痕或污染。特别是,它们缺乏违反逻辑约束形式的异常,例如,允许的对象出现在无效位置。
这篇文章贡献了新的异常检测数据集用于检测局部的结构异常和全局的逻辑异常。
提出一种种新的算法:在结构和逻辑异常的联合检测方面优于现有技术。该技术由局部和全局网络分支组成。第一个分支检查与输入图像中的空间位置无关的受限区域,并且主要负责检测全新的局部结构。第二个分支学习通过瓶颈的训练数据的全局一致性表示,该瓶颈能够检测到违反长范围依赖关系的情况,该长范围依赖关系是许多逻辑异常的关键特征。
二、概念介绍
那么什么是结构异常,什么是逻辑异常呢?
以下图为例:
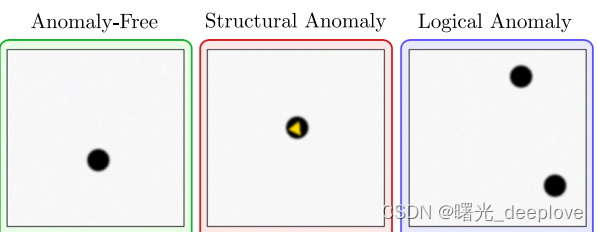
图中,最左边是无异常的ok图,中间出现颜色变化的,这种就是属于结构异常,最右边的是颜色、形状这些都没变化,变化的是小黑圆圈的数量。
现有的大量最先进的无监督异常检测方法都是通过提取预训练网络的局部特征分布来进行建模的。
这些异常检测方法擅长检测MVTec Logical Costraints Anomaly Detection(MVTec LOCO AD) 数据集上的颜色等局部特征。但是这些方法天然地会受限于特征描述符的感受野之内的信息,这就让它难以检测那些违反长范围依赖的异常。
感受野本身由于是局部描述,因此不足以理解图像中的长范围长距离关系依赖!
由于一些VAEs或者GANs的方法具备捕捉整张图像的信息的潜在能力,因此他们可以潜在地检测出上图中最右边多出一个圆圈这种异常。但是这些方法会倾向于产生一些模糊和不准确的重构(这就会导致增加误检),当然这些方法通常会在检测逻辑异常上会优于上面提到的局部特征方法。
三、动机以及文章贡献
基于以上,论文中将异常分为了结构异常和逻辑异常,并且说明了现存方法在两种类型的异常的不同表现。
文中将结构异常定义为:出现在局部限制区域中并且在无异常数据中不存在的新视觉结构。如:颜色变化
文中将逻辑异常定义为:违反了数据中的底层逻辑约束,并且可能需要一种方法来捕获长范围长距离依赖性。例如,电路接线错误、小瓶液位变化或缺少基本组件。
文章贡献点:
(1)引入一个同时覆盖结构和逻辑异常的无监督的新数据集用于评估无监督定位算法。
它包含 5 个不同对象类别的 3644 张图像,灵感来自现实世界的工业检测场景。 结构异常表现为制造产品中的划痕、凹痕或污染。 逻辑异常违反了底层约束,例如,一个允许的对象出现在一个无效的位置,或者一个必要的对象根本不存在。
(2)为了比较我们数据集上不同方法的性能,需要合适的性能度量。 文中发现常用指标不能直接用于评估方法检测逻辑异常的能力。 为此,文章引入了一个性能指标,它采用不同的模式,考虑到数据集中存在的缺陷。 此性能度量是对无监督异常检测的既定度量的概括。
(3)
提出了一种新的方法来对异常进行无监督的像素精确定位。 与现有方法相比,它改进了结构和逻辑异常联合检测的结果。 该方法由一个局部分支和一个全局分支组成,以上分支分别负责检测结构和逻辑异常,受最近成功使用预训练网络的局部特征进行异常检测的启发,我们的局部分支包含一个匹配此类局部描述符的回归网络。 提出方法的全局分支旨在通过一个瓶颈学习训练数据的全局一致性表示来克服捕获输入图像的整个上下文的困难。 在推理过程中,两个分支中的回归错误表明存在异常。 针对最先进方法的广泛评估显示了我们的方法在检测逻辑异常以及两种异常类型的组合定位方面的优越性。
三、方法技术
文献中除了提出MVTec LOCO AD数据集,还提出了GCAD (Global Context Anomaly Detection)方法,
该方法可以同时检测结构异常和逻辑异常。
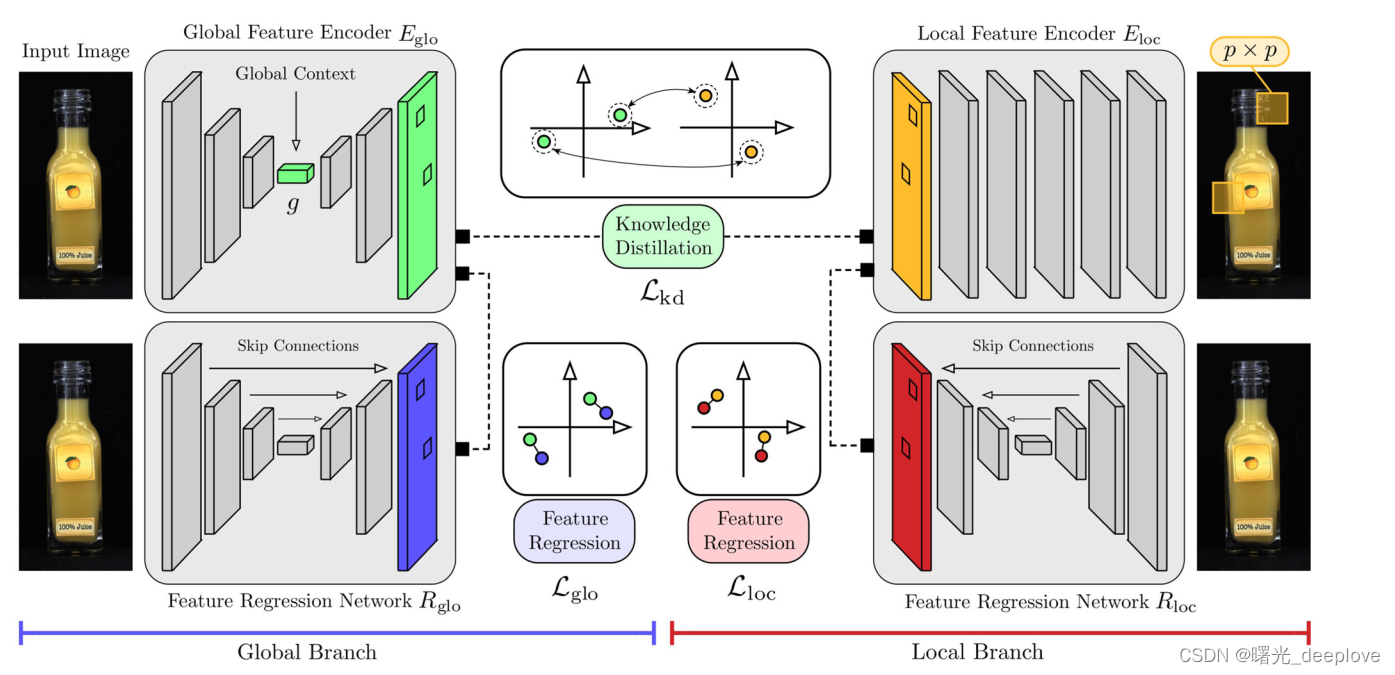
一个全局特征编码器 E g l o E _ {glo} Eglo是由预训练的局部特征编码器 E l o c E _ {loc} Eloc进行训练的得到的( E g l o E _ {glo} Eglo通过一个瓶颈层来捕获无异常训练数据的全局上下文)。
E g l o E _ {glo} Eglo和 R g l o R _ {glo} Rglo的联合训练,通过低维瓶颈促进高维特征的精准匹配。
3.1 Local Model Branch:
局部模型分支。该分支主要受到最近成功的异常分割方法的推动,该方法从预训练的 CNN 中提取的局部特征的分布进行建模。 这类方法在已建立的异常定位基准上实现了最先进的性能,其中大多数异常符合我们对结构异常的定义。
文中模型的这个分支是基于学生-教师方法的。 由于此方法计算图像中的局部受限区域的异常分数,而与其在输入图像中的空间位置无关,因此我们将此分支称为模型的局部分支。
它由一个编码器网络 E l o c E _ {loc} Eloc组成,该网络在从 ImageNet 数据集裁剪的大量图像块上进行了预训练。 在预训练期间,鼓励 E l o c E _ {loc} Eloc通过从预训练分类网络中进行知识蒸馏来提取局部图像块的表达描述符。本文是将在ImageNet上训练的ResNet-18分类器蒸馏成一个稠密块特征描述符网络(通过快速稠密特征提取技术)。 E l o c E _ {loc} Eloc的网络架构和以及ImageNet 上的预训练协议的详细描述可以在原始的 Student-Teacher 论文中找到。
注意:预训练完成后,当优化文中提出的异常检测模型的时候固定 E l o c E _ {loc} Eloc的权重。用公式表达即:
在每个像素位置上, E l o c E _ {loc} Eloc都生成一个 d l o c d _ {loc} dloc维的一个特征描述子。即
E l o c ( I ) ∈ R w × h × d l o c E _ {loc}(I)\in\mathbb{R}^{w\times h\times d _ {loc}} Eloc(I)∈Rw×h×dloc.
每一个特征都描述了一个局部的原图输入影像的 p × p p\times p p×p区域的图像块。
局部分支还包含回归网络 R l o c R _ {loc} Rloc,其用随机权重初始化并被训练以匹配 E l o c E _ {loc} Eloc在无异常训练数据上的输出。它输出一个形状与 E l o c E _ {loc} Eloc生成的形状相同的特征图,即: R l o c ( I ) ∈ R w × h × d l o c R _ {loc}(I)\in\mathbb{R}^{w\times h\times d _ {loc}} Rloc(I)∈Rw×h×dloc.我们使用具有跳跃连接的高容量网络来完成此任务,并最小化Frobenius范数的平方:
L l o c ( I ) L _ {loc}(I) Lloc(I) = ∥ \lVert ∥ E l o c ( I ) E _ {loc}(I) Eloc(I) - R l o c ( I ) R _ {loc}(I) Rloc(I) ∥ \rVert ∥ F 2 {_ {F}^2} F2.
如果在推理过程中,图像包含在训练过程中未观察到的新的局部结构,并且这些结构落入预训练的特征提取器的感受野内,则 E l o c E _ {loc} Eloc将产生 R l o c R _ {loc} Rloc不熟悉的新的局部特征描述符。这会导致很大的回归误差。因此,我们期望我们模型的局部分支在检测结构异常方面表现良好。
3.2 Global Model Branch:
E l o c E _ {loc} Eloc只检查大小为 p × p p\times p p×p像素大小的有限感受野,特别地, E l o c E _ {loc} Eloc是不编码提取的训练特征的位置组成。因此,我们的局部分支天生地就不适合检测那些违背具备长范围长距离依赖关系的异常,这个长距离依赖关系是许多逻辑异常的特征,例如输入图像中目标丢失或者目标额外增多。为了解决这个问题,论文中就在模型中增加了第二个分支用来分析整幅图像的全局上下文。因此,我们将这个新分支称为全局分支。它的设计灵感来自图1中的观察结果,即将输入数据压缩到低维瓶颈的方法具有捕获逻辑约束的能力,并且无法重新生成违反逻辑约束的输入图像。
论文中全局分支由两个网络 E g l o E _ {glo} Eglo和 R g l o R _ {glo} Rglo组成。 E l o g E _ {log} Elog是一个编码器网络,它在每个像素位置产生维度为 d g l o d _ {glo} dglo的描述符, E g l o ( I ) ∈ R w × h × d g l o E _ {glo}(I)\in\mathbb{R}^{w\times h\times d _ {glo}} Eglo(I)∈Rw×h×dglo.
与自动编码器类似,鼓励 E g l o E _ {glo} Eglo生成与训练数据全局一致的特征图。为此, E g l o E _ {glo} Eglo在g维的低维瓶颈上进行编码。与自动编码器相反, E g l o E _ {glo} Eglo不会重建输入图像。它是通过将局部特征编码器 E l o c E _ {loc} Eloc的知识来蒸馏提取到全局分支来进行训练!
为了让 E g l o E _ {glo} Eglo的特征描述符与 E l o c E _ {loc} Eloc的输出层维度相匹配,我们引入一个上采样网络 U U U,它执行一系列 1 × 1 1\times1 1×1的卷积。对于训练,我们最小化:
L k d ( I ) L _ {kd}(I) Lkd(I) = ∥ \lVert ∥ E l o c ( I ) E _ {loc}(I) Eloc(I) - U ( E g l o ( I ) ) U(E _ {glo}(I)) U(Eglo(I)) ∥ \rVert ∥ F 2 {_ {F}^2} F2.
原则上,可以通过将 E l o c E _ {loc} Eloc的特征直接与 U ο E g l o U\omicron E _ {glo} UοEglo的特征进行比较来进行计算异常分数。然而,我们的消融实验研究表明由于 E g l o E _ {glo} Eglo的低维度的瓶颈层,所以高维度的且详细的 E l o c E _ {loc} Eloc特征图只能由 E g l o E _ {glo} Eglo来近似复现生成。直接进行比较的话,由于不正确的特征重构,将会导致在异常图中出现许多误检。为了避免这个问题,全局分支的第二个网络 R g l o R _ {glo} Rglo被训练为使用损失项来匹配 E g l o E _ {glo} Eglo的输出,使用的损失项为:
L g l o ( I ) L _ {glo}(I) Lglo(I) = ∥ \lVert ∥ E g l o ( I ) E _ {glo}(I) Eglo(I) - R g l o ( I ) R _ {glo}(I) Rglo(I) ∥ \rVert ∥ F 2 {_ {F}^2} F2.
其中 R g l o R _ {glo} Rglo旨在将局部图像区域精确地变换为相应的特征向量,而不考虑训练数据的潜在逻辑约束。为了实现这一点, R g l o R _ {glo} Rglo不包含任何瓶颈层,并且被设计为带有跳跃连接的高容量网络。
备注:高容量网络可以理解为:网络中的神经单元数非常多,层数越多,神经网络的拟合能力越强。但是训练速度,难度越大,越容易产生过拟合。其中网络容量可以认为与网络的可训练参数成正比,也可以理解为高容量的网络就是参数量很大的网络! \color{Red}{备注:高容量网络可以理解为:网络中的神经单元数非常多,层数越多,神经网络的拟合能力越强。但是训练速度,难度越大,越容易产生过拟合。其中网络容量可以认为与网络的可训练参数成正比,也可以理解为高容量的网络就是参数量很大的网络!} 备注:高容量网络可以理解为:网络中的神经单元数非常多,层数越多,神经网络的拟合能力越强。但是训练速度,难度越大,越容易产生过拟合。其中网络容量可以认为与网络的可训练参数成正比,也可以理解为高容量的网络就是参数量很大的网络!
E g l o E _ {glo} Eglo和 R g l o R _ {glo} Rglo之间结构的差异在我们的方法中是非常重要的。 R g l o R _ {glo} Rglo的高容量使得它可以准确地重构 E g l o E _ {glo} Eglo的特征,这点与 E g l o E _ {glo} Eglo和 U ο E g l o U\omicron E _ {glo} UοEglo之间的重构误差进行比较可以减少误检的数量。跳跃连接使得 R g l o R _ {glo} Rglo能够在不捕获训练数据的全局上下文的情况下解决回归任务。因此,对于违反全局约束的异常测试图像, E g l o E _ {glo} Eglo和 R g l o R _ {glo} Rglo的输出不同。这点可以获取(需要分析长范围(长距离)依赖关系的)逻辑异常的定位。
3.3 Combination of the Two Branches:
我们端到端地使用单个损失项的累加所得的和训练整个模型,整个单个损失项是分别通过被匹配的特征的深度来进行的归一化,即:
L ( I ) L (I) L(I) = 1 d l o c L k d ( I ) \frac{1}{d _ {loc}}L _ {kd}(I) dloc1Lkd(I) + 1 d g l o L g l o ( I ) \frac{1}{d _ {glo}}L _ {glo}(I) dglo1Lglo(I) + 1 d l o c L l o c ( I ) \frac{1}{d _ {loc}}L _ {loc}(I) dloc1Lloc(I) .
由于 L k d L _ {kd} Lkd和 L g l o L _ {glo} Lglo的联合优化,这个全局特征编码器被鼓励去学习训练数据的有意义的描述符,并同时输出可以被特征回归网络容易匹配的表示。在学习的特征空间中计算残差有助于通过低维瓶颈对更高维度的特征进行精确匹配。
3.4 Scoring Functions for Anomaly Localization
在推理过程中,可以通过将图像编码器网络的特征与相对应的回归网络的特征进行比较来计算测试图像 J ∈ R w × h × n J\in\mathbb{R}^{w\times h\times n} J∈Rw×h×n的逐像素异常的分数,即分别通过以下计算:
A l o c A _ {loc} Aloc = ∥ \lVert ∥ E l o c ( J ) E _ {loc}(J) Eloc(J) - R l o c ( J ) R _ {loc}(J) Rloc(J) ∥ \rVert ∥ 2 {^2} 2 ∈ R w × h \in\mathbb{R}^{w\times h} ∈Rw×h.
A g l o A _ {glo} Aglo = ∥ \lVert ∥ E g l o ( J ) E _ {glo}(J) Eglo(J) - R g l o ( J ) R _ {glo}(J) Rglo(J) ∥ \rVert ∥ 2 {^2} 2 ∈ R w × h \in\mathbb{R}^{w\times h} ∈Rw×h.
这儿,范数取在各自的特征维度( d l o c d _ {loc} dloc和 d g l o d _ {glo} dglo)上。回归误差大表示有异常的像素。 A l o c A _ {loc} Aloc主要负责检测结构异常的, A g l o A _ {glo} Aglo主要负责检测网络的逻辑异常的。
由于 E g l o E _ {glo} Eglo和 R g l o R _ {glo} Rglo网络的权重都是被随机初始化的,因此不存在对于两个网络在结构异常上表现不同这种训练动机。论文中的实验表明:全局分支确实是主要负责检测逻辑异常,然而局部分支在检测结构异常上表现得更好。
为了得到整个模型得异常图,我们在训练后计算验证集中所有图像 I I I的 A l o c ( I ) A _ {loc}(I) Aloc(I)和 A g l o ( I ) A _ {glo}(I) Aglo(I)。
我们然后分别计算所有图片的结果分数的均值 μ l o c \mu _ {loc} μloc、 μ g l o \mu _ {glo} μglo以及标准差 σ l o c \sigma _{loc} σloc、 σ g l o \sigma _{glo} σglo。
在推理阶段,我们归一化单独的异常分数图并且定义这个组合异常分数图,如下:
A A A = A l o c − μ l o c σ l o c \frac{A _ {loc} - \mu _ {loc}}{\sigma _ {loc}} σlocAloc−μloc + A g l o − μ g l o σ g l o \frac{A _ {glo} - \mu _ {glo}}{\sigma _ {glo}} σgloAglo−μglo.
注意我们数据集中的验证集仅仅包含无异常的影像。这里,我们使用相对应的异常图像仅仅是为了去调节两个分支的异常分数的尺度值。
3.5 Anomaly Detection on Multiple Scales
对于 E l o c {E _ {loc}} Eloc的感受野大小 p p p的选择,这个是对于异常定位的性能是有非常大的影响的,特别地是当异常对象的尺寸变化非常大的时候。为了更少地依赖感受野大小的特殊选择,我们在多个感受野大小 p p p下训练了多个模型。
然后通过计算这些模型对应的异常分数图的逐像素的平均值来将这些模型的异常分数图进行结合。
设 p p p是所有评估的感受野的集合,且 A ( p ) A^{(p)} A(p)是从具有 p ∈ P p\in P p∈P大小感受野模型所获得的异常图。
不同感受野对应的异常分数图是通过计算 1 [ p ] Σ p ∈ P A ( p ) \frac{1}{[p]}{\Sigma} _ {p\in P}A^{(p)} [p]1Σp∈PA(p) .
四、全局特征编码器 E g l o E_ {glo} Eglo的网络结构
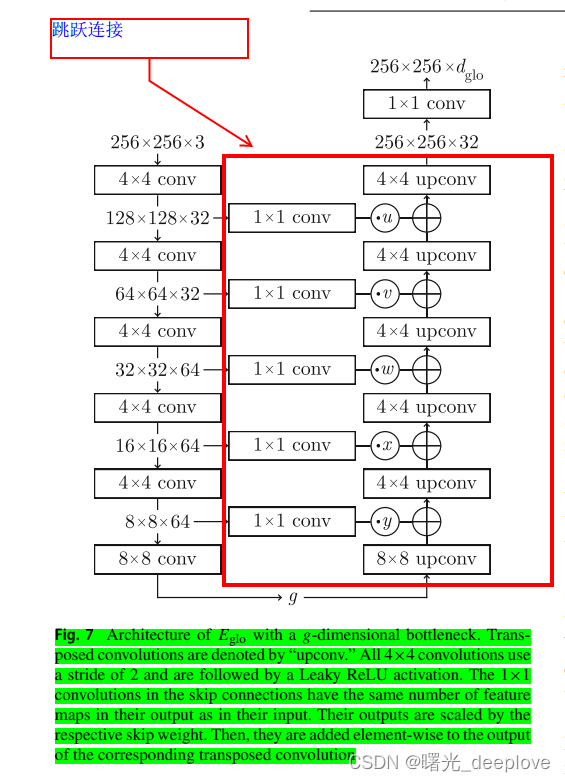
E g l o E_ {glo} Eglo输出的 d g l o d_ {glo} dglo特征通过一个上采样网络 U U U转换为 d l o c d_ {loc} dloc特征。这个上采样网络 U U U是由3个带有非线性激活函数的 1 × 1 1\times1 1×1卷积组成。
上采样网络 U U U的输出与与预训练网络 E l o c E_ {loc} Eloc给出的描述符相匹配。最后,两个回归网络 R l o c R_ {loc} Rloc和 R g l o R_ {glo} Rglo有一个与U-Net相似的结构。
这个与U-Net相似的结构我们使用了一个可公开访问的实现( https://github.com/jvanvugt/pytorch-unet.),其中包括五个下采样块、五个上采样块和一个大小为16×16×1024的瓶颈。
在训练之前,我们对预训练的网络 E l o c E_ {loc} Eloc的特征进行归一化。对于每个 d l o c d_ {loc} dloc特征维度,我们计算训练数据集上所有描述符的平均值和标准差。然后我们更新 E l o c E_ {loc} Eloc的最后一层的权重参数去输出归一化后的特征。
在头50轮次训练,我们仅仅训练全局特征编码器 E g l o E_ {glo} Eglo、上采样网络 U U U和局部回归网络 R l o c R_ {loc} Rloc;在剩下的450轮次训练中,优化全局回归网络 R g l o R_ {glo} Rglo。
五、局部特征编码器 E l o c E_ {loc} Eloc的网络结构
使用的网络架构和训练配置与(Bergmann, P., Fauser, M., Sattlegger, D., & Steger, C. (2020). Uninformed students: Student–teacher anomaly detection with discriminative latent embeddings. In 2020 IEEE/CVF Conference on
Computer Vision and Pattern Recognition (CVPR), pp 4182–4191.)
是一样的。
未完待续。。。。