知识目录
- 一、写在前面✨
- 二、Requests库
- 三、接口调用
- 四、总结撒花😊
一、写在前面✨
大家好!我是初心,希望我们一路走来能坚守初心!
今天跟大家分享的文章是 Python中Requests库在爬虫和自动化中的使用 ,希望能帮助到大家!本篇文章收录于 初心 的 Python从入门到精通 专栏。
🏠 个人主页:初心%个人主页
🧑 个人简介:大家好,我是初心,和大家共同努力
💕欢迎大家:这里是CSDN,我记录知识的地方,喜欢的话请三连,有问题请私信😘
💕 我希望兜兜转转之后那个人还是你。 —— 不要半夜躲在被子里哭了「网易云音乐」
二、Requests库
Requests库——让HTTP服务人类。
Python requests 是一个常用的 HTTP 请求库,可以方便地向网站发送 HTTP 请求,并获取响应结果。
requests 模块比 urllib 模块更简洁。
使用 requests 发送 HTTP 请求需要先导入 requests 模块:
import requests
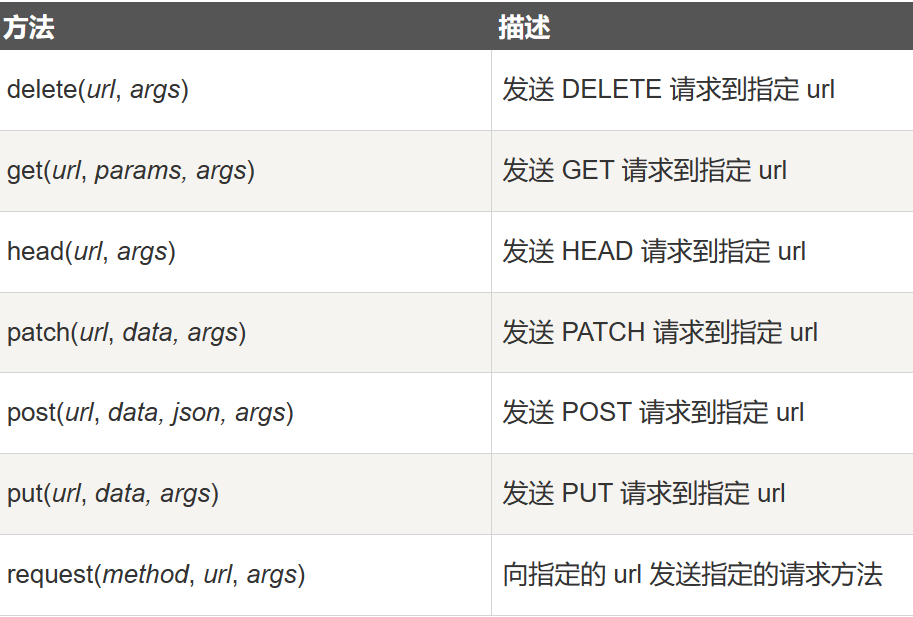
Requests方法:
三、接口调用
编写程序,调用一言网站接口,动漫也好、小说也好、网络也好,不论在哪里,我们总会看到有那么一两个句子能穿透你的心。显示一句诗词或文学、出处、作者(注意要进行简单处理获取有效句子部分)。
import requests
import jsondef get_hitokoto(params):""">>> values = get_hitokoto({'c': 'd', 'c':'i'})>>> None != valuesTrue>>> 'hitokoto' in valuesTrue>>> None != values['hitokoto']True>>> 'from' in valuesTrue>>> None != values['from']True>>> 'from_who' in valuesTrue>>> None != values['from_who']True"""# Edit Your Code Hereimport doctest
doctest.testmod()
# 基础url
baseurl = 'https://v1.hitokoto.cn/?'
# 发送请求并将结果转dict
res = requests.get(baseurl,params=params)
return json.loads(res.text)
四、总结撒花😊
本文主要讲解了如何使用Requests库调用一言网接口,进行简单处理提取句子的有效成分。😊
✨ 这就是今天要分享给大家的全部内容了,我们下期再见!😊
🏠 本文由初心原创,首发于CSDN博客, 博客主页:初心%🏠
🏠 我在CSDN等你哦!😍