文章目录
- 反射相关【4】
- 基础数据类型相关【38】
- 和数字相关(14)
- 数据类型 <4>
- ==bool([x])==
- ==int((x, base=10)==
- ==float([x])==
- ==complex([real[, imag]])==
- 进制转换 <3>
- ==bin(x)==
- ==oct(x)==
- ==hex(x)==
- 数学运算(7)
- ==abs(x)==
- ==divmod(a, b)==
- ==round(x [, n] )==
- ==pow(x, y[, z])==
- ==sum(iterable[, start])==
- ==min( x, y, z, .... )==
- ==max( x, y, z, .... )==
- 和数据结构相关(24)
- 序列 <13>
- 列表和元组 2
- ==list(tup)==
- ==tuple(iterable)==
- 相关内置函数 2
- ==reversed(list)==
- ==slice(start, stop[, step])==
- 字符串 9
- ==str()==
- ==format()==
- ==bytes== 【已废弃】
- ==bytearry==
- ==memoryview(obj)==
- ==ord\(c\)==
- ==chr(i)==
- ==ascii\(c\)==
- ==repr(object)==
- 数据集合 <3>
- 字典 1
- ==dict()==
- 集合 2
- ==set([iterable])==
- ==frozenset([iterable])==
- 相关内置函数 <8>
- ==len(s)==
- ==sorted(iterable, key=None, reverse=False)==
- ==enumerate(sequence, [start=0])==
- ==all(iterable)==
- ==any(iterable)==
- ==zip([iterable, ...])==
- ==filter(function, iterable)==
- ==map(function, iterable, ...)==
- 作用域相关【2】
- ==locals()==
- ==globals()==
- 面向对象相关【9】
- 迭代器/生成器相关【3】
- ==range(start, stop[, step])==
- ==next(iterable[, default])==
- ==iter(object[, sentinel])==
- 其他【12】
- 字符串类型代码的执行(3)
- ==eval(expression[, globals[, locals]])==
- ==exec(expression)==
- ==compile(source, filename, mode[, flags[, dont_inherit]])==
- 输入输出(2)
- ==input([prompt])==
- ==print(*objects, sep=' ', end='\n', file=sys.stdout, flush=False)==
- 内存相关(2)
- ==hash(object)==
- ==id([object])==
- 文件操作相关(1)
- ==open("filePah", mode="", encoding="utf-8")==
- 模块相关(1)
- ==\__import__(moduleName)==
- 帮助(1)
- ==help([object])==
- 调用相关(1)
- ==callable(object)==
- 查看内置属性(1)
- ==dir([object])==
反射相关【4】
基础数据类型相关【38】
和数字相关(14)
数据类型 <4>
bool([x])
定义: 将给定参数转换为布尔类型,如果没有参数,返回 False。
print(bool()) # False
print(bool(0)) # False
print(bool(1)) # True
int((x, base=10)
定义: 将一个字符串或数字转换为整型。
参数说明:
- x – 字符串或数字。
- base – 进制数,默认十进制。
print(int()) # 0 不传入参数,得到结果0
print(int(3.6)) # 3
print(int('12', 16)) # 18 如果是带参数base的话,12要以字符串的形式进行输入,12为16进制
print(int('0xa', 16)) # 10
float([x])
定义: 将整数和字符串转换成浮点数。
print(float(1)) # 1.0
print(float(-1.5)) # -1.5
print(float('123.35')) # 123.35
complex([real[, imag]])
定义: 创建一个值为 real + imag * j 的复数或者转化一个字符串或数为复数。如果第一个参数为字符串,则不需要指定第二个参数。
print(complex(1)) # (1+0j)
print(complex(1, 2)) # (1+2j)
print(complex("1+2j")) # (1+2j) 注意:这个地方在"+"号两边不能有空格,否则会报错
进制转换 <3>
bin(x)
定义: 返回一个整数 int 或者长整数 long int 的二进制表示。
print(bin(5)) # 0b101
print(0b101) # 5
oct(x)
定义: 将一个整数转换成 8 进制字符串。
print(oct(9)) # 0o11
print(0o11) # 9
hex(x)
定义: 将10进制整数转换成16进制,以字符串形式表示。
print(hex(10)) # 0xa 0-f
print(0xa) # 10
数学运算(7)
abs(x)
定义: 返回数字的绝对值。
print(abs(-5.5)) # 绝对值 5.5
divmod(a, b)
定义: 把除数和余数运算结果结合起来,返回一个包含商和余数的元组(a // b, a % b)。
print(divmod(10, 3)) # (3, 1) 除法 (商,余数)
round(x [, n] )
定义: 返回浮点数x的四舍五入值。
print(round(9.12)) # 9
print(round(-100.965, 2)) # -100.97
pow(x, y[, z])
定义: 返回x的y次方,如果z在存在,则再对结果进行取模,其结果等效于pow(x,y)%z。
print(pow(2, 3)) # 8
print(pow(2, 3, 5)) # 3
print(2**3) # 8# 以下是 math 模块 pow() 方法的语法:
import math
print(math.pow(2,3)) # 8.0
注意: pow()通过内置的方法直接调用,内置方法会把参数作为整型,而math模块则会把参数转换为 float。
sum(iterable[, start])
定义: 对序列进行求和计算。
参数说明:
- iterable – 可迭代对象,如:列表、元组、集合。
- start – 指定相加的参数,如果没有设置这个值,默认为0。
print(sum([0, 1, 2])) # 3
print(sum([0, 1, 2], 5)) # 8 列表计算总和后再加5
min( x, y, z, … )
定义: 返回给定参数的最小值,参数可以为序列。
print(min(1, 0, 2)) # 0
print(min([1, 0, 2])) # 0
print(min('012')) # 0
max( x, y, z, … )
定义: 返回给定参数的最大值,参数可以为序列。
print(max(1, 0, 2)) # 2
print(max([1, 0, 2])) # 2
print(max('012')) # 2
和数据结构相关(24)
序列 <13>
列表和元组 2
list(tup)
定义: 将元组转换为列表。
print(list((1, 'a', 'b'))) # [1, 'a', 'b']
tuple(iterable)
定义: 将可迭代对象转换为元组。
print(tuple([1, 'a', 'b'])) # ( 1, 'a', 'b')
print(tuple('abc')) # ('a', 'b', 'c')
相关内置函数 2
reversed(list)
定义: 用于反向列表中元素。
lst = [123, 'b', 'a']
rlst = reversed(lst)
print(list(rlst)) # ['a', 'b', 123]
slice(start, stop[, step])
定义: 实现切片对象,主要用在切片操作函数里的参数传递。
s = '今天天气不好'
s1 = '明天天气很差'
ss = slice(1, 6, 2)
print(s[ss]) # 天气好
print(s1[ss]) # 天气差
字符串 9
str()
定义: 将对象转化为适于人阅读的形式。
format()
# 字符串
print(format('test', '<20')) # 左对齐 test
print(format('test', '>20')) # 右对齐 test
print(format('test', '^20')) # 居中 test# 数值
print(format(3, 'b')) # 二进制 11
print(format(97, 'c')) # 转换成unicode字符 a
print(format(11, 'd')) # 十进制 11
print(format(11, 'o')) # 八进制 13
print(format(11, 'x')) # 十六进制(小写字母) b
print(format(11, 'X')) # 十六进制(大写字母) B
print(format(48, '08d')) # 00000048
print(format(11, 'n')) # 和d一样 11
print(format(11)) # 和d一样 11# 浮点数
print(format(123456789, 'e')) # 科学计数法,默认保留6位小数 1.234568e+08
print(format(123456789, '0.2e')) # 科学计数法,保留2位小数(小写) 1.23e+08
print(format(123456789, '0.2E')) # 科学计数法,保留2位小数(大写) 1.23E+08
print(format(1.23456789, 'f')) # 小数点计数法,保留6位小数 1.234568
print(format(1.23456789, '0.2f')) # 小数点计数法,保留2位小数 1.23
print(format(1.23456789, '0.10f')) # 小数点计数法,保留10位小数 1.2345678900
print("{} {}".format("hello", "python")) # hello python 不设置指定位置,按默认顺序
print("{1} {0}".format("python", "hello")) # hello python 设置指定位置
# 通过字典设置参数
dict = {"name": "百度", "url": "www.baidu.com"}
print("网站名:{name}, 地址:{url}".format(**dict)) # 网站名:百度, 地址:www.baidu.com
# 通过列表索引设置参数
lst = ['百度', 'www.baidu.com']
print("网站名:{0[0]}, 地址:{0[1]}".format(lst)) # 网站名:百度, 地址:www.baidu.com 0是必须的!!
bytes 【已废弃】
bytearry
定义: 返回一个新字节数组。这个数组里的元素是可变的,并且每个元素的值范围: 0 <= x < 256。
print(bytearray([1,2,3])) # bytearray(b'\x01\x02\x03')
memoryview(obj)
定义: 返回给定参数的内存查看对象
mv = memoryview(bytearray('abcd', 'utf-8'))
print(mv[1])
print(mv[0:2].tobytes()) # b'ab'
ord(c)
定义: 以一个字符(长度为1的字符串)作为参数,返回对应的 ASCII 数值,或者 Unicode 数值,如果所给的 Unicode 字符超出了你的 Python 定义范围,则会引发一个 TypeError 的异常。
print(ord('中')) # 20013
print(ord('a')) # 97
chr(i)
定义: 用一个范围在 range(256)内的(就是0~255)整数作参数,返回一个对应的字符。
print(chr(20013)) # 中 十进制
print(chr(0x61)) # a 十六进制for i in range(32, 126): # 第 33~126 号(共94个)是字符,其中第 48~57 号为 0~9 十个阿拉伯数字,65~90 号为 26 个大写英文字母,97~122 号为 26 个小写英文字母,其余为一些标点符号、运算符号等。print(chr(i), end=' ')
ascii(c)
print(ascii('中')) #'\u4e2d'
repr(object)
定义: 将对象转化为供解释器读取的形式。
print(str("你好,我叫\t'Jessica'")) # 你好,我叫'Jessica'
print(repr("你好,我叫\t'Jessica'")) # "你好,我叫'Jessica'"
数据集合 <3>
字典 1
dict()
定义: 用于创建一个字典。
d1 = dict()
print(d1) # 空字典 {}d2 = dict(a=1, b=2, c=3)
print(d2) # 传入关键字 {'a': 1, 'b': 2, 'c': 3}d3 = dict([('a', 1), ('b', 2), ('c', 3)])
print(d3) # 可迭代对象方式来构造字典 {'a': 1, 'b': 2, 'c': 3}d4 = dict(zip(['a', 'b', 'c'], [1, 2, 3]))
print(d4) # 映射函数方式来构造字典 {'a': 1, 'b': 2, 'c': 3}
集合 2
- list vs tuple
list::有序,可重复,可变序列
tuple:有序,可重复,不可变序列(只读) - set vs frozenset
set:无序,不可重复,可变序列
frozenset:无序,不可重复,不可变序列(只读)
set([iterable])
定义: 创建一个无序不重复元素集,可进行关系测试,删除重复数据,还可以计算交集、差集、并集等。
x = set('hello')
y = set('python')
print(x, y) # {'e', 'o', 'h', 'l'} {'t', 'y', 'p', 'o', 'h', 'n'} 重复的被删除
print(x & y) # {'o', 'h'} 交集
print(x | y) # {'y', 'h', 'e', 'p', 'l', 'n', 't', 'o'} 并集
print(x - y) # {'l', 'e'} 差集
frozenset([iterable])
定义: 返回一个冻结的集合,冻结后集合不能再添加或删除任何元素。
s = frozenset(range(3))
print(s) # frozenset({0, 1, 2})
s2 = frozenset([1, 1, 2, 3])
print(s2) # frozenset({1, 2, 3})
相关内置函数 <8>
len(s)
定义: 返回对象(字符、列表、元组等)长度或项目个数。
print(len('hello')) # 5 字符串长度
print(len([1, 2, 3, 4, 5])) # 5 列表元素个数
sorted(iterable, key=None, reverse=False)
定义: 对所有可迭代的对象进行排序操作。
sort 与 sorted 区别:
sort 是应用在 list 上的方法,sorted 可以对所有可迭代的对象进行排序操作。
list 的 sort 方法返回的是对已经存在的列表进行操作,无返回值,而内建函数 sorted 方法返回的是一个新的 list,而不是在原来的基础上进行的操作。
lst = ['john', 'ken', 'jessica']
# 按名字长度排序
new_lst = sorted(lst, key=lambda item: len(item))
print(new_lst) # ['ken', 'john', 'jessica']lst = [('john', 'm', 15), ('ken', 'm', 20), ('jessica', 'f', 18)]
# 按年龄降序排序
new_lst = sorted(lst, key=lambda l:l[2], reverse=True)
print(new_lst) # [('ken', 'm', 20), ('jessica', 'f', 18), ('john', 'm', 15)]lst = [{'name': 'john', 'age': 15}, {'name': 'ken', 'age': 20}, {'name': 'jessica', 'age': 18}]
# 按年龄排序
new_lst = sorted(dict, key=lambda dict: dict['age'])
print(new_lst) # [{'name': 'john', 'age': 15}, {'name': 'jessica', 'age': 18}, {'name': 'ken', 'age': 20}]
enumerate(sequence, [start=0])
定义: 用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标,一般用在 for 循环当中。
参数说明:
- sequence – 一个序列、迭代器或其他支持迭代对象。
- start – 下标起始位置的值。
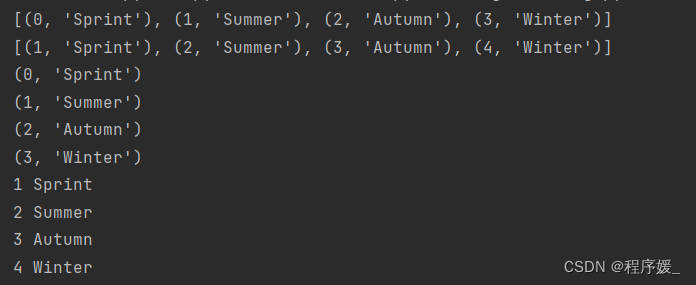
seasons = ['Sprint', 'Summer', 'Autumn', 'Winter']
print(list(enumerate(seasons))) # [(0, 'Sprint'), (1, 'Summer'), (2, 'Autumn'), (3, 'Winter')]
print(list(enumerate(seasons, start=1))) # [(1, 'Sprint'), (2, 'Summer'), (3, 'Autumn'), (4, 'Winter')] 下标从1开始for item in enumerate(seasons):print(item)for i, item in enumerate(seasons, start=1):print(i, item)
结果如下:
all(iterable)
定义: 判断给定的可迭代参数 iterable 中的所有元素是否都为 TRUE,如果是返回 True,否则返回 False。
print(all(['a', 'b', 'c'])) # True
print(all(['a', '', 'c'])) # False 存在一个为空的元素
print(all([0, 1, 2, 3])) # False 存在一个未0的元素
any(iterable)
定义: 于判断给定的可迭代参数 iterable 是否全部为 False,则返回 False,如果有一个为 True,则返回 True。
print(any(['a', 'b', 'c', ''])) # True
print(any(['', 0, False, [], (), {}])) # False 存在一个为空的元素
zip([iterable, …])
定义: 用于将可迭代的对象作为参数,将对象中对应的元素打包成一个个元组,然后返回由这些元组组成的列表。如果各个迭代器的元素个数不一致,则返回列表长度与最短的对象相同,利用 * 号操作符,可以将元组解压为列表。
lst1 = [1, 2, 3]
lst2 = ['a', 'b', 'c', 'd']
z = zip(lst1, lst2)
print(list(z)) # [(1, 'a'), (2, 'b'), (3, 'c')] 元素个数与最短的列表保持一致l1, l2 = zip(*zip(lst1, lst2)) # 与zip相反,zip(*)可理解为解压,返回二维矩阵式
print(list(l1)) # [1, 2, 3]
print(list(l2)) # ['a', 'b', 'c']
filter(function, iterable)
定义: 用于过滤序列,过滤掉不符合条件的元素,返回由符合条件元素组成的新列表。
# 过滤列表中的奇数
odd_filter = filter(lambda x: x % 2 == 1, range(1, 10))
print(list(odd_filter)) # [1, 3, 5, 7, 9]# 筛选年龄大于18的数据
lst = [{'name': 'june', 'age': 27},{'name': 'ken', 'age': 39},{'name': 'bob', 'age': 10}]age_filter = filter(lambda dict: dict['age'] > 18, lst)
print(list(age_filter)) # [{'name': 'june', 'age': 27}, {'name': 'ken', 'age': 39}]
map(function, iterable, …)
定义: 根据提供的函数对指定序列做映射。可以对可迭代对象中的每一个元素进行映射,分别去执行fuction。
# 计算列表中每个元素的平方
mp = map(lambda x: x ** 2, range(1, 10, 2))
print(list(mp)) # [1, 9, 25, 49, 81]
# 等价于:
print([i**2 for i in range(1, 10, 2)]) # [1, 9, 25, 49, 81]# 计算2个列表中相同位置的数据的和
lst1 = [1, 2, 3, 4, 5]
lst2 = [6, 7, 8, 9, 10]
mp = map(lambda x, y: x + y, lst1, lst2)
print(list(mp)) # [7, 9, 11, 13, 15]
作用域相关【2】
locals()
定义: 返回字典类型的局部变量。
globals()
定义: 返回全局变量的字典。
a = 10
def func():a = 20print(locals())func()
print(globals()) # 查看全局作用域所有内容
print(locals()) # 查看当前作用域中的内容
结果如下:

面向对象相关【9】
迭代器/生成器相关【3】
range(start, stop[, step])
for i in range(10):print(i)
next(iterable[, default])
定义: 返回迭代器的下一个项目。
参数说明:
- iterable – 可迭代对象
- default – 可选,用于设置在没有下一个元素时返回该默认值,如果不设置,又没有下一个元素则会触发 StopIteration 异常。
iter(object[, sentinel])
定义: 用来生成迭代器。
参数说明:
- object – 支持迭代的集合对象。
- sentinel – 如果传递了第二个参数,则参数 object 必须是一个可调用的对象(如,函数),此时,iter 创建了一个迭代器对象,每次调用这个迭代器对象的__next__()方法时,都会调用 object。
lst = [1, 2, 3]
it = lst.__iter__()
print(it.__next__()) # 1
it2 = iter(lst) # 等价于:lst.__iter__()
print(next(it2)) # 1 等价于:lst__next__()# def iter(obj):
# return obj.__iter__()
#
# def next(obj):
# return obj.__next__()
其他【12】
字符串类型代码的执行(3)
eval(expression[, globals[, locals]])
定义: 执行字符串类型的代码,并返回最终结果。
参数说明:
- expression – 表达式。
- globals – 变量作用域,全局命名空间,如果被提供,则必须是一个字典对象。
- locals – 变量作用域,局部命名空间,如果被提供,可以是任何映射对象。
r = eval('1+1') # 可以把字符串当成代码去执行,有返回值
print(r) # 2
exec(expression)
定义: 执行字符串类型的代码,返回值永远为 None。
执行储存在字符串或文件中的Python语句,相比于eval,exec可以执行更复杂的Python代码。
# 单行语句字符串
exec('print("Hello Python")') # Hello Python# 多行语句字符串
exec("""
for i in range(5):print(i)
""")'''
# 结果如下:
0
1
2
3
4
'''
compile(source, filename, mode[, flags[, dont_inherit]])
定义: 将一个字符串编译成字节代码。把一段字符串代码加载,后面可以通过exec和eval执行。
参数说明:
- source – 字符串或者AST(Abstract Syntax Trees)对象。。
- filename – 代码文件名称,如果不是从文件读取代码则传递一些可辨认的值。
- mode – 指定编译代码的种类。可以指定为 exec, eval, single。
- flags – 变量作用域,局部命名空间,如果被提供,可以是任何映射对象。
- flags和dont_inherit是用来控制编译源码时的标志。
str = "for i in range(1, 3): print(i)"
c = compile(str, '', 'exec') # 编译成字节代码对象
exec(c) # 1 2str = "3 * 4 + 5"
r = compile(str, '', 'eval')
print(eval(r)) # 17
输入输出(2)
input([prompt])
定义: 接受控制台输入数据,返回为 string 类型。
参数说明: 提示信息
a = input('Please input: ')
print(type(a))
结果如下:

print(*objects, sep=’ ‘, end=’\n’, file=sys.stdout, flush=False)
定义: 打印输出
参数说明:
- objects – 复数,表示可以一次输出多个对象。输出多个对象时,需要用 , 分隔。
- sep – 用来间隔多个对象,默认值是一个空格。
- end – 用来设定以什么结尾。默认值是换行符 \n,我们可以换成其他字符串。
- file – 要写入的文件对象。
- flush – 输出是否被缓存通常决定于 file,但如果 flush 关键字参数为 True,流会被强制刷新。
print("www","baidu","com",sep=".") # 设置间隔符 www.baidu.com
内存相关(2)
hash(object)
** 定义:** 返回对象的哈希值。
print(hash('呵呵'), hash('哈哈')) # -855838824 538020339 (每次运行值都不同)
id([object])
定义: 返回对象的内存地址。
lst1 = [1, 2, 3]
lst2 = [1, 2, 3]
print(id(lst1), id(lst2)) # 20858360 20859520 (每次运行值都不同)
文件操作相关(1)
open(“filePah”, mode=“”, encoding=“utf-8”)
f = open("xxx", mode="", encoding="utf-8")
f.rea()
for line in f:passf.write()with open() as f:pass
模块相关(1)
_import_(moduleName)
定义: 动态加载一个模块。
# 已知导入模块:
import os
# 未知,输入导入模块:
mo = input('>>>') # "os"
__import__(mo) # 动态加载一个模块
帮助(1)
help([object])
定义: 用于查看函数或模块用途的详细说明。
print(help(str)) # 查看 str 数据类型的帮助
调用相关(1)
callable(object)
定义: 判断object是否是可以被调用的。
def func():passprint(callable(func)) # True
print(callable(123)) # False
def run():print('I can run.')def func(fn):if callable(fn): # 判断该内容是否可以被调用fn()else:print('The input func can not callable.')func(run) # I can run.
func(123) # The input func can not callable.
查看内置属性(1)
dir([object])
定义: 不带参数时,返回当前范围内的变量、方法和定义的类型列表;带参数时,返回参数的属性、方法列表。
参数说明: object – 对象、变量、类型。
print(dir())
# ['__builtins__', '__doc__', '__file__', '__loader__', '__name__', '__package__', '__spec__']
print(dir(str))
# ['__add__', '__class__', '__contains__', '__delattr__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__getitem__', '__getnewargs__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__iter__', '__le__', '__len__', '__lt__', '__mod__', '__mul__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__rmod__', '__rmul__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', 'capitalize', 'casefold', 'center', 'count', 'encode', 'endswith', 'expandtabs', 'find', 'format', 'format_map', 'index', 'isalnum', 'isalpha', 'isascii', 'isdecimal', 'isdigit', 'isidentifier', 'islower', 'isnumeric', 'isprintable', 'isspace', 'istitle', 'isupper', 'join', 'ljust', 'lower', 'lstrip', 'maketrans', 'partition', 'replace', 'rfind', 'rindex', 'rjust', 'rpartition', 'rsplit', 'rstrip', 'split', 'splitlines', 'startswith', 'strip', 'swapcase', 'title', 'translate', 'upper', 'zfill']