简述:
1.平时工作中,只要涉及到用户可以自由发言(博客、文档、论坛),就要考虑内容的敏感性处理,sensitive word工具是一个快速的敏感词过滤工具,基于 DFA 算法实现的高性能敏感词工具(mirrors / houbb / sensitive-word · GitCode),主要优点如下:
1.1、 6W+ 词库,且不断优化更新
1.2、 基于 DFA 算法,性能较好
1.3、 基于 fluent-api 实现,使用优雅简洁
1.4、支持敏感词的判断、返回、脱敏等常见操作
1.5 、支持全角半角互换
1.6、 支持英文大小写互换
核心API 概览:
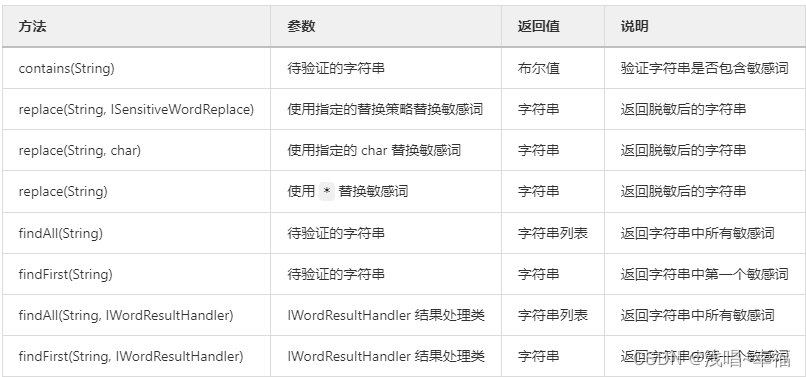
以上就是敏感词的工具类SensitiveWordHelper ,它可以对可以对敏感词的结果进行处理,允许用户自定义 ,内置实现见 WordResultHandlers 工具类:WordResultHandlers.word(),只保留敏感词单词本身:WordResultHandlers.raw(),保留敏感词相关信息,包含敏感词,开始和结束下标
Maven引入:
<dependency><groupId>com.github.houbb</groupId><artifactId>sensitive-word</artifactId><version>0.2.0</version> </dependency>
使用实例:
1、测试方法:
public class Test {public static void main(String[] args) {//是否有敏感词存在String text = "五星红旗迎风飘扬,画像屹立在天安门前。";boolean isFalse = SensitiveWordHelper.contains(text);System.out.println("是否有敏感词存在====>>>>"+isFalse);//返回所有敏感词List<String> wordList = SensitiveWordHelper.findAll(text);System.out.println("返回所有敏感词====>>>>"+wordList);//返回所有敏感词 等价于SensitiveWordHelper.findAll(text)wordList = SensitiveWordHelper.findAll(text,WordResultHandlers.word());System.out.println("返回所有敏感词====>>>>"+wordList);//返回字符串中第一个敏感词String first = SensitiveWordHelper.findFirst(text);System.out.println("返回字符串中第一个敏感词====>>>>"+first);//返回字符串中第一个敏感词 等价于SensitiveWordHelper.findFirst(text)first = SensitiveWordHelper.findFirst(text,WordResultHandlers.word());System.out.println("返回字符串中第一个敏感词====>>>>"+first);//默认的替换策略String result = SensitiveWordHelper.replace(text);System.out.println("默认的替换策略====>>>>"+result);//指定替换的内容 这里可以自定义替换内容result = SensitiveWordHelper.replace(text, '0');System.out.println("指定替换的内容====>>>>"+result);//自定义替换内容MySensitiveWordReplaceUtils mySensitiveWordReplaceUtils = new MySensitiveWordReplaceUtils();result = SensitiveWordHelper.replace(text, mySensitiveWordReplaceUtils);System.out.println("自定义替换内容====>>>>"+result);}
}
2.自定义的替换策略工具类MySensitiveWordReplaceUtils
public class MySensitiveWordReplaceUtils implements ISensitiveWordReplace {@Overridepublic String replace(ISensitiveWordReplaceContext context) {String sensitiveWord = context.sensitiveWord();// 自定义不同的敏感词替换策略,可以从数据库等地方读取if("五星红旗".equals(sensitiveWord)) {return "国家旗帜";}if("毛主席".equals(sensitiveWord)) {return "教员";}// 其他默认使用 * 代替int wordLength = context.wordLength();return CharUtil.repeat('*', wordLength);}}
自定义配置方法
1.针对各种针对各种情况的处理,如:忽略大小写、忽略半角圆角、忽略数字的写法、忽略繁简体、忽略英文的书写格式、忽略重复词、邮箱检测等一些特性默认都是开启的,有时业务需要灵活定义相关的配置特性 为了让使用更加优雅,统一使用 fluent-api 的方式定义:
SensitiveWordBs wordBs = SensitiveWordBs.newInstance().ignoreCase(true).ignoreWidth(true).ignoreNumStyle(true).ignoreChineseStyle(true).ignoreEnglishStyle(true).ignoreRepeat(true).enableNumCheck(true).enableEmailCheck(true).enableUrlCheck(true).init();
以上各项配置的说明如下:

在在一般情况下在开发中会遇到一些关于敏感词范围过大或这敏感词范围不全这种情况,这个时候就会用到敏感词的白名单与黑名单,一般可存入数据库里进行维护
白名单:
@Component
public class MyDdWordAllow implements IWordAllow {@Overridepublic List<String> allow() {List<String> list = new ArrayList<>();list.add("五星红旗");list.add("天安门");return list;}}
黑名单:
@Component
public class MyDdWordDeny implements IWordDeny {@Overridepublic List<String> deny() {List<String> list = new ArrayList<>();list.add("你好");return list;}}
接口自定义之后,当然需要指定才能生效,为了让使用更加优雅,我们设计了引导类 SensitiveWordBs,可以通过 wordDeny() 指定敏感词,wordAllow() 指定非敏感词,通过 init() 初始化敏感词字典 系统的默认配置如下:
SensitiveWordBs wordBs = SensitiveWordBs.newInstance().wordDeny(WordDenys.system()).wordAllow(WordAllows.system()).init();
备注:init() 对于敏感词 DFA 的构建是比较耗时的,一般建议在应用初始化的时候只初始化一次。而不是重复初始化!
配置多个筛选:
@Configuration
public class SpringSensitiveWordConfig {@Autowiredprivate MyDdWordAllow myDdWordAllow;@Autowiredprivate MyDdWordDeny myDdWordDeny;/*** 初始化引导类* @return 初始化引导类* @since 1.0.0*/@Beanpublic SensitiveWordBs sensitiveWordBs() {SensitiveWordBs init = SensitiveWordBs.newInstance().wordAllow(WordAllows.chains(WordAllows.system(), myDdWordAllow)).wordDeny(WordDenys.chains(WordDenys.system(), myDdWordDeny)).ignoreRepeat(false)// 各种其他配置.init();return init;}
}
以上代码中多个敏感词:WordDenys.chains() 方法,将多个实现合并为同一个 IWordDeny
多个白名单:WordAllows.chains() 方法,将多个实现合并为同一个 IWordAllow
最后测试:
写一个测试的controller层 如下:
package net.longjin.controller;import com.alibaba.fastjson.JSONObject;
import com.github.houbb.sensitive.word.bs.SensitiveWordBs;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.*;import java.util.List;/*** @Author:何志鹏* @Package:net.longjin.controller* @Project:mybatis_plus* @Date:2022/12/12 17:29* @Filename:ApiSensitiveWordController*/
@RestController
@RequestMapping("/sensitiveWord")
public class ApiSensitiveWordController {@Autowiredprivate SensitiveWordBs sensitiveWordBs;/*** 获取所有的敏感词* @param jsonObject 文本* @return 结果*/@PostMapping("/findAll")public JSONObject findAll(@RequestBody JSONObject jsonObject) {String text = jsonObject.getString("text");List<String> all = sensitiveWordBs.findAll(text);JSONObject json = new JSONObject();json.put("all",all);return json;}}
测试结果:
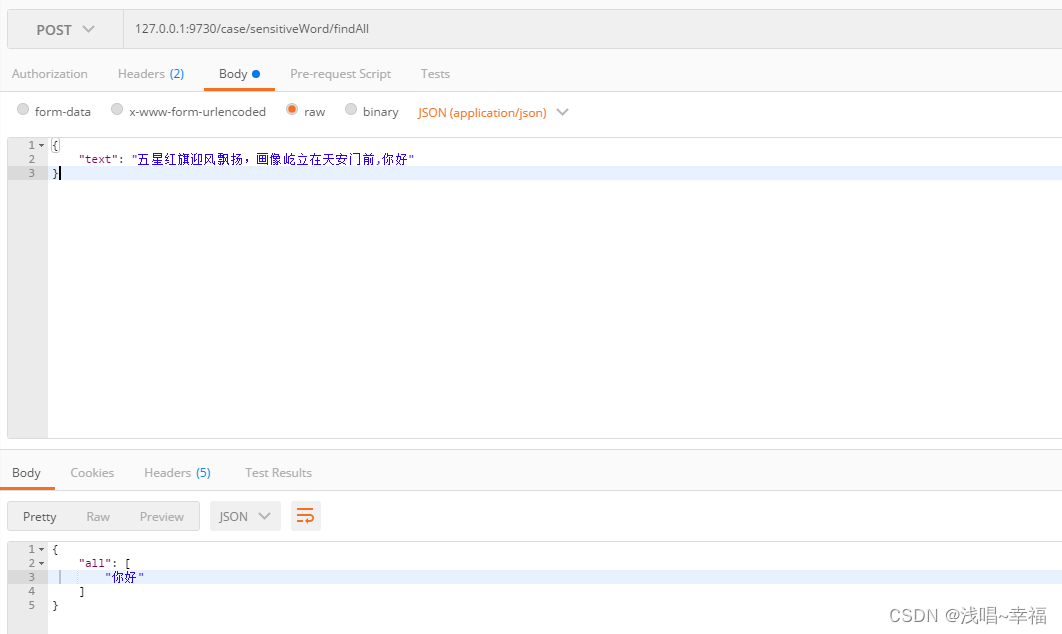
以上配置白名单和黑名单为了测试我是写的死数据 实际开发中,一般白名单和黑名单是在数据库中进行维护的 ,为了保证敏感词修改可以实时生效且保证接口的尽可能简化,此处没有新增 add/remove 的方法,而是在调用 sensitiveWordBs.init() 的时候,根据 IWordDeny+IWordAllow 重新构建敏感词库 因为初始化可能耗时较长(秒级别),所有优化为 init 未完成时不影响旧的词库功能,完成后以新的为准
package net.longjin.sensitiveWord;import com.github.houbb.sensitive.word.bs.SensitiveWordBs;
import net.longjin.config.SpringSensitiveWordConfig;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;/*** @Author:何志鹏* @Package:net.longjin.sensitiveWord* @Project:mybatis_plus* @Date:2022/12/12 17:46* @Filename:SensitiveWordService*/
@Component
public class SensitiveWordService {@Autowiredprivate SensitiveWordBs sensitiveWordBs;/*** 更新词库** 每次数据库的信息发生变化之后,首先调用更新数据库敏感词库的方法。* 如果需要生效,则调用这个方法。** 说明:重新初始化不影响旧的方法使用。初始化完成后,会以新的为准。*/public void refresh() {// 每次数据库的信息发生变化之后,首先调用更新数据库敏感词库的方法,然后调用这个方法。sensitiveWordBs.init();}}
如上,你可以在数据库词库发生变更时,需要词库生效,主动触发一次初始化 sensitiveWordBs.init();
最后附上代码:mybatis_plus: springBoot集成mybatis_plus