import os
import re
import urllib.requestimport requestsdef getHtml(url,headers):# 代理设置proxy = urllib.request.ProxyHandler({'http': '118.190.95.26:9001'}) # 字典# 基本的urlopen不支持代理、cookie等其他Http/Https高级功能,自定义opener()opener = urllib.request.build_opener(proxy, urllib.request.HTTPHandler)urllib.request.install_opener(opener)opener.addheaders = [headers] # 列表data = urllib.request.urlopen(url).read().decode('utf-8', 'ignore')pat='"pic_url":"(.*?)"'imgUrls=re.findall(pat,data)return data,imgUrlsif __name__=='__main__':keyword='李冰冰'#quote编码keyword=urllib.request.quote(keyword)pageString='0'url='https://s.taobao.com/search?q='+keyword+'&imgfile=&commend=all&ssid=s5-e&search_type=item&sourceId&#爬取淘宝图片
news/2025/3/19 20:13:01/
相关文章
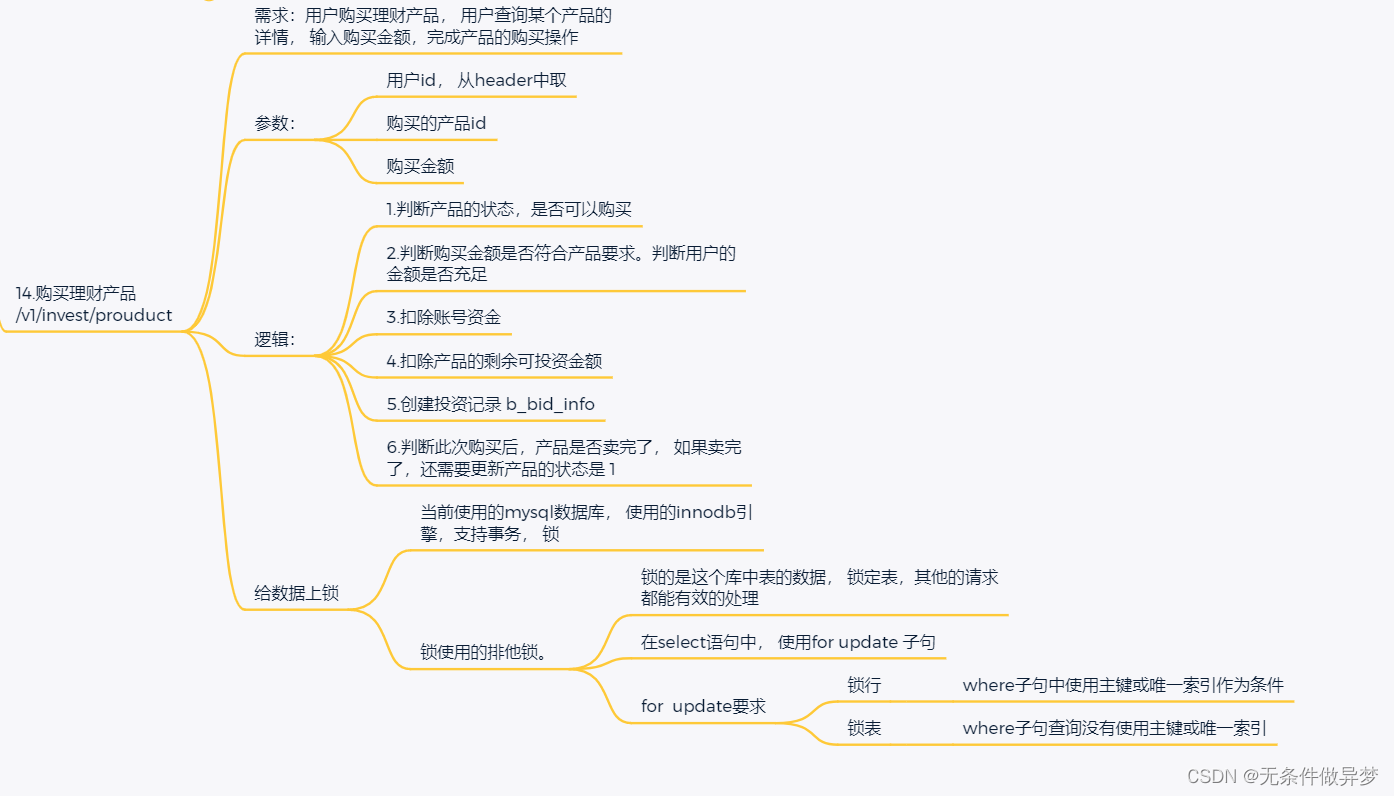
ylb-接口14购买理财产品
总览: 在api模块service包,Invest类下添加(投资理财产品, int 是投资的结果 , 1 投资成功):
package com.bjpowernode.api.service;import com.bjpowernode.api.pojo.BidInfoProduct;import j…
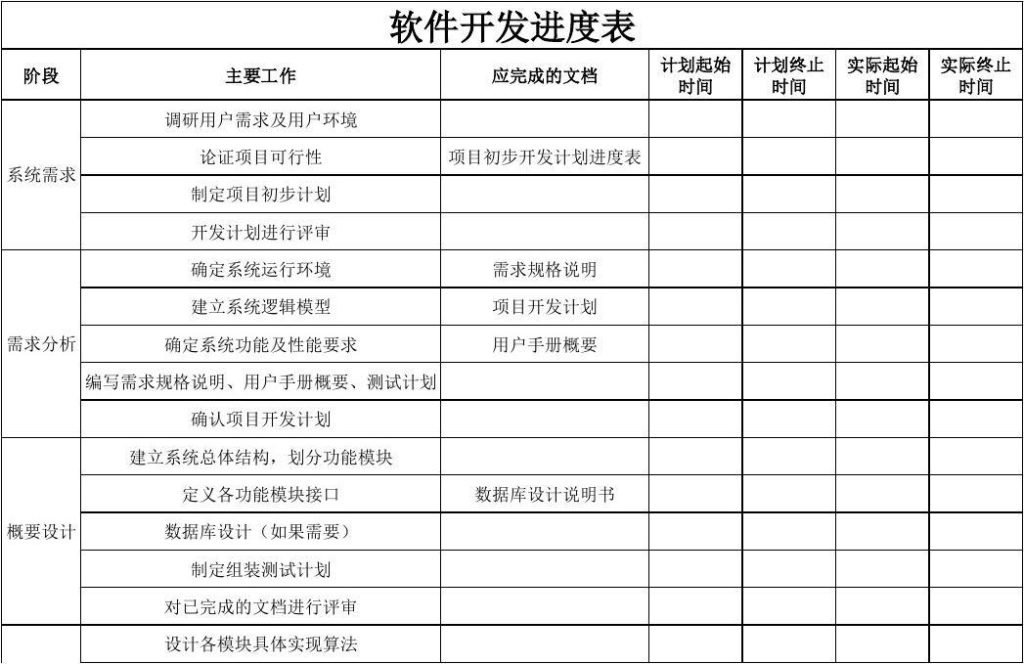
外包软件定制开发中时间和进度管理
引言
时间和进度管理是外包软件定制开发项目中至关重要的方面。有效地管理时间和进度可以确保项目按计划顺利进行,减少延误和风险,从而提高交付的可靠性和质量。然而,由于外包团队和客户位于不同的地理位置和时区,时间和进度管理…

【Pytorch神经网络实战案例】28 GitSet模型进行步态与身份识别(CASIA-B数据集)
1 CASIA-B数据集
本例使用的是预处理后的CASIA-B数据集, 数据集下载网址如下。 http://www.cbsr.ia.ac.cn/china/Gait%20Databases%20cH.asp 该数据集是一个大规模的、多视角的步态库。其中包括124个人,每个人有11个视角(0,18&am…



GPGGA \ GPRMC 格式解析
一、GPGGA格式解析 示例: $GPGGA,044744.00,3122.4658,N,12025.2791,E,1,10,3.00,12.575,M,7.100,M,00,0000*5F 解析说明:
字段0:$GPGGA,语句ID,表明该语句为Global Positioning System Fix Data(GGA&…

【论文阅读】GaitSet: Regarding Gait as a Set for Cross-View Gait Recognition
GaitSet: Regarding Gait as a Set for Cross-View Gait Recognition 摘要IntroGaitSet问题公式描述Set PoolingHorizontal Pyramid MappingMultilayer Global Pipeline 训练和测试实验 论文信息:
作者:Hanqing Chao, Yiwei He, Junping Zhang, Jianfen…