目标
#2020.5.21
#author:pmy
#目标:爬取链家成都的新房楼盘,每个楼盘的信息包括名称,参考均价,区域,具体项目地址,开盘时间,户型
#问题1,项目地址别抓下面的项目地址,而是住区上面的高新楼盘>长治南阳羽龙服 之类的,这个更清晰
#问题2:可能没有参考售价,但应该有字,抓下来就行
本次实战练习只是在于进一步熟练使用BeautifulSoup,更多内容可以点击爬虫实战 爬取豆瓣top250电影(BeautifulSoup)
链家和豆瓣的爬取都是比较简单的,因为是偏向于那种信息展示的网站,比较规范统一。
这里虽然爬取的是成都的新房房源,但其实本博客的代码可以爬取任意城市链家的房源,需要将https://cd.fang.lianjia.com/loupan/pg中的cd改成其他城市的简称,同时将headers中的host修改成bj,将get_url方法中的字符串改成bj,方可。至于二手房,就是修改loupan为ershoufang即可。
网页分析
本次爬取的网站https://cd.fang.lianjia.com/loupan/pg。
打开网页之后,我们发现它是一个分页的展示,一共100页,每页最多10个房源。
然后观察他们每页的url。
发现规律,其中pg参数便是不同分页的关键,第2页是2,而第4页是4。
所以我们便以https://cd.fang.lianjia.com/loupan/pg为基础的url。
从1开始到100,每次和上面的基础url拼接便得到了100个分页的url。
下一步就是从每个分页上抓取10个房源的url。
我们选中第一部电影的标题,发现其url的位置如下图所示。

实现代码如下:
soup = BeautifulSoup(html,'html.parser')ul = soup.find('ul',class_='resblock-list-wrapper')for li in ul.find_all('li',class_='resblock-list post_ulog_exposure_scroll has-results'):a = li.find('a')# print('https://cd.fang.lianjia.com/' + a['href'])yield 'https://cd.fang.lianjia.com/'+a['href']
对于每个房源,我们来分析其各名称,户型,价格等信息的标签特征,从而快速找到信息,抓取信息。
名称的位置特征如下图,先找到class_='DATA-PROJECT-NAME’的h2,直接提取其文本就好。

实现代码如下:
#名称h2 = soup.find('h2',class_='DATA-PROJECT-NAME')house_name = h2.get_text()
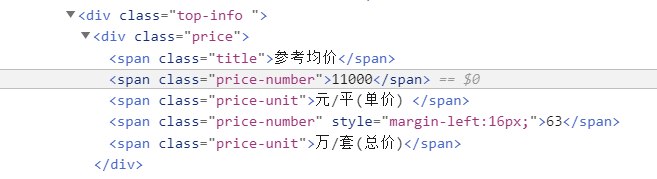
价格的位置特征如下,提取其class_='price-number’的span的文本即可,这里可能没有定价,但是也有这个标签,标签的文本内容为“价格待定”。
实现代码如下:
#参考均价house_price = soup.find('span',class_='price-number').get_text()
区域,为了显示房源大致在哪个区,我便从下图所示的位置来找寻,这样可以知道是高新区还是金牛区,还是什么区。因为发现需要提取的信息旁边一定有本房源的名称,而且位置十分靠上,所以就直接搜索我们直接提取的房源的名称,找到其父节点的前一个兄弟节点即可。

实现代码如下:
#区域area_next = soup.find(string=house_name)house_area = area_next.parent.find_previous_sibling('a').get_text()
具体项目地址,也是和上一个区域类似的方法,通过一定的字符串来寻找
实现代码如下:
#项目地址location_next = soup.find(string='项目地址')house_location = location_next.parent.find_next_sibling('span').get_text()
户型,这里遇到的问题是,有些房源没有户型,所以这里用一个try-catch,同样方法还是和抓取区域一样,用字符串来定位,再找其父节点的兄弟节点。

实现代码如下:
#户型 有的可能没有 需要try-catchtry:type_next = soup.find(string='楼盘户型')house_type = ''for each in type_next.parent.find_next_sibling('span',class_='content').find_all('span'):house_type += each.get_text()except:house_type = ''
开盘时间也是类似

实现代码如下:
#开盘时间date_next = soup.find(string='最新开盘')house_date = date_next.parent.find_next_sibling('span').get_text()
完整代码
#2020.5.21
#author:pmy
#目标:爬取链家成都的新房楼盘,每个楼盘的信息包括名称,参考均价,区域,具体项目地址,开盘时间,户型
#问题1,项目地址别抓下面的项目地址,而是住区上面的高新楼盘>长治南阳羽龙服 之类的,这个更清晰
#问题2:可能没有参考售价,但应该有字,抓下来就行# 成都楼盘原始界面 https://cd.fang.lianjia.com/loupan/
# 北京楼盘原始界面 https://bj.fang.lianjia.com/loupan/
# 区别在于fang前面的城市缩写
# https://cd.fang.lianjia.com/loupan/pg2/
# 页面在于pg“i”#首先爬取子页面链接#然后爬取信息import requests
from bs4 import BeautifulSoup
import time
import jsonbase_url='https://cd.fang.lianjia.com/loupan/pg'
# test_url='https://cd.fang.lianjia.com/loupan/p_dyhybkygs/'headers = {'Host': 'cd.fang.lianjia.com','User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36'
}#获取当前单个url的html
def get_response(url):try:response = requests.get(url, headers=headers)if response.status_code == 200:return response.textexcept requests.ConnectionError as e:print('Error', e.args)#获取当前页面的所有子链接 10个
def get_url(page):url = base_url+str(page)html = get_response(url)soup = BeautifulSoup(html,'html.parser')ul = soup.find('ul',class_='resblock-list-wrapper')for li in ul.find_all('li',class_='resblock-list post_ulog_exposure_scroll has-results'):a = li.find('a')# print('https://cd.fang.lianjia.com/' + a['href'])yield 'https://cd.fang.lianjia.com/'+a['href']###############分析
#div class=resblock-list-container clearfix#ul class=resblock-list-wrapper#li class=resblock-list post_ulog_exposure_scroll has-results#a class=resblock-img-wrapper#获取一套房源信息
def get_data(url):html = get_response(url)soup = BeautifulSoup(html,'html.parser')#名称h2 = soup.find('h2',class_='DATA-PROJECT-NAME')house_name = h2.get_text()#参考均价house_price = soup.find('span',class_='price-number').get_text()#区域area_next = soup.find(string=house_name)house_area = area_next.parent.find_previous_sibling('a').get_text()#项目地址location_next = soup.find(string='项目地址')house_location = location_next.parent.find_next_sibling('span').get_text()#开盘时间date_next = soup.find(string='最新开盘')house_date = date_next.parent.find_next_sibling('span').get_text()#户型 有的可能没有 需要try-catchtry:type_next = soup.find(string='楼盘户型')house_type = ''for each in type_next.parent.find_next_sibling('span',class_='content').find_all('span'):house_type += each.get_text()except:house_type = ''return {'house_name':house_name,'house_price':house_price,'house_area':house_area,'house_date':house_date,'house_location':house_location,'house_type':house_type}#存储到txt文件中
def save_data(data,count):filename = 'result'+str(count)+'.txt'with open(filename, 'a', encoding='utf-8') as f:f.write(json.dumps(data, ensure_ascii=False) + '\n')f.close()if __name__ == '__main__':for i in range(1,101):page = i# 获取每个页面的10个链接urls = get_url(page)for url in urls:# 对每部电影抓取信息并存储save_data(get_data(url), i//10)time.sleep(0.1)time.sleep(0.5)print('第' + str(i) + '页完成')结果