Table of Contents
1.Java
1.0 良心参考资料
1.1 什么是单例模式?如何实现单例模式?哪种在并发的环境中会更好?
1.2 什么是Lambda表达式?你能讲一下Lambda表达式的例子吗?
1.3 讲一下OOM
1.4.在java代码里面怎么使用mysql?
1.5.Java的深拷贝和浅拷贝
1.6 Java的NIO,讲一下多路复用?
1.7 Spring的IOC介绍
1.8 Java容器
1.9 线程和进程的区别
1.10 java线程的状态
1.11 wait()和sleep的区别
1.12 java线程间如何共享数据
1.13 介绍下threadlocal
1.14 介绍下volatile
1.15 介绍下内存可见性问题
1.16 为什么要使用线程池
1.17 线程池主要有哪些参数
1.18 线程池的原理
1.19 用过的jdk命令
1.20 虚拟机参数
1.21 SpringBoot
1.22 ConcurrentHashMap和hashtable的区别?为啥推荐用ConcurrentHashMap?
1.23 Java类的加载过程?
1.24 类加载器有哪些?双亲委派模型?
1.25 Java的反射机制?
1.26 Java的锁机制?
1.27 你能讲一下CAS?
2.数据结构
2.1 简单说一下红黑树?
2.2 十大排序算法
2.3 讲一下动态规划算法以及适用场景?
3.数据库
3.0 良心参考资料
3.1 两阶段提交?
3.2 MySQL的索引类型?为什么索引可以加快查询?
3.3 你知道Redis吗?简单讲一下?
3.4 数据库三大范式?
3.5 数据库事务的四个特性?
3.6 数据库的隔离级别和分别解决了什么问题?
3.7 数据库常见的存储引擎
3.8 索引的数据结构以及b+树细节
3.9 SQL的优化方法
3.10 MySQL和Oracle实现分页有什么不同?MySQL怎么实现分页?
4.计算机网络
4.1 三次握手四次挥手?
4.2 为啥需要三次握手?
4.3 为什么第四次挥手后要等待?
4.4 浏览器从请求url到页面显示的整个过程?
4.5 图片缓存需要用到http的什么字段?
4.6 http1.0 、http1.1、http2.0之间的区别?
4.7 简单介绍一下邮件协议?
4.8 OSI七层模型?
4.9 Http请求头的字段
1.Java
1.0 良心参考资料
https://github.com/Snailclimb/JavaGuide
1.1 什么是单例模式?如何实现单例模式?哪种在并发的环境中会更好?
参考资料:https://www.runoob.com/design-pattern/singleton-pattern.html
我只知道一种最简单的单例模式,这种模式涉及到一个单一的类,该类负责创建自己的对象,同时确保只有单个对象被创建。这个类提供了一种访问其唯一的对象的方式。
优点:
1、在内存里只有一个实例,减少了内存的开销,尤其是频繁的创建和销毁实例(比如管理学院首页页面缓存)。
2、避免对资源的多重占用(比如写文件操作)
缺点:没有接口,不能继承
单例模式的几种实现方式
1、懒汉式,线程不安全,可以通过synchronized实现线程安全。
优点:第一次调用才初始化,避免内存浪费。
缺点:必须加锁 synchronized 才能保证单例,但加锁会影响效率。
2、饿汉式,线程安全,这种方式比较常用,但容易产生垃圾对象。
优点:没有加锁,执行效率会提高。
缺点:类加载时就初始化,浪费内存。
3、双检锁/双重校验锁
这种方式采用双锁机制,安全且在多线程情况下能保持高性能。
1.2 什么是Lambda表达式?你能讲一下Lambda表达式的例子吗?
Lambda表达式也叫做闭包,它允许把函数(可以直接通过名字调用代码块)作为一个方法(写在类里面的函数)的参数传递进去,一个方法的参数,括号中是否可以使用Lambda表达式,取决于这个方法的参数类型:是否是一个函数式接口。也可以直接给一个接口类型的对象赋值,相当于实现了这个接口函数,实际也是实现且创建一个接口对象。使用Lambda表达式可以使得代码更简洁。之前用过lambda表达式的地方是重写sort函数,用lambda表达式实现Comparator接口。
// 1.1 使用匿名内部类根据 name 排序 players
Arrays.sort(players, new Comparator<String>() {@Overridepublic int compare(String s1, String s2) {return (s1.compareTo(s2));}
});
// 1.2 使用 lambda expression 排序 players
Arrays.sort(players, (String s1, String s2) -> (s1.compareTo(s2))); 1.3 讲一下OOM
OOM就是out of memory。
1) java.lang.OutOfMemoryError: Java heap space ------>java堆内存溢出,此种情况最常见,一般由于内存泄露或者堆的大小设置不当引起。对于内存泄露,需要通过内存监控软件查找程序中的泄露代码,而堆大小可以通过虚拟机参数-Xms(java程序启动时初始堆大小),-Xmx等修改。
2) java.lang.OutOfMemoryError: PermGen space ------>java永久代溢出,即方法区溢出了,一般出现于大量Class或者jsp页面,或者采用cglib等反射机制的情况,因为上述情况会产生大量的Class信息存储于方法区。此种情况可以通过更改方法区的大小来解决,使用类似-XX:PermSize=64m -XX:MaxPermSize=256m的形式修改。另外,过多的常量尤其是字符串也会导致方法区溢出。
3) java.lang.StackOverflowError ------> 不会抛OOM error,但也是比较常见的Java内存溢出。JAVA虚拟机栈溢出,一般是由于程序中存在死循环或者深度递归调用造成的,栈大小设置太小也会出现此种溢出。可以通过虚拟机参数-Xss来设置栈的大小。
1.4.在java代码里面怎么使用mysql?
简单粗暴的是使用JDBC,创建一个JDBCConnection对象,然后后创建一个Statement对象,通过statement的execute方法来直接执行SQL语句。之前在用Springboot开发的时候,直接使用了Hibernate框架,可以不用SQL语句,直接实现和数据库的交互。
1.5.Java的深拷贝和浅拷贝
参考资料:https://www.cnblogs.com/plokmju/p/7357205.html
在 Java 中,除了基本数据类型(元类型)之外,还存在 类的实例对象 这个引用数据类型。而一般使用 『 = 』号做赋值操作的时候。对于基本数据类型,实际上是拷贝的它的值,但是对于对象而言,其实赋值的只是这个对象的引用,将原对象的引用传递过去,他们实际上还是指向的同一个对象。
而浅拷贝和深拷贝就是在这个基础之上做的区分,如果在拷贝这个对象的时候,只对基本数据类型进行了拷贝,而对引用数据类型只是进行了引用的传递,而没有真实的创建一个新的对象,则认为是浅拷贝。反之,在对引用数据类型进行拷贝的时候,创建了一个新的对象,并且复制其内的成员变量,则认为是深拷贝。
1.6 Java的NIO,讲一下多路复用?
参考资料:https://juejin.im/entry/599f971af265da247d728531
NIO从字面上理解为 New IO,就是为了弥补原本 I/O 上的不足,它提供了Channel(通道),Buffer(缓冲区),Selector(选择器)几个核心组件,我们可以实现非阻塞的异步IO。
通常来说NIO中的所有IO都是从 Channel(通道) 开始的。
- 从通道进行数据读取 :创建一个缓冲区,然后请求通道读取数据。
- 从通道进行数据写入 :创建一个缓冲区,填充数据,并要求通道写入数据。
多路复用
目前流行的多路复用IO实现主要包括四种:select、poll、epoll、kqueue。多路复用是为了解决高并发的问题。1个线程可以同时发起多个 I/O 调用,并且不需要同步等待数据就绪。在数据就绪完成的时候,会以事件的机制,来通知我们。这样就实现了单线程同时处理多个 IO 调用的问题。
通道,被建立的一个应用程序和操作系统交互事件、传递内容的渠道(注意是连接到操作系统)。
缓存,在JAVA NIO 框架中,为了保证每个通道的数据读写速度JAVA NIO 框架为每一种需要支持数据读写的通道集成了Buffer的支持。
选择器,事件订阅和Channel管理,轮询代理,实现不同操作系统的支持。
实现步骤:
第一阶段:等待数据就绪;
第二阶段:将已就绪的数据从内核缓冲区拷贝到用户空间;
- 创建选择器,它能监听所有的 I/O 操作,并且以事件的方式通知我们哪些 I/O 已经就绪了。
- 创建一个非阻塞的 SocketChannel。
- 建立选择器与 socket 的关联,好让选择器和监听到 Socket 的变化。
- 选择器监听 socket 变化,nio 下的 selecotr 不会去遍历所有关联的 socket。我们在注册时设置了我们关心的事件类型,每次从选择器中获取的,只会是那些符合事件类型,并且完成就绪操作的 socket,减少了大量无效的遍历操作。
- 处理连接就绪事件。
- 处理写入就绪事件。
- 处理读取就绪事件。
1.7 Spring的IOC介绍
参考资料:https://www.cnblogs.com/liuyang0/p/6485191.html
IoC—Inversion of Control,即“控制反转”,它不是什么技术,而是一种设计思想。把创建和查找依赖对象的控制权交给了容器,由容器进行注入组合对象,所以对象与对象之间是松散耦合,这样也方便测试,利于功能复用,更重要的是使得程序的整个体系结构变得非常灵活。
1.8 Java容器
1.8.1 Hashmap底层数据结构的变化
JDK1.8 之前 HashMap 由 数组+链表 组成的,数组是 HashMap 的主体,链表则是主要为了解决哈希冲突而存在的(“拉链法”解决冲突)。JDK1.8 以后在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为 8)时,将链表转化为红黑树,以减少搜索时间。
1.8.2 红黑树的优缺点
优点是能够显著提高查找效率,缺点是维护一个红黑树需要额外的开销。
1.8.3 使用Hashmap的注意事项
Hashmap是线程不安全的,如果要线程安全可以使用hashtable和hashcurrentmap。
1.8.4 List数据结构Java中常用的实现
Java提供了一个list接口和一个ArrayList实现类,ArrayList的底层实现是一个数组,通过动态扩容的方式实现。Vector方法是同步的,线程安全。
1.8.5 Arraylist和Linkedlist的适用场景
参考资料:https://blog.csdn.net/Sherry_Rui/article/details/51068247
ArrayList是基于数组实现的,ArryList初始化时,elementData数组大小默认为10。LinkedList是基于双链表实现的。
(1)如果应用程序对各个索引位置的元素进行大量的存取或删除操作,ArrayList对象要远优于LinkedList对象;
( 2 ) 如果应用程序主要是对列表进行循环,并且循环时候进行插入或者删除操作,LinkedList对象要远优于ArrayList对象;
1.8.6 扩容机制比较
参考资料:JavaGuid
Arraylist的扩容机制:每次add()时,先调用ensureCapacity()保证数组不会溢出,如果此时已满,会扩展为数组length的1.5倍+1。
HashMap的扩容机制:HashMap 默认的初始化大小为16。之后每次扩充,容量变为原来的2倍。
HashTable的扩容机制:Hashtable 默认的初始大小为11,之后每次扩充,容量变为原来的2n+1。
1.8.7 string、stringbuffer和stringbuilder的区别
参考资料:https://blog.csdn.net/mad1989/article/details/26389541
String类是不可变类,任何对String的改变都 会引发新的String对象的生成;StringBuffer则是可变类,任何对它所指代的字符串的改变都不会产生新的对象。StringBuffer和StringBuilder类的区别也是如此,他们的原理和操作基本相同,区别在于StringBufferd支持并发操作,线性安全的,适 合多线程中使用。StringBuilder不支持并发操作,线性不安全的,不适合多线程中使用。
1.9 线程和进程的区别
参考资料:https://blog.csdn.net/mxsgoden/article/details/8821936
进程有独立的地址空间,一个进程崩溃后,在保护模式下不会对其它进程产生影响,而线程只是一个进程中的不同执行路径。线程有自己的堆栈和局部变量,但线程之间没有单独的地址空间,一个线程死掉就等于整个进程死掉,所以多进程的程序要比多线程的程序健壮,但在进程切换时,耗费资源较大,效率要差一些。但对于一些要求同时进行并且又要共享某些变量的并发操作,只能用线程,不能用进程。
1.10 java线程的状态
参考资料:https://blog.csdn.net/pange1991/article/details/53860651
1. 初始(NEW):新创建了一个线程对象,但还没有调用start()方法。
2. 运行(RUNNABLE):Java线程中将就绪(ready)和运行中(running)两种状态笼统的称为“运行”。
线程对象创建后,其他线程(比如main线程)调用了该对象的start()方法。该状态的线程位于可运行线程池中,等待被线程调度选中,获取CPU的使用权,此时处于就绪状态(ready)。就绪状态的线程在获得CPU时间片后变为运行中状态(running)。
3. 阻塞(BLOCKED):表示线程阻塞于锁。
4. 等待(WAITING):进入该状态的线程需要等待其他线程做出一些特定动作(通知或中断)。
5. 超时等待(TIMED_WAITING):该状态不同于WAITING,它可以在指定的时间后自行返回。
6. 终止(TERMINATED):表示该线程已经执行完毕。

1.11 wait()和sleep的区别
参考资料:https://blog.csdn.net/u012050154/article/details/50903326
- sleep()方法正在执行的线程主动让出CPU(然后CPU就可以去执行其他任务),在sleep指定时间后CPU再回到该线程继续往下执行(注意:sleep方法只让出了CPU,而并不会释放同步资源锁!!!);wait()方法则是指当前线程让自己暂时退让出同步资源锁,以便其他正在等待该资源的线程得到该资源进而运行,只有调用了notify()方法,之前调用wait()的线程才会解除wait状态,可以去参与竞争同步资源锁,进而得到执行。
- sleep()方法可以在任何地方使用;wait()方法则只能在同步方法或同步块中使用;
- sleep()是线程线程类(Thread)的方法,会自己醒。wait()是Object的方法,需要使用notify()进行唤醒。
##### sleep对cpu的资源
sleep方法只让出了CPU,而并不会释放同步资源锁!
1.12 java线程间如何共享数据
参考资料:https://blog.csdn.net/hejingyuan6/article/details/47053409
1,如果每个线程执行的代码相同,可以使用同一个Runnable对象,这个Runnable对象中有那个共享数据,例如,卖票系统就可以这么做。
2,如果每个线程执行的代码不同,这时候需要用不同的Runnable对象,例如,设计4个线程。其中两个线程每次对j增加1,另外两个线程对j每次减1,银行存取款。
将共享数据封装成另外一个对象,然后将这个对象逐一传递给各个Runnable对象,每个线程对共享数据的操作方法也分配到那个对象身上完成,这样容易实现针对数据进行各个操作的互斥和通信
将Runnable对象作为一个类的内部类,共享数据作为这个类的成员变量,每个线程对共享数据的操作方法也封装在外部类,以便实现对数据的各个操作的同步和互斥,作为内部类的各个Runnable对象调用外部类的这些方法。
1.13 介绍下threadlocal
参考资料:https://droidyue.com/blog/2016/03/13/learning-threadlocal-in-java/
Thread Local是一个本地线程副本变量工具类。主要用于将私有线程和该线程存放的副本对象做一个映射,各个线程之间的变量互不干扰,在高并发场景下,可以实现无状态的调用,特别适用于各个线程依赖不同的变量值完成操作的场景。
1.14 介绍下volatile
参考资料:https://www.cnblogs.com/dolphin0520/p/3920373.html
一旦一个共享变量(类的成员变量、类的静态成员变量)被volatile修饰之后,那么就具备了两层语义:
1)保证了不同线程对这个变量进行操作时的可见性,即一个线程修改了某个变量的值,这新值对其他线程来说是立即可见的。
2)禁止进行指令重排序。
3)volatile也无法保证对变量的任何操作都是原子性的。
1.15 介绍下内存可见性问题
参考资料:https://www.cnblogs.com/dolphin0520/p/3920373.html
可见性是指当多个线程访问同一个变量时,一个线程修改了这个变量的值,其他线程能够立即看得到修改的值。
1.16 为什么要使用线程池
参考资料:https://blog.csdn.net/zhangjq520/article/details/65633938
1、降低资源消耗;
2、提高响应速度;
3、提高线程的可管理性。
1.17 线程池主要有哪些参数
参考资料:https://blog.csdn.net/daiqinge/article/details/51179445
corePoolSize,初始预创建的线程数。
maxPoolSize,最大的线程数。
keepAliveTime,空闲时间。
allowCoreThreadTimeout,是否允许核心线程空闲退出,默认值为false。
queueCapacity,任务队列容量。
1.18 线程池的原理
线程池为线程生命周期开销问题和资源不足问题提供了解决方案。通过对多个任务重用线程,线程创建的开销被分摊到了多个任务上。其好处是,因为在请求到达时线程已经存在,所以无意中也消除了线程创建所带来的延迟。这样,就可以立即为请求服务,使应用程序响应更快。而且,通过适当地调整线程池中的线程数目,也就是当请求的数目超过某个阈值时,就强制其它任何新到的请求一直等待,直到获得一个线程来处理为止,从而可以防止资源不足。
1.19 用过的jdk命令
参考资料:https://blog.csdn.net/u013457382/article/details/51044853

1.20 虚拟机参数
参考资料:https://www.jianshu.com/p/605e54cc4d40
堆分配参数:
- -xx:+PrintGC 虚拟机启动后,只要遇到GC就会打印日志
- -xx:+UseSerialGC 配置串行回收器
- -xx:+PrintGCDetails gc时可以查看详细信息,包括各个区的情况
- -Xms java程序启动时初始堆大小
堆溢出处理
- 如果堆空间不足,则会抛出内存溢出的错误(Out Of Memory,OOM),这类问题如果发生在生产环境,可能会引起严重的业务中断.
- -XX:HeapDumpOnOutOfMemoryError,使用该参数可以再内存溢出时导出整个堆信息
- -XX:HeapDumpPath 设置导出堆信息的存放路径,与上面的参数配合使用
栈参数配置
-Xss 指定单个线程的最大栈空间,栈空间的大小直接决定了函数可调用的最大深度。
方法区参数配置
- 默认情况下,-XX:MaxPermSize 为64MB,如果系统运行时产生大量的类,就需要设置一个相对合适的方法区,以免永久区内存溢出的问题
- -XX:PermSize 初始化方法区大小
- -XX:MaxPermSize 方法区最大大小
直接内存参数配置
- -XX:MaxDirectMemorySize,如果不设置,默认值为最大堆空间,即-Xmx,直接内存使用达到上限时,会触发垃圾回收,如果不能有效的释放空间,也会引起系统的OOM,
- jdk1.7之后,不再关注这个参数,配不配都没什么大影响
1.21 SpringBoot
参考资料:https://juejin.im/post/5c1b9fea6fb9a049b82a6d44
Spring boot是Spring家族中的一个全新的框架,它用来简化Spring应用程序的创建和开发过程。
特性 :
1.能够快速创建基于Spring的应用程序。(简化配置)
2.能够直接使用java的main方法启动内嵌的Tomcat,Jetty服务器运行Spring boot程序,不需要部署war包文件。
3.提供约定的starter POM来简化来简化Maven配置,让Maven配置变得简单。
4.根据项目的maven依赖配置,Spring boot自动配置Spring,SpringMVC等其它开源框架。
5.提供程序的健康检查等功能。(检查内部的运行状态等)
6.基本可以完全不使用xml配置文件,采用注解配置。(或者默认约定的配置,代码中已经实现)
1.22 ConcurrentHashMap和hashtable的区别?为啥推荐用ConcurrentHashMap?
参考资料:点我
Hashtable(同一把锁),使用 synchronized 来保证线程安全。
ConcurrentHashMap(分段锁) 对整个桶数组进行了分割分段(Segment),每一把锁只锁容器其中一部分数据,到了 JDK1.8 的时候已经摒弃了Segment的概念,而是直接用 Node 数组+链表+红黑树的数据结构来实现,并发控制使用 synchronized 和 CAS 来操作。



1.23 Java类的加载过程?
参考资料:点我
加载:1)加载二进制流 2)将静态数据变为运行时方法区的数据 3)在内存中创建一个对象,作为方法区的数据访问入口。
验证:文件格式,字节码,元数据,符号引用。
准备:准备阶段是正式为类变量分配内存并设置类变量初始值。
解析:将常量池内的符号引用替换为直接引用的过程。
初始化:执行类构造器 <clinit> ()方法的过程。
1.24 类加载器有哪些?双亲委派模型?
参考资料:点我
JVM 中内置了三个重要的 ClassLoader,除了 BootstrapClassLoader 其他类加载器均由 Java 实现且全部继承自java.lang.ClassLoader:
- BootstrapClassLoader(启动类加载器) :最顶层的加载类,由C++实现,负责加载
%JAVA_HOME%/lib目录下的jar包和类或者或被-Xbootclasspath参数指定的路径中的所有类。 - ExtensionClassLoader(扩展类加载器) :主要负责加载目录
%JRE_HOME%/lib/ext目录下的jar包和类,或被java.ext.dirs系统变量所指定的路径下的jar包。 - AppClassLoader(应用程序类加载器) :面向我们用户的加载器,负责加载当前应用classpath下的所有jar包和类。
1.25 Java的反射机制?
参考资料:https://baijiahao.baidu.com/s?id=1619748187138646880&wfr=spider&for=pc
Java反射说的是在运行状态中,对于任何一个类,我们都能够知道这个类有哪些方法和属性。对于任何一个对象,我们都能够对它的方法和属性进行调用。我们把这种动态获取对象信息和调用对象方法的功能称之为反射机制。反射其实是获取类的字节码文件,也就是.class文件,那么我们就可以通过Class这个对象进行获取。
getClass()方法,Class.forName()方法。
1.26 Java的锁机制?
参考资料:https://www.cnblogs.com/takumicx/p/9338983.html
相同点:
-
1.ReentrantLock和synchronized都是独占锁,只允许线程互斥的访问临界区。但是实现上两者不同:synchronized加锁解锁的过程是隐式的,用户不用手动操作,优点是操作简单,但显得不够灵活。一般并发场景使用synchronized的就够了;ReentrantLock需要手动加锁和解锁,且解锁的操作尽量要放在finally代码块中,保证线程正确释放锁。ReentrantLock操作较为复杂,但是因为可以手动控制加锁和解锁过程,在复杂的并发场景中能派上用场。
-
2.ReentrantLock和synchronized都是可重入的(点我)。synchronized因为可重入因此可以放在被递归执行的方法上,且不用担心线程最后能否正确释放锁;而ReentrantLock在重入时要却确保重复获取锁的次数必须和重复释放锁的次数一样,否则可能导致其他线程无法获得该锁。
不同点:
- ReentrantLock可以实现公平锁。公平锁是指当锁可用时,在锁上等待时间最长的线程将获得锁的使用权。
-
ReentrantLock可响应中断。而ReentrantLock给我们提供了一个可以响应中断的获取锁的方法
lockInterruptibly()。该方法可以用来解决死锁问题。
1.27 你能讲一下CAS?
参考资料:https://www.cnblogs.com/barrywxx/p/8487444.html
CAS,compare and swap的缩写,中文翻译成比较并交换。CAS 操作包含三个操作数 —— 内存位置(V)、预期原值(A)和新值(B)。 如果内存位置的值与预期原值相匹配,那么处理器会自动将该位置值更新为新值 。否则,处理器不做任何操作。
2.数据结构
2.1 简单说一下红黑树?
参考资料:https://mp.weixin.qq.com/s/MSB-vFGqNWB26kPydBJQmQ
三句话:两头黑,路同黑,红叶黑。
红黑树是一种平衡二叉树的实现,它定义如下:
1. 节点是红色或者黑色
2. 根节点是黑色
3. 每个叶子的节点都是黑色的空节点(NULL)
4. 每个红色节点的两个子节点都是黑色的。
5. 从任意节点到其每个叶子的所有路径都包含相同的黑色节点
2.2 十大排序算法
参考资料:https://mp.weixin.qq.com/s/vn3KiV-ez79FmbZ36SX9lg
稳定:基归插泡
性能:选择一直坏,堆归好坏平,桶计好线性。
2.3 讲一下动态规划算法以及适用场景?
参考资料:https://github.com/selfboot/LeetCode/tree/master/DynamicProgramming
动态规划就是:将一个问题拆成几个子问题,分别求解这些子问题,即可推断出大问题的解。动态规划会将子问题的结果存起来,这样可以以空间换时间,提高时间效率。
能使用动态规划,需要满足以下特点:
- 最优化的子结构属性。如果一个问题的最优解包含在一系列的子问题集的最优解,那么它就称为具有最优化的子结构属性。
- 重叠的子问题集。当一个递归算法再次访问同一个问题时,这种事会出现一遍又一遍。
2.4 你能简单讲一下回溯算法么?
回溯的本质是利用递归实现多重循环的遍历逻辑,在具体实现上可以是循环里面套递归或者是递归里面套递归。递归的本质也是一种循环遍历,递归跟普通的循环相比,可以实现更为复杂的跳出循环条件控制,因此应用范围会更广,而且递归的循环是隐式的,所以代码实现会比较简洁。
3.数据库
3.0 良心参考资料
1)Gitbub
2)牛客网
3) MySQL
3.1 两阶段提交?
参考资料:https://cloud.tencent.com/developer/article/1334942
在计算机网络以及数据库领域内,为了使基于分布式系统架构下的所有节点在进行事务提交时保持一致性而设计的一种算法(Algorithm)。第一阶段:准备阶段(投票阶段)和第二阶段:提交阶段(执行阶段)。
准备阶段:事务协调者(事务管理器)给每个参与者(资源管理器)发送Prepare消息,每个参与者要么直接返回失败(如权限验证失败),要么在本地执行事务,写本地的redo和undo日志,但不提交。
提交阶段:如果协调者收到了参与者的失败消息或者超时,直接给每个参与者发送回滚(Rollback)消息;否则,发送提交(Commit)消息;参与者根据协调者的指令执行提交或者回滚操作,释放所有事务处理过程中使用的锁资源。
3.2 MySQL的索引类型?为什么索引可以加快查询?
参考资料:https://blog.csdn.net/u012048106/article/details/11895219
参考资料:https://blog.csdn.net/qq_15037231/article/details/80539964
mysql里目前只支持4种索引分别是:full-text,b-tree,hash,r-tree。
b-tree索引应该是mysql里最广泛的索引的了,除了archive基本所有的存储引擎都支持它。
r树:R-tree是B-tree向多维空间发展的另一种形式,它将空间对象按范围划分。
DB在执行一条Sql语句的时候,默认的方式是根据搜索条件进行全表扫描,遇到匹配条件的就加入搜索结果集合。如果我们对某一字段增加索引,查询时就会先去索引列表中一次定位到特定值的行数,大大减少遍历匹配的行数,所以能明显增加查询的速度。
3.3 你知道Redis吗?简单讲一下?
参考资料:https://snailclimb.top/JavaGuide/#/database/Redis/Redis
Redis的默认端口号是:6379
简单来说 redis 就是一个非关系型数据库, redis 的数据是存在内存中的,所以读写速度非常快,因此 redis 被广泛应用于缓存方向。它可以实现高性能和高并发。redis 内部使用文件事件处理器 file event handler,这个文件事件处理器是单线程的,所以 redis 才叫做单线程的模型。它采用 IO 多路复用机制同时监听多个 socket,根据 socket 上的事件来选择对应的事件处理器进行处理。
3.4 数据库三大范式?
参考资料:https://www.jianshu.com/p/0355d9e5ba0e
第一范式:属性不可分割
第二范式:没有部分依赖,不依赖于联合主键的部分主属性。
第三范式:没有传递依赖,非主键之间不应该有依赖关系。
BC范式:所有的属性只依赖于主属性。
3.5 数据库事务的四个特性?
参考资料:https://blog.csdn.net/chenchaofuck1/article/details/51155344
原子性:一个事务要么全部执行成功,要么不执行成功。
一致性:事务执行的结果必须是使数据库从一个一致性状态变到另一个一致性状态。因此当数据库只包含成功事务提交的结果时,就说数据库处于一致性状态。
隔离性:不同的事务直接不能相互干扰。
持久性:一旦事务提交,这种改变应该是持久的,不能回滚。
3.6 数据库的隔离级别和分别解决了什么问题?
参考资料:https://www.cnblogs.com/zhoujinyi/p/3437475.html

3.7 数据库常见的存储引擎
参考资料:https://juejin.im/post/587ec052128fe100570a34ee
mysql5.5之前默认存储引擎是MyISAM,5.5之后改为InnoDB。它不支持事务,也不支持外键,其优势是访问的速度快。
3.8 索引的数据结构以及b+树细节
参考资料:https://www.iteye.com/blog/uule-2429508
常见的索引的数据结构有:Hash表,全文索引,B树,B+树,R树。

综合起来,B+树比B-树优势有三个:
1、IO次数更少
2、查询性能稳定
3、范围查询简便。
MyISAM和InnoDB都是基于B+树实现索引,但具体实现有区别,可以参考这篇文章。
3.9 SQL的优化方法
参考资料:https://www.jianshu.com/p/dac715a88b44
1. SQL语句中IN包含的值不应过多,对于连续的数值,能用 between 就不要用 in 了。
2. 避免在where子句中对字段进行表达式操作,对字段进行 null 值判断。
3.尽量用union all代替union。
4. 应该尽量把字段设置为NOT NULL,这样在将来执行查询的时候,数据库不用去比较NULL值。
5.使用联合(UNION)来代替手动创建的临时表。
6.优化的查询语句:
1)首先,最好是在相同类型的字段间进行比较的操作。
2)其次,在建有索引的字段上尽量不要使用函数进行操作。
3)第三,在搜索字符型字段时,我们有时会使用LIKE关键字和通配符,这种做法虽然简单,但却也是以牺牲系统性能为代价的
3.10 MySQL和Oracle实现分页有什么不同?MySQL怎么实现分页?
参考资料:https://blog.csdn.net/tianxiezuomaikong/article/details/60467462
MySQL通过一个Limit关键字直接实现分页查询,Oracle需要使用ROWNUM关键字,进行查询行的限制。
4.计算机网络
4.1 三次握手四次挥手?
参考资料:https://blog.csdn.net/qzcsu/article/details/72861891
三次握手的过程:
1. 客户端向服务器发出连接请求报文,此时,TCP客户端进程进入了 SYN-SENT(同步已发送状态)状态。
2. TCP服务器收到请求报文后,如果同意连接,则发出确认报文。此时,TCP服务器进程进入了SYN-RCVD(同步收到)状态。
3. TCP客户进程收到确认后,还要向服务器给出确认。此时,TCP连接建立,客户端进入ESTABLISHED(已建立连接)状态。
4. 当服务器收到客户端的确认后也进入ESTABLISHED状态,此后双方就可以开始通信了。
四次挥手的过程:
1. 客户端进程发出连接释放报文,并且停止发送数据。此时,客户端进入FIN-WAIT-1(终止等待1)状态。
2. 服务器收到连接释放报文,发出确认报文,此时,服务端就进入了CLOSE-WAIT(关闭等待)状态。这时候处于半关闭状态,即客户端已经没有数据要发送了,但是服务器若发送数据,客户端依然要接受。这个状态还要持续一段时间,也就是整个CLOSE-WAIT状态持续的时间。
3. 客户端收到服务器的确认请求后,此时,客户端就进入FIN-WAIT-2(终止等待2)状态,等待服务器发送连接释放报文。
4. 服务器将最后的数据发送完毕后,就向客户端发送连接释放报文,此时,服务器就进入了LAST-ACK(最后确认)状态,等待客户端的确认。
5. 服务器只要收到了客户端发出的确认,立即进入CLOSED状态。同样,撤销TCB后,就结束了这次的TCP连接。
4.2 为啥需要三次握手?
主要防止已经失效的连接请求报文突然又传送到了服务器,从而产生错误。
4.3 为什么第四次挥手后要等待?
1. 保证客户端发送的最后一个ACK报文能够到达服务器,因为这个ACK报文可能丢失。
2. 防止类似与“三次握手”中提到了的“已经失效的连接请求报文段”出现在本连接中。
4.4 浏览器从请求url到页面显示的整个过程?
参考资料:https://zhuanlan.zhihu.com/p/23155051
1)浏览器查找域名对应的IP地址。
- Response:Last-Modified
- Request:If-Modified-Since
2)浏览器根据 IP 地址与服务器建立 socket 连接。(三次握手)
3)浏览器与服务器通信: 浏览器请求,服务器处理请求,服务器返回相应的数据的过程。浏览器还接收 HTML 文件时便开始渲染、显示网页。
4)浏览器与服务器断开连接。(四次挥手)
4.5 图片缓存需要用到http的什么字段?
参考资料:https://www.cnblogs.com/vajoy/p/5341664.html
Expires字段声明了一个网页或URL地址不再被浏览器缓存的时间,一旦超过了这个时间,浏览器都应该联系原始服务器。
Cache-Control
If-Match
If-None-Match
Last-Modified
4.6 http1.0 、http1.1、http2.0之间的区别?
参考资料:https://juejin.im/entry/5981c5df518825359a2b9476
HTTP1.0和HTTP1.1的一些区别:
- 缓存处理,控制字段更多。
- 带宽优化及网络连接的使用,HTTP1.1则在请求头引入了range头域,它允许只请求资源的某个部分。
- 在HTTP1.1中新增了24个错误状态响应码。
- HTTP1.1的请求消息和响应消息都应支持Host头域。
- HTTP 1.1支持长连接(PersistentConnection)和请求的流水线(Pipelining)处理。在HTTP1.1中默认开启Connection: keep-alive。
HTTP2.0和HTTP1.X相比的新特性
- 新的二进制格式。
- 多路复用。
- header压缩。
- 服务端推送。
HTTP2.0的多路复用和HTTP1.X中的长连接复用有什么区别?
HTTP/1.1 Pipeling解决方式为,若干个请求排队串行化单线程处理。
HTTP/2多个请求可同时在一个连接上并行执行。
4.7 简单介绍一下邮件协议?
参考资料:https://blog.csdn.net/kavensu/article/details/8085409
POP3:POP3是Post Office Protocol 3的简称,即邮局协议的第3个版本,是TCP/IP协议族中的一员(默认端口是110)。本协议主要用于支持使用客户端远程管理在服务器上的电子邮件。
IMAP:IMAP全称是Internet Mail Access Protocol,即交互式邮件访问协议,是一个应用层协议(端口是143)。用来从本地邮件客户端(Outlook Express、Foxmail、Mozilla Thunderbird等)访问远程服务器上的邮件。
SMTP:SMTP的全称是“Simple Mail Transfer Protocol”,即简单邮件传输协议(25号端口)。它是一组用于从源地址到目的地址传输邮件的规范,通过它来控制邮件的中转方式。SMTP 协议属于 TCP/IP 协议簇,它帮助每台计算机在发送或中转信件时找到下一个目的地。
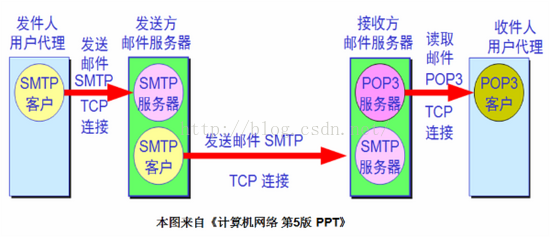
4.8 OSI七层模型?
应用层: HTTP FTP TFTP SMTP SNMP DNS TELNET HTTPS POP3 DHCP
表示层,会话层,
传输层,TCP UDP
网络层,ICMP IGMP IP(IPV4 IPV6) ARP RARP
数据链路层,
物理层。
4.9 Http请求头的字段
参考资料:https://blog.csdn.net/melody_day/article/details/53559054
Connection:表示是否需要持久连接。
Cookie:设置cookie,这是最重要的请求头信息之一
Host:初始URL中的主机和端口。
Accept-Encoding:浏览器能够进行解码的数据编码方式,比如gzip。
Accept-Language:浏览器所希望的语言种类,当服务器能够提供一种以上的语言版本时要用到。