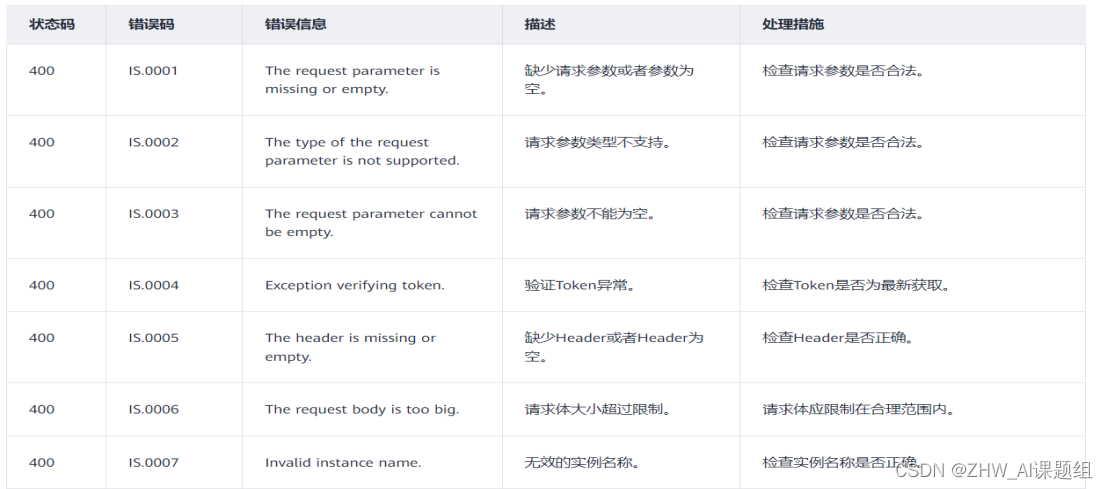
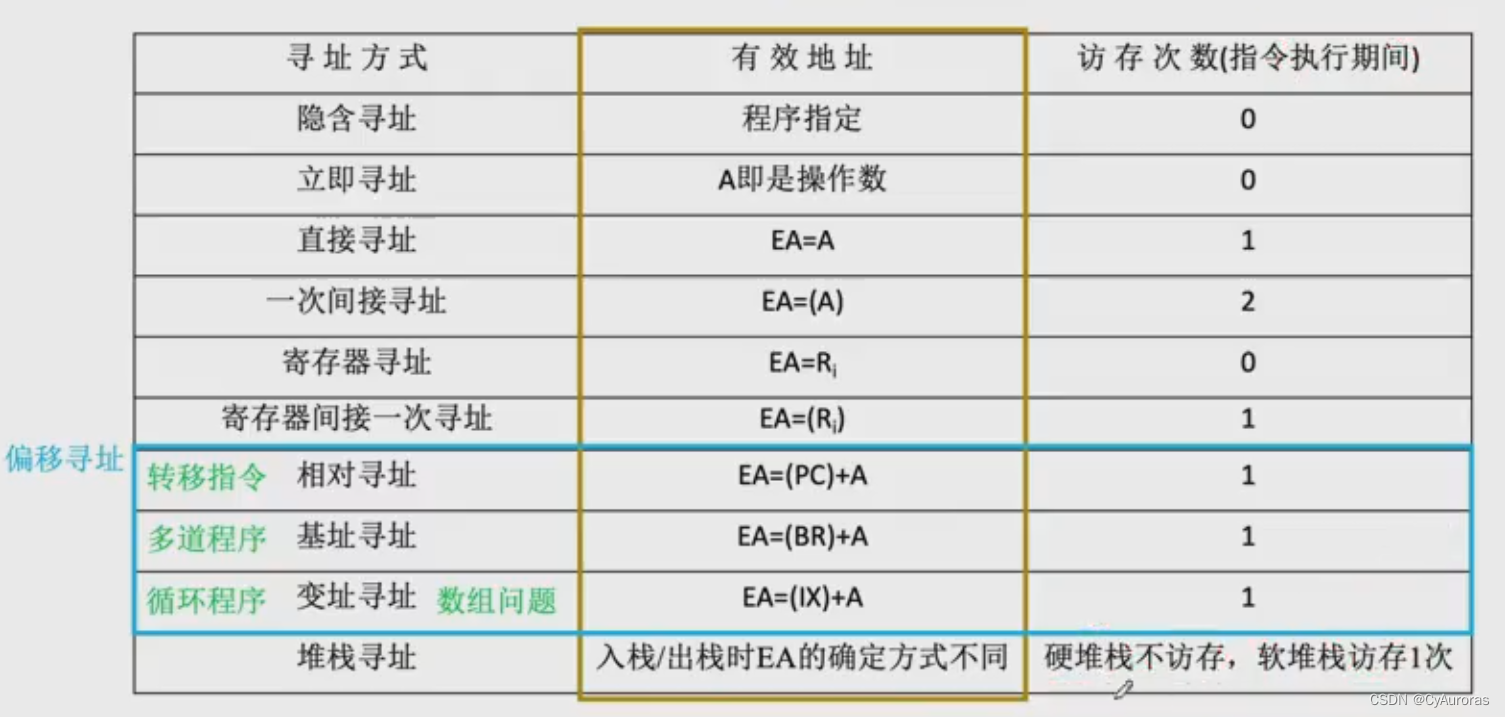
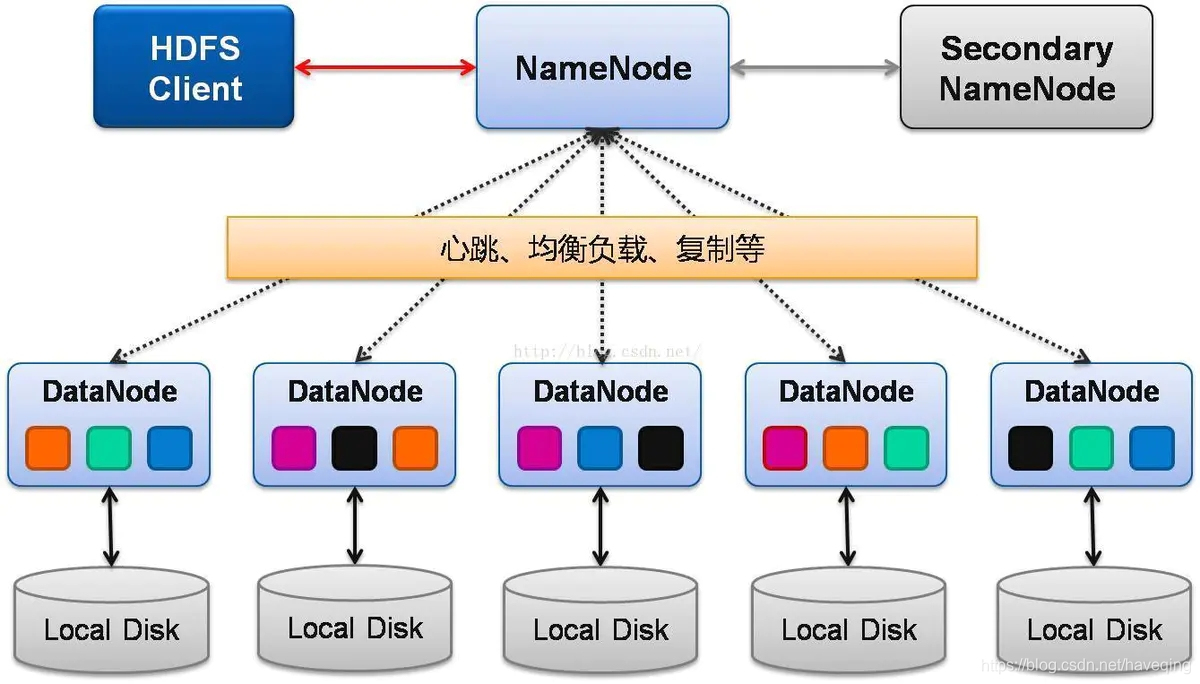
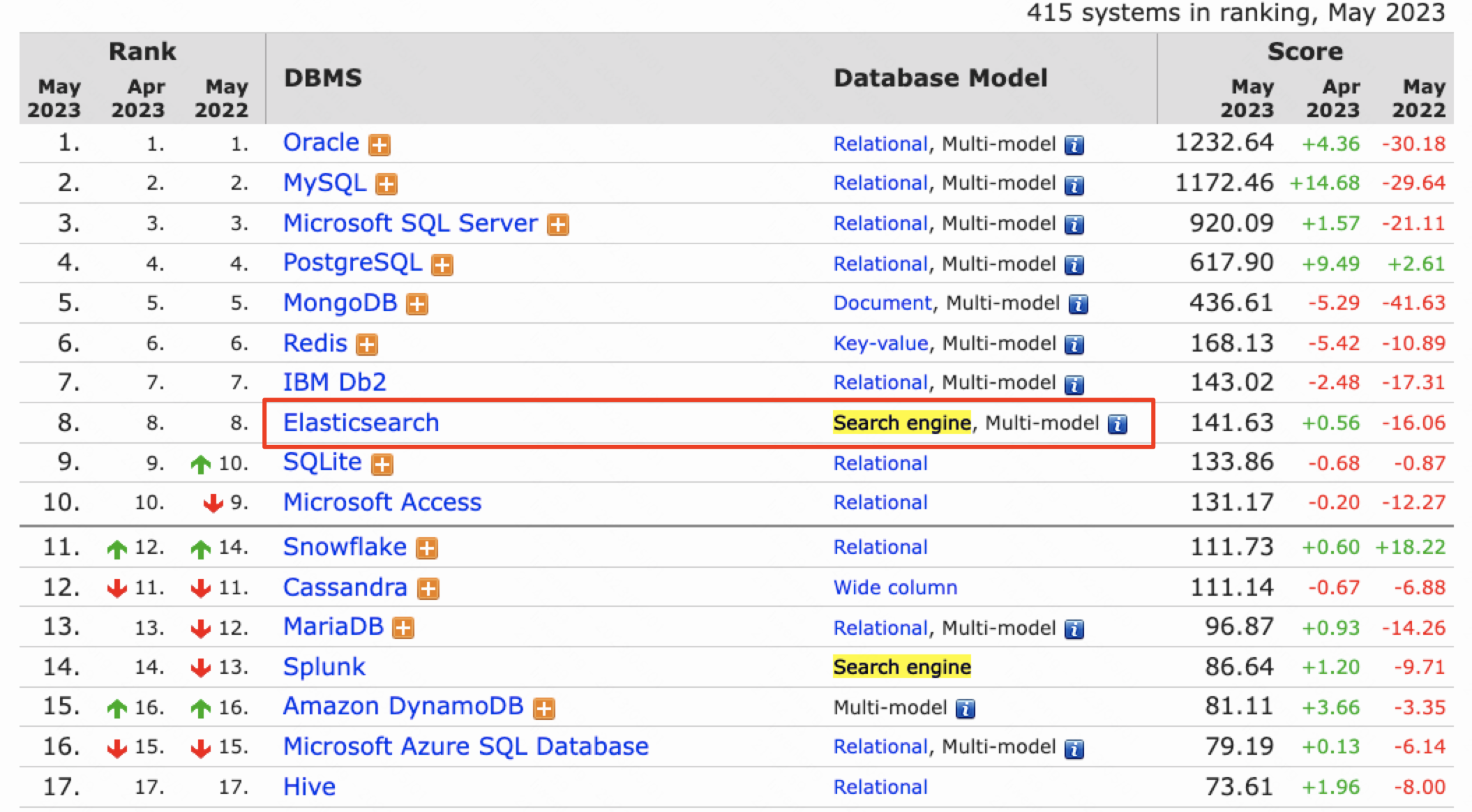
四、模型训练解析
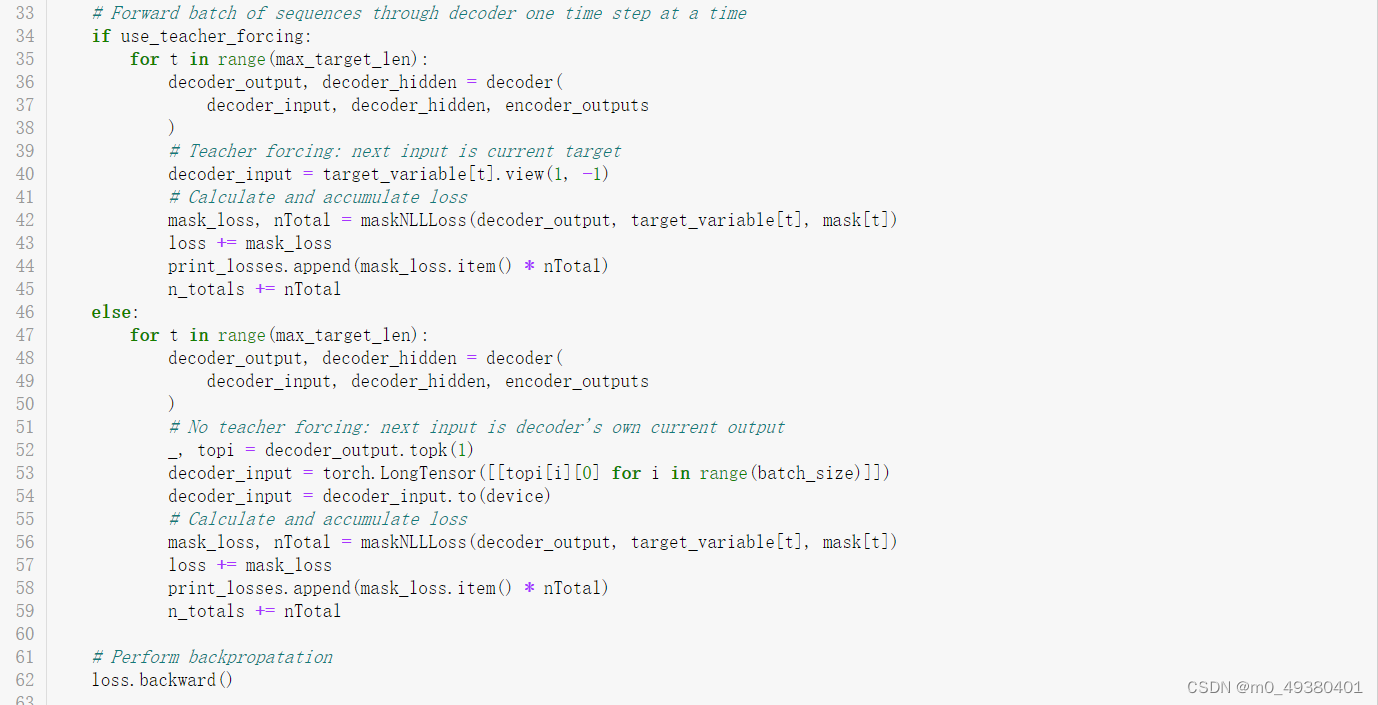
在PyTorch提供的“Chatbot Tutorial”中,关于训练提到了2个小技巧:
- 使用”teacher forcing”模式,通过设置参数“teacher_forcing_ratio”来决定是否需要使用当前标签词汇来作为decoder的下一个输入,而不是把decoder当前预测出来的词汇当做decoder的下一个输入,这是因为存在这样的情况,如果当前预测出来的词汇跟输入词汇从语义上来讲没有多大关联时,如果继续使用预测出来的词汇来训练模型,有可能就会造成比较大的预测偏差,从而导致模型训练后的预测效果很差,如果改为直接使用输入词汇对应的目标词汇(标签)来作为decoder的下一个输入,相当于进行强制纠偏,使decoder训练时输出与输入之间不至于出现偏差很大的情况。
- 第2个小技巧是使用梯度裁剪(Gradient Clipping),这是一种常用的防止梯度爆炸的技术。在深度学习训练过程中,因为网络层数较多,梯度可能会非常大,导致模型无法收敛。梯度裁剪的目的就是限制梯度的大小,使其不超过一个预设的阈值,从而避免梯度爆炸的问题。
训练过程如下:
- 输入语句正向传播通过encoder
- 使用SOS token作为decoder的初始输入,使用encoder的final hidden state来初始化decoder的hidden state
- Decoder端根据输入单步执行产生输出
- 如果执行”teacher forcing”模式,则把当前对应的目标词汇(标签)作为decoder的下一个输入,否则使用当前decoder的输出词汇作为decoder的下一个输入
- 计算并累加损失
- 执行反向传播
- 执行梯度裁剪
- 更新decoder和encoder的模型参数
以下是代码示例:


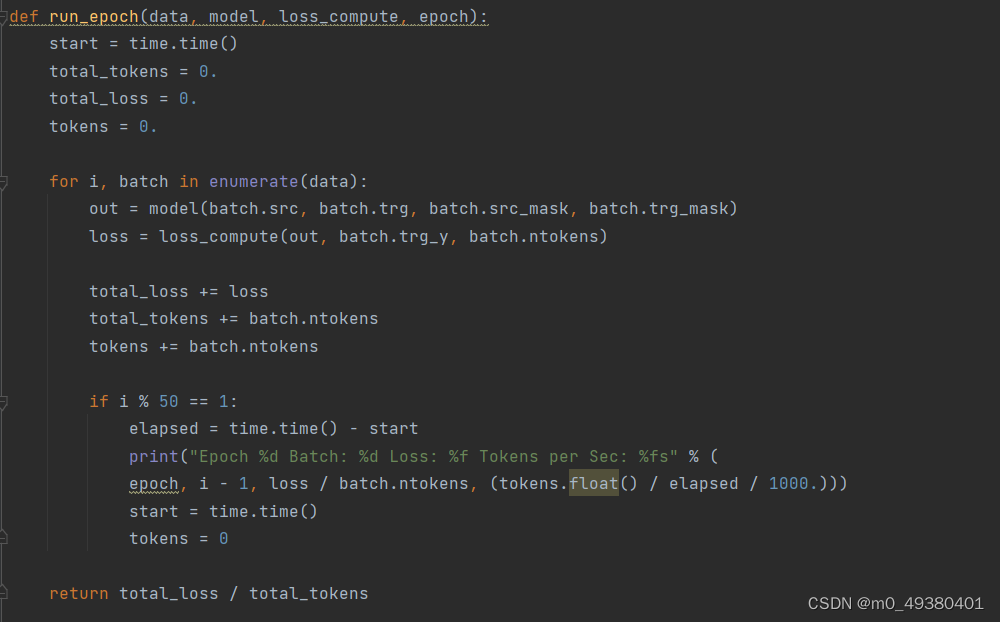
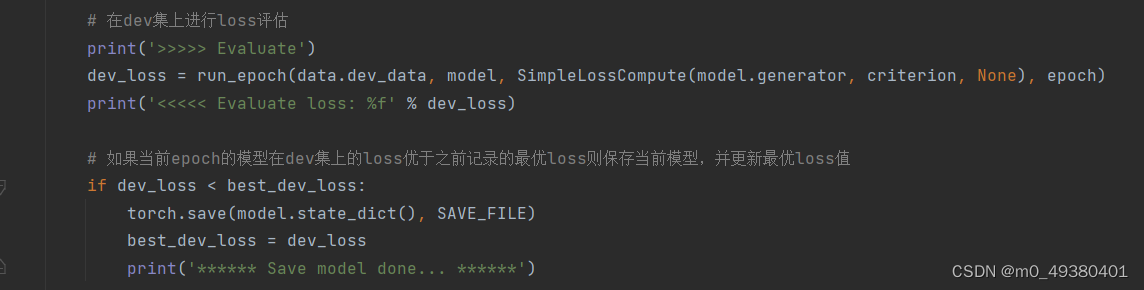
以下是Transformer模型训练代码示例,
- 首先把输入sequence(对话输入),输出sequence(对话输出),以及各自的mask传入模型做正向传播
- 计算预测结果与标签的损失,然后反向传播更新模型参数
- 训练时可以使用验证集(dev dataset)对训练效果进行评估
五、模型预测(推理)过程解析
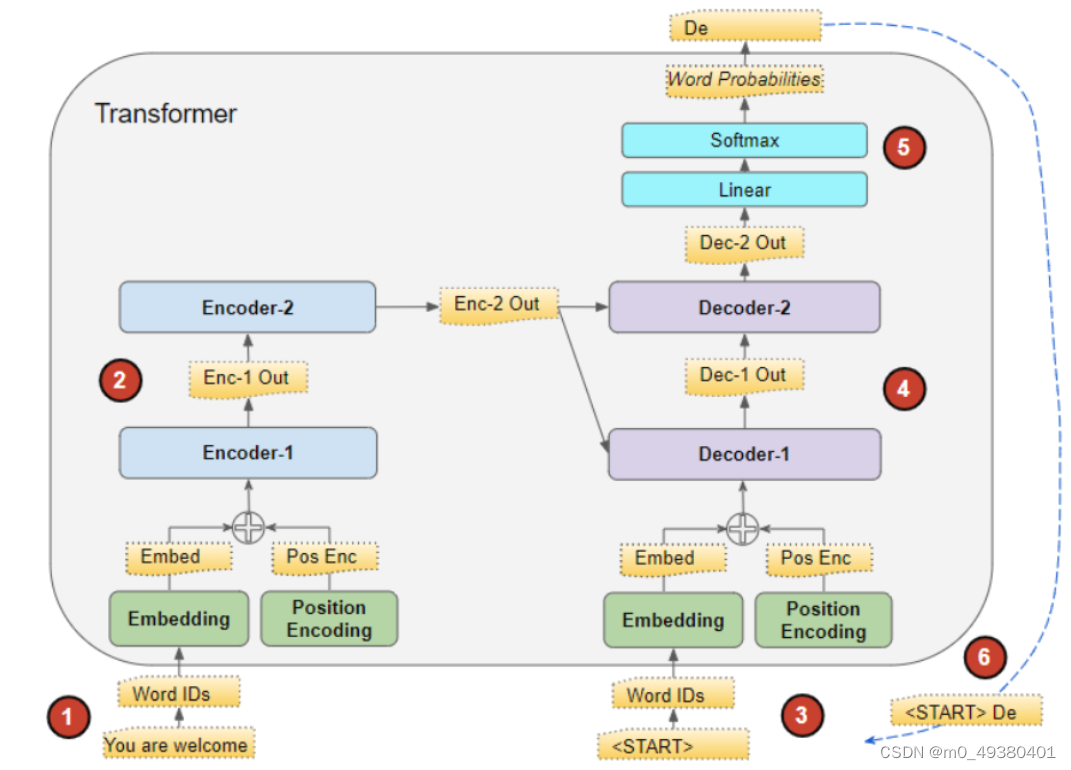
下面这个图描述了Transformer的预测推理过程:
- 假设使用两个encoder和两个decoder来构成这个Transformer模型,首先把输入语句转为embedding词向量,并加入位置编码信息
- 正向传播通过encoder1,它的输出再通过encoder2,期间会使用多头注意力机制对输入序列中的每个词向量并行地进行注意力Q,K,V的计算
- Decoder1使用<START> token进行初始化,并使用带掩码多头注意力机制进行计算,并且需要根据前面encoder2的输出进行注意力的计算,然后输出预测得到的词汇
- Decoder1输出的词汇作为decoder2的输入,同样decoder2在进行多头注意力计算时也需要使用encoder2的注意力计算输出结果
- Decoder2的输出传入线性层,之后使用Softmax函数转为0到1之间的概率,然后可以使用greedy search(贪心解码)算法得到概率最高的词汇作为预测结果
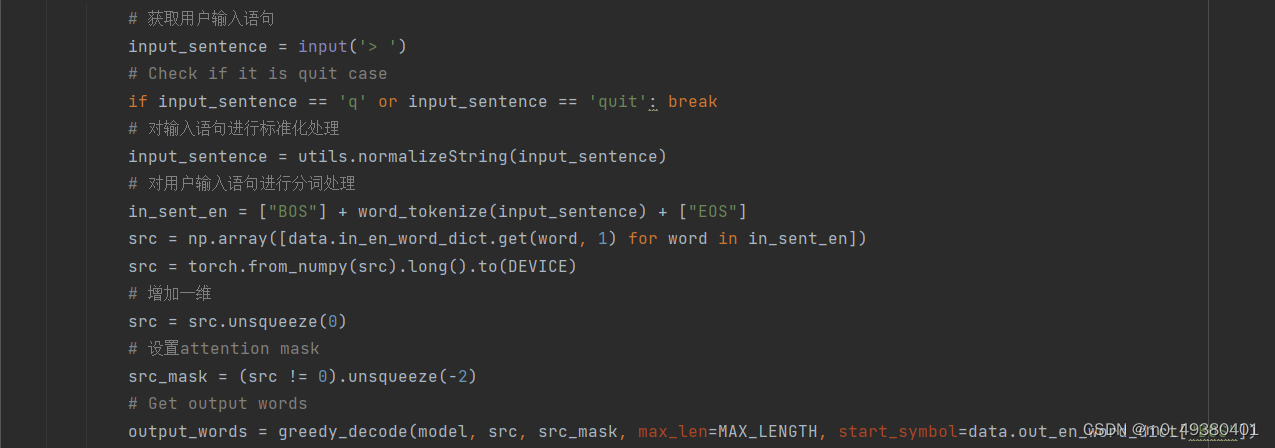
下面是预测相关代码的示例:
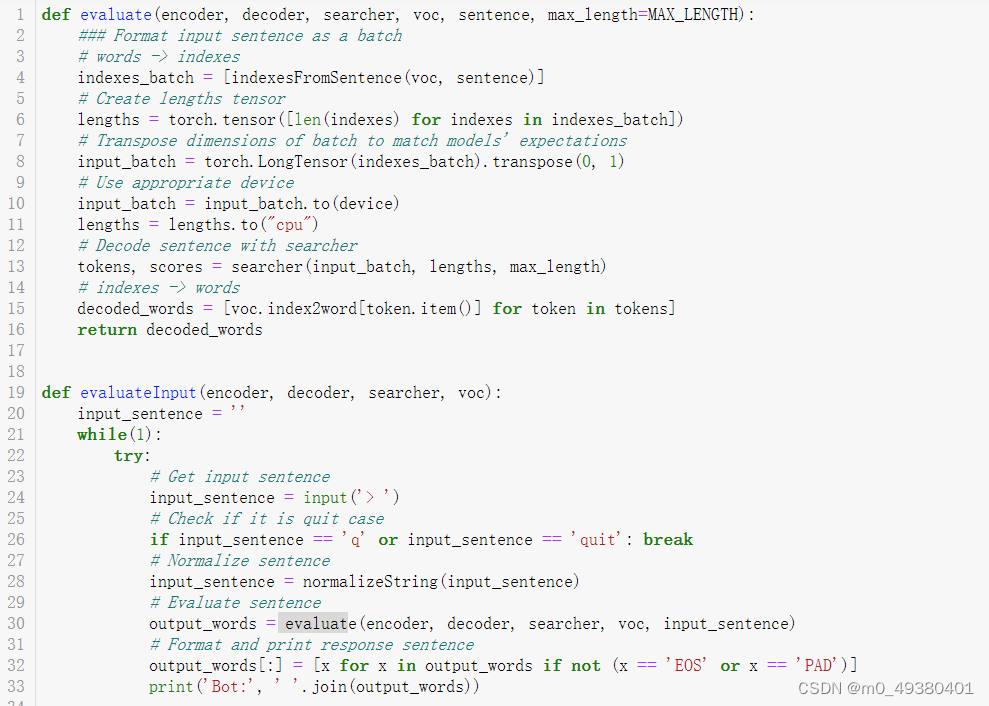
再来看下PyTorch提供的聊天机器人样例的预测操作:
- 用户输入正向传播通过encoder模型
- 把encoder的final hidden layer作为decoder模型的first hidden input
- 使用SOS_token作为decoder的第一个输入来初始化模型
- decoder根据encoder的输出(上篇文章提到的“Luong attention”注意力机制计算),以及当前decoder的输入,hidden state来输出预测得到的词汇(迭代操作)
- 使用Softmax计算概率并根据概率获取最有可能出现的词汇
- 把当前预测得到的词汇作为下一个decoder的输入
- 收集所有预测得到的词汇
以下是预测相关代码的示例:
六、聊天机器人对话效果解析
基于Transformer的聊天机器人和PyTorch提供的聊天机器人都使用同样的训练语料(“Cornell Movie-Dialogs Corpus.”)进行训练,基于Transformer的聊天机器人模型训练了20个epochs,输入语句最大长度设置为60,PyTorch提供的聊天机器人训练配置如下:
clip = 50.0
teacher_forcing_ratio = 1.0
learning_rate = 0.0001
decoder_learning_ratio = 5.0
n_iteration = 4000
print_every = 1
save_every = 500
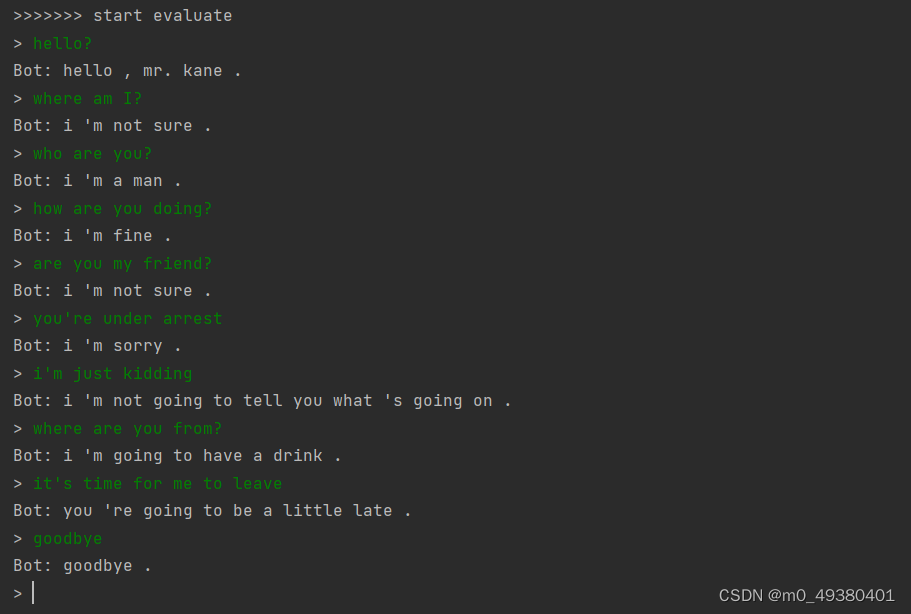
使用同样的测试对话语料分别对两个模型进行测试,基于Transformer模型的对话测试结果如下:
PyTorch提供的聊天机器人对话测试结果如下: