摘要
语音克隆是个性化语音接口非常需要的功能。我们介绍了一个神经语音克隆系统,该系统仅从少数音频样本中学习合成一个人的声音。我们研究了两种方法:说话人适应和说话人编码。说话人自适应是基于多说话人生成模型的微调。说话人编码是基于训练一个单独的模型来直接推断一个新的说话人嵌入,这将被应用到一个多说话人生成模型中。从语音的自然度和与原始说话人的相似度来看,这两种方法都可以获得很好的性能,即使有一些克隆音频。2 虽然说话人自适应可以实现稍好的自然度和相似度,但说话人编码方法的克隆时间和所需内存明显更少,这使得它更有利于低资源部署。
介绍
基于深度神经网络的生成模型已经成功应用于许多领域,如图像生成[例如,Oord等人,2016b, Karras等人,2017]、语音合成[例如,Oord等人,2016a, Arik等人,2017a, Wang等人,2017]和语言建模[例如,Jozefowicz等人,2016]。深度神经网络能够对复杂的数据分布进行建模,并且可以进一步以外部输入为条件来控制生成样本的内容和风格。
在语音合成中,生成模型可以以文本和说话者身份为条件[例如,Arik等人,2017b]。虽然文本携带语言信息并控制生成语音的内容,但说话者身份捕获音高、语速和口音等特征。多说话人语音合成的一种方法是在文本、音频和说话人身份的三元组上共同训练生成模型和说话人嵌入[例如,Ping等人,2018]。其思路是用低维嵌入对讲话者相关信息进行编码,同时在所有讲话者之间共享大部分模型参数。这种方法的一个限制是,它们只能在训练期间为观察到的说话人生成语音。一个有趣的任务是从几个语音样本中学习一个看不见的说话者的声音,也就是语音克隆,这对应于以说话者身份为条件的语音的几次生成建模。虽然生成模型可以用大量的音频样本3从头开始训练,但我们关注的是用几分钟甚至几秒钟的数据来克隆一个新说话人的语音。这是具有挑战性的,因为模型必须从非常有限的数据中学习说话人的特征,并且仍然可以推广到看不见的文本。
在本文中,我们研究了序列到序列神经语音合成系统中的语音克隆[Ping et al., 2018]。我们的贡献如下:
1.我们展示并分析了语音克隆的说话人自适应方法的强度,基于使用几个样本对未见说话人的预训练多说话人模型进行微调。
2.我们提出了一种新颖的说话人编码方法,该方法在主观评价中提供了可比性和相似性,同时显著减少了克隆时间和计算资源需求。
3.我们提出了基于神经说话人分类和说话人验证的语音克隆自动评价方法。
4.我们通过嵌入操作演示了性别和口音转换的语音变形。
相关工作
我们的工作建立在最先进的神经语音合成和少量生成建模的基础上。
神经语音合成:最近,人们对使用神经网络进行语音合成的兴趣激增,包括Deep Voice 1 [Arik等人,2017a], Deep Voice 2 [Arik等人,2017b], Deep Voice 3 [Ping等人,2018],WaveNet [Oord等人,2016a], SampleRNN [Mehri等人,2016],Char2Wav [Sotelo等人,2017],Tacotron [Wang等人,2017]和VoiceLoop [Taigman等人,2018]。在这些方法中,具有注意机制的序列到序列模型[Ping等人,2018,Wang等人,2017,Sotelo等人,2017]具有更简单的管道,可以产生更自然的语音[例如,Shen等人,2017]。在这项工作中,我们使用Deep Voice 3作为基线多说话人模型,因为它具有简单的卷积架构和高效的训练效率和快速的模型自适应。需要注意的是,我们的技术可以无缝地应用到其他神经语音合成模型中。
few-shot生成建模:人类可以仅从几个例子中学习新的生成任务,这激发了对few-shot生成模型的研究。早期的研究主要集中在贝叶斯方法上。例如,层次贝叶斯模型被用于挖掘字符的组合性和因果关系[Lake et al., 2013, 2015]和语音中的单词[Lake et al., 2014]。最近,深度神经网络在少镜头密度估计和条件图像生成方面取得了巨大的成功[例如,Rezende等人,2016年,Reed等人,2017年,Azadi等人,2017年],因为它们在学习表征中具有巨大的组合潜力。在这项工作中,我们研究了以特定说话者为条件的语音的少镜头生成建模。我们训练了一个单独的说话人编码网络,通过仅将未订阅的音频样本作为输入来直接预测多说话人生成模型的参数。
讲话者相关语音处理:讲话者相关建模已被广泛研究用于自动语音识别(ASR),其目标是通过利用讲话者特征来提高性能。特别是,在神经ASR中有两组方法,与我们的两种语音克隆方法一致。第一组是针对整个模型(Yu et al., 2013)、模型的一部分(Miao and Metze, 2015, Cui et al., 2017)或仅仅针对一个说话人嵌入(Abdel-Hamid and Jiang, 2013, Xue et al., 2014)的说话人自适应。语音克隆的说话人适应与这些方法是相同的,但当考虑文本到语音与语音到文本时,差异就出现了[Yamagishi等人,2009]。第二组是基于与嵌入联合训练ASR模型。嵌入的提取可以基于i-vector [Miao et al., 2015],或者基于分类损失训练的神经网络的瓶颈层[Li and Wu, 2015]。虽然说话人编码的一般思路也是基于直接提取嵌入,但作为一个主要区别,我们的说话人编码器模型是用与语音合成直接相关的目标函数来训练的。最后,依赖于说话人的建模对于多说话人语音合成是必不可少的。使用i向量来表示说话人相关特征是一种方法[Wu等人,2015],然而,它们具有单独训练的局限性,其目标与语音合成没有直接关系。此外,在少量音频的情况下,它们可能无法被准确提取[Miao et al., 2015]。多扬声器语音合成的另一种方法是使用可训练的扬声器嵌入[Arik等人,2017b],这些嵌入是随机初始化的,并从生成损失函数中进行联合优化。
语音转换:语音克隆的一个密切相关的任务是语音转换。语音转换的目标是在保持语言内容不变的情况下,修改源说话人的话语,使其听起来像目标说话人。与语音克隆不同,语音转换系统不需要泛化到看不见的文本。一种常见的方法是动态频率翘曲,以对齐不同扬声器的频谱。Agiomyrgiannakis和Roupakia[2016]提出了一种动态规划算法,该算法在使用匹配最小化算法匹配源和目标扬声器的同时,同时估计最优频率扭曲和加权变换。Wu等人[2016]使用与局部线性嵌入集成的频谱转换方法进行流形学习。也有使用神经网络建模光谱转换的方法[Desai等人,2010,Chen等人,2014,Hwang等人,2015]。这些模型通常使用大量目标和源扬声器的音频对进行训练。
从多扬声器生成建模到语音克隆
我们考虑一个多说话人生成模型,f(ti,j, si;W,esi ),它接受一个文本ti,j和一个说话人身份si。模型中的可训练i 参数由W、es参数化。后者表示对应于si的可训练说话人嵌入。W和es都是通过最小化i 损失函数L来优化的,该函数L惩罚了生成音频和真音频之间的差异(例如,谱图的回归损失):
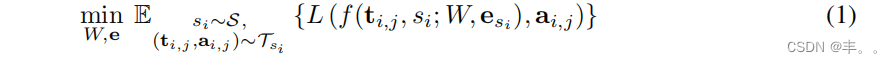
其中S为一组说话者,si S为说话者S的文本音频对的训练集,i,j iS为2个说话i,j 者S的真值音频。对所有训练说话者的文本音频对进行期望i估计。我们使用Wand e来表示c 训练b的参数和嵌入。说话人嵌入已经被证明可以用低维向量有效地捕捉说话人的特征[Arik等人,2017b, Ping等人,2018]。尽管只使用生成损失进行训练,但在说话人嵌入空间中观察到判别属性(例如性别和口音)[Arik等人,2017b]。
对于语音克隆,我们从一组克隆sk 音频a中提取一个看不见的说话k 人的说话人特征,并为该说话人生成一个给定任何文本的音频。生成音频的两个性能指标是语音自然度和说话人相似度(即,生成的音频听起来是否像目标说话人的发音)。神经语音克隆的两种方法在图1中进行了总结,并在以下章节中进行了解释。
说话人自适应
说话者自适应的思想是使用几个音频-文本对一个未见的说话者微调一个训练好的多说话者模型。微调既可以应用于扬声器嵌入[Taigman等人,2018],也可以应用于整个模型。对于仅嵌入的自适应,我们有以下目标
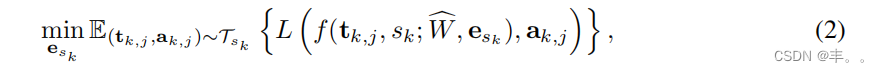
中为sk 目标说话者的一组文本音频对。对于k整个模型自适应,我们有以下目标:

虽然整个模型为说话人的适应提供了更多的自由度,但它的优化对于少量克隆数据来说是具有挑战性的。为了避免过拟合,需要提前停止。
说话人编码
我们提出了一种说话人编码方法,直接从一个看不见的说话人的音频样本中估计说话人嵌入。这样的模型在语音克隆过程中不需要进行任何微调。因此,同样的模型可以用于所有看不见的扬声器。扬声器编码器,g(Ask ;Θ)取一组克隆音频样本a,sk 并估计sk 扬声器sk的e。模型通过Θ参数化。理想情况下,扬声器编码器可以从零开始与多扬声器生成模型联合训练,并为生成的音频定义损失函数:
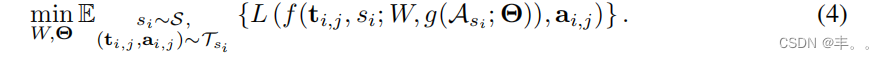
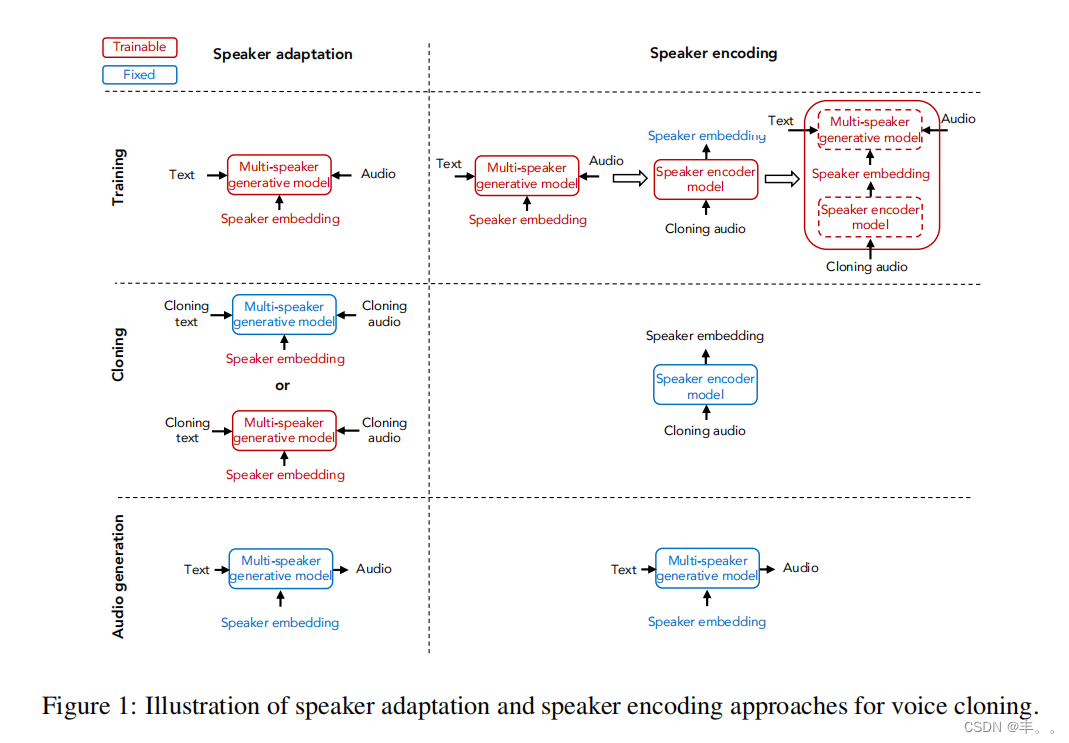
注意,说话人编码器是与多说话人生成模型的说话人一起训练的。在训练过程中,随机抽取一组克隆音频样本si 用于训练说话人si。在推理过程中,来自目标说话ksk 人sa的音频样本用于计算g(a;sk Θ)。我们观察到从头开始联合训练的优化挑战:扬声器编码器倾向于估计平均声音以最小化整体生成损失。一种可能的解决方案是为中间嵌入或4 生成的音频引入判别损失函数。5然而,在我们的案例中,这样的方法只略微改善了说话者的差异。相反,我们为说话人编码器提出了一个单独的训练过程。说话人嵌入是从b训练si 好的多说话人生成模型f(t, s;i,j iW, e),然后,扬声器ssk i 编码器g(A;Θ)使用L1损失进行训练,以预测来自采样克隆音频的嵌入:
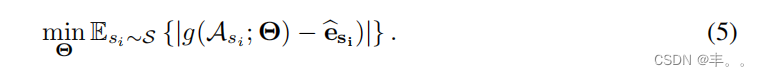
最终,整个模型可以按照Eq. 4进行联合微调,使用预训练好的Wandc Θasb 进行初始化。微调鼓励生成模型补偿嵌入估计误差,并可能减少注意力问题。然而,生成损失仍然主导着学习,生成音频中的说话人差异也可能略有减少(详见4.3节)。

对于扬声器编码器g(Ask ;Θ),我们提出了一个由三部分组成的神经网络架构(如图2所示):
(i)光谱处理:我们将克隆音频样本的mel-谱图输入到prenet, prenet包含具有指数线性单元的全连接层,用于特征转换。
(ii)时间处理:为了利用长期上下文,我们使用带有门控线性单元和残差连接的卷积层,应用平均池化来总结整个话语。
(iii)克隆样本注意力:考虑到不同的克隆音频包含不同数量的说话人信息,我们使用多头自注意机制[Vaswani et al., 2017]来计算不同音频的权重并获得聚合嵌入。
用于评价的判别模型
除了人的评价,我们还提出了两种使用判别模型评价语音克隆性能的方法。
说话人分类
说话人分类器确定一个音频样本属于哪个说话人。对于语音克隆评估,使用用于克隆的说话人集来训练说话人分类器。高质量的语音克隆会带来较高的分类准确率。该架构由图6中相似的光谱和时间处理层以及softmax函数之前的附加嵌入层组成。
说话人验证
演讲者验证是基于演讲者的测试音频和注册音频来验证演讲者声称的身份的任务。特别是,它执行二进制分类来识别测试音频和注册音频是否来自同一演讲者[例如,Snyder等人,2016]。我们考虑了一个端到端与文本无关的说话者验证模型Snyder等人,2016。说话人验证模型可以在多说话人数据集上进行训练,然后用于验证克隆音频和ground-truth音频是否来自同一说话人。与说话人分类方法不同,说话人验证模型不需要使用来自目标说话人的音频进行克隆训练,因此它可以用于具有少量样本的未见说话人。作为定量的性能指标,相等错误率(EER)6 可以用来衡量克隆的音频与地面真实音频的接近程度。
实验
数据集
在我们的第一组实验中(第4.3节和4.4节),使用LibriSpeech数据集[Panayotov等人,2015]训练多说话人生成模型和说话人编码器,该数据集包含2484个说话人的音频(16 KHz),总计820小时。LibriSpeech是一个用于自动语音识别的数据集,与语音合成数据集相比,它的音频质量更低。7 语音克隆是在VCTK数据集上进行的[Veaux et al., 2017]。VCTK由108名英语母语者以48 KHz采样的各种口音的音频组成。为了与LibriSpeech数据集保持一致,VCTK音频被降采样到16 KHz。对于选定的演讲者,每个实验随机采样一些克隆音频。附录B中给出的句子用于生成用于评估的音频。在我们的第二组实验(第4.5节)中,我们的目标是研究训练数据集的影响。我们将VCTK数据集拆分用于训练和测试:84个扬声器用于训练多扬声器模型,8个扬声器用于验证,16个扬声器用于克隆。
模型规格
我们的多说话人生成模型基于Ping等人[2018]提出的卷积序列到序列架构,具有类似的超参数和Griffin-Lim声码器。为了获得更好的性能,我们通过将跳长和窗口大小参数减少到300和1200来提高时间分辨率,并添加二次损失项来超线性地惩罚大幅度分量。对于说话人自适应实验,我们将嵌入维数降低到128,因为它产生的过拟合问题更少。总体而言,基线多说话人生成模型在为LibriSpeech数据集训练时大约有25M个可训练参数。对于第二组实验,使用Ping等人[2018]的VCTK模型的超参数,使用Griffin-Lim声码器为VCTK的84个说话人训练一个多说话人模型。
我们为不同数量的克隆音频分别训练扬声器编码器。最初,克隆音频被转换为80个频带的对数谱图,跳长为400,窗口大小为1600。Log-mel谱图被馈送到光谱处理层,这些层由大小为128的2层prenet组成。然后,用滤波器宽度为12的两个1-D卷积层进行时间处理。最后,对键、查询和值应用2个头和128个单位大小的多头注意。最终的嵌入大小为512。验证集由25个手持扬声器组成。使用64个批次大小,初始学习率为0.0006,退火率为0.6,每8000次迭代应用一次。验证集的平均绝对误差如附录D中的图11所示。更多的克隆音频会导致更准确的说话人嵌入估计,特别是在注意机制下(关于学习到的注意系数的更多细节见附录D)。
我们使用VCTK数据集训练说话人分类器,对音频样本属于108个说话人中的哪一个进行分类。说话人分类器有一个大小为256的全连接层,6个卷积层,256个宽度为4的滤波器,以及一个大小为32的最终嵌入层。对于大小为512的验证集,该模型达到了100%的准确率。
我们使用LibriSpeech数据集训练说话人验证模型。验证集由来自Librispeech的50个待定演讲者组成。eer是通过在测试集中随机配对来自相同或不同说话者的话语(每种情况50%)来估计的。我们对每个测试集进行40960次试验。我们在附录C中描述了说话人验证模型的细节。
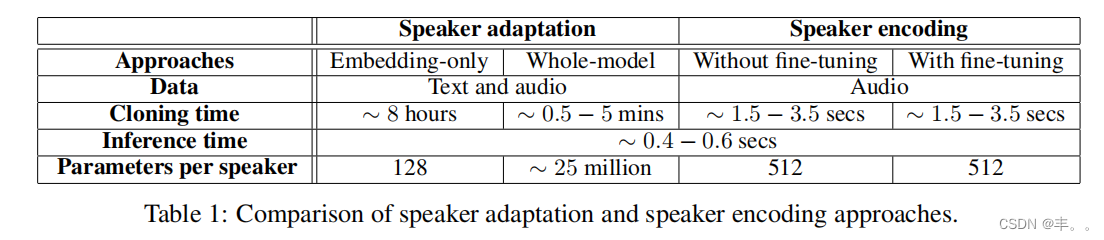
对于说话人自适应方法,我们使用说话人分类精度来选择最优的迭代次数。对于说话人编码,我们考虑了说话人编码器和多说话人生成模型联合微调和不联合微调的语音克隆表1总结了这些方法,并列出了对训练、数据、克隆时间和内存占用的要求。
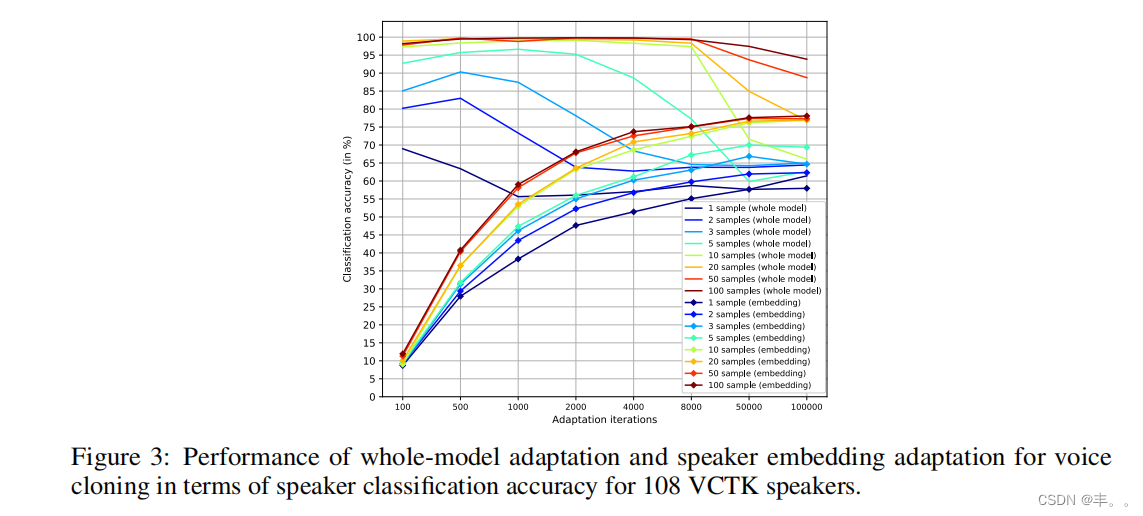
图3:在108个VCTK说话人的说话人分类准确率方面,全模型自适应和说话人嵌入自适应用于语音克隆的表现。
对于说话人自适应,图3显示了说话人分类精度与迭代次数的关系。对于两者,随着样本数量的增加,分类精度显著提高,最多可达10个样本。在低样本计数情况下,调整说话人嵌入不太可能导致样本过拟合
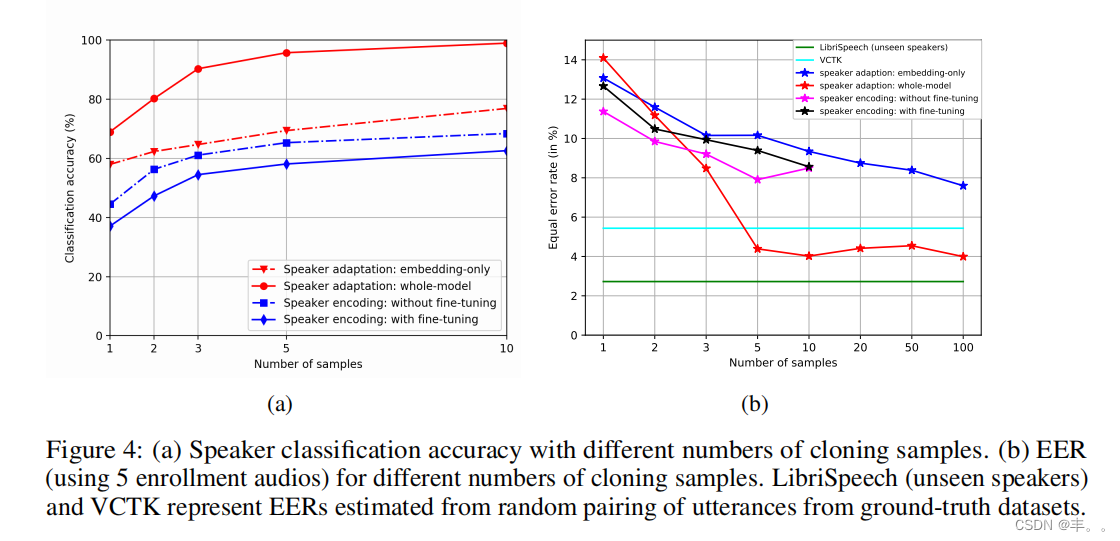
而不是调整整个模型。这两种方法也需要不同的迭代次数来收敛。与全模型自适应相比(即使100个克隆音频样本,它也会在1000次迭代左右收敛),嵌入自适应需要明显更多的迭代才能收敛,因此它会导致更长的克隆时间。
图4a和4b显示了通过说话人分类和说话人验证模型获得的分类精度和EER。说话人自适应和说话人编码都受益于更多的克隆音频。当克隆音频样本数量超过5个时,全模型自适应优于其他技术。与嵌入自适应相比,说话人编码产生的分类精度较低,但它们实现了相似的说话人验证性能。
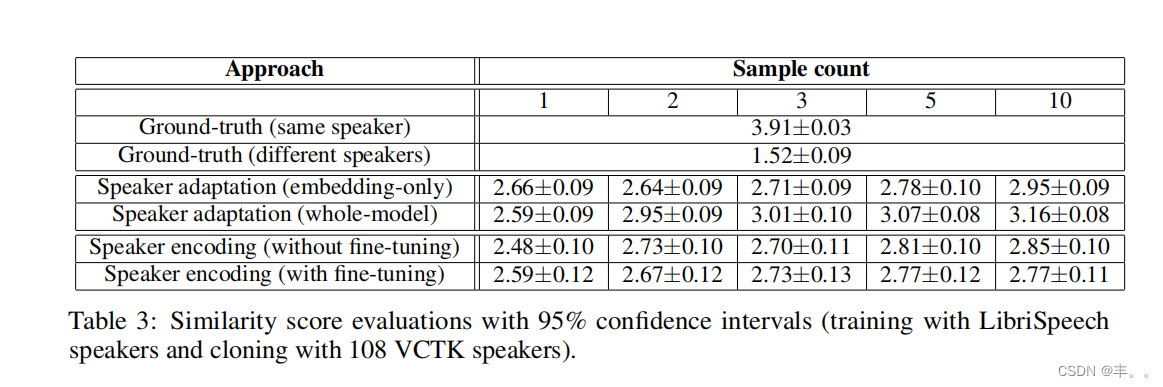
除了通过判别模型进行评估外,我们还对Amazon Mechanical Turk框架进行了主题测试。对于自然度的评估,我们使用5级平均意见评分(MOS)。为了评估生成的音频与目标说话者的真实音频的相似程度,我们使用了[Wester et al., 2016]中的问题和类别的4级相似度评分。9 表2和表3显示了人工评估的结果。更多的克隆音频可以改善这两个指标。这种改进对于整个模型的适应更为显著,因为为看不见的说话者提供了更多的自由度。事实上,对于高样本数,由于更好质量的适应样本在训练数据上占主导地位,自然度显著超过了基线模型。说话人编码实现了与基线模型相似或更好的自然度。通过微调,自然度甚至得到了进一步的提高,因为它允许生成模型学习如何补偿说话人编码器的错误。随着说话人编码的样本数增加,相似度得分略有提高,并与说话人嵌入自适应的分数相匹配。
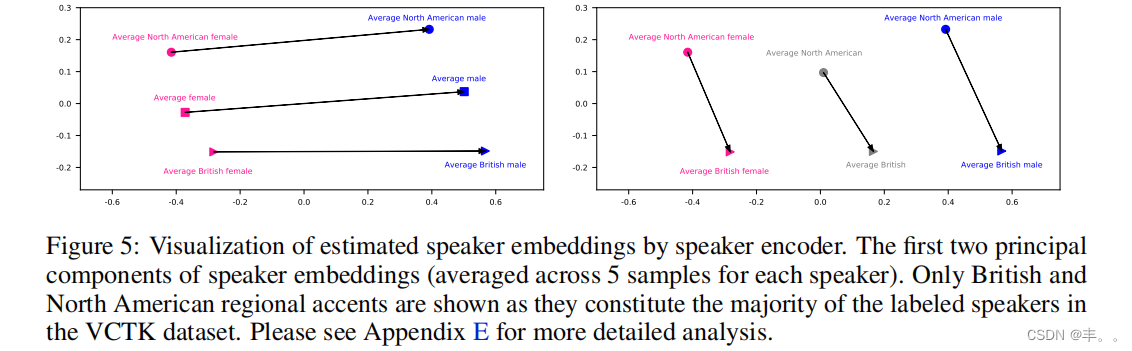
通过嵌入操纵实现语音变形
如图5所示,音箱编码器将音箱映射到一个有意义的潜在空间中。受词嵌入操作的启发(例如,为了证明存在简单的代数运算,如国王-王后=男性-女性),我们将代数运算应用于推断嵌入,以转换其语音特征。为了转换性别,我们估计每个性别的平均说话人嵌入,并将它们的差异添加到特定的说话人。例如,British male + AveragedFemale - AveragedMale得到一个英国女性说话者。同样,我们通过BritishMale + AveragedAmerican - AveragedBritish来考虑口音转换的区域,从而得到一个美国男性说话者。我们的结果展示了具有特定性别和口音特征的高质量音频。
训练数据集的影响
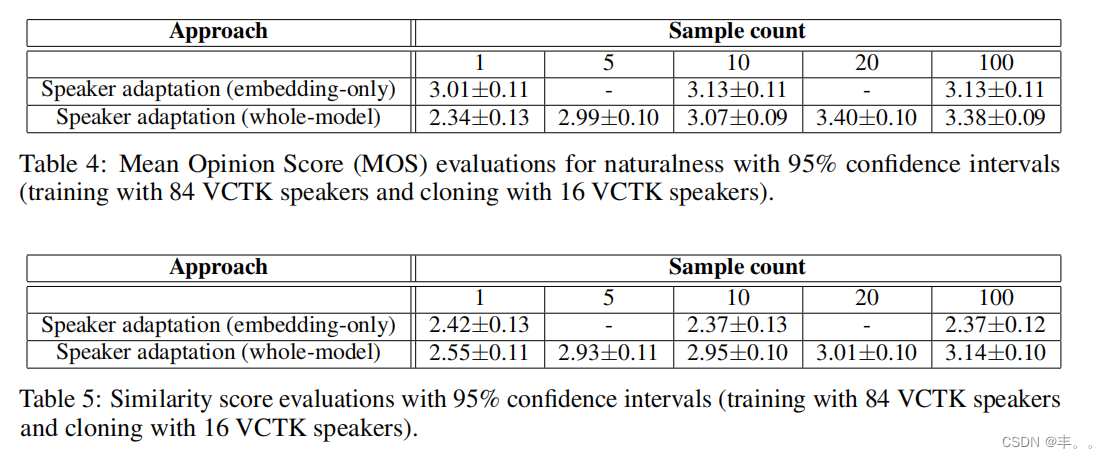
为了评估数据集的影响,我们考虑使用包含84个扬声器的VCTK子集进行训练,并在另外16个扬声器上进行克隆。表4和表5给出了人类的评估
对于说话人的适应。11 说话人验证结果见附录c。一方面,与LibriSpeech相比,更干净的VCTK数据改善了多说话人生成模型,从而获得更好的整体模型自适应结果。另一方面,由于VCTK数据集中的说话人多样性有限,仅嵌入自适应的表现明显不如全模型自适应。
结论
研究了两种神经语音克隆方法:说话人自适应和说话人编码。我们证明,即使只有少量的克隆音频,这两种方法也可以获得良好的克隆质量。对于自然度,我们证明了说话人自适应和说话人编码都可以实现类似于基线多说话人生成模型的MOS。因此,所提出的技术在未来有可能通过更好的多扬声器模型得到改进(例如用WaveNet声码器取代Griffin- Lim)。出于相似性,我们证明了这两种方法都受益于大量的克隆音频。整体模型和仅嵌入自适应之间的性能差距表明,除了说话人嵌入之外,生成模型中仍然存在一些判别性的说话人信息。通过嵌入的紧凑表示的好处是快速克隆和每个说话人占用的空间小。我们观察到使用低质量音频和有限说话人多样性的语音识别数据集训练多说话人生成模型的缺点。数据集质量的提高将导致更高的自然度。我们希望我们的技术能够从大规模和高质量的多说话人数据集中显著受益。