目录
一、无效数据的常见场景
(1)测试阶段
(2)测试方法
二、无效数据的概念
三、无效数据的影响
四、无效数据的识别
五、无效数据的处理方法
(1)拒绝无效数据
① 拒绝无效数据的概念
② 拒绝无效数据的方法
(2)过滤无效数据
① 过滤无效数据的概念
② 过滤无效数据的方法
(3)转换无效数据
① 转换无效数据的概念
② 转换无效数据的方法
(4)数据验证
① 数据验证的概念
② 数据验证的方法
(5)数据清洗
① 数据清洗的概念
② 数据清洗的方法
③ 数据清洗的工具
④ 数据清洗的挑战
⑤ 数据清洗的注意事项
六、减少无效数据的方法
七、实际案例举例
(1)医疗行业
(2)电商行业
(3)音视频行业
一、无效数据的常见场景
(1)测试阶段
在测试过程中,以下测试阶段可能会出现无效数据:
- 研发自测
- 冒烟测试
- 功能测试
- 接口测试
- 并发测试
- 压力测试
- 渗透测试
(2)测试方法
在测试过程中,以下测试方法可能会出现无效数据:
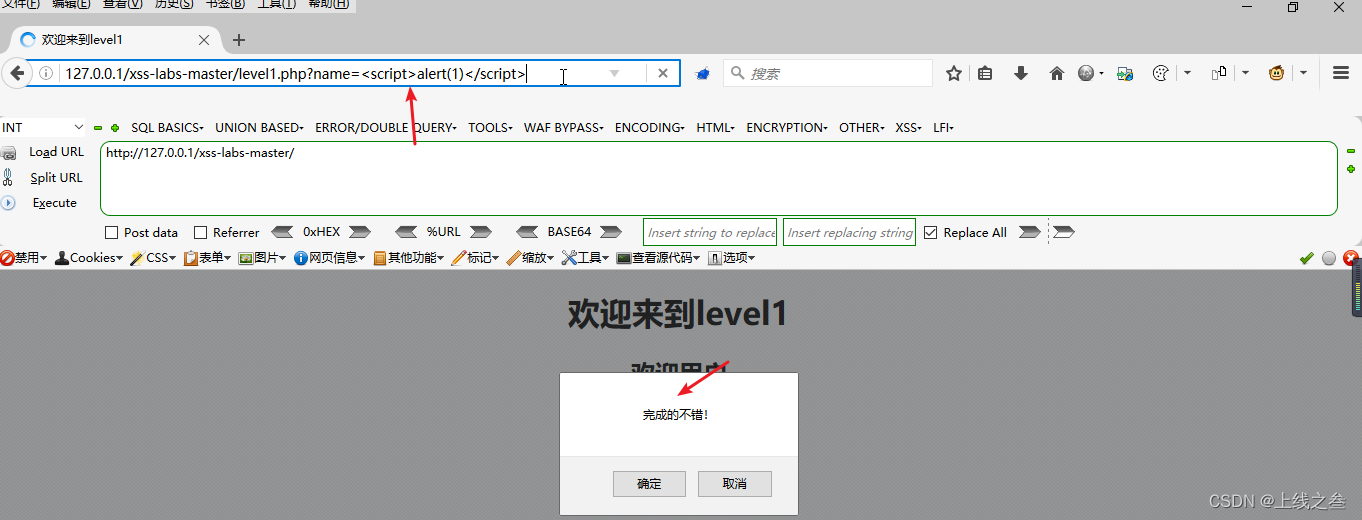
空值测试:测试输入为空或未定义的数据,例如空字符串、空数组、null 等。
边界测试:测试数据在边界值上的情况,例如测试最小值和最大值、正数和负数、整数和小数等。
数据格式测试:测试数据的格式是否符合要求,例如测试日期格式、时间格式、货币格式、电话号码格式等。
数据类型测试:测试数据类型是否符合要求,例如测试整数、小数、布尔值、字符串、对象等。
数据范围测试:测试数据是否在有效范围内,例如测试年龄是否在 0 到 120岁 之间、测试金额是否在 0 到 1000000 之间等。
非法输入测试:测试输入是否符合要求,例如测试输入是否为空、是否为非法字符、是否为无效数据等。
无效字符测试:测试数据中是否包含无效字符,例如测试输入是否包含特殊字符、非法字符等。
无效长度测试:测试数据长度是否符合要求,例如测试字符串长度是否符合要求、测试数组长度是否符合要求等。
无效数据测试:在测试中,测试人员可能会故意输入无效数据,但如果测试人员没有正确识别无效数据,可能会导致测试数据无效,例如个人信息年龄为 25 岁,但是生日为去年,而需求统计需同时用到年龄和生日数据完成分析,同时个人信息不做强制关联,生产环境测试产生的无效数据会影响实际分析等。
随机测试:随机生成的测试数据可能会包含无效数据,因为这些数据没有经过验证。
环境测试:如果测试人员没有考虑到测试环境的影响,可能会导致测试数据无效
重复测试:在重复测试中,如果测试人员没有正确处理之前的测试数据,可能会导致测试数据无效
二、无效数据的概念
- 在测试过程中,无效数据指的是不符合预期输入要求或者不合法的数据。
- 无效数据可能是无效的格式、无效的类型、无效的范围或无效的关联。
- 无效数据在测试过程中需要被充分考虑和测试,以保证系统能够正确地处理这些数据并且不会出现异常行为。
- 同时,测试人员需要在测试用例中涵盖尽可能多的无效数据情况,以提高测试覆盖率和测试质量。
三、无效数据的影响
无效数据对系统造成影响的原因:
系统容错性不足:当系统接收到无效数据时,如果系统没有足够的容错机制来处理这些数据,就会导致系统崩溃或者产生错误,从而影响系统的正常运行。
数据处理错误:无效数据可能会导致系统对数据的处理出现异常,例如无效数据可能会导致系统计算错误或者逻辑错误,从而影响系统的正确性和可靠性。
安全问题:无效数据可能会被恶意攻击者利用来进行攻击,例如 SQL 注入攻击、跨站脚本攻击等,从而导致系统的安全性受到威胁。
数据库异常:无效数据可能会导致数据库出现异常,例如数据过长、数据类型错误等,从而影响系统的数据存储和查询功能。
用户体验问题:无效数据可能会导致系统出现异常或者错误提示,从而影响用户的使用体验,降低用户的满意度。
综上所述,无效数据对系统造成的影响是非常严重的,测试人员需要在测试过程中充分考虑这些因素,确保系统能够正确处理各种类型的数据,提高系统的稳定性和可靠性。
四、无效数据的识别
在测试过程中识别无效数据的方法如下:
确认数据的格式和类型是否正确:在测试过程中,我们应该检查数据是否符合预期的格式和类型。例如,如果我们正在测试一个电子邮件应用程序,我们可以检查电子邮件地址是否包含“@”符号。
检查错误消息:在测试过程中,我们应该检查系统是否正确地处理无效数据,并生成适当的错误消息。例如,如果我们正在测试一个登录应用程序,我们可以尝试使用无效的用户名和密码来测试系统的反应,并检查系统是否正确地生成错误消息。
使用边界值测试:边界值测试是一种测试方法,它使用最小和最大值来测试系统的行为。例如,如果我们正在测试一个计算器应用程序,我们可以使用边界值测试来确定系统是否正确地处理最小和最大值。
使用随机数据测试:随机数据测试是一种测试方法,它使用随机生成的数据来测试系统的行为。例如,如果我们正在测试一个搜索引擎应用程序,我们可以使用随机搜索词来测试系统的搜索功能。
使用黑盒测试:利用黑盒测试方法进行测试,通过输入各种数据进行测试,发现无效数据并记录下来。例如,可以输入数字、字母、特殊字符等各种数据进行测试,发现无效数据并记录下来,以便后续分析和修复。
使用人工测试:在测试过程中,我们应该使用人工测试来确定系统是否正确地处理无效数据。例如,如果我们正在测试一个购物车应用程序,我们可以尝试添加无效的商品并检查系统的反应。
使用需求分析测试:根据需求文档和功能规格说明书进行分析,确定有效数据的范围和类型,然后将无效数据定义为不在这个范围和类型内的数据。例如,如果一个系统要求输入年龄必须在18岁到60岁之间,那么输入小于18岁或大于60岁的数据就可以认为是无效数据。
- 使用场景分析测试:根据输入数据的特征和业务逻辑进行判断,确定无效数据的特征。例如,如果一个系统要求输入的电话号码必须是11位数字,那么输入非数字字符或者长度不为11位的数据就可以认为是无效数据。
- 使用自动化测试:利用自动化测试工具进行数据校验和过滤,排除无效数据。例如,可以使用正则表达式或者数据校验工具对输入数据进行检查,如果数据不符合规定,就可以自动过滤掉。
总的来说,识别无效数据需要结合具体的业务需求和测试方法进行分析和判断,只有通过多种方法进行测试,才能准确地识别出无效数据。
五、无效数据的处理方法
(1)拒绝无效数据
① 拒绝无效数据的概念
拒绝无效数据:是指在测试过程中,测试人员拒绝使用或接受无效数据进行测试的方法。可以通过编写测试用例来验证输入数据是否符合要求。如果输入数据不符合要求,可以拒绝该数据,并给出相应的提示信息。
② 拒绝无效数据的方法
确认测试需求和规范:在测试开始前,测试人员应该清楚地了解测试需求和规范,以便能够识别无效数据并拒绝使用它们进行测试。
设定数据验证规则:测试人员可以设定数据验证规则,以确保只有符合规则的数据才能被用于测试。例如,可以设定输入数据必须符合特定格式或长度等规则。
使用模拟数据:测试人员可以使用模拟数据来代替无效数据进行测试。模拟数据是根据测试需求和规范生成的数据,可以确保测试的准确性和可靠性。
强制输入数据:测试人员可以通过强制输入数据的方式来确保只有符合规范的数据才能被用于测试。例如,在测试时,可以禁止测试人员手动输入数据,只能从特定的数据源中选择数据进行测试。
(2)过滤无效数据
① 过滤无效数据的概念
过滤无效数据:是指在测试过程中,通过一定的筛选方法,将不符合测试目的或无法产生有效测试结果的数据进行过滤或剔除,从而提高测试效率和准确性的方法。可以使用过滤器来过滤掉无效数据。过滤器可以根据预设的规则来判断数据是否有效,并将无效数据过滤掉。
② 过滤无效数据的方法
数据清洗:对测试数据进行预处理,去除重复数据、空数据、异常数据等无效数据,保证测试数据的准确性和完整性。
数据采样:对测试数据进行随机或有选择地采样,避免测试数据集过大或过小,从而影响测试结果的准确性。
数据分析:对测试数据进行统计分析,筛选出对测试结果有重要影响的数据,优先进行测试,提高测试效率。
数据过滤:根据测试需求和测试目的,对测试数据进行筛选,去除不必要的数据,减少测试时间和成本。
(3)转换无效数据
① 转换无效数据的概念
转换无效数据:是指在测试过程中,将无效数据转换为有效数据以便进行测试的一种方法。例如,对于日期格式不正确的数据,可以将其转换为正确的日期格式。
② 转换无效数据的方法
数据转换:将无效数据转换为有效数据,使其符合预期输入要求或者业务逻辑。例如,将非法字符替换为合法字符、将超长字符串截断、将不合法的日期格式转换为合法的日期格式等。
数据清洗:在测试前对数据进行清洗,去除无效数据。例如,去除空格、去除重复数据、去除无效字符等。
数据生成:生成符合预期输入要求或者业务逻辑的数据,用于测试。例如,生成随机数、生成指定范围内的数字、生成符合业务逻辑的数据等。
数据验证:对转换后的数据进行验证,确保其符合预期输入要求或者业务逻辑。例如,验证日期格式是否正确、验证字符串长度是否符合要求、验证数据是否符合业务逻辑等。
(4)数据验证
① 数据验证的概念
数据验证方法是指在测试过程中,对输入数据进行验证的方法。数据验证方法可以根据数据类型、数据范围、数据格式等方面来进行验证。数据验证方法的目的是确保输入数据的正确性和合法性,以避免系统出现错误或异常。
② 数据验证的方法
数据类型验证:对输入数据的数据类型进行验证,确保输入数据的类型与系统要求的类型一致。
数据范围验证:对输入数据的范围进行验证,确保输入数据的范围在系统要求的范围之内。
数据格式验证:对输入数据的格式进行验证,确保输入数据的格式符合系统要求的格式。
数据完整性验证:对输入数据进行完整性验证,确保输入数据的完整性和一致性。
数据合法性验证:对输入数据进行合法性验证,确保输入数据符合系统要求的合法性要求。
(5)数据清洗
① 数据清洗的概念
数据清洗是指在数据处理过程中,对数据进行预处理,以消除数据中的噪声、错误和不一致性,使数据更加干净和有用。
② 数据清洗的方法
- 缺失值填充:对于缺失的数据,通过插值等方法填充缺失值。
- 异常值处理:对于异常数据,通过删除或替换等方法处理异常值。
- 重复值处理:对于重复的数据,通过删除重复值等方法处理。
③ 数据清洗的工具
- OpenRefine:一款开源的数据清洗工具,可以对数据进行筛选、转换、合并等操作。
- Trifacta:一款商业化的数据清洗工具,可以自动识别数据类型,并提供交互式的数据清洗界面。
④ 数据清洗的挑战
数据质量问题:数据清洗的首要问题是数据质量。数据质量问题可能包括数据缺失、重复数据、无效数据、格式错误等。这些问题可能会影响数据分析的准确性和可靠性,因此需要花费大量时间和精力对数据进行清洗和修复。
数据量问题:现代软件系统产生的数据量非常庞大,可能涉及到数百万条数据。因此,数据清洗需要处理大量的数据。这需要使用高效的算法和技术来处理数据,以确保数据清洗的速度和准确性。
数据来源问题:数据清洗的另一个挑战是数据来源问题。数据可能来自不同的系统和平台,并且可能以不同的格式和结构存储。因此,数据清洗需要考虑不同的数据来源和格式,并采取相应的措施来处理数据。
数据保护问题:数据清洗涉及到大量的敏感数据,如个人身份信息、财务信息等。因此,数据清洗需要采取相应的措施来保护数据的安全性和隐私性,如数据加密、访问控制等。
数据可视化问题:数据清洗后,需要将数据可视化以进行分析和决策。因此,数据清洗需要考虑如何将数据可视化,并提供易于使用的界面和工具来帮助用户进行数据分析。
⑤ 数据清洗的注意事项
- 保留原始数据:在进行数据清洗时,需要注意保留原始数据,以便在需要时进行对比和验证。
数据源的质量:数据清洗的第一步是确保数据源的质量。数据源应该是可靠的,准确的,完整的,并且没有重复的数据。
数据清洗的目标:在开始数据清洗之前,需要明确数据清洗的目标。这将有助于确定哪些数据需要清洗,以及如何清洗这些数据。
数据清洗的流程:数据清洗应该是一个系统化的过程,包括数据收集,数据预处理,数据转换和数据验证。这个过程应该被记录下来,以便在以后的数据清洗中可以重复使用。
数据清洗的工具:使用适当的工具可以使数据清洗更加高效和准确。例如,可以使用Excel、Python、R等工具进行数据清洗。
数据清洗的规则:在进行数据清洗之前,需要定义数据清洗的规则。这些规则应该包括数据类型、数据格式、数据范围等。
数据清洗的验证:数据清洗后,需要进行数据验证以确保数据的准确性和完整性。可以使用数据可视化、数据统计等方式来验证数据。
数据清洗的文档:数据清洗的结果应该被记录下来,以便在以后的数据清洗中可以重复使用。这些记录应该包括数据清洗的目标、流程、规则、工具和验证结果等。
六、减少无效数据的方法
确定测试目标和需求:在测试过程中,首先需要明确测试目标和需求,这样可以避免测试过程中浪费时间和精力在不必要的测试上,这将有助于确定测试数据的类型和范围,从而减少无效数据的数量。
选择合适的测试用例:测试用例应该根据需求和目标选择,避免测试重复的用例和不必要的用例,以此来减少无效数据的数量。
使用真实数据:使用真实数据进行测试可以帮助测试人员更好地模拟实际情况,从而减少无效数据的数量。
使用随机数据生成器:在测试过程中,使用随机数据生成器可以生成大量的测试数据,这样可以模拟各种不同的情况,从而更全面地测试系统,避免手动输入或复制粘贴数据的错误和重复,以此来减少无效数据的数量。
使用数据过滤器:在测试过程中,可以使用数据过滤器来过滤掉无效数据。这样可以将注意力集中在真正有意义的数据上,从而提高测试效率。
删除重复数据:在测试过程中,可能会出现大量的重复数据。这些数据不仅浪费时间和资源,而且可能会导致测试结果不准确。因此,测试人员应该删除重复数据,以减少无效数据的数量,避免使用过多的冗余数据,可以减少测试时间和测试数据存储的空间。
定期清理无效数据:在测试过程中,应该定期清理无效数据,避免测试数据的混乱和过多占用存储空间。
七、实际案例举例
(1)医疗行业
在医疗行业中,无效数据的处理和成功管理对于确保患者的安全和治疗效果至关重要。以下是一个真实案例,展示了如何处理无效数据和成功管理数据以提高医疗保健的质量。
案例:一个医院使用电子病历系统,但发现系统中有一些无效的医疗数据,例如重复的记录,错误的数据输入等等。这些无效数据可能会导致医生做出错误的诊断和治疗决策,从而影响患者的治疗效果和安全。
解决方案:为了解决这个问题,测试团队采取了以下措施:
数据清理:测试团队对系统中的数据进行了清理,删除了重复的记录和错误的数据输入,确保系统中的数据准确无误。
数据验证:测试团队对系统中的数据进行了验证,确保每个数据都符合医疗行业的标准和规范,并且与患者的实际情况相符。
数据管理:测试团队建立了一个数据管理系统,确保所有的医疗数据都被正确地记录和管理,包括数据的存储、备份和恢复等等。
结果:通过以上措施,医院成功地处理了无效数据,并成功地管理了医疗数据,从而提高了医疗保健的质量和效率。医生可以更准确地诊断和治疗患者,患者也可以更安全和有效地接受治疗。
(2)电商行业
案例:在电商行业中,一个真实案例是关于用户输入无效地址的情况。在一个电商平台上,用户在下单时输入了无效地址,导致订单无法成功提交。该平台的测试团队在测试过程中发现了这个问题,并提出了解决方案。
解决方案:测试团队提出的解决方案是,在用户输入地址时,通过正则表达式验证地址的有效性。如果地址无效,则提示用户重新输入。此外,测试团队还建议在后台系统中增加一个地址校验模块,用于自动验证用户输入的地址是否有效。
结果: 通过测试团队的努力,该电商平台成功解决了无效地址的问题。用户在下单时,系统会自动验证地址的有效性,如果地址无效,则会提示用户重新输入。这样可以避免用户输入无效地址导致订单无法提交的问题,提高了平台的用户体验。同时,后台系统的地址校验模块也能够自动验证用户输入的地址,保证了数据的准确性和完整性。
在一个电商网站的测试过程中,我们发现一些用户在订单提交过程中使用了无效的邮政编码。这些邮政编码不仅无法被系统识别,还会导致订单无法成功提交。为了解决这个问题,我们决定在用户提交订单前对邮政编码进行验证。我们编写了一个邮政编码验证程序,可以检查用户输入的邮政编码是否有效。如果邮政编码无效,系统会提示用户重新输入。这个解决方案不仅提高了订单提交的成功率,还提高了用户体验。
电商平台的 “购物车” 功能没有成功地管理用户的多个订单,导致了用户的混乱和退货行为增多。在测试中,我们发现系统不会正确地把多个订单组成一笔订单进行管理、核算和计算,导致了用户购买了一些重复的商品,或者输入了一些数量错误的商品等。我们提出了一个解决方案,即系统可以在购物车中对订单进行分组、计算、计价并禁止用户添加重复的订单等。
购物网站忽略了无效数据输入的处理,导致了订单成交失败。在测试中,我们模拟了输入一些无效的数据(例如错误的地址、错误的电话号码等),然后发现系统没有返回错误结果或及时支持用户,这会影响到用户对网站的信任和消费。因此,我们提出了一个改进方案,可以在不同输入的情况下对无效数据进行有效处理,并返回相应的错误消息提示用户进行修改。
(3)音视频行业
案例: 在音视频行业中,一个真实案例是关于视频流的测试。在测试过程中,测试人员发现了一些无效数据,这些数据会导致视频流的质量下降。经过分析,测试人员发现这些无效数据是由于网络延迟和带宽限制引起的。为了解决这个问题,测试人员采用了一些技术手段,如数据压缩和网络优化,以确保视频流的质量。
解决方案: 为了有效处理无效数据,测试人员需要采用一些技术手段和工具。例如,他们可以使用数据分析工具来分析数据,确定哪些数据是无效的。他们还可以使用网络优化工具来优化网络,以确保数据传输的稳定性和可靠性。此外,他们还可以使用数据压缩技术来减少数据传输的带宽消耗。
结果: 通过有效处理无效数据,测试人员可以确保测试结果的准确性和可靠性。在音视频行业中,这意味着测试人员可以确保视频流的质量和稳定性。这将有助于提高用户的满意度和信任度,从而促进业务的发展和增长。