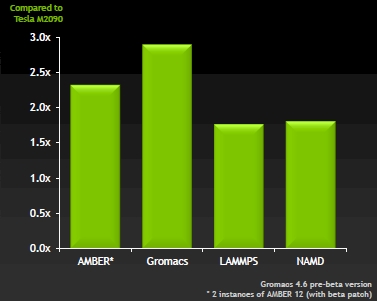
AMD K8 and K10 pipeline
(The microarchitecture of Intel, AMD and VIA CPUs https://www.agner.org/optimize/)
-
流水线结构
- 指令会尽可能少,尽可能晚地在流水线中被拆分。每一条read-modify宏指令会在执行阶段拆分成read和modify微指令,在提交之前重新合并成宏指令。
- K8没有执行单元的执行带宽超过64或者80位,K10则支持128位的浮点执行单元。
- AMD和Intel的最大差别:AMD包括三条并行的流水线。在取指阶段之后,指令就会分布到三个流水线中。在简单的情况下,指令会在相应的流水线提交。
- K10有stack engine,结构类似于Intel的处理器
- 流水线的长度估计是12级,因为测量的错误分支预测代价为12周期
- 流水线的具体结构
- 指令取指1, K10每周期32B,K7/8每周期16B
- 指令取指2+转移预测
- Pick/Scan。能够缓存7条指令,并且会将三条指令分发到三个流水线的译码器中
- 译码1,分解指令
- 译码2,决定输入输出寄存器
- Pack。解码器最多生成六个宏操作,同时被排列成3个执行流水线的三个宏操作行
- Pack/Decode。寄存器重命名。整数寄存器从“integer future file and register file”中读取。将整数指令发射到整数流水线,浮点指令发射到浮点流水线。
- Dispatch(整数)。发射宏操作到RS(3*8)
- Schedule(整数)。乱序调度read-modify和read-modify-write指令会被拆分成多条微操作
- Execution units and address generation units(整数)。三条整数流水线都有ALU和AGU。整数乘法只能够在其中一条流水线完成
- Data cache access(整数)。发射读/写请求到数据缓存
- Data cache response(整数)
- Retirement(整数)。按序提交宏操作
- Stack map(浮点)。将浮点栈寄存器映射到虚拟寄存器
- 寄存器重命名(浮点)
- Dispatch(浮点)
- Schedule(浮点)。RS为3*12表项。
- Register read(浮点)。
- Execution units(浮点)。FADD,FMUL,FMISC,均为流水化实现,但是延迟超过了1周期。整数向量操作在浮点单元执行
- 浮点的地址计算,缓存访问,提交可能和整数流水线共用一套。
- 浮点流水线由于增加了一些新的流水级,因此更长。最小的浮点指令延迟测量为2周期,最大的为4周期。
- LSQ按序完成所有的内存读操作,写操作也按序完成,但是允许读操作之前的写操作之前完成
- 作者测量:在段基址为零时,计算地址和从L1-cache读取的操作需要3个周期;否则需要4周期。(大部分情况为零,在16为系统的保护模式和实模式下为非零)
- Vector path指令:复杂的指令,需要超过两个宏操作的指令。
-
指令取指:
- K10中,取指包以32B对齐,在K7和K8中以16B对齐
- 分支信息存储在I-cache中。jump和跳转分支的吞吐量为每两个周期一条跳转
-
Predecoding and instruction length decoding
- 指令长度范围为1-15B。指令的边界信息会标记在I-cache中,同时会拷贝到L2-cache中。因此指令长度译码不会是一个瓶颈,尽管每周期只能处理一条指令
- I-cache存储着许多的预译码信息,包括指令的终止位置,操作码的位置,区分(单,双,向量)路径指令和标识jump和call的信息。其中有一部分的信息也会被复制到L2-cache中。(大量的预译码信息可能会导致带宽降低)
- K8每周期最多可以译码三条指令,不管是否对齐
- 每个指令译码器每周期只能够处理最多三个前缀,如果多了需要额外的周期。
-
Single, double and vector path instructions
- 三种指令的区分:
- direct path single instruction:只能够产生一条宏操作的指令
- direct path double instruction:能够产生两条宏操作的指令
- vector path instruction :能够产生超过两条宏操作的指令
- 处理器的吞吐量限制为每周期三条宏操作,而不是指令。
- 向量路径指令比另外两种指令更低效,因为需要独占译码器和流水线,通常也无法进行重排序优化
- 一条宏操作会存在多个输入相关,例如MOV [EAX+EBX],ECX
- 三种指令的区分:
-
整数执行管道
- 三条流水线的每一条都有单独的ALU和AGU。但是只有一条流水线能够执行整数乘法操作。
- 每个周期最多允许进行两条存储操作和一条lea指令,因为D-cache只有两个端口
- 32位整数乘法需要3周期,在全流水线的情况下仅需要一个周期。
-
浮点执行管道
- 包括三个执行单元称为:FADD,FMUL,FMISC。FMUL处理乘法和除法。FMISC则用于处理写内存和类型转换操作。三个单元都可以完成读内存操作
- 浮点执行单元有自己的寄存器堆和80位数据总线
- 加法和乘法操作延迟为4周期,全流水化后为1个周期。除法为11个周期,无法流水化。数据传输和比较操作需要两个周期。
- SIMD的整数操作同样在浮点流水线完成,FADD和FMUL管道都包括了整数ALU,能够处理加法,布尔运算和以为操作。整数乘法只能够在FMUL中完成。
-
Store forwarding stalls
-
如果读操作和前一个写操作的地址相同,但是读的数据宽度更大,则此时无法进行前递
-
如果起始地址不同,也无法进行前递
-
如果写操作的数据保存在AH,BH,CH,DH中,则无法进行前递
; Example 17.7. Store forwarding stall for AH mov [esi],al ; Write 8 bits mov bl,[esi] ; Read 8 bits. No stall mov [edi],ah ; Write from high 8-bit register mov cl,[edi] ; Read from same address. Stall
-
-
Cache
- I-cache和D-cache:
- 64KB,2路组相联,64B。D-cache包括两个端口可以用于读/写。
- 在K10中,读端口为128位,写端口为64位。在K8中,都为64位。
- 在I-cache中,64B的cache-line被均分为4块;在D-cache中,被分成8块。在同一个bank,同一个周期无法进行俩个存储操作,除非两个访问相同cacheline的都操作
- L2-cache:
- 512KB(可能更多),16路组相联,64B,总线宽度128位,伪LRU替换算法
- 数据预取只会发生在L2-cache
- L2-cache包括了用于自动纠错的位,但是只适用于数据,而不包括代码。对于代码,预留的位域将用于保存一些额外的信息,例如指令边界,分支信息等。(代码是只读的数据,因此发生奇偶校验错误时,可以直接从RAM重新加载)
- I-cache和D-cache: