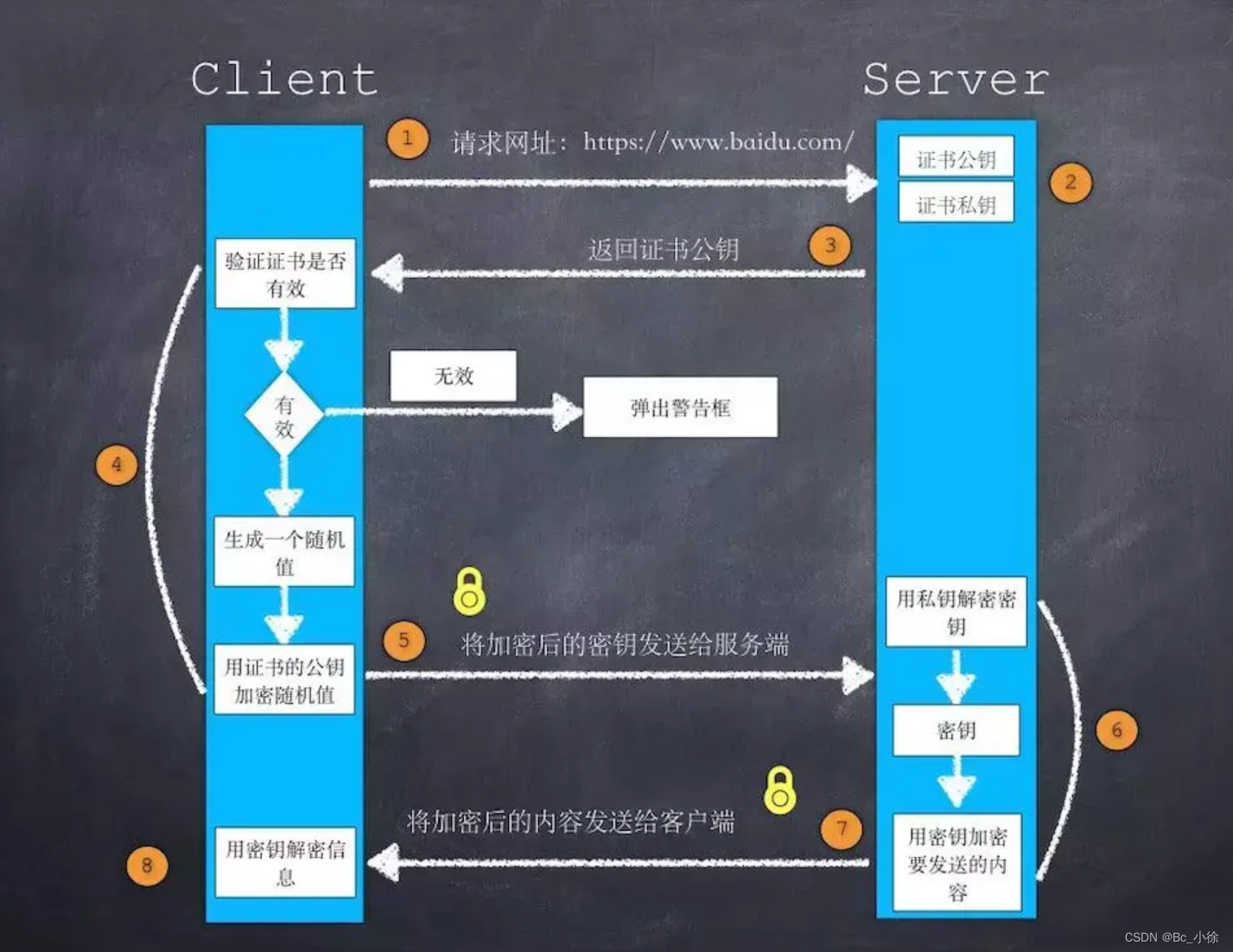
这篇文章梳理一下Bits, Bytes and Integers——二进制unsigned以及Two-complement表示,十六进制这些事儿。
计算机中所有数据都是用二进制的0和1组成的,直接上知识点。
二进制
Unsigned以及Two-complement
同样的一串二进制数,按照有符号或者无符号两种不同的方式解析,就会得到不同的值,但是这个二进制数本身是不变的。unsigned的就是无符号的解析,而two-complement则是有符号解析中最常用的一种。
unsigned

unsigned其实就是最传统的二进制和十进制直接的转换对应啦,直接按位加,算就完事。
举个例子:对于10110,根据1在的位置,可以知道三个1的值分别为16+4+2=22。
对于一个N位的unsigned二进制数,它的二进制表示可以从00…00到11…11,也就是说可以表示的范围是:0~2^N-1。
signed(Two-complement)
Two-complement是解释有符号数的常用解释办法。在2’s complement表示中,最左边的一位为符号位,为1就是负数,为0就是正数。而让这个数为负数的手段就是这个符号位也参与计算,让它以一个最高位的负权重来让整个结果变成负数。
举个例子:同样对于10110,它的值为-16+4+2=-10。因为这个时候最左边的那一位变成负数了。
在two’s complement representation中,正数左边一定有0填充,比如32 = 0100000,而不是100000,否则就变成负数了。
如何根据32的二进制表示知道-32的呢?公式:-x = ~x + 1
- 首先,我们知道unsigned下32为100000;
- 然后我们左边加一个0,这不会影响大小,但是给了一个符号位,从而方便后续操作,此时得到了0100000;
- 反转所有的位:1011111,再+1,得1100000就是我们要的-32。
问题来了,这个1100000也才7位啊,正常计算机里如果是int类型是32位,long类型是64位,那如何表示-32呢?很简单,补1即可(下面会讲到,扩充符号位值不变),int类型的-32位11111111 11111111 11111111 11100000。这就是Two-complement表示负数的奇妙之处,就算左边疯狂+1,最终结果加和依然不会变,不信你可以自己加一下看看。
关于Two-complement的范围,因为最左边的一位要拿来当作符号位,正数时左边要位0,因此整体范围要少一半。对于N位的二进制数,范围是:-2^(N-1)~2^(N-1)-1。
UMin,UMax,TMin,TMax
UMin是unsigned下的最小,其实就是0;UMax则因为全是1,变成2的N次方-1。
TMin是Two’s Complement下的最小,第一位是1(负数),其他全是0,即-2的N-1次方;
TMax第一位是0(正数),其他全是1,所以值是2的N-1次方-1。

上面的例子是N=16时的情况贴出来方便你理解,重点应关注各种对应的二进制表示。
这里补充一个特殊案例:-TMin还是TMin。首先你很轻易知道-TMin超过了Two-complement的表示范围,因为”-2的N-1次方到2的N-1次方-1“这个范围是不对称的。但具体原因我们可以按步骤算一下:

最后一行就是-x的二进制表示,可以发现依然是TMin。
unsigned和signed两者之间类型转换
如果一个表达式中unsigned与signed混合,signed会隐式转换为unsigned,再进行表达式的计算。在C语言中,(unsigned)a就是把a转为无符号,(int)a就是转为有符号。那么此时表达式:
-1 > 0U,是True还是False呢?应该是True。注意:这里U是unsigned类型。
用下面这个图来解释一下这个例子:首先-1转为unsigned类型,其二进制不变,数值变为了15,unsigned的15再和unsigned的0比较,所以是大于号。

下面也是一些其他例子和结论关系,帮助你理解这个隐式类型转换。总之就是首先我们看有没有unsigned的,有的话就全转为unsigned的去处理,再比较大小。如果都是signed的话就直接比较即可。

Extension(扩展)和Truncation(截断)
扩展extension其实就是给一个数字更多的空间,这个很简单,不影响原数大小的情况下扩充位,就是直接在左边补符号位即可。
下面的例子中,本来x是short int类型,有2个字节,经过转为4个字节的int类型后,二进制表示就在左边补充了两个字节的符号位。

截断truncation更简单,直接把左边多余不要的位砍掉即可。然后根据结果reinterpreted重新解释。不管是那种类型,都这么干,如下图:

所以truncation的结果是不稳定的,比如对于sign类型的数据之前还是正数,但因为去掉了左边的一些部分,导致新的第一个符号位变成了1,那就直接变成负数了。
十六进制

十六进制的特点其实就是每一位的范围有16个选择,即0-15,只不过10往后用字母表示了。对于16进制我觉得一个比较重要的点是知道和二进制之间的快速转换。这里我们不需要通过十进制来当中间的过程,只要知道16进制中的一位对应半个字节,也就是4比特。即二进制中的每4位就可以转换成16进制中的一位。如:
0xCAFE = 1100(C) 1010(A) 1111(F) 1110(E)
通过这种方式我们可以快速地实现二进制和十六进制之间的转换。
对于十六进制其他没什么好说的,从十六进制计算十进制也和从二进制计算十进制差不多,只不过从右往左每一位权重是16的0次方,16的1次方,16的二次方……
最后提一下位运算
非常基础的部分,就放在最后说吧,主要是&和&&,|和||的,~和!的区别值得说一下。
首先对于&, |, ~ 以及^,他们是针对二进制中的逐个比特0和1直接的计算的的。


而对于&&,||以及!,它们针对的是布尔值True或False,返回值也只能是True(1)或False(0)。当我们对这些符号使用具体数据时,会涉及到自动转换:0会变成False,一切非0会变成True。来一个例子: !!3 = 1。 为什么呢?因为3不是0,就是True,则!3=False , !!3就是True了。
左移和右移
首先你得知道左移n位会将原数字乘以2的n次方,右移n位则是缩小2的n次方。
对于unsigned的类型:不管是左移右移都是补0。
对于signed类型:对于左移操作,基本就是直接在右边补0; 但对于右移,分为逻辑右移(左边补0)和算术右移(左边补符号位),算数右移主要是为了负数(最左边符号位位1)的符号不变,如果是正数的话,两种右移都是一样的。 一般来说,右移补符号位是最常用的。

最后来一个思考:
为什么我们用two's-complement去代表signed类型数据呢?相比其他表示方法,这种representation好在哪里?原因如下:
Other representations of signed integers (ones-complement and sign-and-magnitude) have two representations of zero (+0 and −0), which makes testing for a zero result more difficult. Also, addition and subtraction of two’s complement signed numbers are done exactly the same as addition and subtraction of unsigned numbers (with wraparound on overflow), which means a CPU can use the same hardware and machine instructions for both.
简单来说使用two's-complement能让我们计算机不用管数据实际是啥类型,对于给定的二进制该加的加,该减的减,最终都能得到正确结果。
最后的最后,附一套带答案的cmu官方练习题链接http://www.cs.cmu.edu/afs/cs/academic/class/15213-m23/www/activities/bits-and-bytes-soln.pdf作为补充,方便你加深理解。