1 为什么使用Redis
Redis是No-SQL(Not Only SQL)的一种,目前最火的一种非关系型数据库
基于内存存储,支持多种数据类型,键值对存储,Java开发主要面向服务端,就需要抗并发量,性能
Java程序中,使用Redis.
主流NO-SQL对比:对比选择了Redis
小知识:
数据库的分类:
1.Old-SQL
泛指关系型数据库,典型代表:Mysql、Sql Server、Oracle、PostgreSql、H2、Sqllite
2.No-SQL
泛指非关系型,性能,典型代表:Redis(内存 键值对存储)、MongoDB(文档)、Hbase(列)
3.New-SQL
泛指新型数据库,主打海量数据,高并发,典型代表:TiDb、云平台(自主数据)
2 Redis为什么快
1.基于C语言开发,可以直接操作硬件
2.基于内存存储,性能高
3.多路复用:单线程干多线程的事
4.RESP协议-实现数据传输
5.底层存储结构的优化
6.快速实现集群
3 Redis数据类型
Redis的数据类型,针对Redis中键值对(Key-Value)的值而言
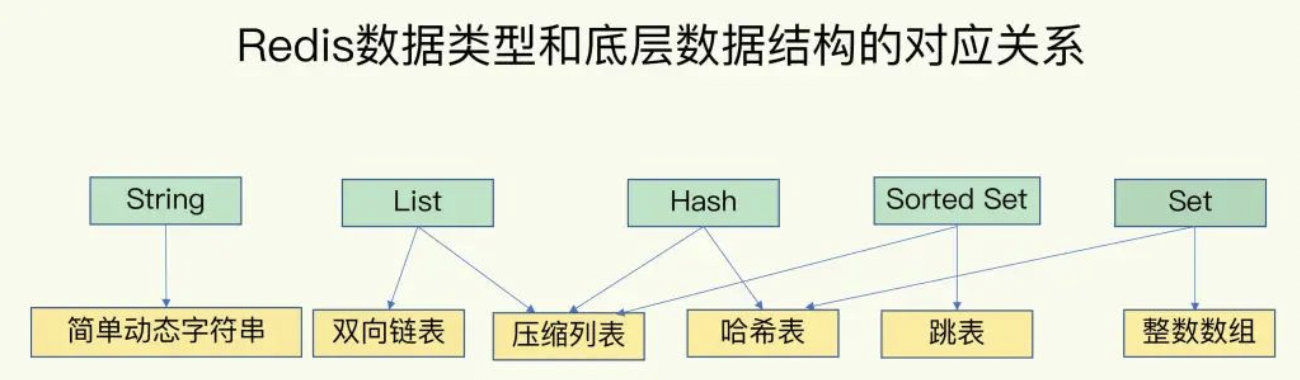
1.String类型
值是字符串类型
2.List类型
值是List集合,特点:存储多个元素,可以重复,保证添加顺序
3.Set类型
值是Set集合,特点:存储多个元素,不重复,不保证添加顺序
4.SortSet(Zset)类型
值是Map<Object,Double>,一种特殊Set集合,特点:存储多个元素,每个元素有:元素的值(任意类型)和分数(Score,只能Double),其中元素的值不能重复,分数是可以重复,而且还能根据分数排序
5.Hash类型
值是Map<Field(Object),Value(Object),>,特点:存储多个元素,每个元素有字段(Field)和值(Value),Field唯一,Value可以重复
6.Bitmap类型
值是一个byte数组,特点:byte数组,值只能是0或1,默认0
小身材大容量,应用场景:2种状态,海量数据,比如1亿用户,今日登录的人数、今日的签到人数、今日的抽奖人数
1Byte=8byte
1GB=1024MB=1024 * 1024KB=1024 * 1024 * 1024 B=1024 * 1024 * 1024 * 8b
7.Geo类型
值是一个地理位置数组,特点:元素是地理位置信息(经度、纬度、地点名称),可以进行计算距离,半径搜索
8.Hyperloglog类型
值是基数,特点:类似函数,计算集合中的基数
4 Redis底层结构之SDS
SDS(simple dynamic string)简单动态字符串,Redis是基于C语言,但是字符串类型,重构了SDS
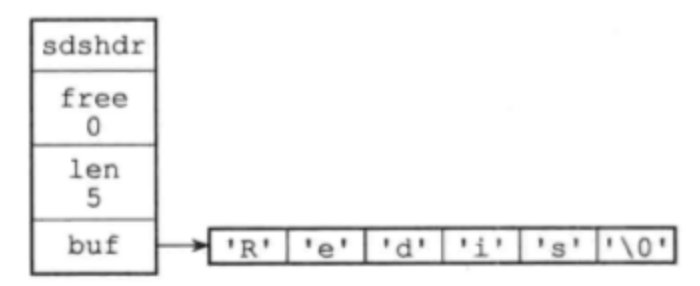
SDS就是String的底层,内部有三个属性
- len : 保存的字符串长度。获取字符串的长度就是O(1)
- free:剩余可用存储字符串的长度
- buf:保存字符串
SDS的优点:
当用户修改字符串时sds api会先检查空间是否满足需求,如果满足,直接执行修改操作,如果不满足,将空间修改至满足需求的大小,然后再执行修改操作 空间预分配 如果修改后的sds的字符串小于1MB时(也就是len的长度小于1MB),那么程序会分配与len属性相同大小的未使用空间(就是再给未使用空间free也分配与len相同的空间) 例:字符串大小为600k,那么会分配600k给这个字符串使用,再分配600k的free空间在那。 惰性空间释放,当缩短sds的存储内容时,并不会立即使用内存重分配来回收字符串缩短后的空间,而是通过free将空闲的空间记录起来,等待将来使用。真正需要释放内存的时候,通过调用api来释放内存 通过空间预分配操作,redis有效的减少了执行字符串增长所需要的内存分配次数 如果修改后sds大于1MB时(也就是len的长度大于等于1MB),那么程序会分配1MB的未使用空间 例:字符串大小为3MB,那么会分配3MB给这个字符串使用,再分配1MB的free空间在那。
5 Redis底层结构之Hash
Hash表数据结构,其实hash表本身就是一个数组,将key通过hash算法计算得出hash值对数组长度取模,用得到的值作为数组下标,然后把value保存在数组下标的位置。由于存储结构是数组,所以hash表的读复杂度是O(1)。
应用场景
1.Redis键值对(Hash类型)的底层实现。
2.当一个哈希键包含的键值对比较多,又或者键值对总的元素都是比较长的字符串时,Redis会使用hash表作为哈希键的底层实现。
3.集合键的底层实现之一
哈希冲突问题
当hash表的负载因子过大时,会频繁出现hash冲突的问题,不同的key经过hash计算和取模得到相同的数组下标。redis使用链表法,将数组下标相同的key使用链表串联起来,以解决哈希冲突的问题。但是当哈希冲突过多,链表长度过长时(需遍历链表,查找key完全匹配的数据),那么它的查询效率也将会降低到O(n),这个时候就要考虑增大数组的长度,执行rehash操作。
渐进式rehash
rehash操作需要创建一个新的长度*2的数组,将所有的key进行hash计算并对新的数组长度取模,然后把数据放在新的数组下标中,这样可以大幅度减少哈希冲突的比例,防止查询效率的退化。但是在生产系统中的数据量是很大的,如果一下子对所有的key进行rehash计算并迁移,那么会导致cpu负载过重,响应正常的对外提供服务。redis采用了渐进式的rehash方式,分批次的将所有key完成rehash,然后将指针引用到新的数组地址。
6 Redis底层结构之ZipList
ZipList:压缩表,列表键(List)和哈希键(Hash类型和SortSet)底层实现,Redis会在列表键包含少量列表项且短字符串,使用压缩表作为底层结构。为了节约内存而开发

7 Redis底层结构之SkipList
SkipList跳表,有序的链表,构建索引,提高查询效率,空间换时间,查找方式从上链表的顶层往下查找
时间复杂度是O(logn)

8 Redis集群策略
3种策略
第一种:主从复制
可以实现一主多从,一台主库(Master),多台从库(Slaver)
优点:避免单点故障,主从的数据一模一样
缺点:1.Redis存储上限没有解决 2.一旦主库崩了,就无法写入
第二种:哨兵机制+主从复制
Redis提供了哨兵机制,监听主库运行,一旦主库连接不上,在从库中自动选举一台从库作为主库
优点:避免单点故障,解决了主库宕机的意外情况
缺点:1.Redis存储上限没有解决
第三种:Redis-Cluster+Redis哨兵+主从复制
利用Redis的插件Redis-cluster实现去中心化的Redis集群搭建,实现多主多从
优点:避免单点故障,解决了主库宕机的意外情况,解决了Redis存储上限
缺点:费钱、复杂度
9 Redis穿透
穿透:海量请求,访问一些Redis不存在的数据,最终请求全部落到数据库中,引起了数据库的宕机或卡顿
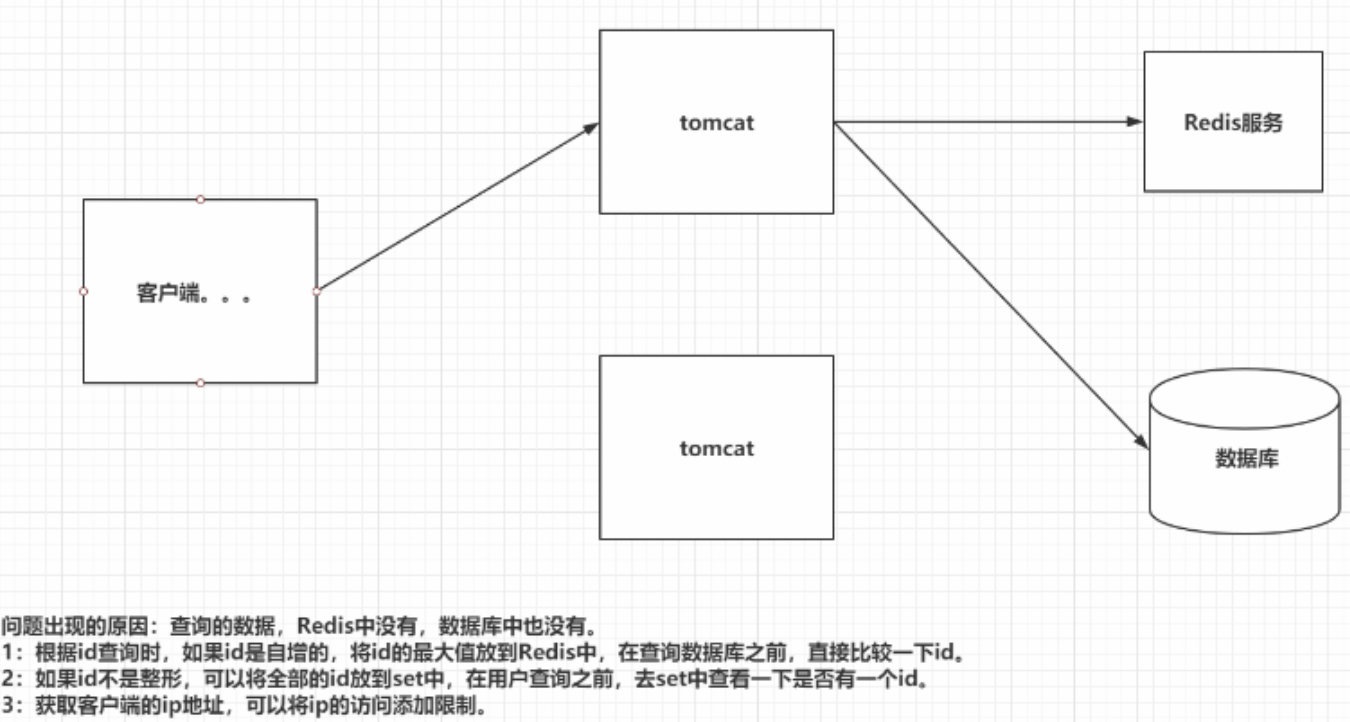
解决方案:
1.布隆过滤器,直接使用RedissonClient(看门狗)的BloomFilter,底层原理:hash算法+Bitmap类型
10 Redis击穿
击穿:海量请求,同时访问一个热点key,结果访问的一瞬间,key失效了,导致请求落到了数据库
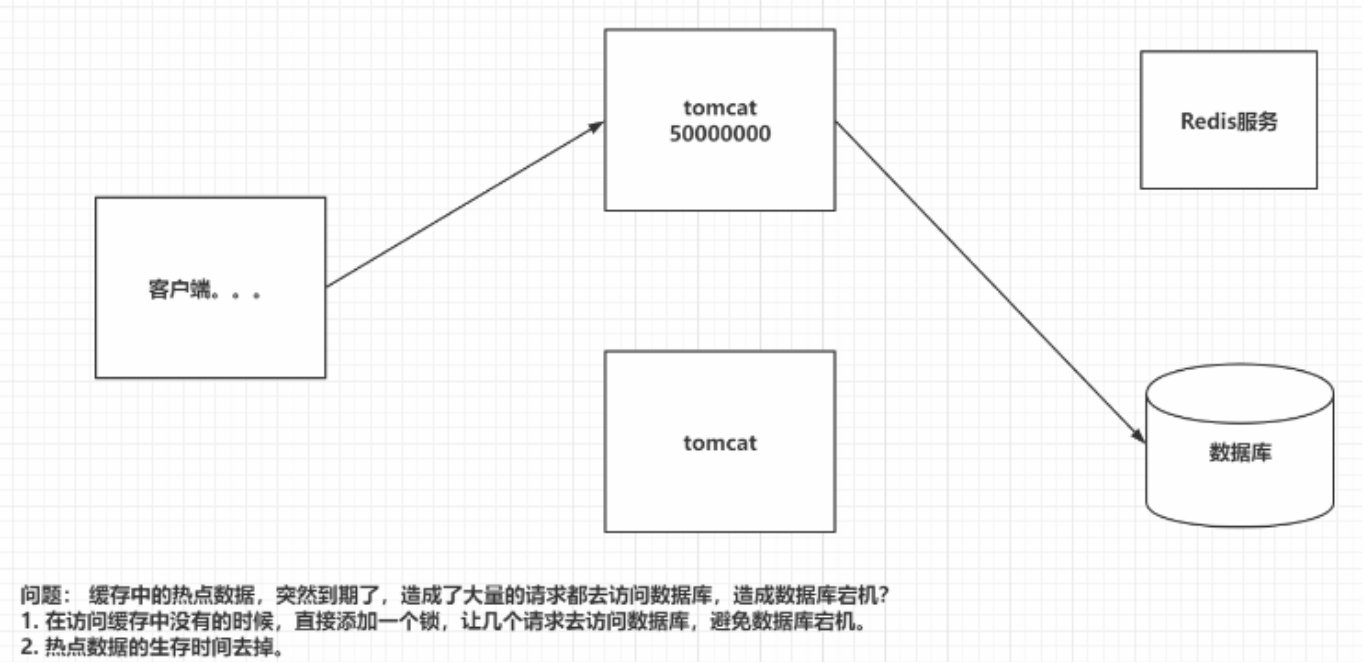
解决方案:
1.热点key不设置有效期
2.key失效了,加个锁再去访问数据库,然后更新数据
3.避免热点key
11 Redis雪崩
雪崩:海量请求,同时访问很多个key,结果访问的一瞬间,这些key失效了,导致请求落到了数据库

解决方案:
1.这些key不要在同一时间失效,追加随机时间戳
12 Redis倾斜
倾斜:集群中,海量请求,访问key结果都分配到了某一个服务器上,导致这台服务器压力过大
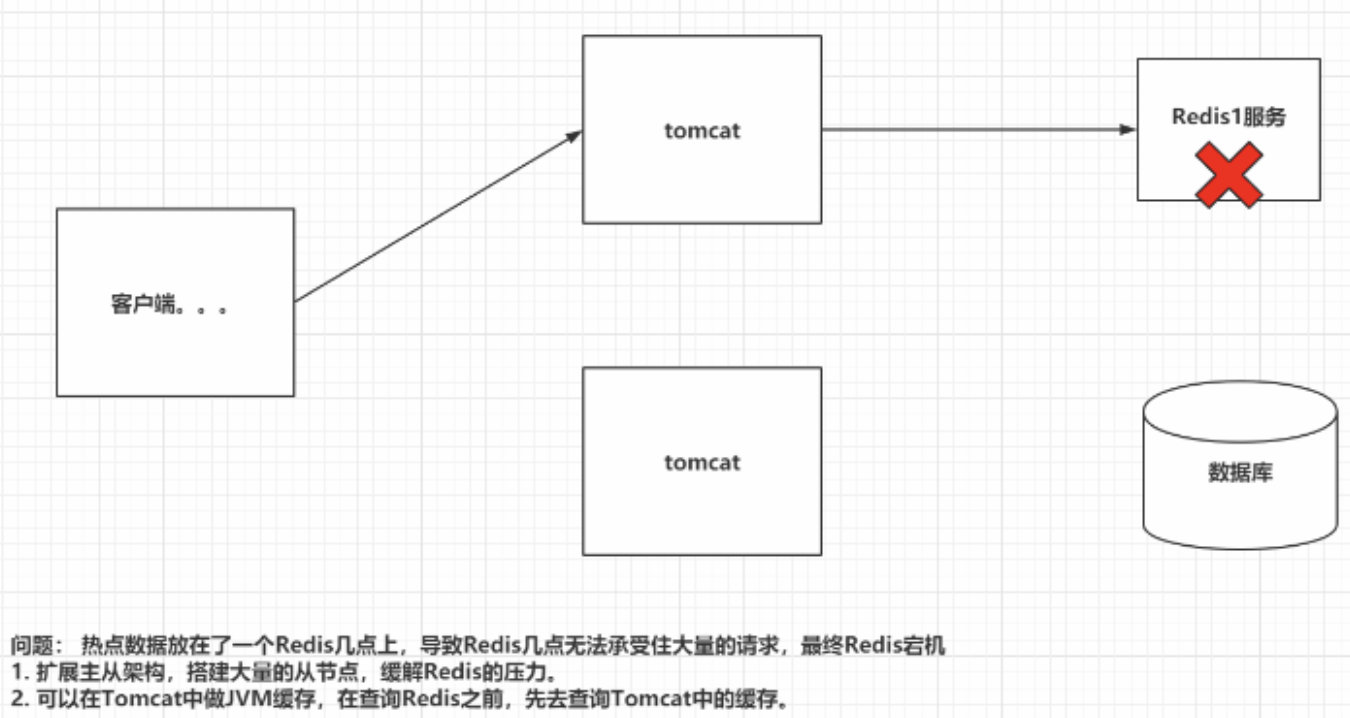
解决方案:
1.从设计的角度解决热点key的问题
13 Redis过期策略
Redis中,可以为key设置有效期,key过去的时候,就需要触发过期策略
1.定期删除:Redis每隔指定时间,随机检查指定数量key,如果key失效就删除。
2.惰性删除:Redis在查询的时候,会对进行校验,校验是否过期,如果过期删除。
Redis就是采用这2种方式解决过期的key删除
14 Redis淘汰机制
Redis中有淘汰机制,解决存储空间不足的问题
在redis.conf文件中,设置触发的条件,内存使用率达到多少就触发哪种淘汰机制
在Redis内存已经满的时候,添加了一个新的数据,执行淘汰机制。
volatile-lru:在内存不足时,Redis会在设置过了生存时间的key中干掉一个最近最少使用的key。
allkeys-lru:在内存不足时,Redis会在全部的key中干掉一个最近最少使用的key。
volatile-lfu:在内存不足时,Redis会在设置过了生存时间的key中干掉一个最近最少频次使用的key。
allkeys-lfu:在内存不足时,Redis会再全部的key中干掉一个最近最少频次使用的key。
volatile-random:在内存不足时,Redis会再设置过了生存时间的key中随机干掉一个。
allkeys-random:在内存不足时,Redis会再全部的key中随机干掉一个。
volatile-ttl:在内存不足时,Redis会在设置过了生存时间的key中干掉一个剩余生存时间最少的key。
noeviction:(默认)在内存不足时,直接报错。
指定淘汰机制的方式:maxmemory-policy 具体策略,设置Redis的最大内存:maxmemory 字节大小
15 基于Redis的分布式锁
锁:保证任一时间,只能有一个线程访问,解决线程安全
分布式锁:集群下,解决线程安全,就需要使用分布式锁
分布式锁的实现方案:
1.基于Redis实现分布式锁:性能高,稳定性一般
2.基于zookeeper(分布式目录存储)实现分布式锁:性能一般,稳定性高
Redis实现分布式锁:RedLock(红锁) 直接设置key(锁的名称)再设置一个超时时间
**1.互斥:**任何时刻只能有一个client获取锁
**2.释放死锁:**即使锁定资源的服务崩溃或者分区,仍然能释放锁
**3.容错性:**只要多数redis节点(一半以上)在使用,client就可以获取和释放锁
RedLock的底层实现原理:
多节点redis实现的分布式锁算法(RedLock):有效防止单点故障
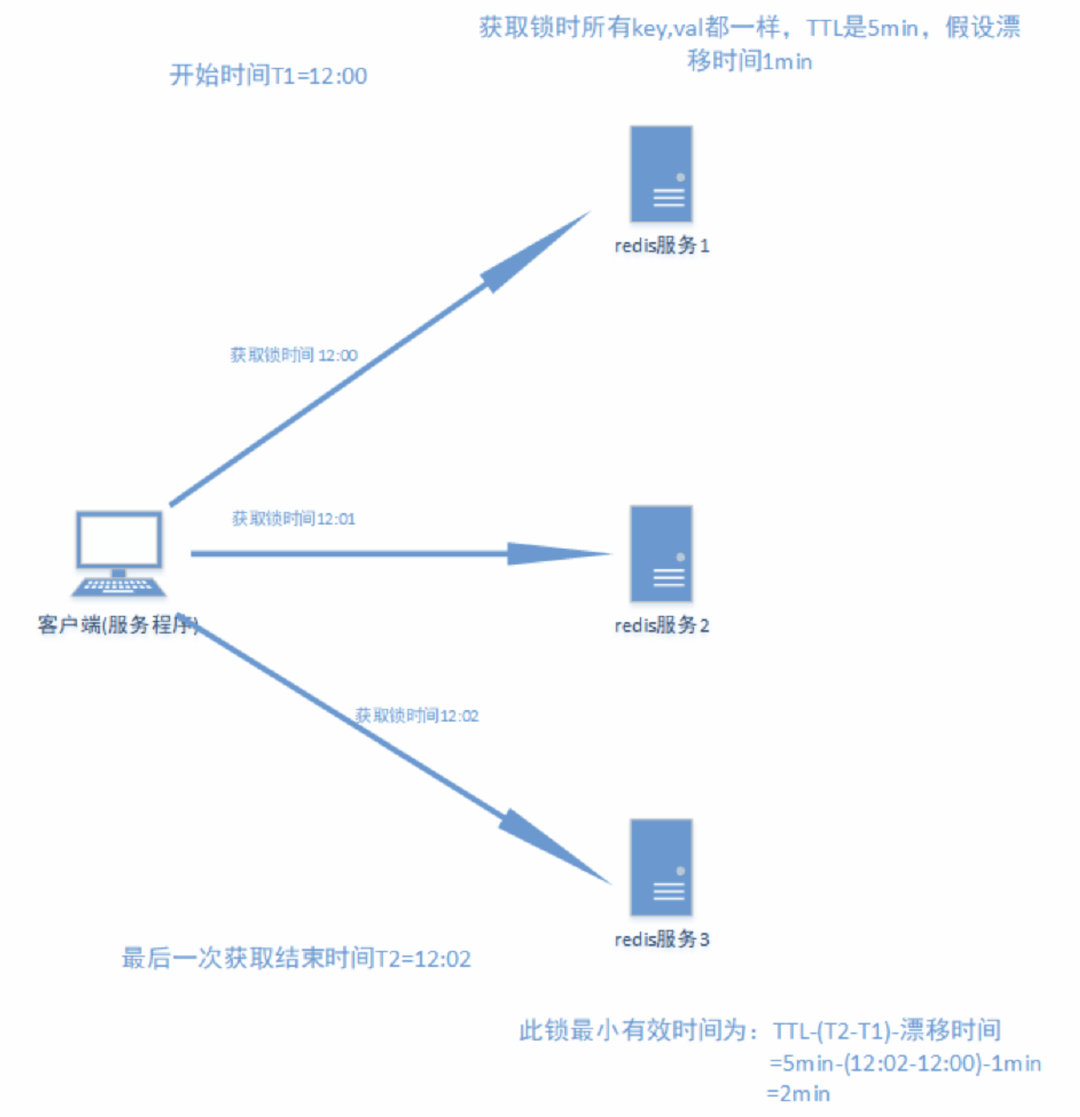
假设有5个完全独立的redis主服务器
1.获取当前时间戳
2.client尝试按照顺序使用相同的key,value获取所有redis服务的锁,在获取锁的过程中的获取时间比锁过期时间短很多,这是为了不要过长时间等待已经关闭的redis服务。并且试着获取下一个redis实例。
比如:TTL为5s,设置获取锁最多用1s,所以如果一秒内无法获取锁,就放弃获取这个锁,从而尝试获取下个锁
3.client通过获取所有能获取的锁后的时间减去第一步的时间,这个时间差要小于TTL时间并且至少有3个redis实例成功获取锁,才算真正的获取锁成功
4.如果成功获取锁,则锁的真正有效时间是 TTL减去第三步的时间差 的时间;比如:TTL 是5s,获取所有锁用了2s,则真正锁有效时间为3s(其实应该再减去时钟漂移);
5.如果客户端由于某些原因获取锁失败,便会开始解锁所有redis实例;因为可能已经获取了小于3个锁,必须释放,否则影响其他client获取锁
16 Redis应用
项目中使用Redis的时候:1.为什么用Redis 2.Redis的哪种数据类型 3.Redis存储什么数据 4.Redis是否设置有效期 5.怎么保证数据同步
1.缓存
很多次的访问都是访问相同的数据,可以考虑做缓存
比如首页、商品详情页、动态列表页、排行榜、多版本号兼容等
难点:保证数据一致性
2.有效期数据
短时间的有效期的数据,可以考虑使用Redis
比如:验证码、令牌、订单超时等
3.分布式锁
实现分布式锁,共享锁的状态
4.共享数据
利用Redis实现微服务(或集群)中的多个服务间的数据共享
比如:分布式Session
5.性能
利用Redis的高性能,可以早海量并发量下,以Redis为主库
比如:秒杀的下单、订单削峰填谷等
17 数据同步一致性
数据同步一致性的问题:比如Redis->Mysql Mysq->Es
1.直接操作
更改数据源的时候直接更改对应缓存数据
2.延迟同步(延时双删)
更改数据源(主库),基于Mq的延迟实现延迟同步操作
3.定时同步
任务调度框架实现定时数据同步
4.第三方软件,实现数据迁移(定时)
淘宝Cancel


![[附源码]计算机毕业设计仓库管理系统Springboot程序](https://img-blog.csdnimg.cn/16d0a5281bbc4b4b9e1cba4c41572adb.png)
![[LeetCode 1769]移动所有球到每个盒子所需的最小操作数](https://img-blog.csdnimg.cn/772e58710f5245d0938e5c02d160edb1.png)