主要原因有两个方面:
- 为了防止历史报文被下一个相同的四元组的连接接收(主要)
- 为了安全性,防止黑客伪造相同序列号的TCP报文被对方接收
展开第一点:
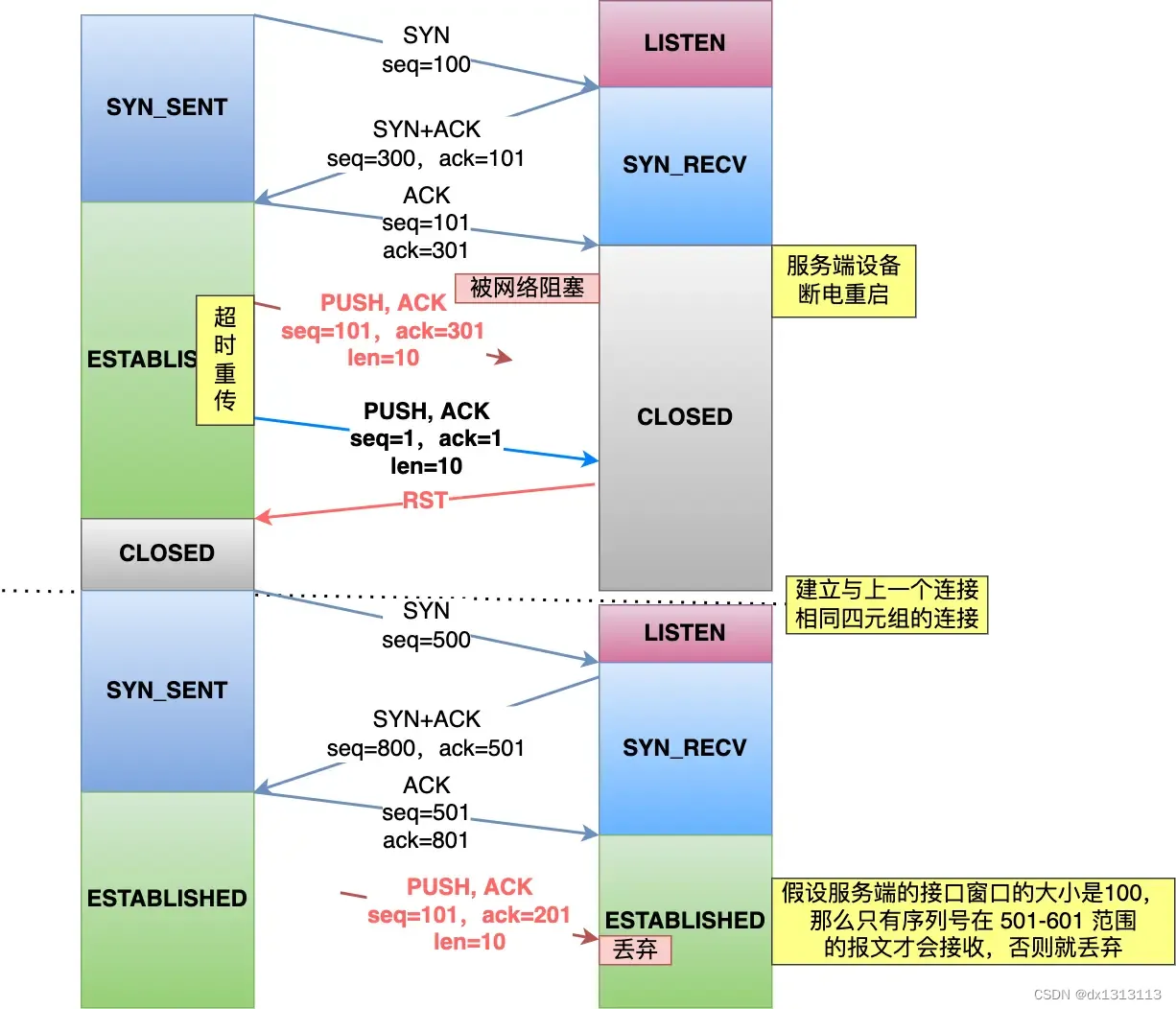
假设每次建立连接,客户端恶核服务端的初始化序列号都是从0开始:
过程如下:
- 客户端和服务端建立一个TCP连接,在客户端发送数据包被网络阻塞了,然后超时重传这个数据包,而此时服务端设备断电重启了,之前与客户端建立的连接就消失了,于是在收到客户端的数据包的时候就会发送RST报文。
- 紧接着,客户端又与服务端建立了与上一个连接相同的四元组连接。
- 在新连接建立完成后,上一个连接中被网络阻塞的数据包刚好到达了服务端,刚好该数据包的序列号正好是在服务端的接收窗口内,所以该数据包会被服务端正常接收,就会造成数据错误。

可以看到,如果每次建立连接,客户端和服务端的初始化序列号都是一样的话,很容易出现历史报文被下一个相同四元组的连接接收的问题。
如果每次建立连接客户端和服务端的初始化序列号都不一样,就有大概率因为历史报文的序列号不在对方的接受窗口,从而很大程度上避免了历史报文
如果每次建立连接客户端与服务端的初始化序列号都一样,就有很大概率遇到历史报文的序列号刚好在对方的接收窗口内,从而导致历史报文被新连接成功接收。
初始序列号ISN是如何随机产生的?
RFC793 提到初始化序列号 ISN 随机生成算法:ISN = M + F(localhost, localport, remotehost, remoteport)。
- M是一个计时器,这个计时器每隔4微秒+1
- F是一个Hash算法,根据源IP,目的IP,源端口号,目标端口号生成的一个随机数值。要保证Hash算法不能被外部轻易推算出,用MD5算法是一个比较好的选择
可以看出,随机数是会基于时钟计时器递增的,基本不可能会随机成一样的初始化序列号。