一、数据库概述
1.为什么软件测试工程师还需要学习数据库以及开发方面的知识?
- 测试工程师的目的是找出软件的不足,并告诉开发工程师,出现问题的环境,操作步骤和输入输出数据;优秀的测试工程师,需要告诉开发团队,软件的不足,这类不足会导致什么情况,如何避免,以及如何去修改(这是为什么高级软件测试工程师比开发工程师工资高的原因)。
- 测试工程师在测试软件过程中,不仅仅需要在界面进行操作,还需要检查数据库中的数据是否正确,从而在软件出现问题时候,能够定位到问题原因;
- 学习数据库,掌握数据库操作,增加面试成功机会,可以提高工资。
2. 什么是数据库
- Excle的数据的确很方便,但是对于企业来说就不一样了。一个公司里面可能有成千上万的Excel表格,还在不同的电脑上,而他们的员工和客户需要实时看到企业给他们提供的所有数据,这种文件管理的方法就很麻烦,总不能每分钟都把一个新的巨大无比的Excel文件发给所有客户呀。
- 数据库是按照数据的结构来组织、存储、和管理数据的仓库,简而言之,就是存放数据的仓库。正是因为有了数据库后,所有人可以直接在这个系统上查找数据和修改数据。例如你每天使用余额宝查看自己的账户收益,就是从后台数据库读取数据后给你的。
- 数据库的英文名称叫DB(Database),那么数据库里面有什么东东呢?
其实,数据库通常包含一个或多个表组成。如果你用过Excel,就会知道Excel是一张一张的二维表。每个表都是由列和行组成的,其中每一列都用名字来标识出来。同样的,数据库里存放的也是一张一张的表,只不过各个表之间是有联系的。所以,简单来说:数据库=多张表+各表之间的关系
其实数据库是逻辑上的概念,它是一堆互相关联的数据,放在物理实体上,是一堆写在磁盘上的文件,文件中有数据。这些最基础的数据组成了表(table)。
3. 常见数据库
-
Oracle是最挣钱的数据库,出自甲骨文公司,市场占有率非常高,功能非常强大,被一些大型企业,电信,银行,证券公司、金融公司所使用,市场占有率第一。
-
MySQL是一个关系型数据库管理系统,由瑞典MySQL AB 公司开发,目前属于 Oracle 旗下产品。MySQL 是最流行的关系型数据库管理系统之一,在 WEB 应用方面,MySQL是最好的 RDBMS (Relational Database Management System,关系数据库管理系统) 应用软件。MySQL目前最流行的开源数据库,被甲骨文公司所占用,威胁着老大Oracle的地位,开源,免费,支持多平台,简单易学易操作,市场占有率第二。
-
SQLServer是微软开发的数据库,针对服务器,仅支持Windows操作系统,号称是windows上最好用的数据库。数据库的天下不仅仅是MySQL和Oracle的,SQLServer也正在慢慢崛起,微软网罗了不少数据库的专家,推出了不少重磅功能。
-
MongoDB,最好用的文档型数据库,是NOSQL类型数据库的领导者之一,也是当前最成功的NoSQL类型数据库,数据存储格式采用JSON形式,非常灵活。
-
Redis,最好的内存级数据库,查询效率极高,并且在Redis 3.0之后,支持多种数据类型,String,Set,List,Hash等类型,开始支持集群,弥补了自身短板。是目前做缓存最流行的数据库
-
Neo4J,最好的图形化数据库,流行话较低,但是图形化数据库的绝对领导者。
-
SQLite,最流行的嵌入式数据库,占领手机行业的绝对领导者地位,Android和IOS两大手机系统,都内嵌了SQLite数据库,SQLite是一个完整的关系型数据库,支持标准SQL,支持事务操作,程序包非常小,是嵌入式设备的最佳选择。
各个数据库软件的使用差别大同小异,但是因为MySQL是开源的,成为各大公司使用的主流,面试也主要以MySQL为主。
4.数据库和SQL是什么关系?
结构化查询语言(Structured Query Language)简称SQL,是一种特殊目的的编程语言,是一种数据库查询和程序设计语言,用于存取数据以及查询、更新和管理关系数据库系统;同时也是数据库脚本文件的扩展名。
数据库里面放着数据,而SQL是用来操作数据库里数据的语言(工具)。
例如有一碗米饭(碗就是mysql,里面放的米是数据),你要吃碗里的米饭,拿什么吃?拿筷子(sql)。用筷子(sql)操作碗里(mysql)的米饭(数据)
二、MySQL数据库的安装配置
https://blog.csdn.net/weixin_60579861/article/details/123283666?spm=1001.2014.3001.5501
三、SQL语句分类
3.1. DDL-数据库定义语言
3.1.1. 概念及作用
database defination language 数据库定义语言,用于定义数据库,用于定义表结构
3.1.2. 表中字段基本数据类型
MySQL支持多种类型,大致可以分为三类:数值、日期/时间和字符串(字符)类型
- 一个汉字占多少长度与编码有关:
UTF-8:一个汉字=3个字节
GBK:一个汉字=2个字节 - varchar(n) 表示 n 个字符,无论汉字和英文,Mysql 都能存入 n 个字符,仅是实际字节长度有所区别
3.1.3. 数据库语句操作
- 在登陆 MySQL 服务后,使用 create 命令创建数据库,语法如下:
CREATE DATABASE 数据库名;//创建第一个数据库 mydb1 create database mydb1 - 在删除数据库过程中,务必要十分谨慎,因为在执行删除命令后,所有数据将会消失。语法:
//删除创建的数据库 drop database mydb1; - 在你连接到 MySQL 数据库后,可能有多个可以操作的数据库,所以你需要选择你要操作的数据库
//选择数据库 user mydb1
注意:所有的数据库名,表名,表字段都是区分大小写的。所以你在使用SQL命令时需要输入正确的名称。
- 查看数据库创建细节
show create database mydb1 - 创建一个使用gbk字符集的数据库
create database mydb2 character set gbk
3.1.4. 表结构语句操作
- 选择数据库
use mydb1 - 创建MySQL数据表需要以下信息:
表名、表字段名、定义每个表字段//创建表 create table student(id int,name varchar(20),sex varchar(20),age int,salery float(6,2),birthday date)//删除表 drop table student;//查看所有表 show tables//查看表的创建细节 show create table student;//展示表结构 desc student// 在原有的学生基础上添加address列 alter table student add address varchar(20) //在原有的学生基础上删除address列 alter table student drop address
3.1.5. 定义表的约束
create table student(id int primary key auto_increment,name varchar(20) unique not null,sex varchar(20),age int,salery float(6,2),birthday date)
- 如果你不想字段为 NULL 可以设置字段的属性为 NOT NULL, 在操作数据库时如果输入该字段的数据为NULL ,就会报错。
- AUTO_INCREMENT定义列为自增的属性,一般用于主键,数值会自动加1。
- PRIMARY KEY关键字用于定义列为主键。为了标识数据库记录唯一性,不允许记录重复,且键值不能为空,主键也是一个特殊索引。 您可以使用多列来定义主键,列间以逗号分隔。
- UNIQUE KEY的用途:主要是用来防止数据插入的时候重复的
- ENGINE:设置存储引擎
- CHARSET: 设置编码
3.2 DML - 数据库操作语言
3.2.1. 概念及作用
DML:data manipulation language 数据库操作语言,用以操作数据库。
3.2.2. 插入数据
//插入数据
insert into student values(1,’zhangsan’,’nan’,19,389.10,’1999-10-10’);
//查询
select * from student
- 问题一:插入中文会报错
insert into student values(2,’李四’,’男’,19,389.10,’1999-10-10’);
- 解决:
//通知服务器客户端使用的编码是gbk
set character_set_client=gbk;//通知服务器客户端查看结果集使用的编码是 gbk
set character_set_results=gbk;insert into student(id,name,sex,age) values(3,’王五’,’男’,19);
- 问题二:数据库命令框如果有中文就乱码
charset gbk;
3.2.3. 删除数据
//删除单条数据
delete from student where id=1;//删除所有数据,不删除结构,会放到日志中,事务提交后才生效
delete from student;//摧毁表,删除表中所有数据,不删除结构,立即生效
truncate table student;
注意:delete from student;与truncate table student;都能删除该表中所有数据,区别:前者删除后自增主键还在,后者主键会从1开始。
3.2.4. 修改数据
//设置所有人的年龄加10岁
update student set age=age+10//修改zhangsan 为张三
update student set name=’张三’ where name=’zhangsan’//修改王五的salery和出生日期
update student set salery=100.01,birthday=’1999-10-10’ where id=3;
3.3 DQL-数据库查询语言
3.3.1.概念及作用
Data Query Language 数据库查询语言
3.3.2.数据查询
//删除student
drop table student
//创建数据库表-学生成绩表
create table student(id int primary key auto_increment,name varchar(20) unique not null,chinese float,english float,math float);//添加几条数据
insert into student values(1,’张三’,90,80,80);
insert into student values(2,’李四’,90,87,60);
insert into student values(3,’王五’,70,60,69);
insert into student values(4,’赵六’,99,90,87);//查询所有学生信息
select * from student;//查询id为1的学生信息
select * from student where id=1;//查询id为1的学生姓名
select name from student where id=1;//查询数学成绩大于80的同学成绩
select * from student where math>80//查询所有学生成绩,并输出效果为 姓名 语文 英语 数学 效果,见下图:
select name as 姓名,chinese as 语文,english as 英语,math as 数学 from student//查询所有成绩及数学分+10分
select *,(math+10)from student//统计每个学生的总分
select name,(math+english+chinese) as 总分 from student//查询总分大于230分的同学
select * from student where (math+english+chinese)>230//查询数学成绩在80-90之间的同学
select * from student where math between 80 and 90//查询数学语文英语都大于80的同学成绩
select * from student where math>80 and english>80 and chinese >80;//查询数学成绩在 80 60 90内的同学,即数学成绩有60、80、90的。
select * from student where math in(80,60,90);//模糊查询
// _ 代表一个,%代表多个(0 - 无限)
//查询所有姓名中包含张的同学
select * from student where name like ‘%张%’
查询所有学生成绩,并输出效果.png

3.3.3. 排序查询
MySQL中 升序为asc,降序为desc
例如:
升序:select * from 表名 order by 表中的字段 asc(MySQL中默认是升序排列,可不写) ;
降序:select * from 表名 order by 表中的字段 desc ;
若要进行同时一个升序一个降序 例如:
order by 升序字段 asc,降序字段 desc ;
//按照数学成绩从小到大查询
select * from student order by math;
//按照数学成绩从大到小查询
select * from student order by math desc;
3.3.4.分页查询
limit是mysql的分页查询语法:select * from table limit m,n
其中m是指记录从m+1开始,,N代表取n条记录。
//取出第3条至第6条,4条记录
select * from student limit 2,4//查询出数学成绩由高到低前两名
select * from student order by math desc limit 0,2;
3.3.5.分组查询
分组查询得到结果是第一次查到的某个组别。
//创建一个订单表
create table employee(id int,name varchar(20),sex varchar(20),age int);
insert into employee values(1,'sunsan','男',18);
insert into employee values(2,'lisi','男',18);
insert into employee values(3,'wangwu','女',19);
insert into employee values(4,'zhaoliu','男',15);//分组查询select * from employee group by sex;//分组查询加条件select * from employee group by sex having age>18;
- 注意:
1)分组之后查询的字段最好不要是name等,最好的分组字段和聚合函数
2)where和having的区别
①where在分组之前限定,如果不满足条件则不参与分组。having在分组之后限定,如果不满足条件,则不会被查出来。
②where后不可以跟聚合函数,having可以进行聚合函数判断。
③having只能和group by一起使用select sex ,avg(math),count from student where math > 70 group by sex having age > 18
3.3.6. 报表查询
count 个数
sum 总数
avg 平均数
max 最大值
min 最小值
//统计班级里边有多少学生
select count(*)from student;//统计总成绩大于250分的人数
select count(*)from student where (math+english+chinese)>250;//统计班级里边各科总成绩
select sum(math),sum(english),sum(chinese) from student//统计所有科目的总成绩
select sum(math+english+chinese) from student;//统计一下语文平均成绩
select sum(chinese)/count(*) from student;
select avg(chinese) from student;//统计一下班级语文最高分和最低分
select max(chinese) from student;
select min(chinese) from student;//报表查询订单根据名称合并后,总价格>10000的商品
select * from orders group by product having sum(price) >7000
3.4 数据控制语言
数据控制语言:简称【DCL】(Data Control Language),用来定义数据库的访问权限和安全级别,及创建用户;关键字:grant等
四、多表设计
4.1.一对一
一张表的一条记录一定只能与另外一张表的一条记录进行对应,反之亦然。
有时候,为了业务,或者避免一张表中数据量过大,过复杂,在开发中会进行一对一方式来设计表。

4.2. 一对多(1方建主表(id为主键字段), 多方建外键字段)
一个实体的某个数据与另外一个实体的多个数据有关联关系, 一对多的关系在设计的时候,需要设计表的外键。
4.2.1. 班级表和学生表设计
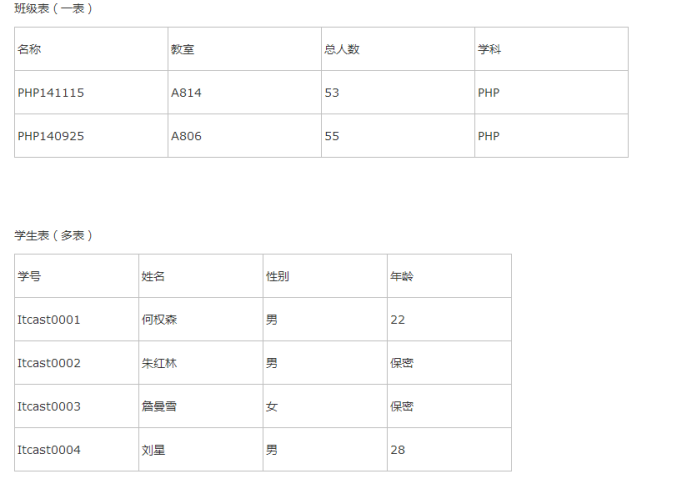

部门表和员工表设计

4.2.2.创建数据库表
- constraint 约束
- foreign key就是表与表之间的某种约定的关系,由于这种关系的存在,能够让表与表之间的数据,更加的完整,关连性更强。
- foreign key语句的式例:FOREIGN KEY(Sno) REFERENCES Student(Sno)
注意:表的外键必须是另一张表的主键
//创建班级表
create table class(id int primary key auto_increment,name varchar(20));
//创建学生表
create table student(id int primary key auto_increment,name varchar(20),sex varchar(20),class_id int,constraint foreign key(class_id) references class(id));//插入班级数据
insert into class values(1,'ceshiban');
insert into class values(2,'kaifa');
//插入学生数据
insert into student values(1,'zhangsan','nan',1);
insert into student values(2,'lisi','nan',2);
insert into student values(3,'jingjing','nan',2);//联查
select * from student where class_id=(select id from class where id=2);
补一个外键的注意(默认是约束): 删除主键信息时,当该主键字段值在外键表中存在时,该记录是不能删除的。---要把外键表是的相关信息删除之后,才能删除。
子查询:嵌套在其他查询中的查询。
4.3、多对多( 3个表= 2个实体表 + 1个关系表 )
一个实体的数据对应另外一个实体的多个数据,另外实体的数据也同样对应当前实体的多个数据。
一个学生可以有多个老师,一个老师可以教多个学生
解决方案:创建一个中间表,专门用来维护多表之间的对应关系,通常是能够唯一标识出数据的字段(主键)
create table teacher(id int primary key,name varchar(100));
create table student (id int primary key,name varchar(100));create table teacher_student(teacher_id int,student_id int,constraint foreign key(teacher_id) references teacher(id),constraint foreign key(student_id) references student(id));insert into teacher values(1,'梁老师');
insert into teacher values(2,'李老师');insert into student values(1,”张三”);
insert into student values(2,”李四”);insert into teacher_student values(1,1);
insert into teacher_student values(1,2);
insert into teacher_student values(2,1);
insert into teacher_student values(2,2);//查询李老师所教的学生
select id from teacher where name=’李老师’
select student_id from teacher_student where teacher_id=idselect * from student where id in(select student_id from teacher_student where teacher_id =(select id from teacher where name='李老师'));//查询张三的所有老师
select * from teacher where id in(select teacher_id from teacher_student where student_id=(select id from student where name='张三'));
五、 连表查询
分类:内连接、外连接、交叉连接
5.1. 初始定义表结构
create table customer(id int primary key auto_increment,name varchar(20),city varchar(20));create table orders(id int primary key auto_increment,good_name varchar(20),price float(8,2),customer_id int);
insert into customer (name,city) values('李老师','东北');
insert into customer (name,city) values('崔老师','山西');
insert into customer (name,city) values('张老师','内蒙');
insert into customer (name,city) values('闫老师','天津');insert into orders(good_name,price,customer_id) values('电脑',59,1);
insert into orders(good_name,price,customer_id) values('笔记本',88,2);
insert into orders(good_name,price,customer_id) values('吹风机',99,1);
insert into orders(good_name,price,customer_id) values('香水',300,3);
insert into orders(good_name,price,customer_id) values('牛奶',100,6);
5.2.交叉查询
交叉查询,又叫笛卡尔积查询,会将左表和右表的信息,做一个乘积将所有信息查询出来,会产生临时表,比较占用内存,生成的记录数=表1 X表2
select * from customer,orders;
select * from customer cross join orders;
5.3. 内连接查询
内连接,inner join on 查询两张表,设定条件,将两张表中对应的数据查询出来
不会产生笛卡尔积,不会产生临时表,性能高
select * from customer c inner join orders o on c.id=o.customer_id;
select * from customer,orders where customer.id=orders.customer_id;
select * from customer c,orders o where c.id=o.customer_id;
5.4. 左外连接
左外连接 left join on 设定条件,将两张表对应的数据查询出来,同时将左表自己没有关联的数据也查询出来
注意:join前面是左,后面是右
select * from customer c left join orders o on c.id=o.customer_id;
5.5. 右外连接
右外连接 right join on 设定条件,将两张表对应的数据查询出来,同时将右表自己没有关联的所有数据查询出来
select * from customer c right join orders o on c.id=o.customer_id;
5.6. 联合查询
select * from customer left join orders on customer.id=orders.customer_id
having price>20;
六、MySQL图形化工具navicat
6.1. 安装介绍
MySQL常见的图形化工具
6.2. Navicat工具使用步骤
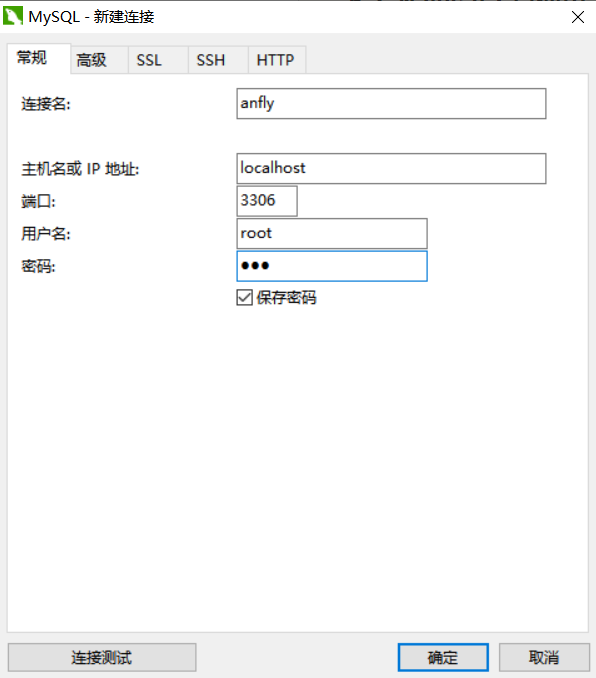
6.2.1. 链接,mysql,输入用户名,密码
6.2.2.新建库,鼠标点击右键


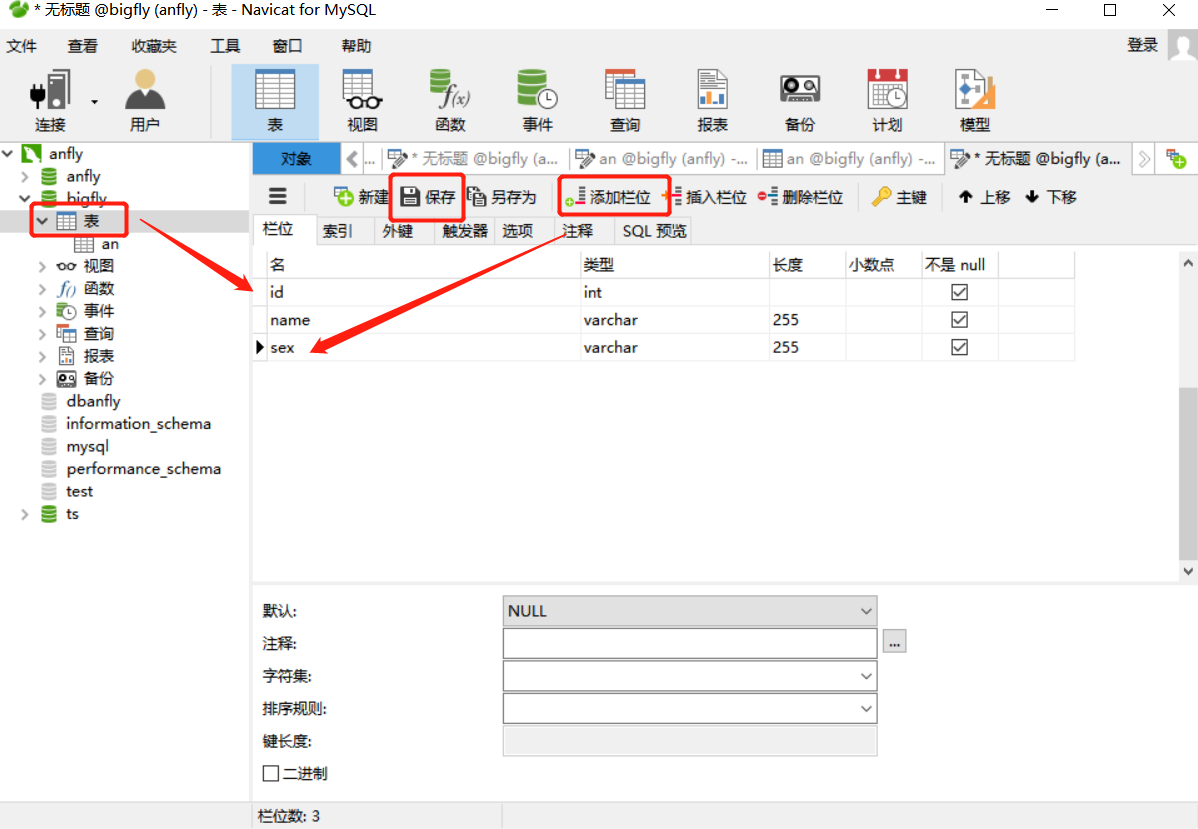
6.2.3.新建表
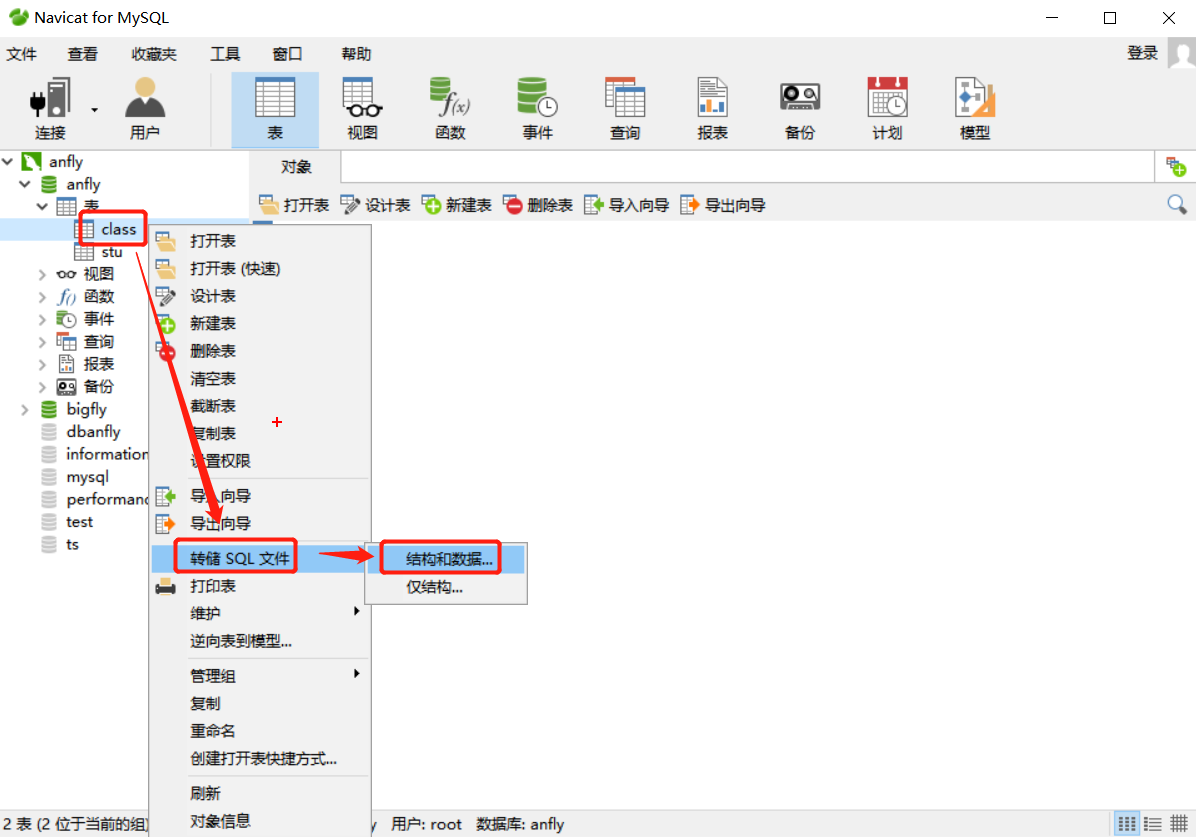
七、数据库备份与恢复
1. 使用图形界面工具:
2. 使用doc命令:
mysqldump –u用户名 –p密码 数据库名>生成的脚本文件路径
注意,不要打分号,不要登录mysql,直接在cmd下运行
注意,生成的脚本文件中不包含create database语句
mysqldump -uroot -proot host>C:\Users\Administrator\Deskt
op\mysql\1.sql

3. 导入SQL文件
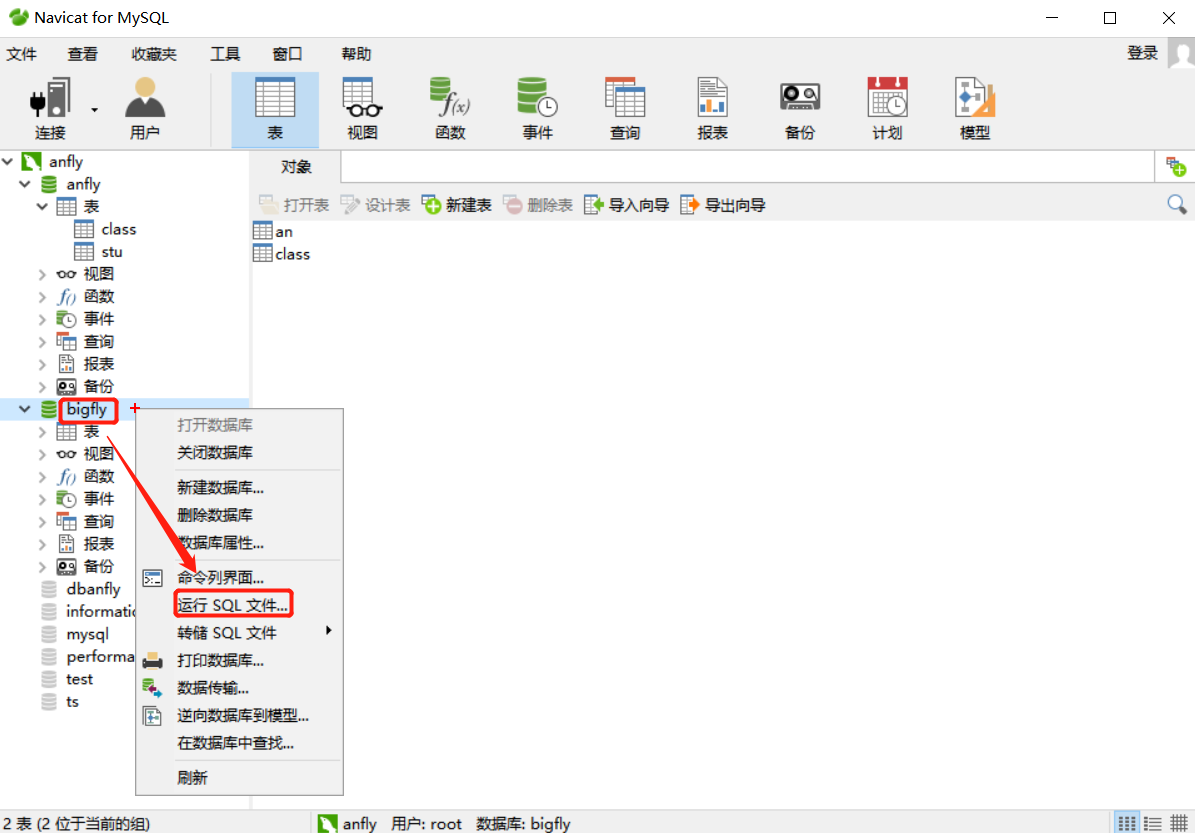
导入文件
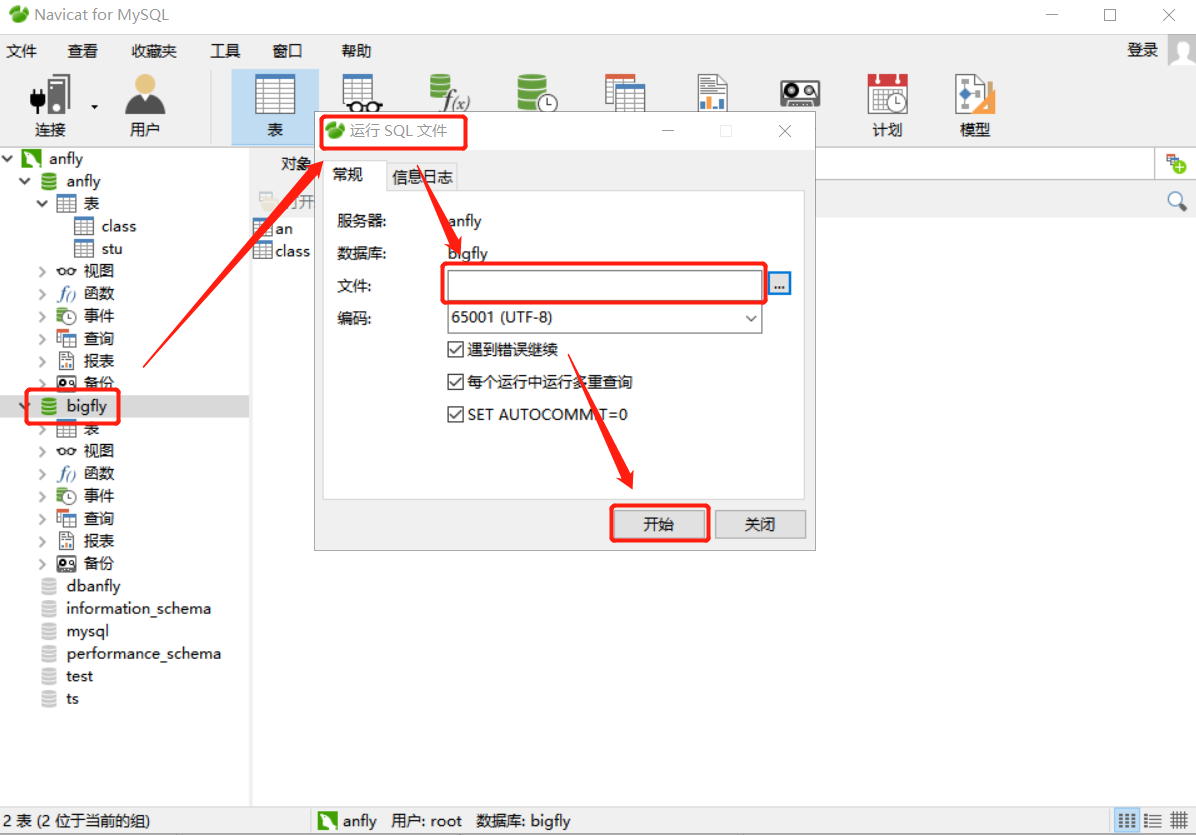
刷新即可,F5刷新
4.恢复
a)使用图形界面工具:
b)使用doc命令行:
i.不登录恢复
mysql -u用户名 -p密码 数据库<脚本文件路径
注意,不要打分号,不要登录mysql,直接在cmd下运行

ii.登录之后恢复
选择库 use 库名称
Source sql文件路径

八、数据库常用性能优化(了解)
-
数据库性能优化这块,我们考虑比较多的还是查询这块,互联网项目对数据查询非常频繁,对效率,性能要求比较高。
-
查询这块优化的话,主要就需要使用索引这种方式,所谓索引就是建立一种快速查找的方式,比如我们查字典,有一个ABCD的索引.
-
举个例子,如果我们创建一个表
create table user(id integer ,name varchar(20),job varchar(20));如果我们数据库中有1000万条数据,当我查询select * from user where name=’张三’的时候,这种查询方式就类似于整个数据库的扫描,效率非常低。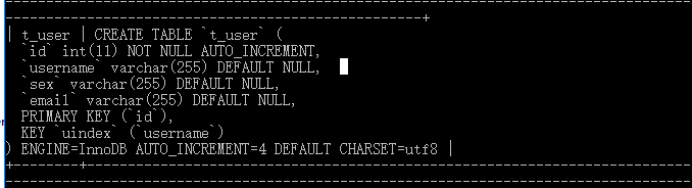
-
我们可以给这个name设置一个索引
create index n on user (name);这是设置一种普通(normal)索引,然后我们查询的时候,有了这个索引,效率就会大大提升,当然对于索引,它的方式有BTree类型和Hash类型,是两种管理数据库索引的方式,这个我没有深入研究。这个我们可以自己设置。默认是btree。 -
索引类型的话,有normal(普通类型)类型、unique(唯一类型)、fulltext全文索引、主键索引、非空索引、聚集索引。
①主键索引,primary key 在设置的时候,已经指定了,其实也是非空索引。
②非空索引是not null,设置这种方式的该字段下内容不能为空,
③聚集索引(联合索引),是在设置多个查询条件的时候使用。比如 创建一张表,有名字,有工作,我们想经常频繁的用到名字和工作它俩结合在一起来查询数据库中表的数据。这个时候,可以将名字和工作指定为聚集索引。create index m on user(name,job); 这样当我们指定select * from user where name=xxx and job=xxx的时候,就会按照索引方式来做。 -
这种优化方式就是索引优化,在使用索引优化方案的时候,我们需要注意避免在索引字段上使用条件函数等操作。
了解:
Show index form orders;查看索引
面试题:
-
为什么要创建索引呢(优点)?
这是因为,创建索引可以大大提高系统的性能。
①过创建唯一性索引,可以保证数据库表中每一行数据的唯一性。
②可以大大加快数据的检索速度,这也是创建索引的最主要的原因。
③可以加速表和表之间的连接,特别是在实现数据的参考完整性方面特别有意义。
④在使用分组和排序子句进行数据检索时,同样可以显著减少查询中分组和排序的时间。
⑤通过使用索引,可以在查询的过程中,使用优化隐藏器,提高系统的性能。 -
建立方向索引的不利因素(缺点)
也许会有人要问:增加索引有如此多的优点,为什么不对表中的每一个列创建一个索引呢?这种想法固然有其合理性,然而也有其片面性。虽然,索引有许多优点,但是,为表中的每一个列都增加索引,是非常不明智的。这是因为,增加索引也有许多不利的一个方面。
①创建索引和维护索引要耗费时间,这种时间随着数据量的增加而增加。
②索引需要占物理空间,除了数据表占数据空间之外,每一个索引还要占一定的物理空间,如果要建立聚簇索引,那么需要的空间就会更大。
③当对表中的数据进行增加、删除和修改的时候,索引也要动态的维护,这样就降低了数据的维护速度。 -
创建方向索引的准则
索引是建立在数据库表中的某些列的上面。因此,在创建索引的时候,应该仔细考虑在哪些列上可以创建索引,在哪些列上不能创建索引。
一般来说,应该在这些列上创建索引。
①在经常需要搜索的列上,可以加快搜索的速度;
②在作为主键的列上,强制该列的唯一性和组织表中数据的排列结构;
③在经常用在连接的列上,这些列主要是一些外键,可以加快连接的速度;
④在经常需要根据范围进行搜索的列上创建索引,因为索引已经排序,其指定的范围是连续的;
⑤ 在经常需要排序的列上创建索引,因为索引已经排序,这样查询可以利用索引的排序,加快排序查询时间;
⑥在经常使用在WHERE子句中的列上面创建索引,加快条件的判断速度。 -
同样,对于有些列不应该创建索引。一般来说,不应该创建索引的的这些列具有下列特点:
①对于那些在查询中很少使用或者参考的列不应该创建索引。这是因为,既然这些列很少使用到,因此有索引或者无索引,并不能提高查询速度。相反,由于增加了索引,反而降低了系统的维护速度和增大了空间需求。
②对于那些只有很少数据值的列也不应该增加索引。这是因为,由于这些列的取值很少,例如人事表的性别列,在查询的结果中,结果集的数据行占了表中数据行的很大比例,即需要在表中搜索的数据行的比例很大。增加索引,并不能明显加快检索速度。
③对于那些定义为text, image和bit数据类型的列不应该增加索引。这是因为,这些列的数据量要么相当大,要么取值很少。
④当修改性能远远大于检索性能时,不应该创建索引。这是因为,修改性能和检索性能是互相矛盾的。当增加索引时,会提高检索性能,但是会降低修改性能。当减少索引时,会提高修改性能,降低检索性能。因此,当修改性能远远大于检索性能时,不应该创建索引。
九、数据库性能检测方式(了解)
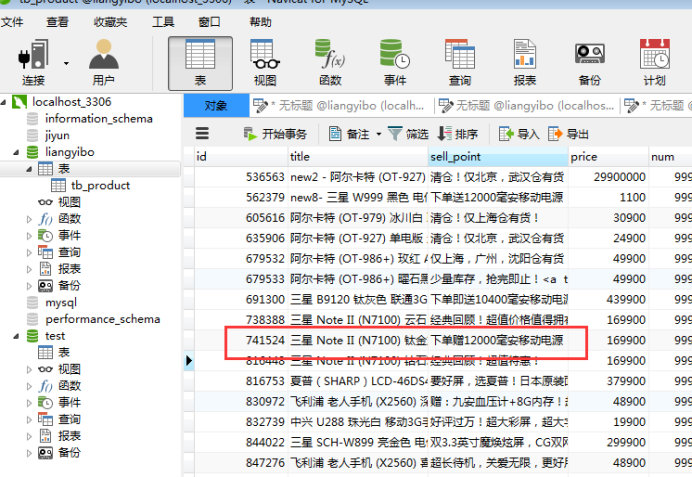
在设计SQL的时候,我们一般会使用explain检测sql,看是否使用到索引,避免出现整表搜索方式查询[filesort(不是以索引方式的检索,我们叫做filesort)](我在这张表中把gender设置成normal索引,name没有任何设置)
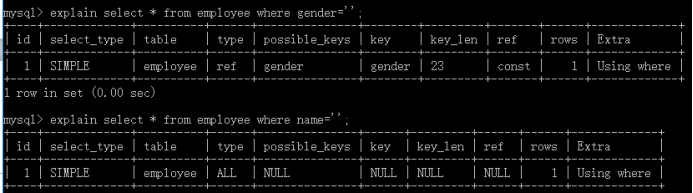
对比看的,对有索引的字段,在检测的时候,会显示是一个引用的key。
explain select*from tb_product where title='';
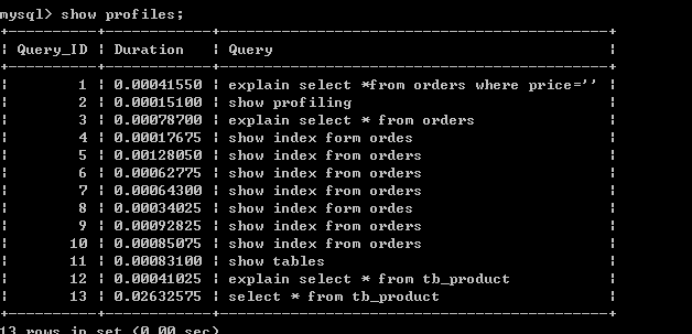
还可以使用profiling方式检测数据库执行的方式,可以查询sql的运行时间
注释:查看profiling信息,show variables like '%profiling%';
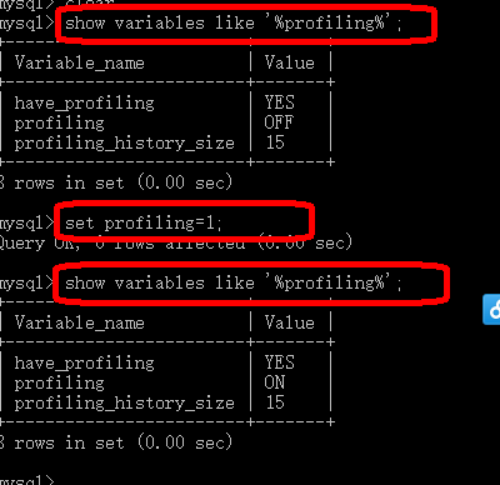
第一步:set profiling=1;(开启profiling)
第二步运行:select title from tb_product ;
第三步:查看运行时间show profiles;
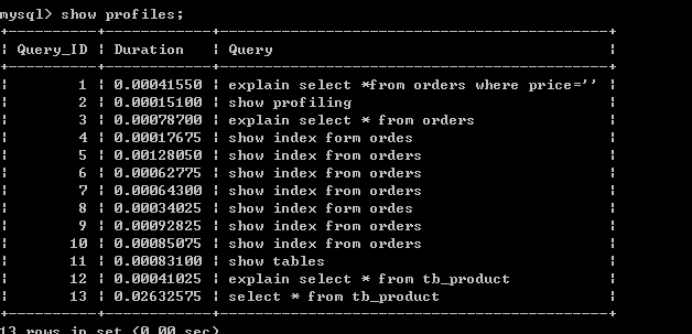
Duration:持续时间,事件花费的时间总计(以毫秒为单位?)