系列文章目录
本系列开篇文章,接下来应该还会写物体分类
文章目录
- 系列文章目录
- 前言
- 一、物体检测whatwhyhow
- 1.1 物体检测干啥的,怎么检测物体
- 1.2 传统和现代
- 1.2.1 传统方法
- 1.2.2 深度学习时代
- 1.3 深度学习物体检测评价标准
- 1.3.1 IoU
- 1.3.2 mAP
- 二、深度学习网络骨架(Backbone)
- 2.1 LeNet
- 2.2 AlexNet(深度学习破冰之作)
- 2.3 VGGNet(神经网络开始变的很深)
- 2.4 GoogLeNet
- 2.5 ResNet
- 2.6 DenseNet
- 2.7 CSP
- 三、Neck
- 3.1 FPN
- 3.2 PAN
- 3.3 SPP
前言
本篇文章是我这两年自学的目标检测的笔记的一个总结,因为我比较菜,所以可能会出现很多目标检测理解的错误,请大佬们见谅勿喷,欢迎友善讨论,如果本篇文章侵犯了您的权利,请联系我删除本篇文章,本文参考了https://github.com/floodsung/Deep-Learning-Papers-Reading-Roadmap(这个非常好的深度学习论文集免费且非常具有代表性)3.2节所提到的所有论文和花书和西瓜书和动手学深度学习和深度学习之PyTorch物体检测实战和一些讲Yolo和FastRCNN的文章和课程
一、物体检测whatwhyhow
1.1 物体检测干啥的,怎么检测物体
物体检测技术,通常是指在一张图像中检测出物体出现的位置及对应的类别
有点抽象,看图说话
如何在下图把框画出来
这里有两种思路
- 第一种物体类别,框的左下角坐标( x m i n x_{min} xmin, y m i n y_{min} ymin),框的右上角坐标( x m a x x_{max} xmax, y m a x y_{max} ymax)
- 第二种物体类别,框的中心点坐标(x,y),框的高度和宽度h、w
上述两种思路等价
(对于物体检测,我个人的想法找到可利用特征,利用特征的区别分类物体和定位,无论在计算机视觉还是在其他的声光电领域)
1.2 传统和现代
1.2.1 传统方法
物体检测传统算法通常分为区域选取、特征提取、特征分类三个阶段
1.区域选取:首先选取图像中可能出现的物体的位置,由于物体位置、大小都不固定,因此传统算法通常使用滑动窗口(Sliding Windows)算法,但这种算法会存在大量的冗余框
2.特征提取:在得到物体位置后,通常使用人工精心设计的提取器进行特征提取
3.特征分类:对上一步得到的特征进行分类,通常使用SVM、AdaBoost的分类器
————————摘自深度学习之PyTorch物体检测实战
我在大一的那一年(2016)接触过传统的特征提取,不过现在已经比较不常见了,所以就不多赘述了
1.2.2 深度学习时代
- 2014 RCNN(Regions with CNN features):拉开了深度学习做物体检测的序幕
- 2015 Fast RCNN(Faster R-CNN: Towards real-time object detection with region proposal networks.):提出锚框(Anchor)1这一划时代思想,实现端到端检测与卷积共享
- 2016 YOLO v1(You only look once: Unified, real-time object detection):实现了无锚框的一阶检测
- 2016 SSD(SSD: Single Shot MultiBox Detector.):实现了多特征图2的一阶检测
- 2016 R_FCN(R-FCN: Object Detection via Region-based Fully Convolutional Networks.):提高速度,稍微提升精度
- 2017 FPN:利用特征金字塔实现了更优秀的特征提取网络
- 2017 Mask RCNN:实例分割3,提升物体检测效果
- 2020 YOLO v4(YOLOv4: Optimal Speed and Accuracy of Object Detection.)
深度学习时代,物体检测算法常分为一阶两阶
- 两阶:两阶算法通常在第一阶段专注于物体出现的位置,第二阶段专注于对建议框进行分类,寻找更精确的位置,经典二阶Fast R-CNN
- 一阶:一阶算法将二阶算法的两个阶段合二为一,在一个阶段里完成寻找物体出现位置和类别预测,一阶速度一般较快(
当然快,两步并一步走人也走得快YOLO在实时领域大杀特杀,领域比如YOLO创始人退圈原因小道消息听个乐呵我没查证),但精度会有所损失,经典一阶YOLO
1.3 深度学习物体检测评价标准
1.3.1 IoU
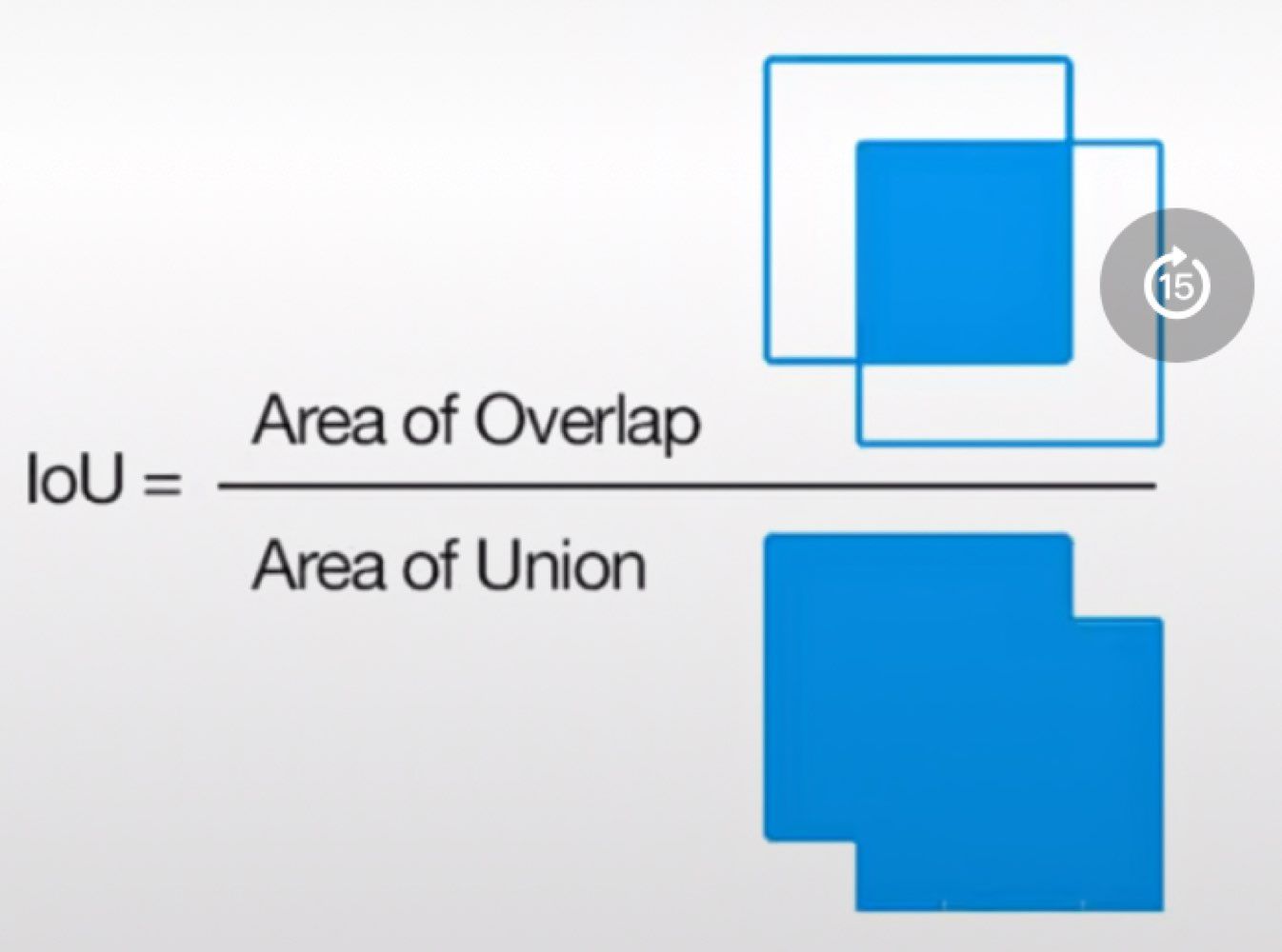
IoU(Intersection of Union):预测框与真实框的贴合程度,分子预测框与真实框重叠的部分(预测框与真实框交集),分母预测框与真实框所包含的所有区域(预测框与真实框并集)
I o U = S A ∩ S B S A ∪ S B IoU=\frac{S_A \cap S_B}{S_A \cup S_B} IoU=SA∪SBSA∩SB
1.3.2 mAP
前置知识
- 正确检测框TP(True Poseitive):预测框正确地与标签框匹配了,两者间的IoU大于0.5
- 误检框FP(False Positive):将背景预测成了物体
- 漏检框FN(False Negative):本来需要检测出的物体,模型没有检测出
- 正确背景TN(True Negative):本身是背景,模型也没有检测出来
在二分类问题中被称为真正例TP、假正例FP、真反例TN、假反例FN
P = T P T P + F P P=\frac{TP}{TP+FP} P=TP+FPTP
R = T P T P + F N R=\frac{TP}{TP+FN} R=TP+FNTP
P查准率(准确率)R查全率(召回率)
查准率和查全率是一对矛盾的度量,以查准率P为纵轴,以查全率R为横轴作图,就得到查准率-查全率曲线,简称"P-R曲线"
——————摘自西瓜书
预测值(Dets):物体类别、边框位置的4个预测值、该物体的得分
标签值(GTs):物体类别、边框位置的4个真值
AP一个类别的检测精度,mAP(mean Average Precision)多个类别的平均精度
AP计算方法
————————摘自深度学习之PyTorch物体检测实战
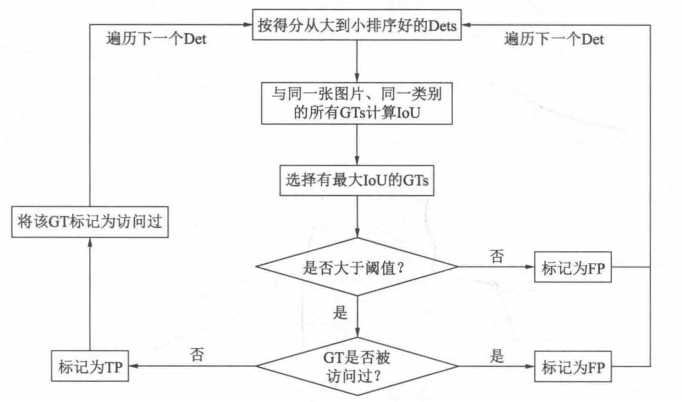
是不是懵了,我也有点懵,不过呢这还有个比较好理解AP的计算方法,计算P-R曲线下的面积
A P = ∫ 0 1 P d r AP=\int_0^1Pdr AP=∫01Pdr
这里积分上下限01比较好理解,因为P-R曲线横坐标R范围就(0,1)超出零到一那不能用传统的概率论了
这里先挖一个坑,为什么对P-R图积分会得到AP呢
这里不能简单地积分,严格意义上需要对曲线进行处理
需要的前置知识终于讲完了,接下来我们将游历深度学习的发展历程,并且发现深度学习在物体识别中的作用
二、深度学习网络骨架(Backbone)
当前的物体检测算法虽然各不相同,但第一步通常是利用卷积神经网络处理输入图像,生成深层的特征图,然后再利用各种算法完成区域生成与损失计算,这部分卷积神经网络是整个检测算法的骨架,也被称为Backbone
———摘自深度学习之PyTorch物体检测实战
本来我以为用Transformer物体检测就摆脱CNN了,然后我去翻了DETR(Detection Transformer),笑死上来先来一套CNN,所以本来我想修改上述引用,看来就不用大修了
CNN我不想写注释了,这都能单开一篇文章了,以后有时间再写CNN
我们先来看看深度学习怎么发展,然后看深度学习发展在网络骨架怎么应用的
本节大部分模型具体代码我攒一攒开服务器训练一下贴上来
在这里,我记录一下术语Backbone以及相关的neck,head等
其实这类似于人体结构,Backbone用于特征提取,head负责预测,neck接在Backbone和head之间,顺序大致如下(中间还会有很多层):input->backbone->neck->head(这难道就是屁股决定脑袋?(滑稽))
2.1 LeNet
LeNet来源于LeNet论文第一作者Yann LeCun,LeCun大家很熟啊,是深度学习三巨头之一,LeNet在被提出的时候能达到当时手写数字识别最先进的结果,LeNet第一次将卷积神经网络推上舞台,不过这个模型太老了,这里就不细讲了
2.2 AlexNet(深度学习破冰之作)
2012年Alex、Ilya、Hinton三位提出AlexNet,Hinton老爷子大家做深度学习的也肯定比较熟啊,Hinton老爷子也是深度学习三巨头之一,AlexNet在ImageNet赢下冠军后,人们开始重视起卷积神经网络(CV领域,其他领域可能还得晚一点才重视CNN),不过AlexNet的论文特别有意思,感觉就像现在的炼丹效果很好但不知道为啥(可能始作俑者就是AlexNet)(我不歧视炼丹,因为我本身就炼丹,炼丹技术还是得过硬,否则即便有很好的网络效果也不一定好,炼丹与网络架构相辅相成)
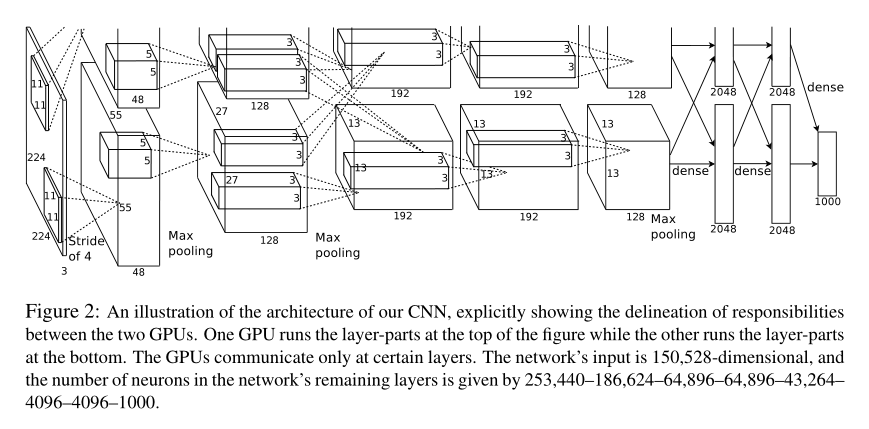
(有点绝望,我是不是还得写啥叫卷积层池化层丢弃法全连接层激活函数,挖坑)
上图为AlexNet的网络架构,第一层卷积层为卷积核大小为11×11的卷积层(这个卷积核有点大,以后的卷积神经网络少见大卷积核),然后接一个卷积核大小为3×3步幅为2最大池化层(Max Pooling),第二个卷积层为卷积核大小5×5的卷积层,第三、四、五个卷积层为卷积核大小3×3的卷积层,然后再接一个3×3步幅为2最大池化层,最后接两个全连接层(带丢弃法的全连接层),每层卷积层和全连接层激活函数都为ReLu函数,AlexNet还有图像增强缓解过拟合
2.3 VGGNet(神经网络开始变的很深)
AlexNet论文最后的Discussion说了一句AlexNet需要很深效果才好(当然当时论文里的论据不是很充分,但这句结论正确的),2014年VGG提出通过重复使用简单的基础块构建深度模型(没想到吧这么早就出现模块化概念了),并且VGG探索了网络深度与性能的关系

上图为AlexNet的Discussion
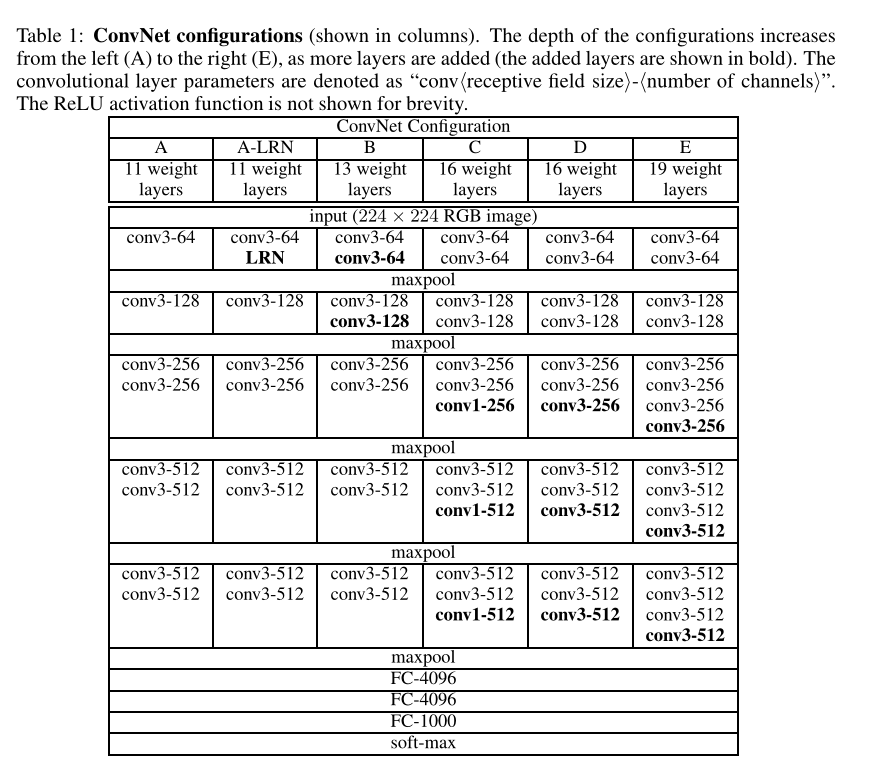
VGG块组成规律:连续使用数个相同的填充为1、窗口形状为3×3的卷积层后接上一个步幅为2、窗口形状为2×2的最大池化层,卷积层保持输入的高和宽不变,而池化层对其减半
————————摘自动手学深度学习
填充为1、窗口形状为3×3卷积后导致输出高度宽度与输入相同,步幅为2、窗口形状为2×2池化后导致输出高度宽度减半,常见的VGG有很多种,这里就不一一赘述了,按照项目选择模型组合
2.4 GoogLeNet
GoogLeNet虽然名字向LeNet致敬,但已经看不太出来LeNet影子,GoogLeNet继承了NiN中网络串联网络的思想,并在此基础上进行改进
GoogLeNet中最有特色的为Inception块(得名于盗梦空间)
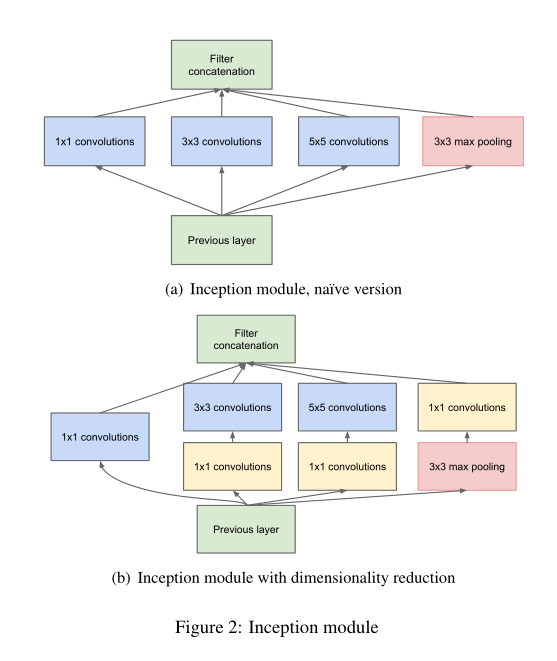
上图为Inception块结构
Inception块里有4条并行的线路。前3条线路使用窗口大小分别是1×1、3×3和5×5的卷积层来抽取不同空间尺寸下的信息,其中2个线路会对输入先做1×1卷积来减少输入通道数,以降低模型复杂度。第四条线路则使用3×3最大池化层,后接1×1卷积层改变通道数。4条线路都使用了合适的填充来使输入与输出的高和宽一致。最后我们将每条线路的输出在通道上连结,并输入接下来的层中去
————————摘自动手学深度学习
这里需要特殊说明的是第二通道和第三通道的1×1卷积层
假设我们将通道维当作特征维,将高和宽维度上的元素当作数据样本,那么1×1卷积层的作用与全连接层等价
NiN提出了另外一个思路,即串联多个由卷积层和“全连接”层构成的小网络来构建一个深层网络
NiN使用1×1卷积层来替代全连接层,从而使空间信息能够自然传递到后面的层中去
————————摘自动手学深度学习
经过上述的铺垫,大家应该明白为什么书中会说GoogLeNet吸收很多NiN的思想,第二通道和第三通道1×1的卷积层和NiN十分相似
2.5 ResNet
经过上述几个模型之后,人们认识到深度学习的模型深度与性能成正比,所以人们开始疯狂加层,然后令人困惑的现象出现了,达到一定层数后,模型的效果非但没变好,反而误差在增大,当时很多人认为,深度学习可能到头了,模型只能搭几十层,这时候何恺明大神(这位大佬还提出了MAE等著名模型)提出了ResNet模型,成功解决了深度问题,并深刻影响了后来的深度神经网络模型的设计,ResNet模型最具有特色的为残差块
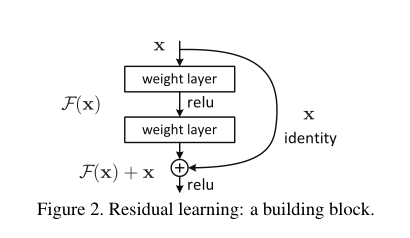
上图为残差块结构
ResNet最为核心的思想:保底,即达到一定层数后,如果下一层学的不好,那么我直接拿上一层的参数再训练,反正走到最后模型肯定不会比上次差(个人理解,理解错了勿喷)
其实按《动手学深度学习》里面讲的函数类可以这么理解:
首先,假设有一类特定的神经网络架构F,它包含学习速率和其他超参数设置。对于所有f ∈ \in ∈F,存在一些参数集(例如权重和偏置),这些参数可以通过在合适的数据集上进行训练而获得。现在假设 f ∗ f^* f∗是我们真正想要找到的函数,如果 f ∗ ∈ F f^* \in F f∗∈F,那我们可以轻而易举的训练得到它,但通常我们不会那么幸运。相反,我们将尝试找到一个函数 f F ∗ f^*_F fF∗,这是我们在F中的最佳选择。例如,给定一个具有x特性和y标签的数据集,我们可以尝试通过解决以下优化问题来找到它:
f F ∗ : = a r g m i n f L ( X , y , f ) s u b j e c t t o f ∈ F f^*_F:=\underset{f}{argmin}L(X,y,f)subject to f \in F fF∗:=fargminL(X,y,f)subjecttof∈F
那么,怎样得到更近似真正 f ∗ f^* f∗的函数呢?唯一合理的可能性是,我们需要设计一个更强大的架构 F ′ F' F′。换句话说,我们预计 f F ′ ∗ f^*_{F'} fF′∗比 f F ∗ f^*_F fF∗“更近似”。然而,如果 F ⊈ F ′ F \nsubseteq F' F⊈F′,则无法保证新的体系“更近似”。事实上, f F ′ ∗ f^*_{F'} fF′∗可能更糟,对于非嵌套函数(non-nested function)类,较复杂的函数类并不总是向“真”函数 f ∗ f^* f∗靠拢(复杂度由 F 1 F_1 F1向 F 6 F_6 F6递增)。下图左边虽然 F 3 F_3 F3比 F 1 F_1 F1更接近 f ∗ f^* f∗,但 F 6 F_6 F6却离得更远了。相反右侧的嵌套函数(nested function)类可以避免上述问题
————————摘自动手学深度学习
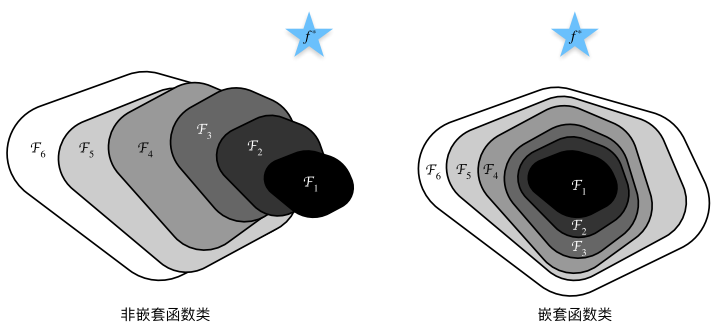
嵌套函数每次都包含上一次学习的架构,这样再差也不会比上次学的更差(保底),其实一开始我看到这么长的描述我都晕了(晕数学),后来仔细读过之后就明白其实就是把上次的结果与输出加和
还有两句话我还没揣摩明白,我先摆在这
Resnet通过短路连接,加强了前后层信息流通,在一定程度上缓解了梯度消失现象
————————摘自深度学习之PyTorch物体检测实战
在残差块中,输入可通过跨层数据线路更快地向前传播
————————摘自动手学深度学习
2.6 DenseNet
ResNet极大地改变了如何参数化深层网络中函数的观点(它改变了深度学习(雾)),这么好的工作自然有很多跟进,其中比较出名的DenseNet,ResNet只是连接一层,DenseNet我全都连(ps的时候把饱和度拉满),玩笑话说完,该看看数学推导了,从某种程度上,DenseNet拓展了ResNet
ResNet将函数展开为f(x) = x + g(x)
也就是说,ResNet将f分解为两部分:一个简单的线性项和一个复杂的非线性项那么再向前拓展一步,如果我们想将f拓展成超过两部分的信息呢一种方案便是DenseNet
ResNet和DenseNet的关键区别在于,DenseNet输出是连接而不是如ResNet的简单相加。因此,在应用越来越复杂的函数序列后,我们执行从x到其展开式的映射:
x → [ x , f 1 ( x ) , f 2 ( [ x , f 1 ( x ) ] ) , f 3 ( [ x , f 1 ( x ) , f 2 ( [ x , f 1 ( x ) ] ) ] ) , … x \rightarrow [x,f_1(x),f_2([x,f_1(x)]),f_3([x,f_1(x),f_2([x,f_1(x)])]),… x→[x,f1(x),f2([x,f1(x)]),f3([x,f1(x),f2([x,f1(x)])]),…
最后,将这些展开式结合到多层感知机,再次减少特征的数量。
DenseNet这个名字由变量之间的“稠密连接”而得来,最后一层与之前的所有层紧密相连
稠密网络主要由两部分组成:稠密块(dense block)和过渡层(transition layer)
稠密块定义如何连接输入和输出,过渡层控制通道数量
————————摘自动手学深度学习
2.7 CSP
三、Neck
3.1 FPN
3.2 PAN
3.3 SPP
———————————————————————填坑———————————————————————
———————————————————————我现在画饼越来越熟练了———————————————————————
————————————————————————2023年4月10日 20:26————————————————————————
—————————————————————————————注释—————————————————————————————
目标检测算法通常会在输入图像中采样大量区域,然后判断这些区域中是否包含我们感兴趣的目标,并调整区域边缘从而更精确地预测目标的真实边界框(ground-truth bounding box),不同的模型使用的区域采样方法可能不同。这里我们介绍其中的一种方法:它以每个像素为中心生成多个大小和宽高比(aspect ratio)不同边界框。这些边界框被称为锚框(anchor box)。(说白了,设置框的大小每个像素遍历一遍)
————————摘自动手学深度学习 ↩︎二维卷积层输出的二维数组可以看作输入在空间维度(宽和高)上某一级的表征,也叫特征图(feature map)(输入与卷积核卷积就会形成一个特征图,比如RGB图像与1个卷积核卷积会形成1个特征图)
————————摘自动手学深度学习 ↩︎语义分割和图像分割和实例分割
语义分割:将图像分割成属于不同语义类别的区域,这些语义区域的标注和预测都是像素级的
图像分割:将图像分割成不同区域,这类问题的方法通常利用图像中像素的相关性,在训练时不需要有关图像像素的标签信息,在预测时也无法保证分割出的区域具有我们希望得到的语义
实例分割:实例分割又叫同时检测并分割,实例分割研究如何识别图像中各个目标实例的像素级区域,与语义分割有所不同,,实例分割不仅区分语义,还区分不同的目标实例,比如一张图片存在两个狗,实例分割区分像素属于哪只狗
————————摘自动手学深度学习 ↩︎