什么是Druid连接池?
Druid连接池是阿里巴巴开源的数据库连接池项目。
Druid连接池为监控而生,内置强大的监控功能,监控特性不影响性能。功能强大,能防SQL注入,内置Loging能诊断Hack应用行为。
哦,首先Druid是一个数据库连接池,第一次学,我也不知道,那么先来看看什么的数据库连接池
什么是数据库连接池?
数据库连接池(Database Connection Pooling)在程序初始化时创建一定数量的数据库连接对象并将其保存在一块内存区中,它允许应用程序重复使用一个现有的数据库连接,而不是重新建立一个;释放空闲时间超过最大空闲时间的数据库连接以避免因为没有释放数据库连接而引起的数据库连接遗漏。
即在程序初始化的时候创建一定数量的数据库连接,用完可以放回去,下一个在接着用,通过配置连接池的参数来控制连接池中的初始连接数、最小连接、最大连接、最大空闲时间这些参数保证访问数据库的数量在一定可控制的范围类,防止系统崩溃,使用户的体验好
哦,懂了,跟那个线程池似的
再来看看它是干嘛的?
刚才说道他的作用: Druid连接池为监控而生,内置强大的监控功能,监控特性不影响性能。功能强大,能防SQL注入,内置Loging能诊断Hack应用行为。
哦,懂了,监控对数据库的行为的
那他有什么意义呢?
数据库连接池的意义在于,能够重复利用数据库连接,提高对请求的响应时间和服务器的性能。
连接池中提前预先建立了多个数据库连接对象,然后将连接对象保存到连接池中,当客户请求到来时,直接从池中取出一个连接对象为客户服务,当请求完成之后,客户程序调用close()方法,将连接对象放回池中。
哦,懂了,提高了数据库连接效率(提高对请求的响应时间和服务器的性能)
那为什么就用它呢?
各产品性能指标如下:
Druid连接池在性能、监控、诊断、安全、扩展性这些方面远远超出竞品
在这里插入图片描述
哦,懂了,因为Druid它牛在这里插入图片描述
哦,那怎么用?
查了半天有人说是先要管理配置DataSource连接池对象
那先看看什么是DataSource,这个不要慌,翻译成中文就好,就是数据源(数据源就是一个数据的来源,在这相当于数据库)
说到这扩展一下什么是DataSource对象:
什么是DataSource对象?
DataSource对象是javax.sql包中的一个接口,其实就是可以标识为一个数据库连接资源,数据源对象里面应该存储连接的url,用户名和密码等连接信息。
哦,DataSource对象是个接口,放数据库连接信息的
在使用JDBC连接数据库的时候,都使用通过DriverManager进行获取Connection对象,getConnection方法都需要传递url,name.passwd等信息,其实这些信息就是可以充当一个数据源对象。
那什么是DataSource连接池呢?
翻译成中文就是数据源连接池。数据源就是一个数据的来源,相当于数据库。
但是程序去访问数据库并不直接访问,会通过一个代理,也就是数据连接池,每一个数据连接池引用的对象肯定有数据源。DataSource的实现子类有很多,其中很多第三方的连接池都是需要实现DataSource的,如果创建一个带数据池的数据源,则就有连接池功能了。
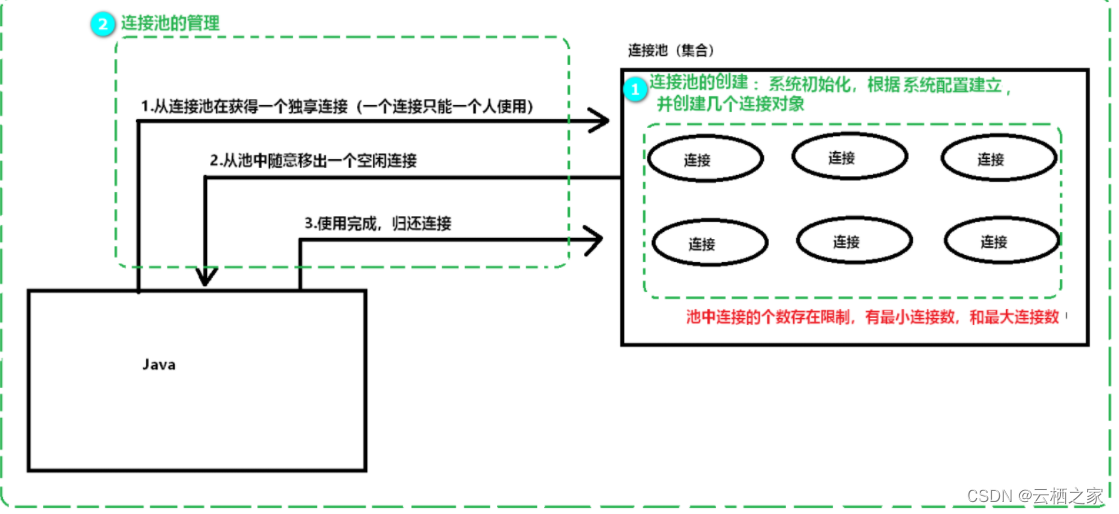
配置参数
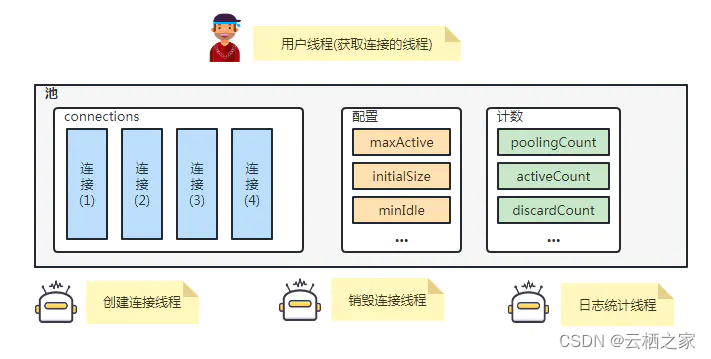
和其它连接池一样DRUID的DataSource类为:com.alibaba.druid.pool.DruidDataSource,基本配置参数如下:
配置 缺省值 说明
name 配置这个属性的意义在于,如果存在多个数据源,监控的时候可以通过名字来区分开来。
如果没有配置,将会生成一个名字,格式是:“DataSource-” + System.identityHashCode(this)
jdbcUrl 连接数据库的url,不同数据库不一样。例如:
mysql : jdbc:mysql://10.20.153.104:3306/druid2
oracle : jdbc:oracle:thin:@10.20.149.85:1521:ocnauto
username 连接数据库的用户名
password 连接数据库的密码。如果你不希望密码直接写在配置文件中,可以使用ConfigFilter。详细看这里:https://github.com/alibaba/druid/wiki/%E4%BD%BF%E7%94%A8ConfigFilter
driverClassName 根据url自动识别 这一项可配可不配,如果不配置druid会根据url自动识别dbType,然后选择相应的driverClassName(建议配置下)
initialSize 0 初始化时建立物理连接的个数。初始化发生在显示调用init方法,或者第一次getConnection时
maxActive 8 最大连接池数量
maxIdle 8 已经不再使用,配置了也没效果
minIdle 最小连接池数量
maxWait 获取连接时最大等待时间,单位毫秒。配置了maxWait之后,缺省启用公平锁,并发效率会有所下降,如果需要可以通过配置useUnfairLock属性为true使用非公平锁。
poolPreparedStatements false 是否缓存preparedStatement,也就是PSCache。PSCache对支持游标的数据库性能提升巨大,比如说oracle。在mysql下建议关闭。
maxOpenPreparedStatements -1 要启用PSCache,必须配置大于0,当大于0时,poolPreparedStatements自动触发修改为true。在Druid中,不会存在Oracle下PSCache占用内存过多的问题,可以把这个数值配置大一些,比如说100
validationQuery 用来检测连接是否有效的sql,要求是一个查询语句。如果validationQuery为null,testOnBorrow、testOnReturn、testWhileIdle都不会其作用。
testOnBorrow true 申请连接时执行validationQuery检测连接是否有效,做了这个配置会降低性能。
testOnReturn false 归还连接时执行validationQuery检测连接是否有效,做了这个配置会降低性能
testWhileIdle false 建议配置为true,不影响性能,并且保证安全性。申请连接的时候检测,如果空闲时间大于timeBetweenEvictionRunsMillis,执行validationQuery检测连接是否有效。
timeBetweenEvictionRunsMillis 有两个含义:
- Destroy线程会检测连接的间隔时间2) testWhileIdle的判断依据,详细看testWhileIdle属性的说明
numTestsPerEvictionRun 不再使用,一个DruidDataSource只支持一个EvictionRun
minEvictableIdleTimeMillis
connectionInitSqls 物理连接初始化的时候执行的sql
exceptionSorter 根据dbType自动识别 当数据库抛出一些不可恢复的异常时,抛弃连接
filters 属性类型是字符串,通过别名的方式配置扩展插件,常用的插件有:
监控统计用的filter:stat日志用的filter:log4j防御sql注入的filter:wall
proxyFilters
类型是List<com.alibaba.druid.filter.Filter>,如果同时配置了filters和proxyFilters,是组合关系,并非替换关系
使用方法
DB数据源的使用方法也就是2种,一种是在代码中写死通过NEW操作符创建DataSSource,然后set一些连接属性,这里不在累述;另外一种是基于SPRING的配置方法,然后让SPRING的Context自动加载配置(以下配置文件默认都在项目根目录下conf文件夹中)
1、属性文件:application.properties(DataSource连接参数)
jdbc.driverClassName=com.mysql.jdbc.Driver
jdbc.url=jdbc:mysql://127.0.0.1:3306/test
jdbc.username=root
jdbc.password=1qaz!QAZ
测试五步骤:
//从第三步开始;Properties prop=new Properties();//加载文件;方式一:读取文件,需要把配置文件放在项目下;//prop.load(new FileReader("druid.properties"));//方式二:位置在src下;InputStream is = Demo02连接池.class.getClassLoader().getResourceAsStream("druid.properties");prop.load(is);//System.out.println(prop);//第四步:获取连接池对象;//德罗伊连接池工厂.通过prop来创建连接池对象;因为要指定连接到哪个ip?哪个端口?哪个数据库?DataSource ds= DruidDataSourceFactory.createDataSource(prop);//第五步;Connection conn = ds.getConnection();System.out.println(conn);