MySQL技术内幕-InnoDB存储引擎第2版-学习笔记-01
1. MySQL体系结构和存储引擎
1.1 定义数据库和实例
-
数据库database:
物理操作系统文件或其他形式文件类型的集合。
当使用NDB引擎时,数据库的文件可能不是操作系统上的文件,而是存放于内存中的文件,定义不变。
-
实例instance:
MySQL数据库由后台线程以及一个共享内存区组成。共享内存可以被运行的后台线程所共享。需要牢记的是,数据库实例才是真正用于操作数据库文件的。
一个实例对应一个数据库,一个数据库对应一个实例。在集群情况下,可能存在一个数据库被多个数据实例使用的情况。
MySQL单进程多线程,MySQL数据库实例在系统上的表现就是一个进程。
1.2 MySQL体系结构
MySQL体系结构_贾维斯的博客-CSDN博客_mysql体系结构

- 连接池组件
- 管理服务和工具组件
- SQL接口组件
- 查询分析器组件
- 优化器组件
- 缓冲(Cache)组件
- 插件式存储引擎
- 物理文件
MySQL数据库区别于其他数据库的最重要的一个特点就是插件式的表存储引擎。
存储引擎基于表,而不是数据库。
1.3 MySQL存储引擎
1.3.1 InnoDB存储引擎
MySQL5.5.8开始,InnoDB是默认的存储引擎。
-
InnoDB存储引擎支持事务
-
主要面向在线事务处理(OLTP)应用
-
行锁设计
-
支持外键
-
支持类似Oracle的非锁定读,默认读操作不会产生锁
-
数据存储在逻辑表内
-
MySQL4.1之后,InnoDB表单独存放到独立的ibd文件中
-
支持用裸设备(raw disk)建立表空间
-
多版本并发控制(MVCC)以支持高并发性
-
实现SQL标准的4种隔离级别,默认为REPEATABLE
-
使用next-key locking策略避免幻读(phantom)现象
-
提供插入缓冲(insert buffer)、二次写(double write)、自适应哈希索引(adaptive hash index)、**预读(read ahead)**等高性能和高可用的功能
-
对于表中数据的存储,InnoDB存储引擎采用了聚集(clustered)的方式,因此每张表的存储都是按主键的顺序进行存放
-
如果没有显式地在表定义时指定主键,InnoDB存储引擎会为每一行生成一个6字节的ROWID,并以此作为主键
1.3.2 MyISAM存储引擎
在MySQL5.5.8之前MyISAM存储引擎是默认的存储引擎(除WIndows版本外)
-
不支持事务
-
表锁设计
-
支持全文索引
-
主要面向OLAP数据库应用
-
MyISAM的缓存池只缓存(cache)索引文件,而不缓冲数据文件
-
MyISAM存储引擎表由MYD和MYI组成,MYD用来存放数据文件,MYI用来存放索引文件
-
可以使用myisampack工具进一步压缩数据文件
-
myisampack使用哈夫曼(Huffman)编码静态算法压缩数据,压缩后的表是只读的
-
MySQL5.0之前,MyISAM默认支持的表大小为4GB
(如需支持更大的表,需指定MAX_ROWS和AVG_ROW_LENGTH属性)
-
MySQL5.0起,MyISAM默认支持256TB的单表数据
对于MyISAM存储引擎表,MySQL数据库只缓存索引文件,数据文件的缓存由操作系统本身完成,这与其他使用LRU算法缓存数据的大部分数据库不同。
MySQL5.1.23之前,32位和64位的操作系统缓存索引的缓冲区最大只能设置为4GB,往后的版本64位系统可以支持大于4GB的索引缓冲区。
1.3.3 NDB存储引擎
NDB是集群存储引擎,类似Oracle的RAC集群。与Oracle RAC share everything架构不同,NDB采用的是share nothing的集群架构,可用性更高。
-
数据全部存放在内存中,主键查找(primaru key looups)速度极快
(MySQL5.1开始,可以将非索引数据放在磁盘上)
-
通过添加NDB数据存储节点(Data Node)可以线性提高数据库性能,是高可用、高性能的集群系统
-
连接操作(JOIN)在MySQL数据库层完成,而不是在存储引擎层完成
(复杂的连接操作需要巨大的网络开销,因此查询速度很慢)
1.3.4 Memory存储引擎
之前称HEAP存储引擎。
-
将表中的数据存放在内存中
(如果数据库重启或者发生崩溃,表中的数据都将消失)
-
适合用于存储临时数据的临时表,以及数据仓库中的维度表
-
默认使用哈希索引,而不是B+树索引
-
只支持表锁,并发性能较差
-
不支持TEXT和BLOB类型数据
-
存储变长字段(varchar)时,按照定长字段(char)方式存储,会造成内存浪费
(eBay的工程师Igor Chernyshev给出patch解决方案)
-
MySQL数据库使用Memory存储引擎作为临时表来存放查询的中间结果集(intermediate result)。如果中间结果集大雨Memory存储引擎表的容量设置,又或者中间含有TEXT或BLOB列类型字段,则MySQL数据库会把其转换到MyISAM存储引擎表而存放到磁盘中。MyISAM不缓存数据文件,此时产生的临时表的性能对于查询会有损失。
1.3.5 Archive存储引擎
- 只支持INSERT和SELECT操作
- MySQL5.1起,支持索引
- 使用zlib算法将数据行(row)进行压缩后存储,压缩比一般可达到1:10
- 适合存储归档数据,如日志信息
- 使用行锁实现高并发插入操作
- 非事务安全,设计目标主要是提供高速插入和压缩功能
1.3.6 Federated存储引擎
-
不存放数据,只是指向一台远程MySQL数据库服务器上的表
(类似SQL Server的链接服务器和Oracle的透明网关)
-
只支持MySQL数据库表,不支持异构数据库表
1.3.7 Maria存储引擎
-
设计目标是取代MyISAM,作为MySQL的默认存储引擎
(可视为是MyISAM的后续版本)
-
支持缓存数据和索引文件
-
行锁设计
-
提供MVCC功能
-
支持事务和非事务安全的选项
-
对BLOB字符类型的处理性能更好
1.3.8 其他存储引擎
Merge、CSV、Sphinx、Infobright等。
-
支持全文索引:MyISAM、InnoDB(1.2版本)和Sphinx
-
对于ETL操作,MyISAM更有优势;OLTP环境,InnoDB效率更高
-
当表的数据量大于1000万时MySQL的性能会急剧下降吗?
根据场景选择合适的存储引擎(以及正确的配置)。官方手册提及,Mytrix和Inc.在InnoDB上存储超过1TB的数据,还有一些网站使用InnoDB存储引擎,处理插入/更新的操作平均800次/秒
1.4 各储存引擎之间的比较
什么是存储引擎以及不同存储引擎特点 - wildfox - 博客园 (cnblogs.com)

- 通过
SHOW ENGINES或查找information_schema架构下的ENGINES表,可查看当前使用的MySQL数据库所支持的存储引擎
1.5 连接MySQL
连接MySQL操作是一个连接进程和MySQL数据库实例进行通信,本质上是进程通信。
进程通信的方式有管道、命名管道、TCP/IP套接字、UNIX域套接字等。
MySQL数据库提供的连接方式从本质上看即上述提及的进程通信方式。
1.5.1 TCP/IP
MySQL实例(server)在一台服务器上,客户端client在另一台服务器上与其通过TCP/IP网络进行通信。
在通过TCP/IP连接到MySQL实例时,MySQL数据库会先检查一张权限视图,用来判断发起请求的客户端IP是否允许连接到MySQL实例。
在mysql架构下,表名为user。
1.5.2 命名管道和共享内存
-
如果两个需要进程通信的进程在同一台服务器上,可以使用命名管道,Microsoft SQL Server数据库默认安装后的本地连接也是使用命名管道。在MySQL数据库中须在配置文件中启用
--enable-named-pipe选项。 -
在MySQL4.1之后,提供共享内存的连接方式,通过配置文件中添加
--shared-memory实现。如果想使用共享内存的方式,在连接时,MySQL客户端还需要使用--protocol=memory选项。
1.5.3 UNIX域套接字
在Linux和Unix环境下,还可以使用UNIX域套接字。UNIX域套接字不是网络协议,只能在MySQL客户端和数据库实例在一台服务器上的情况下使用。用户可以在配置文件中指定套接字文件的路径,如--socket=/tmp/mysql.sock。当数据库实例启动后,用户可以通过下列命令来进行UNIX域套接字文件的查找:
SHOW VARIABLES LIKE 'socket';
查出UNIX域套接字文件路径后,进行连接mysql -udavid -S 套接字文件
1.6 小结
- 数据库、数据库实例
- 常见的表存储引擎的特性
- MySQL独有的插件式存储引擎概念
2. InnoDB存储引擎
InnoDB是事务安全的MySQL存储引擎,设计上采用了类似Oracle数据库的结构。
通常来说,InnoDB存储引擎是OLTP应用中核心表的首选存储引擎。
2.1 InnoDB存储引擎概述
MySQL5.5开始,InnoDB是MySQL默认的表存储引擎(之前的版本InnoDB存储引擎尽在Windows下为默认的存储引擎)。
InnoDB是第一个完整支持ACID事务的MySQL存储引擎(BDB是第一个支持事务的MySQL存储引擎,已经停止开发)
特点:
- 行锁设计
- 支持MVCC
- 支持外键
- 提供一致性非锁定读
- 被设计用来最有效地利用以及使用内存和CPU
2.2 InnoDB存储引擎的版本
| 版本 | 功能 |
|---|---|
| 老版本InnoDB | 支持ACID、行锁设计、MVCC |
| InnoDB 1.0.x | 继承了上述版本所有功能,增加了compress和dynamic页格式 |
| InnoDB 1.1.x | 继承了上述版本所有功能,增加了Linux AIO、多回滚段 |
| InnoDB 1.2.x | 继承了上述版本所有功能,增加了全文索引支持、在线索引添加 |
2.3 InnoDB体系架构
InnoDB体系架构详解_qqqq0199181的博客-CSDN博客_innodb架构
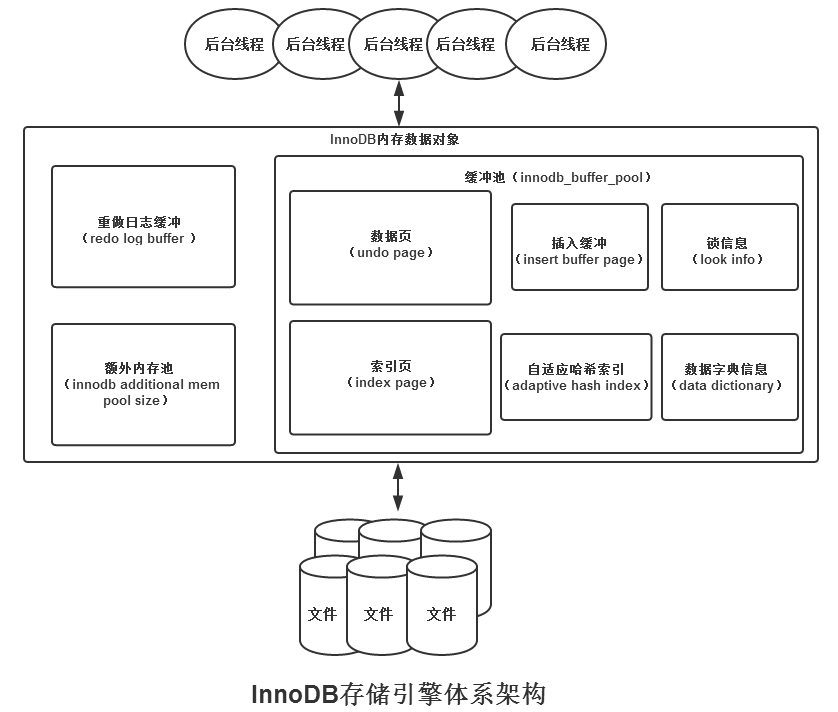
InnoDB存储引擎有多个内存块,可以认为这些内存块组成了一个大的内存池,负责如下工作:
- 维护所有进程/线程需要访问的多个内部数据结构。
- 缓存磁盘上的数据,方便快速地读取,同时在对磁盘文件的数据修改之前在这里缓存。
- 重做日志(redo log)缓冲。
后台线程的主要作用是负责刷新内存池中的数据,保证缓冲池中的内存缓存是最近的数据。此外将已修改的数据文件刷新到磁盘文件,同时保证在数据库发生异常的情况下InnoDB能恢复到正常运行状态。
2.3.1 后台线程
-
Master Thread
主要负责将缓冲池中的数据异步刷新到磁盘,保证数据的一致性。
- 脏页的刷新
- 合并插入缓冲(INSERT BUFFER)
- UNDO页的回收
- …
ps:2.5节会详细地介绍各个版本中的Master Thread的工作方式。
-
IO Thread
在InnoDB存储引擎中大量使用了AIO(Async IO)来处理写IO请求,极大提高数据库的性能。
IO Thread主要负责这些IO请求的回调(call back)处理。
(此处省略参数配置、使用介绍)
-
Purge Thread
事务被提交后,其所使用的undolog可能不再需要,因此需要PurgeThread回收已经使用并分配的undo页。
- InnoDB1.1之前,purge操作仅在Master Thread中完成
- InnoDB1.1之后,purge操作可以独立到单独的线程中进行
(此处省略配置文件设置启用独立的Purge Thread)
-
Page Cleaner Thread
InnoDB 1.2.x版本中引入。
将之前版本中脏页的刷新操作都放入到单独的线程中完成,减轻原Master Thread的工作及对于用户查询线程的阻塞,进一步提高InnoDB存储引擎的性能。
2.3.2 内存
InnoDB存储引擎基于磁盘存储,并将其中的记录按照页的方式进行管理。因此可以将其视为基于磁盘的数据库系统(Disk-base Database)。
-
缓冲池
简单来说就是一块内存区域,通过内存的速度来弥补磁盘速度较慢对数据库性能的影响。
在数据库中进行读取页的操作,首先将从磁盘读到的页放在缓冲池中。这个过程称为将页"FIX"在缓冲池中。下一次再读取相同的页时,首先判断该页是否在缓冲池中。若在缓冲池中,称该页在缓冲池中被命中,直接读取该页,否则读取磁盘上的页。
对于数据库中过的页操作,则首先修改在缓冲池中的页,然后再以一定的频率刷新到磁盘上。
- 并非每次缓冲池中的页发生更新时触发刷新数据到磁盘,而是通过Checkpoint机制刷新到磁盘。
(此处省略缓冲池大小配置)
-
缓冲池缓存的数据页数据类型有:索引页、数据页、undo页、插入缓冲(insert buffer)、自适应哈希索引(data dictionary)等。

InnoDB存储引擎内部结构_weixin_33860528的博客-CSDN博客
从InnoDB 1.0.x开始,允许有多个缓冲池实例。每个页根据哈希值平均分配到不同的缓冲池实例中。可通过innodb_buffer_pool_instances进行配置,默认值为1。
(此处省略关于innodb_buffer_pool_instances相关的配置介绍和使用)
-
LRU List、Free List和Flush List
通常来说,数据库中的缓冲池通过LRU算法进行管理。当缓冲池不能存放新读取到的页时,首先释放LRU列表中尾端的页。
InnoDB存储引擎中,缓冲池中的页大小默认为16KB,同样使用LRU算法对缓冲池进行管理。
InnoDB对传统LRU进行优化,在LRU列表中加入了midpoint位置。新读取到的页,并非放到LRU列表首部,而是放到LRU列表的midpoint位置。(在InnoDB称为midpoint insertion strategy)
默认配置下,midpoint在LRU列表长度的5/8处。(可由innodb_old_blocks_pct控制)
(此处省略innodb_old_blocks_pct配置和说明)
InnoDB中,把midpoint之后的列表称为old列表,之前的称为new列表。可以简单理解为new列表中的页都是最为活跃的热点数据。
-
为什么不适用朴素的LRU算法,将新读取的页插入LRU首部?
若直接插入LRU首部,诸如索引或者数据的扫描操作,会使缓冲池中的页被刷新出,这些数据一般仅在本次查询中使用,非热点数据。这使得原先真正的热点数据从LRU列表中被移除,下一次读取该页,需要重新从磁盘读取。
为解决该问题,InnoDB引入innodb_old_blocks_time,表示该页读取到mid位置后需要等待多久才会被加入到LRU列表的热端。
(省略配置介绍)
数据库启动时,LRU列表空,所有页存放在Free列表中。当需要从缓冲池分页时,首先从Free列表中查找是否有可用的空闲页,若有则将该页从Free列表中删除,放入LRU列表中。
- 当页从LRU的old部分加入到new部分时,称该操作为page made young
- 因innodb_old_blocks_time的设置而导致页没有从old部分移动到new部分的操作称为page not made young
可以通过
SHOW ENGINE INNODB STATUS观察LRU列表以及Free列表的使用情况和运行状态。(此处省略指令的使用)
- 缓冲池中的页还可能被分配给自适应哈希索引、Lock信息、Insert Buffer等页,这部分页不需要LRU算法维护,因此不再LRU列表中
SHOW ENGINE INNODB STATUS,输出的Buffer pool hit rate表示缓冲池命中率,通常不应该小于95%,出现异常时需要观察是否是由于全表扫描引起LRU列表被污染的问题。SHOW ENGINE INNODB STATUS显示的非当前状态,而是过去某个时间范围的InnoDB存储引擎的状态。(省略压缩页unzip_LRU内容介绍)
-
-
重做日志缓冲(redo log buffer)
InnoDB首先将重做日志信息放入该缓冲区,然后按照一定频率将其刷新到重做日志文件。
redo log buffer一般不用设置很大,一般每一秒钟会将重做日志缓冲刷新到日志文件,只需保证每秒产生的事务量在这个缓冲大小之内即可。(配置参数innodb_log_buffer_size,默认8MB)
通常8MB足以,下列三种情况下会将刷新缓冲到磁盘的重做日志文件中:
- Master Thread每一秒将重做日志缓冲刷新到重做日志文件
- 每个事物提交时会将重做日志缓冲到重做日志文件
- 当重做日志缓冲池剩余空间小于1/2时,重做日志缓冲刷新到重做日志文件
-
额外的内存池
在InnoDB中,通过内存堆(heap)的方式管理内存。对一些数据结构本身的内存进行分配时,需要从额外的内存池中进行申请,当该区域内存不足时,会从缓冲池中进行申请。
例如,分配了缓冲池(innodb_buffer_pool),但是每个缓冲池中的帧缓冲(frame buffer)还有对应的缓冲池控制对象(buffer control block),这些对象记录了一些诸如LRU、锁、等待等信息,而这个对象的内存需要从额外内存池中申请。
因此,申请了很大的InnoDB缓冲池时,也应考虑相应增加这个值。
* 2.4 Checkpoint技术
为了避免数据丢失,当前事务数据库系统普遍采用了Write Ahead Log策略。即当食物提交时,先写重做日志(磁盘),再修改页(内存)。(宕机导致内存数据丢失时,即通过重做日志完成数据恢复,保证事务ACID的D,Durability)
Checkpoint(检查点)技术主要解决以下几个问题:
- 缩短数据库的恢复时间(宕机时,Checkpoint之前的页都已经刷新回磁盘,只需对Checkpoint之后的重做日志进行恢复)
- 缓冲池不够用时,将脏页刷新到磁盘(当缓冲池不够用时,根据LRU算法会溢出最近最少使用的页,若此页为脏页,那么需要强制执行Checkpoint,将脏页也就是页的新版本刷回磁盘)
- 重做日志不可用时,刷新脏页(当前事务数据库系统对重做日志的设计都是循环使用的,并非无限增大。不再需要的重做日志片段在宕机时可被覆盖重用。如果这部分重做日志还需要使用,那必须强制产生Checkpoint,将缓冲池中的页纸烧刷新到当前重做日志的位置。)
InnoDB存储引擎,通过LSN(Log Sequence Number)标记版本。LSN是8字节数字,单位是字节。每个页有LSN,重做日志也有LSN,Checkpoint也有LSN。可通过SHOW ENGINE INNODB STATUS来观察。
概述,Checkpoint主要作用即将缓冲池中的脏页刷回到磁盘。不同的细节即:每次刷新多少页到磁盘、从哪里取脏页面、什么时候触发Checkpoint。
InnoDB引擎内部,有两种Checkpoint:
- Sharp Checkpoint(默认在数据库关闭时将所有脏页刷新回磁盘,参数
innodb_fast_shutdown=1) - Fuzzy Checkpoint(InnoDB存储引擎内部使用,只刷新一部分脏页)
InnoDB存储引擎中可能发生以下几种情况的Fuzzy Checkpoint:
-
Master Thread Checkpoint
每秒or每十秒速度异步从缓冲池刷新一定比例脏页回磁盘,不阻塞用户查询线程。
-
FLUSH_LRU_LIST Checkpoint
InnoDB 1.1.版本之前,在用户查询线程需保证LRU列表有差不多100个空闲页供用户查询时使用。若没有100个可用空闲页,那么InnoDB存储引擎会将LRU列表尾端的页移除,如果这些页中有脏页,那么需要进行Checkpoint,而这些页来自LRU列表,所以称为FLUSH_LRU_LIST Checkpoint。
MySQL5.6,InnoDB1.2.x版本开始,这项检查放在单独的Page Cleaner线程中运行,用户可通过参数
innodb_lru_scan_depth控制LRU列表中可用页的数量(默认1024)。 -
Async/Sync Flush Checkpoint
重做日志文件不可用时,需强制从脏页列表中选取部分脏页刷新回磁盘。Async/Sync Flush Checkpoint保证重做日志的循环使用的可用性。InnoDB 1.2.x之前,Async Flush Checkpoint阻塞发现问题的用户查询线程,而Sync Flush Checkpoint阻塞所有用户查询线程,并等待脏页刷新完成。InnoDB 1.2.x开始,这部分的刷新操作同样放到单独的Page Cleaner Thread中,不阻塞用户查询线程。
SHOW ENGINE INNODB STATUS可观察具体细节。 -
Dirty Page too much Checkpoint
为保证缓存池有足够可用的页,脏页过多会触发InnoDB存储引擎强制进行Checkpoint。阈值油
innodb_max_dirty_pages_pct控制,值75表示脏页数据占比75%强制Checkpoint刷新部分脏页到磁盘。InnoDB 1.0.x之前默认值90,之后默认值75。
2.5 Master Thread工作方式
InnoDB存储引擎的主要工作在单独的后台线程Master Thread中完成。
2.5.1 InnoDB 1.0.x版本之前的Master Thread
Master Thread具有最高线程优先级。其内部由多个循环(loop)组成:主循环(loop)、后台循环(backgroup loop)、刷新循环(flush loop)、暂停循环(suspend loop)。Master Thread根据数据库运行状态在上述几种loop中进行切换。
大部分操作在主循环Loop中,其有两大部分的操作——每秒钟的操作和每10秒的操作。
每秒钟的操作包括:
-
日志缓冲刷新到磁盘,即使这个事务还没有提交(总是);
这就是为什么再大的食物提交(commit)时间也是很短的。
-
合并插入缓冲(可能);
前一秒内发生的IO次数小于5次则认为当前IO压力小,才执行合并插入缓冲的操作。
-
至多刷新100个Innodb的缓冲池中的脏页到磁盘(可能);
缓冲池中脏页比例超过
buf_get_modified_ratio_pct(默认90,表示90%)则将100个脏页写入磁盘中。 -
如果当前没有用户活动,则切换到background loop(可能)。
每10秒的操作包括:
-
刷新100个脏页到磁盘(可能的情况下);
过去10秒内磁盘IO操作小于200则刷新100个脏页到磁盘。
-
合并至多5个插人缓冲(总是);
在每10秒触发了刷新100脏页到磁盘的动作后,InnoDB存储引擎会合并插入缓冲。
-
将日志缓冲刷新到磁盘(总是);
每10秒操作中合并插入缓冲后,将日志缓冲刷新到磁盘。
-
删除无用的Undo页(总是);
上述操作后,进一步执行full purge操作,删除无用Undo页。对表进行update、delete这类操作时,原先的行被标记为删除,由于一致性要求暂时保留行版本信息。full purge过程中,判断当前事务系统中已被删除的行是否可删除,比如有时候可能在查询操作时需要读取之前版本的undo信息,如果可以删除,InnoDB会立即将其删除。从源代码中可发现,InnoDB存储引擎在执行full purge操作时,每次最多尝试回收20个undo页。
-
刷新100个或者10个脏页到磁盘(总是)
随后,同样判断缓冲池脏页占比是否超过
buf_get_modified_ratio_pct,超过则刷新100个脏页到磁盘,不超过则刷新10%脏页到磁盘。
background loop,若当前没有用户活动(数据库空闲时)活着数据库关闭(shutdown),即切换到该循环。background loop执行以下操作:
- 删除无用的Undo页(总是);
- 合并20个插入缓冲(总是);
- 跳回到主循环(总是);
- 不断刷新100个页直到符合条件(可能,跳转到flush loop中完成)
若 flush loop中也没有什么事情可以做了, InnoDB存储引擎会切换到 suspend loop,将 Master Thread挂起,等待事件的发生。若用户启用(enable)了InnoDB存储引擎,却没有使用任何 InnoDB存储引擎的表,那么Master Thread总是处于挂起的状态。
2.5.2 InnoDB 1.2.x 版本之前的Master Thread
innodb_io_capacity
由于早期hard coding,即使磁盘能够在1秒内处理多于100个页的写入和20个插入缓冲的合并,Master Thread仍只会选择刷新100个脏页和合并20个插入缓冲。此时若发生宕机,由于很多数据没有刷新回磁盘,会导致恢复的时间较久,尤其是对于insert buffer来说。
InnoDB Plugin(从InnoDB 1.0.x版本开始)提供了参数innodb_io_capacity,用来表示磁盘IO的吞吐量(默认值200)。
- 在合并插入缓冲时,合并插入缓冲的数量为
innodb_io_capacity值的5% - 在从缓冲区刷新脏页时,刷新脏页的数量为
innodb_io_capacity
若使用SSD类的磁盘或RAID磁盘阵列,存储设备拥有更高的IO速度,可以调高innodb_io_capacity的值。
innodb_max_dirty_pages_pct
innodb_max_dirty_pages_pct在InnoDB 1.0.x版本之前,默认值90,当脏页占据缓冲池90%,才会刷新100个脏页。如果有很大的内存活着数据库服务器的压力很大,这时刷新脏页的速度反而会降低。从InnoDB 1.0.x版本开始,innodb_max_dirty_pages_pct默认值变为75,加快刷新脏页的频率并保证磁盘IO的负载。
innodb_adaptive_flushing
随着innodb_adaptive_flushing参数的引入,InnoDB存储引擎会通过buf_flush_get_desired_flush_rate函数来判断需要刷新脏页最合适的数量。(buf_flush_get_desired_flush_rate通过判断产生重做日志redo log的速度来决定最合适的刷新脏页数量)。此时,即使脏页的比例小于innodb_max_dirty_pages_pct,也会刷新一定量的脏页。
innodb_purge_batch_size
InnoDB 1.0.x版本引入innodb_purge_batch_size参数,控制每次full purge回收的Undo页数量(默认值20,可动态修改)。
从InnoDB 1.0.x开始,通过命令SHOW ENGINE INNODB STATUS可查看当前Master Thread的状态信息。
2.5.3 InnoDB 1.2.x版本的Master Thread
InnoDB 1.2.x 再次对Master Thread进行优化。其中刷新脏页的操作,从Master Thread线程分离到一个单独的Page Cleaner Thread。
* 2.6 InnoDB关键特性
InnoDB存储引擎的关键特性包括:
- 插入缓冲(Insert Buffer)
- 两次写(Double Write)
- 自适应哈希索引(Adaptive Hash Index)
- 异步IO(Async IO)
- 刷新邻接页(Flush Neighbor Page)
* 2.6.1 插入缓冲
-
Insert Buffer
InnoDB缓冲池中有Insert Buffer信息,Insert Buffer和数据页一样,也是物理页的组成部分。
对于非聚集索引的插入或更新操作,不是每次直接插入到索引页中,而是先判断插入的非聚集索引页是否在缓冲池中,若在则直接插入;若不在,则先放入一个Insert Buffer对象中,之后以一定的频率和情况进行Insert Buffer和辅助索引页子节点的merge(合并)操作,此时通常能合并多个插入操作(因为在同一个索引页中),大大提高了对非聚集索引插入的性能。
使用Insert Buffer需要同时满足以下两个条件:
- 索引是辅助索引(secondary index)
- 索引不是唯一的(unique)
然而,应用程序进行大量的插入操作,这些数据如果都涉及不唯一的非聚集索引,使用到Insert Buffer。此时MySQL数据库发生宕机,就会有大量的Insert Buffer没有合并到实际的非聚集索引中,数据恢复时间在极端情况下需要几个小时。
辅助索引不能是唯一的,因为在插入缓冲时,数据库并不去查找索引页来判断插入的记录的唯一性。如果去查找肯定又会有离散读取的情况发生,从而导致 Insert Buffer失去了意义。
通过
SHOW ENGINE INNODB STATUS可查看插入缓冲的信息。修改
IBUF_POOL_SIZE_PER_MAX_SIZE限制插入缓冲的大小(设置3表示最大只能使用1/3的缓冲池内存)。 -
Changer Buffer
InnoDB 1.0.x版本开始,引入Change Buffer,可视为Insert Buffer的升级。该版本起,InnoDB可对DML操作——INSERT、DELETE、UPDATE都进行缓冲,分别是Insert Buffer、Delete Buffer、Purge Buffer。
和Insert Buffer一样,Change Buffer适用对象仍是非唯一的辅助索引。
对一条记录进行UPDATE操作可分为两个过程:
- 将记录标记为已删除(Delete Buufer对应这一过程)
- 真正将记录删除(Purge Buffer对应这一过程)
InnoDB存储引擎提供了参数
innodb_change_buffering,用来开启各种Buffer的选项,默认值all。该参数的可选值为:inserts、deletes、purges、changes、all、none。insets、deletes、purge对应前面讨论的3种情况。change表示启用inserts和deletes,all表示启用所有,none表示都不启用。InnoDB 1.2.x版本开始,通过参数
innodb_change_buffer_max_size可控制Change Buffer最大使用内存的数量(默认值25,表示最多使用1/4缓冲池内存空间,该参数最大有效值为50)。 -
Insert Buffer的内部实现
Insert Buffer的数据结构是一棵B+树。MySQL4.1之前,每张表有一颗Insert Buffer B+树。后续版本中,全局只有一颗Insert Buffer B+树,负责对所有的表的辅助索引进行Insert Buffer。该B+树存放在共享表空间中,默认也就是ibdata1中。
试图通过独立表空间ibd文件恢复表中数据时,往往会导致CHECK TABLE失败。这是因为表的辅助索引中的数据可能还在 Insert Buffer中,也就是共享表空间中,所以通过ibd文件进行恢复后,还需要进行REPAIR TABLE操作来重建表上所有的辅助索引。
Insert Buffer是一棵B+树,因此其也由叶节点和非叶节点组成。非叶节点存放的是查询的 search key(键值),其构造如图2-3所示。

search key一共占用9个字节,其中 space表示待插入记录所在表的表空间id,在Innodb存储引擎中,每个表有一个唯一的space id,可以通过space id查询得知是哪张表。space占用4字节。marker占用1字节,它是用来兼容老版本的 Insert Buffer。offset表示页所在的偏移量,占用4字节。
当一个辅助索引要插入到页(space,offset)时,如果这个页不在缓冲池中,那么InnoDB存储引擎首先根据上述规则构造一个search key,接下来查询Insert Buffer这棵B+树,然后再将这条记录插入到Insert Buffer B+树的叶子节点中。
对于插入到Insert Buffer B+树叶子节点的记录(如图2-4所示),并不是直接将待插入的记录插入,而是需要根据如下的规则进行构造:

space、marker、page_no字段和之前非叶节点中的含义相同,一共占用9字节。第4个字段metadata占用4字节,其存储的内容如表2-2所示。

IBUF_REC_OFFSET_COUNT是保存两个字节的整数,用来排序每个记录进入Insert Buffer的顺序。因为从InnoDB1.0.x开始支持Change Buffer,所以这个值同样记录进入Insert Buffer的顺序。通过这个顺序回放(replay)才能得到记录的正确值。
从Insert Buffer叶子节点的第5列开始,就是实际插入记录的各个字段了。因此较之原插入记录,Insert Buffer B+树的叶子节点记录需要额外13字节的开销。
因为启用Insert Buffer索引后,辅助索引页(space,page_no)中的记录可能被插入到Insert Buffer B+树中,所以为了保证每次Merge Insert Buffer页必须成功,还需要有一个特殊的页用来标记每个辅助索引页(space,page_no)的可用空间。这个页的类型为Insert Buffer Bitmap。
每个Insert Buffer Bitmap页用来追踪16384个辅助索引页,也就是256个区(Extent)。每个Insert Buffer Bitmap页都在16384个页的第二个页中。关于Insert Buffer Bitmap页的作用会在下一小节中详细介绍。
每个辅助索引页在Insert Buffer Bitmap页中占用4位(bit),由表2-3中的三个部分组成。

-
Merge Insert Buffer
概括地说,Merge Insert Buffer的操作可能发生在以下几种情况下:
-
辅助索引页被读取到缓冲池时;
-
Insert Buffer Bitmap页追踪到该辅助索引页已无可用空间时;
-
Master Thread。
第一种情况为当辅助索引页被读取到缓冲池中时,例如这在执行正常的SELECT查询操作,这时需要检查Insert Buffer Bitmap页,然后确认该辅助索引页是否有记录存放于Insert Buffer B+树中。若有,则将Insert Buffer B+树中该页的记录插入到该辅助索引页中。可以看到对该页多次的记录操作通过一次操作合并到了原有的辅助索引页中,因此性能会有大幅提高。
Insert Buffer Bitmap页用来追踪每个辅助索引页的可用空间,并至少有1/32页的空间。若插入辅助索引记录时检测到插入记录后可用空间会小于1/32页,则会强制进行一个合并操作,即强制读取辅助索引页,将Insert Buffer B+树中该页的记录及待插入的记录插入到辅助索引页中。这就是上述所说的第二种情况。
还有一种情况,之前在分析Master Thread时曾讲到,在Master Thread线程中每秒或每10秒会进行一次Merge Insert Buffer的操作,不同之处在于每次进行merge操作的页的数量不同。
在Master Thread中,执行merge操作的不止是一个页,而是根据srv_innodb_io_capactiy的百分比来决定真正要合并多少个辅助索引页。但InnoDB存储引擎又是根据怎样的算法来得知需要合并的辅助索引页呢?
在Insert Buffer B+树中,辅助索引页根据(space,offset)都已排序好,故可以根据(space,offset)的排序顺序进行页的选择。然而,对于Insert Buffer页的选择,InnoDB存储引擎并非采用这个方式,它随机地选择Insert Buffer B+树的一个页,读取该页中的space及之后所需要数量的页。该算法在复杂情况下应有更好的公平性。同时,若进行merge时,要进行merge的表已经被删除,此时可以直接丢弃已经被Insert/Change Buffer的数据记录。
-
* 2.6.2 两次写
如果说Insert Buffer带给InnoDB存储引擎的是性能上的提升,那么doublewrite(两次写)带给InnoDB存储引擎的是数据页的可靠性。
当发生数据库宕机时,可能InnoDB存储引擎正在写入某个页到表中,而这个页只写了一部分,比如16KB的页,只写了前4KB,之后就发生了宕机,这种情况被称为部分写失效(partial page write)。在InnoDB存储引擎未使用doublewrite技术前,曾经出现过因为部分写失效而导致数据丢失的情况。
有经验的DBA也许会想,如果发生写失效,可以通过重做日志进行恢复。这是一个办法。但是必须清楚地认识到,重做日志中记录的是对页的物理操作,如偏移量800,写’aaaa’记录。如果这个页本身已经发生了损坏,再对其进行重做是没有意义的。这就是说,在应用(apply)重做日志前,用户需要一个页的副本,当写入失效发生时,先通过页的副本来还原该页,再进行重做,这就是doublewrite。在InnoDB存储引擎中doublewrite的体系架构如图2-5所示。

doublewrite由两部分组成,一部分是内存中的doublewrite buffer,大小为2MB,另一部分是物理磁盘上共享表空间中连续的128个页,即2个区(extent),大小同样为2MB。在对缓冲池的脏页进行刷新时,并不直接写磁盘,而是会通过memcpy函数将脏页先复制到内存中的doublewrite buffer,之后通过doublewrite buffer再分两次,每次1MB顺序地写入共享表空间的物理磁盘上,然后马上调用fsync函数,同步磁盘,避免缓冲写带来的问题。在这个过程中,因为doublewrite页是连续的,因此这个过程是顺序写的,开销并不是很大。在完成doublewrite页的写入后,再将doublewrite buffer中的页写入各个表空间文件中,此时的写入则是离散的。
如果操作系统在将页写入磁盘的过程中发生了崩溃,在恢复过程中,InnoDB存储引擎可以从共享表空间中的doublewrite中找到该页的一个副本,将其复制到表空间文件,再应用重做日志。
参数skip_innodb_doublewrite可以禁止使用doublewrite功能,这时可能会发生前面提及的写失效问题。不过如果用户有多个从服务器(slave server),需要提供较快的性能(如在slaves erver上做的是RAID0),也许启用这个参数是一个办法。不过对于需要提供数据高可靠性的主服务器(master server),任何时候用户都应确保开启doublewrite功能。
注意:有些文件系统本身就提供了部分写失效的防范机制,如ZFS文件系统。在这种情况下,用户就不要启用doublewrite了。
* 2.6.3 自适应哈希索引
哈希(hash)是一种非常快的查找方法,在一般情况下这种查找的时间复杂度为O(1),即一般仅需要一次查找就能定位数据。而B+树的查找次数,取决于B+树的高度,在生产环境中,B+树的高度一般为3~4层,故需要3~4次的查询。
InnoDB存储引擎会监控对表上各索引页的查询。如果观察到建立哈希索引可以带来速度提升,则建立哈希索引,称之为自适应哈希索引(Adaptive Hash Index,AHI)。AHI是通过缓冲池的B+树页构造而来,因此建立的速度很快,而且不需要对整张表构建哈希索引。InnoDB存储引擎会自动根据访问的频率和模式来自动地为某些热点页建立哈希索引。
AHI有一个要求,即对这个页的连续访问模式必须是一样的。例如对于(a,b)这样的联合索引页,其访问模式可以是以下情况:
-
WHERE a=xxx
-
WHERE a=xxx and b=xxx
访问模式一样指的是查询的条件一样,若交替进行上述两种查询,那么InonDB存储引擎不会对该页构造AHI。此外AHI还有如下的要求:
- 以该模式访问了100次
- 页通过该模式访问了N次,其中N=页中记录*1/16
根据InnoDB存储引擎官方的文档显示,启用AHI后,读取和写入速度可以提高2倍,辅助索引的连接操作性能可以提高5倍。毫无疑问,AHI是非常好的优化模式,其设计思想是数据库自优化的(self-tuning),即无需DBA对数据库进行人为调整。
通过命令SHOW ENGINE INNODB STATUS可以看到当前AHI的使用状况。
值得注意的是,哈希索引只能用来搜索等值的查询,如SELECT*FROM table WHERE index_col=‘xxx’。而对于其他查找类型,如范围查找,是不能使用哈希索引的。
AHI是由InnoDB存储引擎控制的。用户可以通过观察SHOW ENGINE INNODB STATUS的结果及参数innodb_adaptive_hash_index来考虑是禁用或启动此特性,默认AHI为开启状态。
2.6.4 异步IO
为了提高磁盘操作性能,当前的数据库系统都采用异步IO(Asynchronous IO,AIO)的方式来处理磁盘操作。InnoDB存储引擎亦是如此。
一次SQL查询包括扫描索引页、数据页等操作,每个操作一般需要多次IO,AIO能够一次发起多个IO请求,最后在统一整合IO响应结果。另外AIO能够进行IO Merge操作,将几个请求访问地址连续的IO请求合并成一个,提高IOPS性能。
在InnoDB1.1.x之前,AIO的实现通过InnoDB存储引擎中的代码来模拟实现。而从InnoDB 1.1.x开始(InnoDB Plugin不支持),提供了内核级别AIO的支持,称为Native AIO(Mac OS不支持)。因此在编译或者运行该版本MySQL时,需要libaio库的支持。
参数
innodb_use_native_aio用来控制是否启用Native AIO,在Linux操作系统下,默认值为ON。用户可以通过开启和关闭Native AIO功能来比较InnoDB性能的提升。官方的测试显示,启用Native AIO,恢复速度可以提高75%。
在InnoDB存储引擎中,read ahead方式的读取都是通过AIO完成,脏页的刷新,即磁盘的写入操作则全部由AIO完成。
2.6.5 刷新邻接页
InnoDB存储引擎还提供了Flush Neighbor Page(刷新邻接页)的特性。其工作原理为:当刷新一个脏页时,InnoDB存储引擎会检测该页所在区(extent)的所有页,如果是脏页,那么一起进行刷新。这样做的好处显而易见,通过AIO可以将多个IO写入操作合并为一个IO操作,故该工作机制在传统机械磁盘下有着显著的优势。但是需要考虑到下面两个问题:
-
是不是可能将不怎么脏的页进行了写入,而该页之后又会很快变成脏页?
-
固态硬盘有着较高的IOPS,是否还需要这个特性?
为此,InnoDB存储引擎从1.2.x版本开始提供了参数innodb_flush_neighbors,用来控制是否启用该特性。对于传统机械硬盘建议启用该特性,而对于固态硬盘有着超高IOPS性能的磁盘,则建议将该参数设置为0,即关闭此特性。
2.7 启动、关闭与恢复
在关闭时,参数innodb_fast_shutdown影响着表的存储引擎为InnoDB的行为。该参数可取值为0、1、2,默认值为1。
- 0表示在MySQL数据库关闭时,InnoDB需要完成所有的full purge和merge insert buffer,并且将所有的脏页刷新回磁盘。这需要一些时间,有时甚至需要几个小时来完成。如果在进行InnoDB升级时,必须将这个参数调为0,然后再关闭数据库。
- 1是参数
innodb_fast_shutdown的默认值,表示不需要完成上述的full purge和merge insert buffer操作,但是在缓冲池中的一些数据脏页还是会刷新回磁盘。 - 2表示不完成full purge和merge insert buffer操作,也不将缓冲池中的数据脏页写回磁盘,而是将日志都写入日志文件。这样不会有任何事务的丢失,但是下次MySQL数据库启动时,会进行恢复操作(recovery)。
当正常关闭MySQL数据库时,下次的启动应该会非常“正常”。但是如果没有正常地关闭数据库,如用kill命令关闭数据库,在MySQL数据库运行中重启了服务器,或者在关闭数据库时,将参数innodb_fast_shutdown设为了2时,下次MySQL数据库启动时都会对InnoDB存储引擎的表进行恢复操作。
参数innodb_force_recovery影响了整个InnoDB存储引擎恢复的状况。该参数值默认为0,代表当发生需要恢复时,进行所有的恢复操作,当不能进行有效恢复时,如数据页发生了corruption,MySQL数据库可能发生宕机(crash),并把错误写入错误日志中去。
但是,在某些情况下,可能并不需要进行完整的恢复操作,因为用户自己知道怎么进行恢复。比如在对一个表进行alter table操作时发生意外了,数据库重启时会对InnoDB表进行回滚操作,对于一个大表来说这需要很长时间,可能是几个小时。这时用户可以自行进行恢复,如可以把表删除,从备份中重新导入数据到表,可能这些操作的速度要远远快于回滚操作。
参数innodb_force_recovery还可以设置为6个非零值:1~6。大的数字表示包含了前面所有小数字表示的影响。具体情况如下:
- 1(SRV_FORCE_IGNORE_CORRUPT):忽略检查到的corrupt页。
- 2(SRV_FORCE_NO_BACKGROUND):阻止Master Thread线程的运行,如Master Thread线程需要进行full purge操作,而这会导致crash。
- 3(SRV_FORCE_NO_TRX_UNDO):不进行事务的回滚操作。
- 4(SRV_FORCE_NO_IBUF_MERGE):不进行插入缓冲的合并操作。
- 5(SRV_FORCE_NO_UNDO_LOG_SCAN):不查看撤销日志(Undo Log),InnoDB存储引擎会将未提交的事务视为已提交。
- 6(SRV_FORCE_NO_LOG_REDO):不进行前滚的操作。
需要注意的是,在设置了参数innodb_force_recovery大于0后,用户可以对表进行select、create和drop操作,但insert、update和delete这类DML操作是不允许的。
2.8 小结
- InnoDB存储引擎及其体系结构
- InnoDB存储引擎的关键特性
- 启动和关闭MYSQL时一些配置文件参数对InnoDB存储引擎的影响
第3章开始介绍 MYSQL的文件,包括 My SQL本身的文件和与InnoDB存储引擎本身有关的文件。之后本书将介绍基于InnoDB存储引擎的表,并揭示内部的存储构造。
3. 文件
本章将分析构成MySQL数据库和InnoDB存储引擎表的各种类型文件。这些文件有以下这些。
- 参数文件:告诉MySQL实例启动时在哪里可以找到数据库文件,并且指定某些初始化参数,这些参数定义了某种内存结构的大小等设置,还会介绍各种参数的类型。
- 日志文件:用来记录MySQL实例对某种条件做出响应时写入的文件,如错误日志文件、二进制日志文件、慢查询日志文件、查询日志文件等。
- socket文件:当用UNIX域套接字方式进行连接时需要的文件。
- pid文件:MySQL实例的进程ID文件。
- MySQL表结构文件:用来存放MySQL表结构定义文件。
- 存储引擎文件:因为MySQL表存储引擎的关系,每个存储引擎都会有自己的文件来保存各种数据。这些存储引擎真正存储了记录和索引等数据。本章主要介绍与InnoDB有关的存储引擎文件。
3.1 参数文件
MySQL实例启动时,数据库会按照一定的顺序读取配置文件,用户可通过命令mysql--help | grep my.cnf来寻找。
3.1.1 什么是参数
可以通过命令SHOW VARIABLES查看数据库中的所有参数,也可以通过LIKE来过滤参数名。从MySQL 5.1版本开始,还可以通过information_schema架构下的GLOBAL_VARIABLES视图来进行查找。
3.1.2 参数类型
MySQL数据库中的参数可以分为两类:
- 动态(dynamic)参数
- 静态(static)参数
动态参数意味着可以在MySQL实例运行中进行更改,静态参数说明在整个实例生命周期内都不得进行更改,就好像是只读(read only)的。可以通过SET命令对动态的参数值进行修改,SET的语法如下:
SET
| [global | session] system_var_name= expr
| [@@global. | @@session. | @@]system_var_name= expr
这里可以看到global和session关键字,它们表明该参数的修改是基于当前会话还是整个实例的生命周期。有些动态参数只能在会话中进行修改,如autocommit;而有些参数修改完后,在整个实例生命周期中都会生效,如binlog_cache_size;而有些参数既可以在会话中又可以在整个实例的生命周期内生效,如read_buffer_size。
这次把read_buffer_size全局值更改为1MB,而当前会话的read_buffer_size的值还是512KB。这里需要注意的是,对变量的全局值进行了修改,在这次的实例生命周期内都有效,但MySQL实例本身并不会对参数文件中的该值进行修改。也就是说,在下次启动时MySQL实例还是会读取参数文件。若想在数据库实例下一次启动时该参数还是保留为当前修改的值,那么用户必须去修改参数文件。要想知道MySQL所有动态变量的可修改范围,可以参考MySQL官方手册的Dynamic System Variables的相关内容。
mysql的session、global变量详解_勤天的博客-CSDN博客_mysql session
3.2 日志文件
日志文件记录了影响MySQL数据库的各种类型活动。MySQL数据库中常见的日志文件有:
-
错误日志(error log)
-
二进制日志(binlog)
-
慢查询日志(slow query log)
-
查询日志(log)
这些日志文件可以帮助DBA对MySQL数据库的运行状态进行诊断,从而更好地进行数据库层面的优化。
3.2.1 错误日志
错误日志文件对MySQL的启动、运行、关闭过程进行了记录。MySQL DBA在遇到问题时应该首先查看该文件以便定位问题。该文件不仅记录了所有的错误信息,也记录一些警告信息或正确的信息。用户可以通过命令SHOW VARIABLES LIKE 'log_error’来定位该文件。
当出现MySQL数据库不能正常启动时,第一个必须查找的文件应该就是错误日志文件,该文件记录了错误信息,能很好地指导用户发现问题。
3.2.2 慢查询日志
3.2.1小节提到可以通过错误日志得到一些关于数据库优化的信息,而慢查询日志(slow log)可帮助DBA定位可能存在问题的SQL语句,从而进行SQL语句层面的优化。
在默认情况下,MySQL数据库并不启动慢查询日志,用户需要手工将这个参数设为ON。
另一个和慢查询日志有关的参数是log_queries_not_using_indexes,如果运行的SQL语句没有使用索引,则MySQL数据库同样会将这条SQL语句记录到慢查询日志文件。
MySQL 5.6.5版本开始新增了一个参数log_throttle_queries_not_using_indexes,用来表示每分钟允许记录到slow log的且未使用索引的SQL语句次数。该值默认为0,表示没有限制。在生产环境下,若没有使用索引,此类SQL语句会频繁地被记录到slow log,从而导致slow log文件的大小不断增加,故DBA可通过此参数进行配置。
DBA可以通过慢查询日志来找出有问题的SQL语句,对其进行优化。然而随着MySQL数据库服务器运行时间的增加,可能会有越来越多的SQL查询被记录到了慢查询日志文件中,此时要分析该文件就显得不是那么简单和直观的了。而这时MySQL数据库提供的mysqldumpslow命令,可以很好地帮助DBA解决该问题。
MySQL 5.1开始可以将慢查询的日志记录放入一张表中,这使得用户的查询更加方便和直观。慢查询表在mysql架构下,名为slow_log。
InnoSQL版本加强了对于SQL语句的捕获方式。在原版MySQL的基础上在slow log中增加了对于逻辑读取(logical reads)和物理读取(physical reads)的统计。这里的物理读取是指从磁盘进行IO读取的次数,逻辑读取包含所有的读取,不管是磁盘还是缓冲池。
用户可以通过额外的参数long_query_io将超过指定逻辑IO次数的SQL语句记录到slow log中。该值默认为100,即表示对于逻辑读取次数大于100的SQL语句,记录到slow log中。而为了兼容原MySQL数据库的运行方式,还添加了参数slow_query_type,用来表示启用slow log的方式,可选值为:
- 0表示不将SQL语句记录到slow log
- 1表示根据运行时间将SQL语句记录到slow log
- 2表示根据逻辑IO次数将SQL语句记录到slow log
- 3表示根据运行时间及逻辑IO次数将SQL语句记录到slow log
3.2.3 查询日志
查询日志记录了所有对MySQL数据库请求的信息,无论这些请求是否得到了正确的执行。默认文件名为:主机名.log。
同样地,从MySQL 5.1开始,可以将查询日志的记录放入mysql架构下的general_log表中,该表的使用方法和前面小节提到的slow_log基本一样。
* 3.2.4 二进制日志
二进制日志(binary log)记录了对MySQL数据库执行更改的所有操作,但是不包括SELECT和SHOW这类操作,因为这类操作对数据本身并没有修改。然而,若操作本身并没有导致数据库发生变化,那么该操作可能也会写入二进制日志。
如果用户想记录SELECT和SHOW操作,那只能使用查询日志,而不是二进制日志。此外,二进制日志还包括了执行数据库更改操作的时间等其他额外信息。总的来说,二进制日志主要有以下几种作用。
- 恢复(recovery):某些数据的恢复需要二进制日志,例如,在一个数据库全备文件恢复后,用户可以通过二进制日志进行point-in-time的恢复。
- 复制(replication):其原理与恢复类似,通过复制和执行二进制日志使一台远程的MySQL数据库(一般称为slave或standby)与一台MySQL数据库(一般称为master或primary)进行实时同步。
- 审计(audit):用户可以通过二进制日志中的信息来进行审计,判断是否有对数据库进行注入的攻击。
通过配置参数log-bin[=name]可以启动二进制日志。如果不指定name,则默认二进制日志文件名为主机名,后缀名为二进制日志的序列号,所在路径为数据库所在目录(datadir)。
二进制日志文件在默认情况下并没有启动,需要手动指定参数来启动。可能有人会质疑,开启这个选项是否会对数据库整体性能有所影响。不错,开启这个选项的确会影响性能,但是性能的损失十分有限。根据MySQL官方手册中的测试表明,开启二进制日志会使性能下降1%。但考虑到可以使用复制(replication)和point-in-time的恢复,这些性能损失绝对是可以且应该被接受的。
以下配置文件的参数影响着二进制日志记录的信息和行为:
- max_binlog_size
- binlog_cache_size
- sync_binlog
- binlog-do-db
- binlog-ignore-db
- log-slave-update
- binlog_format
参数max_binlog_size指定了单个二进制日志文件的最大值,如果超过该值,则产生新的二进制日志文件,后缀名+1,并记录到.index文件。从MySQL 5.0开始的默认值为1073741824,代表1G(在之前版本中max_binlog_size默认大小为1.1G)。
当使用事务的表存储引擎(如InnoDB存储引擎)时,所有未提交(uncommitted)的二进制日志会被记录到一个缓存中去,等该事务提交(committed)时直接将缓冲中的二进制日志写入二进制日志文件,而该缓冲的大小由binlog_cache_size决定,默认大小为32K。
此外,**binlog_cache_size是基于会话(session)**的,也就是说,当一个线程开始一个事务时,MySQL会自动分配一个大小为binlog_cache_size的缓存,因此该值的设置需要相当小心,不能设置过大。当一个事务的记录大于设定的binlog_cache_size时,MySQL会把缓冲中的日志写入一个临时文件中,因此该值又不能设得太小。
通过
SHOW GLOBAL STATUS命令查看binlog_cache_use、binlog_cache_disk_use的状态,可以判断当前binlog_cache_size的设置是否合适。Binlog_cache_use记录了使用缓冲写二进制日志的次数,binlog_cache_disk_use记录了使用临时文件写二进制日志的次数。
在默认情况下,二进制日志并不是在每次写的时候同步到磁盘(用户可以理解为缓冲写)。因此,当数据库所在操作系统发生宕机时,可能会有最后一部分数据没有写入二进制日志文件中,这会给恢复和复制带来问题。
参数sync_binlog=[N]表示每写缓冲多少次就同步到磁盘。如果将N设为1,即sync_binlog=1表示采用同步写磁盘的方式来写二进制日志,这时写操作不使用操作系统的缓冲来写二进制日志。sync_binlog的默认值为0,如果使用InnoDB存储引擎进行复制,并且想得到最大的高可用性,建议将该值设为ON。不过该值为ON时,确实会对数据库的IO系统带来一定的影响。
但是,即使将sync_binlog设为1,还是会有一种情况导致问题的发生。当使用InnoDB存储引擎时,在一个事务发出COMMIT动作之前,由于sync_binlog为1,因此会将二进制日志立即写入磁盘。如果这时已经写入了二进制日志,但是提交还没有发生,并且此时发生了宕机,那么在MySQL数据库下次启动时,由于COMMIT操作并没有发生,这个事务会被回滚掉。但是二进制日志已经记录了该事务信息,不能被回滚。这个问题可以通过将参数innodb_support_xa设为1来解决,虽然innodb_support_xa与XA事务有关,但它同时也确保了二进制日志和InnoDB存储引擎数据文件的同步。
参数binlog-do-db和binlog-ignore-db表示需要写入或忽略写入哪些库的日志。默认为空,表示需要同步所有库的日志到二进制日志。
如果当前数据库是复制中的slave角色,则它不会将从master取得并执行的二进制日志写入自己的二进制日志文件中去。如果需要写入,要设置log-slave-update。如果需要搭建master=>slave=>slave架构的复制,则必须设置该参数。
binlog_format参数十分重要,它影响了记录二进制日志的格式。在MySQL 5.1版本之前,没有这个参数。所有二进制文件的格式都是基于SQL语句(statement)级别的,因此基于这个格式的二进制日志文件的复制(Replication)和Oracle 的逻辑Standby有点相似。同时,对于复制是有一定要求的。如在主服务器运行rand、uuid等函数,又或者使用触发器等操作,这些都可能会导致主从服务器上表中数据的不一致(not sync)。另一个影响是,会发现InnoDB存储引擎的默认事务隔离级别是REPEATABLE READ。这其实也是因为二进制日志文件格式的关系,如果使用READ COMMITTED的事务隔离级别(大多数数据库,如Oracle,Microsoft SQL Server数据库的默认隔离级别),会出现类似丢失更新的现象,从而出现主从数据库上的数据不一致。
MySQL 5.1开始引入了binlog_format参数,该参数可设的值有STATEMENT、ROW和MIXED。
(1)STATEMENT格式和之前的MySQL版本一样,二进制日志文件记录的是日志的逻辑SQL语句。
(2)在ROW格式下,二进制日志记录的不再是简单的SQL语句了,而是记录表的行更改情况。基于ROW格式的复制类似于Oracle的物理Standby(当然,还是有些区别)。同时,对上述提及的Statement格式下复制的问题予以解决。从MySQL 5.1版本开始,如果设置了binlog_format为ROW,可以将InnoDB的事务隔离基本设为READ COMMITTED,以获得更好的并发性。
(3)在MIXED格式下,MySQL默认采用STATEMENT格式进行二进制日志文件的记录,但是在一些情况下会使用ROW格式,可能的情况有:
1)表的存储引擎为NDB,这时对表的DML操作都会以ROW格式记录。
2)使用了UUID()、USER()、CURRENT_USER()、FOUND_ROWS()、ROW_COUNT()等不确定函数。
3)使用了INSERT DELAY语句。
4)使用了用户定义函数(UDF)。
5)使用了临时表(temporary table)。
此外,binlog_format参数还有对于存储引擎的限制,如表3-1所示。

binlog_format是动态参数,因此可以在数据库运行环境下进行更改。
当然,也可以将全局的binlog_format设置为想要的格式,不过通常这个操作会带来问题,运行时要确保更改后不会对复制带来影响。
在通常情况下,我们将参数binlog_format设置为ROW,这可以为数据库的恢复和复制带来更好的可靠性。但是不能忽略的一点是,这会带来二进制文件大小的增加,有些语句下的ROW格式可能需要更大的容量。
将参数binlog_format设置为ROW,会对磁盘空间要求有一定的增加。而由于复制是采用传输二进制日志方式实现的,因此复制的网络开销也有所增加。
图书作者在某张17MB大小的表。在
binlog_format='STATEMENT'时执行某UPDATE只增加binlog日志大小约200字节,但是binlog_format='ROW'执行相同UPDATE语句增加13MB大小的日志。因为这时MySQL数据库不再将逻辑的SQL操作记录到二进制日志中,而是记录对于每行的更改。
二进制日志文件的文件格式为二进制(好像有点废话),不能像错误日志文件、慢查询日志文件那样用cat、head、tail等命令来查看。要查看二进制日志文件的内容,必须通过MySQL提供的工具mysqlbinlog。对于STATEMENT格式的二进制日志文件,在使用mysqlbinlog后,看到的就是执行的逻辑SQL语句。
3.3 套接字文件
前面提到过,在UNIX系统下本地连接MySQL可以采用UNIX域套接字方式,这种方式需要一个套接字(socket)文件。套接字文件可由参数socket控制。一般在/tmp目录下,名为mysql.sock。
3.4 pid文件
当MySQL实例启动时,会将自己的进程ID写入一个文件中——该文件即为pid文件。该文件可由参数pid_file控制,默认位于数据库目录下,文件名为主机名.pid。
3.5 表结构定义文件
因为MySQL插件式存储引擎的体系结构的关系,MySQL数据的存储是根据表进行的,每个表都会有与之对应的文件。但不论表采用何种存储引擎,MySQL都有一个以frm为后缀名的文件,这个文件记录了该表的表结构定义。
frm还用来存放视图的定义,如用户创建了一个v_a视图,那么对应地会产生一个v_a.frm文件,用来记录视图的定义,该文件是文本文件,可以直接使用cat命令进行查看。
3.6 InnoDB存储引擎文件
之前介绍的文件都是MySQL数据库本身的文件,和存储引擎无关。除了这些文件外,每个表存储引擎还有其自己独有的文件。本节将具体介绍与InnoDB存储引擎密切相关的文件,这些文件包括重做日志文件、表空间文件。
3.6.1 表空间文件
InnoDB采用将存储的数据按表空间(tablespace)进行存放的设计。在默认配置下会有一个初始大小为10MB,名为ibdata1的文件。该文件就是默认的表空间文件(tablespace file),用户可以通过参数innodb_data_file_path对其进行设置,格式如下:
innodb_data_file_path=datafile_spec1[;datafile_spec2]... 用户可以通过多个文件组成一个表空间,同时制定文件的属性,如:
[mysqld]
innodb_data_file_path = /db/ibdata1:2000M;/dr2/db/ibdata2:2000M:autoextend
这里将/db/ibdata1和/dr2/db/ibdata2两个文件用来组成表空间。若这两个文件位于不同的磁盘上,磁盘的负载可能被平均,因此可以提高数据库的整体性能。同时,两个文件的文件名后都跟了属性,表示文件idbdata1的大小为2000MB,文件ibdata2的大小为2000MB,如果用完了这2000MB,该文件可以自动增长(autoextend)。
设置
innodb_data_file_path参数后,所有基于InnoDB存储引擎的表的数据都会记录到该共享表空间中。若设置了参数innodb_file_per_table,则用户可以将每个基于InnoDB存储引擎的表产生一个独立表空间。独立表空间的命名规则为:表名.ibd。通过这样的方式,用户不用将所有数据都存放于默认的表空间中。
设置innodb_file_per_table=ON时,这些单独的表空间文件仅存储该表的数据、索引和插入缓冲BITMAP等信息,其余信息还是存放在默认的表空间中。图3-1显示了InnoDB存储引擎对于文件的存储方式:

* 3.6.2 重做日志文件
在默认情况下,在InnoDB存储引擎的数据目录下会有两个名为ib_logfile0和ib_logfile1的文件。在MySQL官方手册中将其称为InnoDB存储引擎的日志文件,不过更准确的定义应该是重做日志文件(redo log file)。为什么强调是重做日志文件呢?因为重做日志文件对于InnoDB存储引擎至关重要,它们记录了对于InnoDB存储引擎的事务日志。
当实例或介质失败(media failure)时,重做日志文件就能派上用场。例如,数据库由于所在主机掉电导致实例失败,InnoDB存储引擎会使用重做日志恢复到掉电前的时刻,以此来保证数据的完整性。
每个InnoDB存储引擎至少有1个重做日志文件组(group),每个文件组下至少有2个重做日志文件,如默认的ib_logfile0和ib_logfile1。为了得到更高的可靠性,用户可以设置多个的镜像日志组(mirrored log groups),将不同的文件组放在不同的磁盘上,以此提高重做日志的高可用性。在日志组中每个重做日志文件的大小一致,并以循环写入的方式运行。InnoDB存储引擎先写重做日志文件1,当达到文件的最后时,会切换至重做日志文件2,再当重做日志文件2也被写满时,会再切换到重做日志文件1中。图3-2显示了一个拥有3个重做日志文件的重做日志文件组。

下列参数影响着重做日志文件的属性:
- innodb_log_file_size
- innodb_log_files_in_group
- innodb_mirrored_log_groups
- innodb_log_group_home_dir
参数innodb_log_file_size指定每个重做日志文件的大小。在InnoDB1.2.x版本之前,重做日志文件总的大小不得大于等于4GB,而1.2.x版本将该限制扩大为了512GB。
参数innodb_log_files_in_group指定了日志文件组中重做日志文件的数量,默认为2。
参数innodb_mirrored_log_groups指定了日志镜像文件组的数量,默认为1,表示只有一个日志文件组,没有镜像。若磁盘本身已经做了高可用的方案,如磁盘阵列,那么可以不开启重做日志镜像的功能。
参数innodb_log_group_home_dir指定了日志文件组所在路径,默认为
./,表示在MySQL数据库的数据目录下。
重做日志文件的大小设置对于InnoDB存储引擎的性能有着非常大的影响。一方面重做日志文件不能设置得太大,如果设置得很大,在恢复时可能需要很长的时间;另一方面又不能设置得太小了,否则可能导致一个事务的日志需要多次切换重做日志文件。此外,重做日志文件太小会导致频繁地发生async checkpoint,导致性能的抖动。
重做日志有一个capacity变量,该值代表了最后的检查点不能超过这个阈值,如果超过则必须将缓冲池(innodb buffer pool)中脏页列表(flush list)中的部分脏数据页写回磁盘,这时会导致用户线程的阻塞。
同样是记录事务日志,和二进制日志的区别:
-
首先,二进制日志会记录所有与MySQL数据库有关的日志记录,包括InnoDB、MyISAM、Heap等其他存储引擎的日志。而InnoDB存储引擎的重做日志只记录有关该存储引擎本身的事务日志。
-
其次,记录的内容不同,无论用户将二进制日志文件记录的格式设为STATEMENT还是ROW,又或者是MIXED,其记录的都是关于一个事务的具体操作内容,即该日志是逻辑日志。而InnoDB存储引擎的重做日志文件记录的是关于每个页(Page)的更改的物理情况。
-
此外,写入的时间也不同,二进制日志文件仅在事务提交前进行提交,即只写磁盘一次,不论这时该事务多大。而在事务进行的过程中,却不断有重做日志条目(redo entry)被写入到重做日志文件中。
在InnoDB存储引擎中,对于各种不同的操作有着不同的重做日志格式。到InnoDB 1.2.x版本为止,总共定义了51种重做日志类型。虽然各种重做日志的类型不同,但是它们有着基本的格式,表3-2显示了重做日志条目的结构:

从表3-2可以看到重做日志条目是由4个部分组成:
- redo_log_type占用1字节,表示重做日志的类型
- space表示表空间的ID,但采用压缩的方式,因此占用的空间可能小于4字节
- page_no表示页的偏移量,同样采用压缩的方式
- redo_log_body表示每个重做日志的数据部分,恢复时需要调用相应的函数进行解析
在第2章中已经提到,写入重做日志文件的操作不是直接写,而是先写入一个重做日志缓冲(redo log buffer)中,然后按照一定的条件顺序地写入日志文件。图3-3很好地诠释了重做日志的写入过程。
从重做日志缓冲往磁盘写入时,是按512个字节,也就是一个扇区的大小进行写入。因为扇区是写入的最小单位,因此可以保证写入必定是成功的。因此在重做日志的写入过程中不需要有doublewrite。
前面提到了从日志缓冲写入磁盘上的重做日志文件是按一定条件进行的,那这些条件有哪些呢?
- 第2章分析了主线程(master thread),知道在主线程中每秒会将重做日志缓冲写入磁盘的重做日志文件中,不论事务是否已经提交。
- 另一个触发写磁盘的过程是由参数
innodb_flush_log_at_trx_commit控制,表示在提交(commit)操作时,处理重做日志的方式。
参数
innodb_flush_log_at_trx_commit的有效值有0、1、2。0代表当提交事务时,并不将事务的重做日志写入磁盘上的日志文件,而是等待主线程每秒的刷新。1和2不同的地方在于:1表示在执行commit时将重做日志缓冲同步写到磁盘,即伴有fsync的调用。2表示将重做日志异步写到磁盘,即写到文件系统的缓存中。因此不能完全保证在执行commit时肯定会写入重做日志文件,只是有这个动作发生。
为了保证事务的ACID中的持久性,必须将innodb_flush_log_at_trx_commit设置为1,也就是每当有事务提交时,就必须确保事务都已经写入重做日志文件。那么当数据库因为意外发生宕机时,可以通过重做日志文件恢复,并保证可以恢复已经提交的事务。而将重做日志文件设置为0或2,都有可能发生恢复时部分事务的丢失。不同之处在于,设置为2时,当MySQL数据库发生宕机而操作系统及服务器并没有发生宕机时,由于此时未写入磁盘的事务日志保存在文件系统缓存中,当恢复时同样能保证数据不丢失。
3.7 小结
本章介绍了与MySQL数据库相关的一些文件,并了解了文件可以分为MySQL数据库文件以及与各存储引擎相关的文件。与MySQL数据库有关的文件中,错误文件和二进制日志文件非常重要。当MySQL数据库发生任何错误时,DBA首先就应该去查看错误文件,从文件提示的内容中找出问题的所在。当然,错误文件不仅记录了错误的内容,也记录了警告的信息,通过一些警告也有助于DBA对于数据库和存储引擎进行优化。
二进制日志的作用非常关键,可以用来进行point in time的恢复以及复制(replication)环境的搭建。因此,建议在任何时候时都启用二进制日志的记录。从MySQL 5.1开始,二进制日志支持STATEMENT、ROW、MIX三种格式,这样可以更好地保证从数据库与主数据库之间数据的一致性。当然DBA应该十分清楚这三种不同格式之间的差异。
本章的最后介绍了和InnoDB存储引擎相关的文件,包括表空间文件和重做日志文件。表空间文件是用来管理InnoDB存储引擎的存储,分为共享表空间和独立表空间。重做日志非常的重要,用来记录InnoDB存储引擎的事务日志,也因为重做日志的存在,才使得InnoDB存储引擎可以提供可靠的事务。
4. 表
表的物理存储方式。
4.1 索引组织表
InnoDB存储引擎中,表按照主键顺序组织存放,这种存储方式的表称为索引组织表(index organized table)。InnoDB存储引擎表中,每张表都有主键(Primary Key),如果没有显式定义主键,InnoDB存储引擎会按如下方式选择or创建主键:
- 首先判读表中是否有非空的唯一索引(Unique NOT NULL),如果有,则该列即为主键。
- 如果不符合上述条件,InnoDB存储引擎自动创建一个6字节大小的指针。
当表中有多个非空唯一索引时, InnoDB存储引擎将选择建表时第一个定义的非空唯索引为主键。这里需要非常注意的是,主键的选择根据的是定义索引的顺序,而不是建表时列的顺序。
在单个列为主键的情况下,
_rowid可以显示表的主键值
* 4.2 InnoDB逻辑存储结构
从 InnoDB存储引擎的逻辑存储结构看,所有数据都被逻辑地存放在一个空间中,称之为表空间(tablespace)。表空间又由段(segment)、区(extent)、页(page)组成。页在一些文档中有时也称为块(block), InnoDB存储引擎的逻辑存储结构大致如图4-1所示。

图4-1 InnoDB逻辑存储结构
4.2.1 表空间
表空间可以看做是 Innodb存储引擎逻辑结构的最高层,所有的数据都存放在表空间中。
第3章中已经介绍了在默认情况下 Innodb存储引擎有一个共享表空间 ibdata1,即所有数据都存放在这个表空间内。如果用户启用了参数innodb_file_per_table,则每张表内的数据可以单独放到一个表空间内。
如果启用了
innodb_ file_per_table的参数,需要注意的是每张表的表空间内存放的只是数据、索引和插入缓冲Bitmap页,其他类的数据,如回滚(undo)信息,插入缓冲索引页、系统事务信息,二次写缓冲(Double write buffer)等还是存放在原来的共享表空间内。这同时也说明了另一个问题:即使在启用了参数innodb _file_per_table之后,共享表空间还是会不断地增加其大小。产生undo信息后,即使对事务进行回滚rollback,共享表空间新增的undo信息占用的空间也不会被回收,但是InnoDB会在不需要这些undo信息时,将其占据的空间标记为可用空间,供下次undo使用。
4.2.2 段
图4-1中显示了表空间是由各个段组成的,常见的段有数据段、索引段、回滚段等。因为前面已经介绍过了InnoDB存储引擎表是索引组织的(index organized),因此数据即索引,索引即数据。那么数据段即为B+树的叶子节点(图4-1的Leaf node segment),索引段即为B+树的非索引节点(图4-1的 Non-leaf node segment)。回滚段较为特殊,将会在后面的章节进行单独的介绍。
在 Innodb存储引擎中,对段的管理都是由引擎自身所完成,DBA不能也没有必要对其进行控制。这和 Oracle数据库中的自动段空间管理(ASSM)类似,从一定程度上简化了DBA对于段的管理。
4.2.3 区
区是由连续页组成的空间,在任何情况下每个区的大小都为1MB。为了保证区中页的连续性, InnoDB存储引擎一次从磁盘申请4~5个区。在默认情况下, InnoDB存储引擎页的大小为16KB,即一个区中一共有64个连续的页。
InnoDB1.0.x版本开始引人压缩页,即每个页的大小可以通过参数
KEY_BLOCKSIZE设置为2K、4K、8K,因此每个区对应页的数量就应该为512、256、128。InnoDB1.2.x版本新增了参数
innodb_page_size,通过该参数可以将默认页的大小设置为4K、8K,但是页中的数据库不是压缩。这时区中页的数量同样也为256、128。总之,不论页的大小怎么变化,区的大小总是为1M。
但是,这里还有这样一个问题:在用户启用了参数innodb file_per_tabe后,创建的表默认大小是96KB。区中是64个连续的页,创建的表的大小至少是1MB才对啊?其实这是因为在每个段开始时,先用32个页大小的碎片页(fragment page)来存放数据,在使用完这些页之后才是64个连续页的申请。这样做的目的是,对于一些小表,或者是undo这类的段,可以在开始时申请较少的空间,节省磁盘容量的开销。
4.2.4 页
同大多数数据库一样, InnoDB有页(Page)的概念(也可以称为块),页是InnoDB磁盘管理的最小单位。在Innodb存储引擎中,默认每个页的大小为16KB。而从InnoDB 1.2.x版本开始,可以通过参数innodb_page_size将页的大小设置为4K、8K、16K。若设置完成,则所有表中页的大小都为innodb_page_size,不可以对其再次进行修改。除非通过 mysqldump导入和导出操作来产生新的库。
在 InnoDB存储引擎中,常见的页类型有:
- 数据页(B-tree Node)
- undo页(undo Log Page)
- 系统页(System Page)
- 事务数据页(Transaction system Page)
- 插入缓冲位图页(Insert Buffer Bitmap)
- 插入缓冲空闲列表页(Insert Buffer Free List)
- 未压缩的二进制大对象页(Uncompressed BLOB Page)
- 压缩的二进制大对象页(compressed BLOB Page)
* 4.2.5 行
InnoDB存储引擎是面向行的(row-oriented),也就说数据是按行进行存放的。每个页存放的行记录也是有硬性定义的,最多允许存放16KB/2-200行的记录,即7992行记录。这里提到了row-oriented的数据库,也就是说,存在有column-oriented的数据库。MySQL infobright存储引擎就是按列来存放数据的,这对于数据仓库下的分析类SQL语句的执行及数据压缩非常有帮助。类似的数据库还有 Sybase IQ、 Google Big Table。面向列的数据库是当前数据库发展的一个方向,但这超出了本书涵盖的内容,有兴趣的读者可以在网上寻找相关资料。
* 4.3 InnoDB行记录格式
InnoDB存储引檠和大多数数据库一样(如 Oracle和 Microsoft SQL Server数据库),记录是以行的形式存储的。这意味着页中保存着表中一行行的数据。
在 InnoDB 1.0.x版本之前, InnoDB存储引擎提供了 Compact和 Redundant两种格式来存放行记录数据,这也是目前使用最多的一种格式。 Redundant格式是为兼容之前版本而保留的,如果阅读过 InnoDB的源代码,用户会发现源代码中是用 PHYSICAL RECORD (NEW STYLE)和 PHYSICAL RECORD (OLD STYLE)来区分两种格式的。
在 MYSQL5.1版本中,默认设置为 Compact 行格式。用户可以通过命令 SHOW TABLE STATUS LIKE 'tablename’来査看当前表使用的行格式,其中 row_format 属性表示当前所使用的行记录结构类型。
* 4.3.1 Compact 行记录格式
Compact行记录是在 MySQL5.0 中引入的,其设计目标是高效地存储数据。简单来说一个页中存放的行数据越多,其性能就越高。图4-2显示了 Compact行记录的存储方式:

图4-2 Compact 行记录的格式
从图4-2 可以观察到, Compact 行记录格式的首部是一个非NULL 变长字段长度列表,并且其是按照列的顺序逆序放置的,其长度为:
-
若列的长度小于255 字节,用1字节表示;
-
若大于255个字节,用2字节表示。
变长字段的长度最大不可以超过2字节,这是因在MySQL数据库中VARCHAR类型的最大长度限制为65535 。变长字段之后的第二个部分是NULL 标志位,该位指示了该行数据中是否有NULL 值,有则用1 表示。该部分所占的字节应该为1 字节。接下来的部分是记录头信息(record header) ,固定占用5 字节(40 位),每位的含义见表4-1 。
表4-1 Compact 记录头信息

最后的部分就是实际存储每个列的数据。需要特别注意的是, NULL 不占该部分任何空间,即NULL 除了占有NULL 标志位,实际存储不占有任何空间。另外有一点需要注意的是,每行数据除了用户定义的列外,还有两个隐藏列,事务ID 列和回滚指针列,分别为6 字节和7 字节的大小。若InnoDB 表没有定义主键,每行还会增加一个6 字节的rowid 列。
不管是CHAR类型还是VARCHAR类型,在compact格式下,NULL值都不占用任何存储空间。
* 4.3.2 Redundant行记录格式
Redundant 是MySQL5.0 版本之前InnoDB 的行记录存储方式, MySQL5.0 支持Redundant 是为了兼容之前版本的页格式。Redundant 行记录采用如图4-3 所示的方式存储。

从图4-3 可以看到,不同于Compact 行记录格式, Redundant 行记录格式的首部是一个字段长度偏移列表,同样是按照列的顺序逆序放置的。若列的长度小于255 字节,用1 字节表示:若大于255 字节,用2 字节表示。
第二个部分为记录头信息(recordheader) ,不同于Compact 行记录格式, Redundant 行记录格式的记录头占用6 字节(48位),每位的含义见表4-2 。从表4-2 中可以发现, n_fields 值代表一行中列的数扯,占用10 位。同时这也很好地解释了为什么MySQL 数据库一行支持最多的列为1023 。另一个需要注意的值为1byte_offs_ flags ,该值定义了偏移列表占用1字节还是2字节。而最后的部分就是实际存储的每个列的数据了。

对于VARCHAR类型的NULL值,Redudant行记录格式同样不会占用任何存储空间,而CHAR类型的NULL值需要占用空间。
当表的字符集为Latin1, 每个字符最多只占用1 字节。若用户将表的字符集转换为utf8,CHAR字段固定长度类型将占用原本的
字节数*3大小的字节数。在Redundant 行记录格式下, CHAR 类型将会占用可能存放的最大值字节数。
* 4.3.3 行溢出数据
InnoDB 存储引擎可以将一条记录中的某些数据存储在真正的数据页面之外。
一般认为BLOB 、LOB 这类的大对象列类型的存储会把数据存放在数据页面之外。但是,这个理解有点偏差, BLOB 可以不将数据放在溢出页面,而且即便是VARCHAR 列数据类型,依然有可能被存放为行溢出数据。
首先对VARCHAR 数据类型进行研究。很多DBA 喜欢MySQL 数据库提供的VARCHAR 类型,因为相对于Oracle VARCHAR2 最大存放4000 字节, SQL Server 最大存放8000 字节, MySQL 数据库的VARCHAR 类型可以存放65535 字节。
但是,这是真的吗?真的可以存放65535 字节吗?如果创建VARCHAR 长度为65535 的表,用户会得到下面的错误信息:
mysql> CREATE TABLE test (
-> a VARCHAR(65535)
->)CHARSET=latinl ENGINE=InnoDB;
ERROR 1118 (42000): Row size too large. The maximum row size for the used table
type, not counting BLOBs, is 65535. You have to change some columns to TEXT or
BLOBS 从错误消息可以看到lnnoDB 存储引擎并不支持65535 长度的VARCHAR。这是因为还有别的开销,通过实际测试发现能存放VARCHAR 类型的最大长度为65532 。例如,按下面的命令创建表就不会报错了。
mysql> CREATE TABLE test (
-> a VARCHAR(65532)
->)CHARSET=latinl ENGINE=InnoDB;
Query OK, 0 rows affected (0.15 sec) 需要注意的是,如果在执行上述示例的时候没有将SQL_MODE设为严格模式,或许可以建立表,但是MySQL 数据库会抛出一个warning,如:
mysql> CREATE TABLE test (
-> a VARCHAR(65535)
->)CHARSET=latinl ENGINE=InnoDB;
Query OK, 0 rows affected, 1 warning (0.14 sec)mysql> SHOW WARNINGS\G;
*************************** 1. row***************************
Level: Note
Code: 124 6
Message: Converting column'a'from VARCHAR to TEXT
1 row in set (0.00 sec)warning 信息提示了这次可以创建是因为MySQL 数据库自动地将VARCHAR 类型转换成了TEXT 类型。查看test 的表结构会发现:
mysql> SHOW CREATE TABLE test\G;
*************************** 1. row***************************
Table: test
Create Table: CREATE TABLE'test'(
'a'mediumtext
ENGINE=InnoDB DEFAULT CHARSET=utf8
1 row in set (0.00 sec) 还需要注意上述创建的VARCHAR 长度为65 532 的表,其字符类型是latinl 的,如果换成GBK 又或UTF-8 的,会产生怎样的结果呢?
mysql> CREATE TABLE test (
-> a VARCHAR(65532)
->)CHARSET=GBK ENGINE=InnoDB;
ERROR 1074 (42000): Column length too big for column'a'(max = 32767); use
BLOB or TEXT insteadrnysql> mysql> CREATE TABLE test (
-> a VARCHAR(65532)
->)CHARSET=UTF8 ENGINE=InnoDB;
ERROR 1074 (42000): 这次即使创建列的VARCHAR 长度为65532,也会提示报错,但是两次报错对max值的提示是不同的。因此从这个例子中用户也应该理解VARCHAR (N) 中的N 指的是字符的长度。而文档中说明VARCHAR 类型最大支待65535,单位是字节。
此外需要注意的是, MySQL 官方手册中定义的65535 长度是指所有VARCHAR列的长度总和,如果列的长度总和超出这个长度,依然无法创建,如下所示:
mysql> CREATE TABLE test2
-> a VARCHAR(22000),
-> b VARCHAR(22000),
-> c VARCHAR(22000)
->)CHARSET=latinl ENGINE=InnoDB;
ERROR 1118 (42000): Row size too large. The maximum row size for the used table
type, not counting BLOBs, is 65535. You have to change some columns to TEXT or
BLOBS 3 个列长度总和是66000, 因此InnoDB 存储引擎再次报了同样的错误。
即使能存放65532 个字节,但是有没有想过, InnoDB 存储引擎的页为16KB, 即16384 字节,怎么能存放65532 字节呢?在一般情况下, InnoDB 存储引擎的数据都是存放在页类型为B-tree node 中。但是当发生行溢出时,数据存放在页类型为Uncompress BLOB 页中。
对于行溢出数据,其存放采用图4-4的方式。数据页面其实只保存了VARCHAR (65532)的前768 字节的前缀(prefix) 数据(举例这里都是a) ,之后是偏移量,指向行溢出页,也就是前面用户看到的Uncompressed BLOB Page。

那多长的VARCHAR 是保存在单个数据页中的,从多长开始又会保存在BLOB页呢?可以这样进行思考: InnoDB 存储引擎表是索引组织的,即B+Tree 的结构,这样每个页中至少应该有两条行记录(否则失去了B+Tree 的意义,变成链表了)。因此,如果页中只能存放下一条记录,那么InnoDB 存储引擎会自动将行数据存放到溢出页中。
但是,如果可以在一个页中至少放入两行数据,那VARCHAR 类型的行数据就不会存放到BLOB 页中去。经过多次试验测试,发现这个阔值的长度为8098。
另一个问题是,对于TEXT 或BLOB 的数据类型,用户总是以为它们是存放在Uncompressed BLOB Page 中的,其实这也是不准确的。(TEXT或BLOB数据类型)是放在数据页中还是BLOB 页中,和前面讨论的VARCHAR 一样,至少保证一个页能存放两条记录。
当然既然用户使用了BLOB 列类型,一般不可能存放长度较小的数据。因此在大多数的情况下BLOB 的行数据还是会发生行溢出,实际数据保存在BLOB 页中,数据页只保存数据的前768 字节。
* 4.3.4 Compressed 和Dynamic 行记录格式
InnoDB 1.0.x 版本开始引入了新的文件格式(file format, 用户可以理解为新的页格式),以前支持的Compact 和Redundant 格式称为Antelope 文件格式,新的文件格式称为Barracuda文件格式。Barracuda 文件格式下拥有两种新的行记录格式: Compressed 和Dynamic。
新的两种记录格式对千存放在BLOB 中的数据采用了完全的行溢出的方式,如图4-5 所示,在数据页中只存放20 个字节的指针,实际的数据都存放在Off Page 中,而之前的Compact 和Redundant 两种格式会存放768 个前缀字节。

Compressed 行记录格式的另一个功能就是,存储在其中的行数据会以zlib 的算法进行压缩,因此对于BLOB 、TEXT 、VARCHAR 这类大长度类型的数据能够进行非常有效的存储。
* 4.3.5 CHAR 的行结构存储
通常理解VARCHAR 是存储变长长度的字符类型, CHAR 是存储固定长度的字符类型。而在前面的小节中,用户已经了解行结构的内部的存储,并可以发现每行的变长字段长度的列表都没有存储CHAR 类型的长度。
从MySQL4.l 版本开始, CHR(N) 中的N 指的是字符的长度,而不是之前版本的字节长度。也就说在不同的字符集下, CHAR 类型列内部存储的可能不是定长的数据。
对于多字节字符编码的CHAR 数据类型的存储, lnnoDB 存储引擎在内部将其视为变长字符类型。这也就意味着在变长长度列表中会记录CHAR数据类型的长度。此时,CHAR 类型被明确视为了变长字符类型,对于未能占满长度的字符还是填充0x20。
InnoDB 存储引擎内部对字符的存储和我们用HEX函数看到的也是一致的。因此可以认为在多字节字符集的情况下, CHAR 和VARCHAR 的实际行存储基本是没有区别的。
4.4 lnnoDB 数据页结构
页是InnoDB存储引擎管理数据库的最小磁盘单位。页类型为B-tree Node的页存放的即是表中行的实际数据。
InnoDB数据页由以下7个部分组成,如图4-6所示。
-
File Header (文件头)
-
Page Header (页头)
-
Infimun 和Supremum Records
-
User Records (用户记录,即行记录)
-
Free Space (空闲空间)
-
Page Directory (页目录)
-
File Trailer (文件结尾信息)
其中File Header、Page Header、File Trailer 的大小是固定的,分别为38 、56 、8字节,这些空间用来标记该页的一些信息,如Checksum,数据页所在B+树索引的层数等。User Records 、Free Space、Page Directory 这些部分为实际的行记录存储空间,因此大小是动态的。

图4-6 InnoDB 存储引擎数据页结构
4.4.1 File Header
File Header用来记录页的一些头信息,由表4-3中8个部分组成,共占用38 字节。
表4-3 File Header 组成部分
| 名称 | 大小(字节) | 说明 |
|---|---|---|
| FIL_PAGE_SPACE_OR_CHKSUM | 4 | 当MySQL 为MySQL4.0.14 之前的版本时,该值为0。在之后的MySQL版本中,该值代表页的checksum 值(一种新的checksum 值) |
| FIL_PAGE_OFFSET | 4 | 表空间中页的偏移值。如某独立表空间a.ibd的大小为1GB,如果页的大小为16KB,那么总共有65536 个页。FIL_PAGE_OFFSET表示该页在所有页中的位置。若此表空间的ID 为10,那么搜索页(10,1) 就表示查找表a 中的第二个页 |
| FIL_PAGE_PREV | 4 | 当前页的上一个页, B+Tree 特性决定了叶子节点必须是双向列表 |
| FIL_PAGE_NEXT | 4 | 当前页的下一个页, B+Tree 特性决定了叶子节点必须是双向列表 |
| FIL_PAGE_LSN | 8 | 该值代表该页最后被修改的日志序列位置LSN (Log Sequence Number) |
| FIL_PAGE_TYPE | 2 | lnnoDB 存储引擎页的类型。常见的类型见表4-4。记住0x45BF,该值代表了存放的是数据页,即实际行记录的存储空间 |
| FIL_PAGE_FILE_FLUSH_LSN | 8 | 该值仅在系统表空间的一个页中定义,代表文件至少被更新到了该LSN值。对于独立表空间,该值都为0 |
| FIL_PAGE_ARCH_LOG_NO_OR_SPACE_ID | 4 | 从MySQL4.1 开始,该值代表页属于哪个表空间 |
表4-4 lnnoDB 存储引擎中页的类型
| 名称 | 十六进制 | 解释 |
|---|---|---|
| FIL_PAGE_INDEX | 0x45BF | B+树叶节点 |
| FIL_PAGE_UNDO_LOG | 0x0002 | Undo Log 页 |
| FIL_PAGE_INODE | 0x0003 | 索引节点 |
| FIL_PAGE_IBUF_FREE_LIST | 0x0004 | Insert Buffer 空闲列表 |
| FIL_PAGE_TYPE_ALLOCATED | 0x0000 | 该页为最新分配 |
| FIL_PAGE_IBUF_BITMAP | 0x0005 | Insert Buffer 位图 |
| FIL_PAGE_TYPE_SYS | 0x0006 | 系统页 |
| FIL_PAGE_TYPE_TRX_SYS | 0x0007 | 事务系统数据 |
| FIL_PAGE_TYPE_FSP_HOR | 0x0008 | File Space Header |
| FIL_PAGE_TYPE_XDES | 0x0009 | 扩展描述页 |
| FIL_PAGE_TYPE_BLOB | 0x000A | BLOB 页 |
4.4.2 Page Header
接着File Header 部分的是Page Header,该部分用来记录数据页的状态信息,由14 个部分组成,共占用56 字节,如表4-5 所示。
表4-5 Page Header 组成部分
| 名称 | 大小(字节) | 说明 |
|---|---|---|
| PAGE_N_DIR_SLOTS | 2 | 在 Page Directory(页目录)中的Slot(槽)数,“4.4.5 Page Directory”小节中会介绍 |
| PAGE_HEAP_TOP | 2 | 堆中第一个记录的指针,记录在页中是根据堆的形式存放的 |
| PAGE_N_HEAP | 2 | 堆中的记录数。一共占用2字节,但是第15位表示行记录格式 |
| PAGE_FREE | 2 | 指向可重用空间的首指针 |
| PAGE_GARBAGE | 2 | 已删除记录的字节数,即行记录结构中 delete flag为1的记录大小的总数 |
| PAGE_LAST_INSERT | 2 | 最后插入记录的位置 |
| PAGE_DIRECTION | 2 | 最后插入的方向。可能的取值为: PAGE_LEFT (0x01) PAGE_RIGHT (0x02) PAGE_SAME_REO (0x03) PAGE_SAME_PAGE (0x04) PAGE_NO_DIRECTION (0x05) |
| PAGE_N_DIRECTION | 2 | 一个方向连续插入记录的数量 |
| PAGE_NRECS | 2 | 该页中记录的数量 |
| PAGE_MAX_TRX_ID | 8 | 修改当前页的最大事务ID,注意该值仅在 Secondary Index中定义 |
| PAGE_LEVEL | 2 | 当前页在索引树中的位置,0x00代表叶节点,即叶节点总是在第0层 |
| PAGE_INDEX_ID | 8 | 索引ID,表示当前页属于哪个索引 |
| PAGE_BTR_SEG_LEAF | 10 | B+树数据页非叶节点所在段的 segment header。注意该值仅在B+树的 Root页中定义 |
| PAGE_BTR_SEG_TOP | 10 | B+树数据页所在段的 segment header。注意该值仅在B+树的 Root页中定义 |
* 4.4.3 lnfimum和Supremum Record
在InnoDB 存储引擎中,每个数据页中有两个虚拟的行记录,用来限定记录的边界。Infimum 记录是比该页中任何主键值都要小的值, Supremum 指比任何可能大的值还要大的值。这两个值在页创建时被建立,并且在任何情况下不会被删除。在Compact行格式和Redundant 行格式下,两者占用的字节数各不相同。图4-7 显示了Infimum 和Supremum 记录。

4.4.4 User Record和Free Space
User Record 就是之前讨论过的部分,即实际存储行记录的内容。再次强调, InnoDB存储引擎表总是B+树索引组织的。
Free Space 很明显指的就是空闲空间,同样也是个链表数据结构。在一条记录被删除后,该空间会被加入到空闲链表中。
* 4.4.5 Page Directory
Page Directory (页目录)中存放了记录的相对位置(注意,这里存放的是页相对位置,而不是偏移量),有些时候这些记录指针称为Slots(槽)或目录槽(Directory Slots) 。与其他数据库系统不同的是,在lnnoDB 中并不是每个记录拥有一个槽,InnoDB存储引擎的槽是一个稀疏目录(sparse directory),即一个槽中可能包含多个记录。伪记录lnfimum 的n_owned 值总是为1,记录Supremum的n_owned 的取值范围为[1, 8],其他用户记录n_owned的取值范围为[4,8] 。当记录被插入或删除时需要对槽进行分裂或平衡的维护操作。
在 Slots中记录按照索引键值顺序存放,这样可以利用二叉查找迅速找到记录的指针。假设有(‘i’,‘d’,‘c’,‘b’,‘e’,‘g’,‘l’,‘h’,'f",‘j’,‘k’,‘a’),同时假设一个槽中包含4条记录,则 Slots中的记录可能是(‘a’,‘e’,‘i’)
由于在InnoDB 存储引擎中Page Direcotry 是稀疏目录,二叉查找的结果只是一个粗略的结果,因此InnoDB 存储引擎必须通过recorder header 中的next_record 来继续查找相关记录。同时, Page Directory 很好地解释了recorder header 中的n_owned 值的含义,因为这些记录并不包括在Page Directory 中。
需要牢记的是, B+树索引本身并不能找到具体的一条记录,能找到只是该记录所在的页。数据库把页载入到内存,然后通过Page Directory 再进行二叉查找。只不过二叉查找的时间复杂度很低,同时在内存中的查找很快,因此通常忽略这部分查找所用的时间。
4.4.6 File Trailer
为了检测页是否已经完整地写入磁盘(如可能发生的写人过程中磁盘损坏、机器关机等), lnnoDB 存储引擎的页中设置了File Trailer部分。
File Trailer 只有一个FIL_PAGE_END_LSN 部分,占用8 字节。前4 字节代表该页的checksum 值,最后4 字节和File Header 中的FIL_PAGE_ LSN 相同。将这两个值与File Header 中的FIL_PAGE_SPACE_OR_ CHKSUM 和FIL_PAGE_LSN 值进行比较,看是否一致(checksum 的比较需要通过InnoDB 的checksum 函数来进行比较,不是简单的等值比较),以此来保证页的完整性(not corrupted) 。
在默认配置下, InnoDB 存储引擎每次从磁盘读取一个页就会检测该页的完整性,即页是否发生Corrupt,这就是通过File Trailer 部分进行检测,而该部分的检测会有一定的开销。用户可以通过参数innodb_ checksums 来开启或关闭对这个页完整性的检查。
MySQL 5.6.6 版本开始新增了参数innodb_checksum_ algorithm,该参数用来控制检测checksum 函数的算法,默认值为crc32, 可设置的值有: innodb 、crc32 、none 、strict_innodb 、strict_crc32 、strict_none 。
innodb 为兼容之前版本InnoDB 页的checksum 检测方式, crc32 为MySQL 5.6.6 版本引进的新的checksum 算法,该算法较之前的innodb 有着较高的性能。但是若表中所有页的checksum 值都以strict 算法保存,那么低版本的MySQL 数据库将不能读取这些页。none 表示不对页启用checksum 检查。
strict_*正如其名,表示严格地按照设置的checksum 算法进行页的检测。因此若低版本MySQL 数据库升级到MySQL 5.6.6 或之后的版本,启用strict_crc32 将导致不能读取表中的页。启用strict_crc32 方式是最快的方式,因为其不再对innodb 和crc32 算法进行两次检测。故推荐使用该设置。若数据库从低版本升级而来,则需要进行mysql_upgrade 操作。
4.4.7 lnnoDB 数据页结构示例分析
4.5 Named File Formats机制
从lnnoDB 1.0.x 版本开始, InnoDB 存储引通过Named File Formats 机制来解决不同版本下页结构兼容性的问题。
InnoDB 存储引擎将1.0.x 版本之前的文件格式(file format) 定义为Antelope,将这个版本支持的文件格式定义为Barracuda 。新的文件格式总是包含于之前的版本的页格式。图4-8 显示了Barracuda 文件格式和Antelope 文件格式之间的关系, Antelope 文件格式有Compact 和Redudant 的行格式, Barracuda 文件格式既包括了Antelope 所有的文件格式,另外新加入了之前已经提到过的Compressed 和Dynamic 行格式。

4.6 约束
4.6.1 数据完整性
关系型数据库系统和文件系统的一个不同点是,关系数据库本身能保证存储数据的完整性,不需要应用程序的控制,而文件系统一般需要在程序端进行控制。当前几乎所有的关系型数据库都提供了约束(constraint) 机制,该机制提供了一条强大而简易的途径来保证数据库中数据的完整性。一般来说,数据完整性有以下三种形式:
实体完整性保证表中有一个主键。在InnoDB 存储引照表中,用户可以通过定义Primary Key 或Unique Key 约束来保证实体的完整性。用户还可以通过编写一个触发器来保证数据完整性。
域完整性保证数据每列的值满足特定的条件。在InnoDB 存储引擎表中,域完整性可以通过以下几种途径来保证:
- 选择合适的数据类型确保一个数据值满足特定条件。
- 外键(Foreign Key) 约束。
- 编写触发器。
- 还可以考虑用DEFAULT 约束作为强制域完整性的一个方面。
参照完整性保证两张表之间的关系。InnoDB 存储引擎支持外键,因此允许用户定义外键以强制参照完整性,也可以通过编写触发器以强制执行。
对于InnoDB 存储引擎本身而言,提供了以下几种约束:
-
Primary Key
-
Unique Key
-
Foreign Key
-
Default
-
NOT NULL
4.6.2 约束的创建和查找
约束的创建可以采用以下两种方式:
-
表建立时就进行约束定义
-
利用ALTER TABLE 命令来进行创建约束
4.6.3 约束和索引的区别
约束更是一个逻辑的概念,用来保证数据的完整性,而索引是一个数据结构,既有逻辑上的概念,在数据库中还代表着物理存储的方式。
4.6.4 对错误数据的约束
在某些默认设置下, MySQL 数据库允许非法的或不正确的数据的插入或更新,又或者可以在数据库内部将其转化为一个合法的值,如向NOT NULL 的字段插入一个NULL值, MySQL 数据库会将其更改为0 再进行插入,因此数据库本身没有对数据的正确性进行约束。
如果用户想通过约束对于数据库非法数据的插入或更新,即MySQL数据库提示报错而不是警告,那么用户必须设置参数sql_mode, 用来严格审核输入的参数。
4.6.5 ENUM 和SET 约束
MySQL 数据库不支持传统的CHECK 约束,但是通过ENUM 和SET 类型可以解决部分这样的约束需求。(如果想实现CHECK 约束,还需要配合设置参数sql_mode)
对于传统CHECK 约束支持的连续值的范围约束或更复杂的约束, ENUM 和SET 类型还是无能为力,这时用户需要通过触发器来实现对千值域的约束。
* 4.6.6 触发器与约束
触发器的作用是在执行INSERT 、DELETE 和UPDATE 命令之前或之后自动调用SQL 命令或存储过程。MySQL 5.0 对触发器的实现还不是非常完善,限制比较多,而从MySQL 5.1 开始触发器已经相对稳定,功能也较之前有了大幅的提高。
创建触发器的命令是CREATE TRIGGER,只有具备Super 权限的MySQL 数据库用户才可以执行这条命令。
最多可以为一个表建立6 个触发器,即分别为INSERT 、UPDATE 、DELETE 的BEFORE 和AFTER 各定义一个。BEFORE 和AFTER 代表触发器发生的时间,表示是在每行操作的之前发生还是之后发生。当前MySQL 数据库只支持FOR EACH ROW 的触发方式,即按每行记录进行触发,不支持像DB2 的FOR EACH STATEMENT 的触发方式。
4.6.7 外键约束
外键用来保证参照完整性, MySQL 数据库的MyISAM 存储引擎本身并不支持外键,对于外键的定义只是起到一个注释的作用。而InnoDB 存储引擎则完整支持外键约束。
用户可以在执行CREATE TABLE 时就添加外键,也可以在表创建后通过ALTER TABLE 命令来添加
一般来说,称被引用的表为父表,引用的表称为子表。外键定义时的ON DELETE和ON UPDATE 表示在对父表进行DELETE 和UPDATE 操作时,对子表所做的操作,可定义的子表操作有:
-
CASCADE
CASCADE 表示当父表发生DELETE 或UPDATE 操作时,对相应的子表中的数据也进行DELETE 或UPDATE 操作。
-
SET NULL
SET NULL 表示当父表发生DELETE 或UPDATE操作时,相应的子表中的数据被更新为NULL 值,但是子表中相对应的列必须允许为NULL 值。
-
NO ACTION
NO ACTION 表示当父表发生DELETE 或UPDATE 操作时,抛出错误,不允许这类操作发生。
-
RESTRICT
RESTRICT 表示当父表发生DELETE 或UPDATE 操作时,抛出错误,不允许这类操作发生。如果定义外键时没有指定ON DELETE 或ON UPDATE,RESTRICT 就是默认的外键设置。
InnoDB 存储引擎在外键建立时会自动地对该列加一个索引,这和Microsoft SQL Server数据库的做法一样。因此可以很好地避免外键列上无索引而导致的死锁问题的产生。
对于参照完整性约束,外键能起到一个非常好的作用。但是对于数据的导入操作时,外键往往导致在外键约束的检查上花费大量时间。因为MySQL 数据库的外键是即时检查的,所以对导入的每一行都会进行外键检查。
用户可以在导入过程中忽视外键的检查,如:
mysql> SET foreign_key_checks = 0;mysql> LOAD DATA......mysql> SET foreign_key_checks = l;
4.7 视图
在MySQL 数据库中,视图(View) 是一个命名的虚表,它由一个SQL 查询来定义,可以当做表使用。与持久表(permanent table) 不同的是,视图中的数据没有实际的物理存储。
4.7.1 视图的作用
视图在数据库中发挥着重要的作用。视图的主要用途之一是被用做一个抽象装置,特别是对于一些应用程序,程序本身不需要关心基表(base table) 的结构,只需要按照视图定义来取数据或更新数据,因此,视图同时在一定程度上起到一个安全层的作用。
MySQL 数据库从5.0 版本开始支持视图,创建视图的语法如下:
CREATE
[OR REPLACE)
[ALGORITHM = {UNDEFINED | MERGE | TEMPTABLE)]
(DEFINER = { user | CURRENT_USER })
[ SQL SECURITY { DEFINER | INVOKER })
VIEW view_name [ (column_list) ]
AS select_statement
[WITH [CASCADED | LOCAL] CHECK OPTION] 虽然视图是基于基表的一个虚拟表,但是用户可以对某些视图进行更新操作,其本质就是通过视图的定义来更新基本表。一般称可以进行更新操作的视图为可更新视图(updatable view) 。视图定义中的WITH CHECK OPTION 就是针对于可更新的视图的,即更新的值是否需要检查。
-
SHOW TABLES命令会返回所有的表和视图(虚拟表)。 -
如果只想要查询基表,可以使用如下SQL:
SELECT * FROM information_schema.TABLES WHERE table_type = 'BASE TABLE' AND table_schema = database()\G; -
查看视图的元数据(meta data),可通过如下SQL:
SELECT * FROM information_schema.VIEWS WHERE table_schema = database()\G;
* 4.7.2 物化视图
Oracle 数据库支持物化视图该视图不是基于基表的虚表,而是根据基表实际存在的实表,即物化视图的数据存储在非易失的存储设备上。物化视图可以用于预先计算并保存多表的链接(JOIN) 或聚集(GROUP BY) 等耗时较多的SQL 操作结果。这样,在执行复杂查询时,就可以避免进行这些耗时的操作,从而快速得到结果。物化视图的好处是对于一些复杂的统计类查询能直接查出结果。在Microsoft SQL Server 数据库中,称这种视图为索引视图。
在Oracle 数据库中,物化视图的创建方式包括以下两种:
-
BUILD IMMEDIATE
默认的创建方式,在创建物化视图的时候就生成数据
-
BUILD DEFERRED
在创建物化视图时不生成数据,以后根据需要再生成数据
查询重写是指当对物化视图的基表进行查询时,数据库会自动判断能否通过查询物化视图来直接得到最终的结果,如果可以,则避免了聚集或连接等这类较为复杂的SQL操作,直接从已经计算好的物化视图中得到所需的数据。
物化视图的刷新是指当基表发生了DML操作后,物化视图何时采用哪种方式和基表进行同步。刷新的模式有两种:
-
ON DEMAND
在用户需要的时候进行刷新
-
ON COMMIT
在对基表的DML操作提交的同时进行刷新
而刷新的方法有四种:
-
FAST
增量刷新,只刷新自上次刷新以后进行的修改
-
COMPLETE
对整个物化视图进行完全的刷新
-
FORCE
数据库在刷新时会去判断是否可以进行快速刷新,如果可以,则采用FAST 方式,否则采用COMPLETE 的方式
-
NEVER
不进行任何刷新
MySQL 数据库本身并不支持物化视图,换句话说, MySQL 数据库中的视图总是虚拟的。但是用户可以通过一些机制来实现物化视图的功能。例如要创建一个ON DEMAND 的物化视图还是比较简单的,用户只需定时把数据导入到另一张表。
通过触发器,在MySQL 数据库可以实现类似物化视图的功能。但是MySQL 数据库本身并不支持物化视图,因此对于物化视图支持的查询重写(Query Rewrite) 功能就显得无能为力,用户只能在应用程序端做一些控制。
ps:具体步骤可以看原书代码
4.8 分区表
* 4.8.1 分区概述
一文彻底搞懂MySQL分区_民工哥博客的技术博客_51CTO博客
分区功能并不是在存储引擎层完成的,因此不是只有lnnoDB 存储引擎支持分区,常见的存储引擎MylSAM 、NDB 等都支持。但也并不是所有的存储引擎都支持,如CSV 、FEDORATED 、MERGE 等就不支持。在使用分区功能前,应该对选择的存储引擎对分区的支持有所了解。
MySQL 数据库在5.1版本时添加了对分区的支持。分区的过程是将一个表或索引分解为多个更小、更可管理的部分。就访问数据库的应用而言,从逻辑上讲,只有一个表或一个索引,但是在物理上这个表或索引可能由数十个物理分区组成。每个分区都是独立的对象,可以独自处理,也可以作为—个更大对象的一部分进行处理。
MySQL 数据库支持的分区类型为水平分区,并不支持垂直分区。此外, MySQL数据库的分区是局部分区索引,一个分区中既存放了数据又存放了索引。而全局分区是指,数据存放在各个分区中,但是所有数据的索引放在一个对象中。目前, MySQL 数据库还不支持全局分区。
- 水平分区:指将同一表中不同行的记录分配到不同的物理文件中
- 垂直分区:指将同一表中不同列的记录分配到不同的物理文件中
可以通过以下命令来查看当前数据库是否启用了分区功能:
SHOW VARIABLES LIKE '%partition%'\G; 也可以通过命令SHOW PLUGINS 来查看:
SHOW PLUGINS\G; 大多数DBA 会有这样一个误区:只要启用了分区,数据库就会运行得更快。这个结论是存在很多问题的。就我的经验看来,分区可能会给某些SQL 语句性能带来提高,但是分区主要用于数据库高可用性的管理。在OLTP 应用中,对于分区的使用应该非常小心。总之,如果只是一味地使用分区,而不理解分区是如何工作的,也不清楚你的应用如何使用分区,那么分区极有可能会对性能产生负面的影响。
当前MySQL 数据库支持以下几种类型的分区:
- RANGE 分区:行数据基于属于一个给定连续区间的列值被放入分区。MySQL5.5开始支待RANGE COLUMNS 的分区。
- LIST 分区:和RANGE 分区类似,只是LIST 分区面向的是离散的值。MySQL5.5开始支持LIST COLUMNS 的分区。
- HASH 分区:根据用户自定义的表达式的返回值来进行分区,返回值不能为负数。
- KEY 分区:根据MySQL 数据库提供的哈希函数来进行分区。
不论创建何种类型的分区,如果表中存在主键或唯一索引时,分区列必须是唯一索引的一个组成部分。
唯一索引可以是允许NULL 值的,并且分区列只要是唯一索引的一个组成部分,不需要整个唯一索引列都是分区列。
* 4.8.2 分区类型
-
查看表在磁盘上的物理文件,启用分区之后,表不再由一个ibd 文件组成了,而是由建立分区时的各个分区ibd 文件组成,如:
t#P#p0.ibd,t#P#p1.ibd。 -
可以通过查询information_schema架构下的PARTITIONS表来查看每个分区的具体信息。
-
通过EXPLAIN PARTITION命令可以查看指令执行的逻辑。如果查询命中特定的分区,就不需要查询所有的分区——称为Partition Pruning(分区修剪)。
-
在用INSERT 插入多个行数据的过程中遇到分区未定义的值时, MyISAM 和InnoDB 存储引擎的处理完全不同。MyISAM 引擎会将之前的行数据都插入,但之后的数据不会被插入。而lnnoDB 存储引擎将其视为一个事务,因此没有任何数据插入。在使用分区时,需要对不同存储引擎支持的事务特性进行考虑。
-
RANGE 分区
最常用的一种分区类型。
下面的CREATE TABLE 语句创建了一个id 列的区间分区表。当id 小于10 时,数据插入p0分区。当id 大于等于10 小于20 时,数据插入p1分区。
CREATE TABLE t(id INT ) ENGINE=INNDB PARTITION BY RANGE (id) (PARTITION pO VALUES LESS THAN (10),PARTITION pl VALUES LESS THAN (20));RANGE 分区主要用于日期列的分区,例如对于销售类的表,可以根据年来分区存放销售记录。
对于RANGE 分区的查询,优化器只能对
YEAR(),TO_DAYS(),TO_SECONDS(),UNIX_TIMESTAMP()这类函数进行优化选择。 -
LIST 分区
LIST 分区和RANGE 分区非常相似,只是分区列的值是离散的,而非连续的。如:
mysql> CREATE TABLE t ( -> a INT, -> b INT) ENGINE=INNODB -> PARTITION BY LIST(b) ( -> PARTITION p0 VALUES IN (1,3,5,7,9), -> PARTITION p1 VALUES IN (0,2,4,6,8) ->); Query OK, 0 rows affected (0.26 sec)不同于RANGE 分区中定义的VALUES LESS THAN 语句, LIST 分区使用VALUES IN 。因为每个分区的值是离散的,因此只能定义值。
-
HASH 分区
HASH分区的目的是将数据均匀地分布到预先定义的各个分区中,保证各分区的数据数量大致都是一样的。在RANGE 和LIST 分区中,必须明确指定一个给定的列值或列值集合应该保存在哪个分区中;而在HASH 分区中, MySQL 自动完成这些工作,用户所要做的只是基于将要进行哈希分区的列值指定一个列值或表达式,以及指定被分区的表将要被分割成的分区数量。
要使用HASH 分区来分割一个表,要在CREATE TABLE 语句上添加一个**“PARTITION BY HASH (expr)“** 子句,其中“expr” 是一个返回一个整数的表达式。它可以仅仅是字段类型为 MySQL整型的列名。此外,用户很可能需要在后面再添加一个 **“PARTITIONS num“**子句,其中num是一个非负的整数,它表示表将要被分割成分区的数量。如果没有包括一个PARTITIONS 子句,那么分区的数量将默认为1。
MOD(YEAR('2010-04-01'), 4) =MOD(2010,4) =2 MySQL 数据库还支持一种称为LINEAR HASH 的分区,它使用一个更加复杂的算法来确定新行插入到已经分区的表中的位置。它的语法和HASH分区的语法相似,只是将关键字HASH改为LINEAR HASH。
LINEAR HASH 分区的优点在于,增加、删除、合并和拆分分区将变得更加快捷,这有利于处理含有大量数据的表。它的缺点在于,与使用HASH 分区得到的数据分布相比,各个分区间数据的分布可能不大均衡。
-
取大于分区数矗4 的下一个2 的幕值V, V=POWER(2, CEILING(LOG(2,num)))=4;
-
所在分区N=YEAR(‘2010-04-01’)&(V-1)=2 。
-
-
KEY分区
KEY 分区和HASH 分区相似,不同之处在于HASH 分区使用用户定义的函数进行分区, KEY 分区使用MySQL 数据库提供的函数进行分区。对于NDB Cluster 引擎,MySQL 数据库使用MD5 函数来分区;对于其他存储引擎, MySQL 数据库使用其内部的哈希函数,这些函数基千与PASSWORD()一样的运算法则。
在KEY 分区中使用关键字LINEAR 和在HASH 分区中使用具有同样的效果,分区的编号是通过2的幕(powers-of-two) 算法得到的,而不是通过模数算法。
-
COLUMNS分区
在前面介绍的RANGE 、LIST 、HASH 和KEY 这四种分区中,分区的条件是:数据必须是整型(interger) ,如果不是整型,那应该需要通过函数将其转化为整型,如YEAR(), TO_DAYS(), MONTH()等函数。
MySQL5.5 版本开始支持COLUMNS 分区,可视为RANGE 分区和LIST 分区的一种进化。COLUMNS 分区可以直接使用非整型的数据进行分区,分区根据类型直接比较而得,不需要转化为整型。此外, RANGE COLUMNS 分区可以对多个列的值进行分区。
COLUMNS 分区支持以下的数据类型:
- 所有的整型类型,如INT、SM凡.,LINT、TINYINT、BIGINT。FLOAT 和DECIMAL则不予支持。
- 日期类型,如DATE 和DATETIME。其余的日期类型不予支持。
- 字符串类型,如CHAR 、VARClfAR 、BINARY 和VARBINARY。BLOB 和TEXT类型不予支持。
MySQL5.5 开始支持COLUMNS 分区,对于之前的RANGE 和LIST 分区,用户可以用RANGE COLUMNS 和LIST COLUMNS 分区进行很好的代替。
4.8.3 子分区
子分区(subpartitioning) 是在分区的基础上再进行分区,有时也称这种分区为复合分区(composite partitioning) 。
MySQL 数据库允许在RANGE 和LIST 的分区上再进行HASH 或KEY 的子分区。
可以通过使用SUBPARTITION 语法来显式地指出各个子分区的名字。
子分区的建立需要注意以下几个问题:
-
每个子分区的数量必须相同。
-
要在一个分区表的任何分区上使用SUBPARTITION 来明确定义任何子分区,就必须定义所有的子分区。
-
每个SUBPARTITION 子句必须包括子分区的一个名字。
-
子分区的名字必须是唯一的。
子分区可以用于特别大的表,在多个磁盘间分别分配数据和索引。
由于lnnoDB 存储引擎使用表空间自动地进行数据和索引的管理,因此会忽略DATA DIRECTORY 和INDEX DIRECTORY 语法。
* 4.8.4 分区中的NULL值
MySQL 数据库允许对NULL 值做分区,但是处理的方法与其他数据库可能完全不同。MYSQL 数据库的分区总是视NULL 值视小于任何的一个非NULL 值,这和MySQL 数据库中处理NULL 值的ORDER BY 操作是一样的。因此对于不同的分区类型, MySQL 数据库对于NULL 值的处理也是各不相同。
-
对于RANGE 分区,如果向分区列插入了NULL 值,则MySQL 数据库会将该值放入最左边的分区。
-
在LIST 分区下要使用NULL 值,则必须显式地指出哪个分区中放入NULL 值,否则会报错。
-
HASH 和KEY 分区对于NULL 的处理方式和RANGE 分区、LIST 分区不一样。任何分区函数都会将含有NULL 值的记录返回为0。
* 4.8.5 分区和性能
-
对于OLAP 的应用,分区的确是可以很好地提高查询的性能,因为OLAP 应用大多数查询需要频繁地扫描一张很大的表。假设有一张1 亿行的表,其中有一个时间戳屈性列。用户的查询需要从这张表中获取一年的数据。如果按时间戳进行分区,则只需要扫描相应的分区即可。这就是前面介绍的Partition Pruning 技术。
-
对于OLTP 的应用,分区应该非常小心。在这种应用下,通常不可能会获取一张大表中10%的数据,大部分都是通过索引返回几条记录即可。而根据B+树索引的原理可知,对于一张大表,一般的B+树需要2~3 次的磁盘IO 。因此B+树可以很好地完成操作,不需要分区的帮助,并且设计不好的分区会带来严重的性能问题。
很多开发团队会认为含有1000W 行的表是一张非常巨大的表,所以他们往往会选择采用分区,如对主键做10 个HASH 的分区,这样每个分区就只有100W 的数据了,因此查询应该变得更快了,如SELECT * FROM TABLE WHERE PK=@pk 。但是有没有考虑过这样一种情况:100W 和1000W 行的数据本身构成的B+树的层次都是一样的,可能都是2 层。那么上述走主键分区的索引并不会带来性能的提高。好的,如果1000W 的B+树的高度是3, IOOW 的B+树的高度是2, 那么上述按主键分区的索引可以避免1 次IO ,从而提高查询的效率。这没问题,但是这张表只有主键索引,没有任何其他的列需要查询的。如果还有类似如下的SQL 语句: SELECT * FROM TABLE WHERE KEY=@key, 这时对于KEY 的查询需要扫描所有的10 个分区,即使每个分区的查询开销为2 次IO, 则一共需要20 次IO 。而对于原来单表的设计, 对于KEY的查询只需要2~3 次IO 。
注意:即使是根据自增长主键进行的HASH 分区也不能保证分区数据的均匀。因为插入的自增长ID 并非总是连续的,如果该主键值因为某种原因被回滚了,则该值将不会再次被自动使用。
对于使用InnoDB 存储引擎作为OLTP 应用的表在使用分区时应该十分小心,设计时确认数据的访问模式,否则在OLTP 应用下分区可能不仅不会带来查询速度的提高,反而可能会使你的应用执行得更慢。
* 4.8.6 在表和分区间交换数据
MySQL5.6 开始支持ALTER TABLE … EXCHANGE PARTITION语法。该语句允许分区或子分区中的数据与另一个非分区的表中的数据进行交换。
- 如果非分区表中的数据为空,那么相当于将分区中的数据移动到非分区表中。
- 若分区表中的数据为空,则相当于将外部表中的数据导入到分区中。
要使用ALTER TABLE … EXCHANGE PARTITION语句,必须满足下面的条件:
- 要交换的表需和分区表有着相同的表结构,但是表不能含有分区
- 在非分区表中的数据必须在交换的分区定义内
- 被交换的表中不能含有外键,或者其他的表含有对该表的外键引用
- 用户除了需要ALTER、INSERT 和CREATE 权限外,还需要DROP 的权限
此外,有两个小的细节需要注意:
-
使用该语句时,不会触发交换表和被交换表上的触发器
-
AUTO_INCREMENT 列将被重置
4.9 小结
- lnnoDB 存储引擎表总是按照主键索引顺序进行存放的
- 表的物理实现(如行结构和页结构)
- 和表有关的约束问题, MySQL 数据库通过约束来保证表中数据的各种完整性,其中也提到了有关InnoDB 存储引擎支持的外键特性
- 视图,在MySQL 数据库中视图总是虚拟的表,本身不支持物化视图。但是通过一些其他的技巧(如触发器)同样也可以实现一些简单的物化视图的功能
- 分区, MySQL 数据库支持RANGE 、LIST 、HASH 、KEY 、COLUMNS分区,并且可以使用HASH 或KEY 来进行子分区。需要注意的是,分区并不总是适合于OLTP 应用,用户应该根据自己的应用好好来规划自己的分区设计
5. 索引与算法
这一章的主旨是对InnoDB 存储引擎支持的索引做一个概述,并对索引内部的机制做一个深人的解析,通过了解索引内部构造来了解哪里可以使用索引。本章的风格和别的有关MySQL 的书有所不同,更偏重于索引内部的实现和算法问题的讨论。
* 5.1 lnnoDB 存储引擎索引概述
InnoDB 存储引擎支持以下几种常见的索引:
- B+树索引
- 全文索引
- 哈希索引
前面已经提到过, lnnoDB 存储引擎支持的哈希索引是自适应的, lnnoDB 存储引擎会根据表的使用情况自动为表生成哈希索引,不能人为干预是否在一张表中生成哈希索引。
B+树索引就是传统意义上的索引,这是目前关系型数据库系统中查找最为常用和最为有效的索引。B+树索引的构造类似于二叉树,根据键值(Key Value) 快速找到数据。
注意:B+树中的B不是代表二叉(binary), 而是代表平衡(balance) ,因为B+树是从最早的平衡二叉树演化而来,但是B+树不是一个二叉树。
另一个常常被DBA 忽视的问题是: B+树索引并不能找到一个给定键值的具体行。B+树索引能找到的只是被查找数据行所在的页。然后数据库通过把页读入到内存,再在内存中进行查找,最后得到要查找的数据。
5.2 数据结构与算法
B+树索引是最为常见,也是在数据库中使用最为频繁的一种索引。
5.2.1 二分查找法
二分查找法(binary search) 也称为折半查找法,用来查找一组有序的记录数组中的某一记录,其基本思想是:将记录按有序化(递增或递减)排列,在查找过程中采用跳跃式方式查找,即先以有序数列的中点位置为比较对象,如果要找的元素值小于该中点元素,则将待查序列缩小为左半部分,否则为右半部分。通过一次比较,将查找区间缩小一半。
如有5 、10 、19 、21 、31 、37 、42 、48 、50 、52 这10 个数,现要从这10 个数中查找48 这条记录,其查找过程如图5-1 所示。

图5-1 二分查找法
从图5-1 可以看出,用了3 次就找到了48 这个数。如果是顺序查找,则需要8次。因此二分查找法的效率比顺序查找法要好(平均地来说)。但如果说查5这条记录,顺序查找只需1次,而二分查找法需要4次。我们来看,对于上面10 个数来说,平均查找次数为(1+2+3+4+5+6+7+8+9+10) /10=5.5 次。而二分查找法为(4+3+2+4+3+1+4+3+2+3)/10=2.9 次。在最坏的情况下,顺序查找的次数为10,而二分查找的次数为4 。
二分查找法的应用极其广泛,而且它的思想易于理解。第一个二分查找法在1946年就出现了,但是第一个完全正确的二分查找法直到1962 年才出现。
在前面的章节中,相信读者已经知道了,每页Page Directory 中的槽是按照主键的顺序存放的。对于某一条具体记录的查询是通过对Page Directory 进行二分查找得到的。(见 4.4.5 Page Directory)
5.2.2 二叉查找树和平衡二叉树
在介绍B+树前,需要先了解一下二叉查找树。B+树是通过二叉查找树,再由平衡二叉树, B 树演化而来。相信在任何一本有关数据结构的书中都可以找到二叉查找树的章节,二叉查找树是一种经典的数据结构。图5-2 显示了一棵二叉查找树。

图5-2 二叉查找树
图5-2 中的数字代表每个节点的键值,在二叉查找树中,左子树的键值总是小于根的键值,右子树的键值总是大于根的键值。因此可以通过中序遍历得到键值的排序输出,图5-2 的二叉查找树经过中序遍历后输出: 2 、3 、5 、6 、7 、8 。
对图5-2 的这棵二叉树进行查找,如查键值为5 的记录,先找到根,其键值是6, 6 大于5, 因此查找6 的左子树,找到3; 而5 大于3, 再找其右子树;一共找了3 次。如果按2 、3 、5 、6 、7 、8 的顺序来找同样需要3 次。用同样的方法再查找键值为8 的这个记录,这次用了3 次查找,而顺序查找需要6 次。计算平均查找次数可得:顺序查找的平均查找次数为(1+2+3+4+5+6)/6=3.3 次,二叉查找树的平均查找次数为(3+3+3+2+2+1)/6=2.3次。二叉查找树的平均查找速度比顺序查找来得更快。
二叉查找树可以任意地构造,同样是2 、3 、5 、6 、7 、8 这五个数字,也可以按照图5-3的方式建立二叉查找树。

图5-3 效率较低的一棵二叉查找树
图5-3 的平均查找次数为(1+2+3+4+5+5) /6=3.16 次,和顺序查找差不多。显然这棵二叉查找树的查询效率就低了。因此若想最大性能地构造一棵二叉查找树,需要这棵二叉查找树是平衡的,从而引出了新的定义——平衡二叉树,或称为AVL 树。
平衡二叉树的定义如下:首先符合二叉查找树的定义,其次必须满足任何节点的两个子树的高度最大差为1 。显然,图5-3 不满足平衡二叉树的定义,而图5-2 是一棵平衡二叉树。平衡二叉树的查找性能是比较高的,但不是最高的,只是接近最高性能。最好的性能需要建立一棵最优二叉树,但是最优二叉树的建立和维护需要大量的操作,因此,用户一般只需建立一棵平衡二叉树即可。
平衡二叉树的查询速度的确很快,但是维护一棵平衡二叉树的代价是非常大的。通常来说,需要1 次或多次左旋和右旋来得到插入或更新后树的平衡性。对千图5-2 所示的平衡树,当用户需要插入一个新的键值为9 的节点时,需做如图5–4 所示的变动。
这里通过一次左旋操作就将插入后的树重新变为平衡的了。但是有的情况可能需要多次,如图5-5 所示。

图5-4 和图5-5 中列举了向一棵平衡二叉树插入一个新的节点后,平衡二叉树需要做的旋转操作。除了插入操作,还有更新和删除操作,不过这和插入没有本质的区别,都是通过左旋或者右旋来完成的。因此对一棵平衡树的维护是有一定开销的,不过平衡二叉树多用于内存结构对象中,因此维护的开销相对较小。
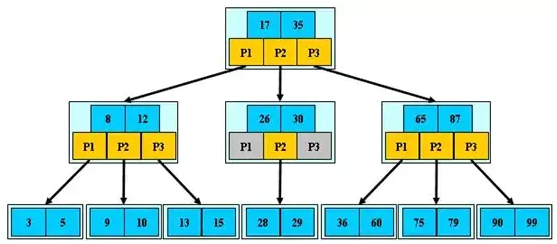
5.3 B+ 树
B+树和二叉树、平衡二叉树一样,都是经典的数据结构。B+树由B 树和索引顺序访问方法(ISAM, 是不是很熟悉?对,这也是MyISAM引擎最初参考的数据结构)演化而来,但是在现实使用过程中几乎已经没有使用B 树的情况了。
B+树的定义在任何一本数据结构书中都能找到,其定义十分复杂,在这里列出来只会让读者感到更加困惑。这里,我来精简地对B+树做个介绍: B+树是为磁盘或其他直接存取辅助设备设计的一种平衡查找树。在B+树中,所有记录节点都是按键值的大小顺序存放在同一层的叶子节点上,由各叶子节点指针进行连接。先来看一个B+树,其高度为2, 每页可存放4 条记录,扇出(fan out) 为5, 如图5-6 所示。

图5-6 一棵高度为2 的B+树
5.3.1 B+树的插入操作
B+树的插入必须保证插入后叶子节点中的记录依然排序,同时需要考虑插人到B+树的三种情况,每种情况都可能会导致不同的插入算法。如表5-1 所示。

这里用一个例子来分析B+树的插入。例如,对于图5-6 中的这棵B+树,若用户插入28 这个键值,发现当前LeafPage 和Index Page 都没有满,直接进行插入即可,之后得图5-7。

图5-7 插入键值28
接着再插入70 这个键值,这时原先的Leaf Page 已经满了,但是Index Page 还没有满,符合表5-1 的第二种情况,这时插入Leaf Page 后的情况为55 、55 、60 、65 、70,并根据中间的值60 来拆分叶子节点,可得图5-8 。

图5-8 插入键值70
因为图片显示的关系,这次没有能在各叶子节点加上双向链表指针。不过如图5-6、图5-7 一样,它还是存在的。
最后插入键值95, 这时符合表5-1 中讨论的第三种情况,即Leaf Page 和Index Page都满了,这时需要做两次拆分,如图5-9 所示。

可以看到,不管怎么变化, B+ 树总是会保待平衡。但是为了保持平衡对于新插入的键值可能需要做大量的拆分页(split) 操作。因为B+树结构主要用于磁盘,页的拆分意味着磁盘的操作,所以应该在可能的情况下尽量减少页的拆分操作。因此, B+树同样提供了类似于平衡二叉树的旋转(Rotation) 功能。
旋转发生在Leaf Page 已经满,但是其的左右兄弟节点没有满的情况下。这时B+树并不会急于去做拆分页的操作,而是将记录移到所在页的兄弟节点上。在通常情况下,左兄弟会被首先检查用来做旋转操作,因此再来看图5-7 的情况,若插入键值70, 其实B+树并不会急于去拆分叶子节点,而是去做旋转操作,得到如图5-10 所示的操作。

从图5-10 可以看到,采用旋转操作使B+树减少了一次页的拆分操作,同时这颗B+树的高度依然还是2 。
5.3.2 B+树的删除操作
B+树使用填充因子(fill factor) 来控制树的删除变化, 50 %是填充因子可设的最小值。B+树的删除操作同样必须保证删除后叶子节点中的记录依然排序,同插入一样,B+树的删除操作同样需要考虑以下表5-2 中的三种情况,与插入不同的是,删除根据填充因子的变化来衡量。

根据图5-9 的B+树来进行删除操作。首先删除键值为70 的这条记录,该记录符合表5-2 讨论的第一种情况,删除后可得到图5-11 。

接着删除键值为25 的记录,这也是表5-2 讨论的第一种情况,但是该值还是Index Page 中的值,因此在删除Leaf Page 中的25 后,还应将25 的右兄弟节点的28更新到Page Index中,最后可得图5-12。

最后看删除键值为60 的情况。删除Leaf Page 中键值为60 的记录后, Fill Factor 小于50% ,这时需要做合并操作,同样,在删除Index Page 中相关记录后需要做Index Page 的合并操作,最后得到图5-13 。

5.4 B+树索引
前面讨论的都是B+树的数据结构及其一般操作, B+ 树索引的本质就是B+树在数据库中的实现。但是B+索引在数据库中有一个特点是高扇出性,因此在数据库中, B+树的高度一般都在2~4 层,这也就是说查找某一键值的行记录时最多只需要2到4次IO,这倒不错。因为当前一般的机械磁盘每秒至少可以做100 次IO,2~4 次的IO 意味着查询时间只需0.02 ~ 0.04秒。
数据库中的B+树索引可以分为聚集索引(clustered inex) 和辅助索引(secondary index), 但是不管是聚集还是辅助的索引,其内部都是B+树的,即高度平衡的,叶子节点存放着所有的数据。聚集索引与辅助索引不同的是,叶子节点存放的是否是一整行的信息。
5.4.1 聚集索引
之前已经介绍过了, InnoDB 存储引擎表是索引组织表,即表中数据按照主键顺序存放。而聚集索引(clustered index) 就是按照每张表的主键构造一棵B+树,同时叶子节点中存放的即为整张表的行记录数据,也将聚集索引的叶子节点称为数据页。聚集索引的这个特性决定了索引组织表中数据也是索引的一部分。同B+树数据结构一样,每个数据页都通过一个双向链表来进行链接。
由于实际的数据页只能按照一棵B+树进行排序,因此每张表只能拥有一个聚集索引。在多数情况下,查询优化器倾向于采用聚集索引。因为聚集索引能够在B+树索引的叶子节点上直接找到数据。此外,由于定义了数据的逻辑顺序,聚集索引能够特别快地访问针对范围值的查询。查询优化器能够快速发现某一段范围的数据页需要扫描。
辅助索引有时也称非聚集索引(non-clustered index)
(聚簇索引)数据页上存放的是完整的每行的记录,而在非数据页的索引页中,存放的仅仅是键值及指向数据页的偏移量,而不是一个完整的行记录。

许多数据库的文档会这样告诉读者:聚集索引按照顺序物理地存储数据。如果看图5-14 ,可能也会有这样的感觉。但是试想一下,如果聚集索引必须按照特定顺序存放物理记录,则维护成本显得非常之高。所以,聚集索引的存储并不是物理上连续的,而是逻辑上连续的。这其中有两点:一是前面说过的页通过双向链表链接,页按照主键的顺序排序;另一点是每个页中的记录也是通过双向链表进行维护的,物理存储上可以同样不按照主键存储。
-
聚集索引的另一个好处是,它对于主键的排序查找和范围查找速度非常快。叶子节点的数据就是用户所要查询的数据。
-
另一个是范围查询(range query) ,即如果要查找主键某一范围内的数据,通过叶子节点的上层中间节点就可以得到页的范围,之后直接读取数据页即可,
5.4.2 辅助索引
对于辅助索引(Secondary Index,也称非聚集索引),叶子节点并不包含行记录的全部数据。叶子节点除了包含键值以外,每个叶子节点中的索引行中还包含了一个书签(bookmark) 。该书签用来告诉InnoDB 存储引擎哪里可以找到与索引相对应的行数据。由于InnoDB 存储引擎表是索引组织表,因此lnnoDB 存储引擎的辅助索引的书签就是相应行数据的聚集索引键。图5-15 显示了InnoDB 存储引擎中辅助索引与聚集索引的关系。

辅助索引的存在并不影响数据在聚集索引中的组织,因此每张表上可以有多个辅助索引。当通过辅助索引来寻找数据时, lnnoDB 存储引擎会遍历辅助索引并通过叶级别的指针获得指向主键索引的主键,然后再通过主键索引来找到一个完整的行记录。举例来说,如果在一棵高度为3 的辅助索引树中查找数据,那需要对这棵辅助索引树遍历3 次找到指定主键,如果聚集索引树的高度同样为3,那么还需要对聚集索引树进行3 次查找,最终找到一个完整的行数据所在的页,因此一共需要6 次逻辑IO 访问以得到最终的一个数据页。
对于其他的一些数据库,如Microsoft SQL Seiver 数据库,其有一种称为堆表的表类型,即行数据的存储按照插入的顺序存放。这与MySQL 数据库的MyISAM 存储引擎有些类似。堆表的特性决定了堆表上的索引都是非聚集的,主键与非主键的区别只是是否唯一且非空(NOT NULL) 。因此这时书签是一个行标识符(Row ldentifiedr, RID) ,可以用如“文件号:页号:槽号”的格式来定位实际的行数据。
有的Microsoft SQL Server 数据库DBA 问过我这样的问题,为什么在Microsoft SQLServer 数据库上还要使用索引组织表?堆表的书签使非聚集查找可以比主键书签方式更快,并且非聚集可能在一张表中存在多个,我们需要对多个非聚集索引进行查找。而且对于非聚集索引的离散读取,索引组织表上的非聚集索引会比堆表上的聚集索引慢一些。
当然,在一些情况下,使用堆表的确会比索引组织表更快,但是我觉得大部分原因是由于存在OLAP (On-Line Analytical Processing, 在线分析处理)的应用。其次就是前面提到的,表中数据是否需要更新,并且更新是否影响到物理地址的变更。此外另一个不能忽视的是对于排序和范围查找,索引组织表通过B+树的中间节点就可以找到要查找的所有页,然后进行读取,而堆表的特性决定了这对其是不能实现的。最后,非聚集索引的离散读,的确存在上述的情况,但是一般的数据库都通过实现**预读(read ahead)**技术来避免多次的离散读操作。因此,具体是建堆表还是索引组织表,这取决于应用,不存在哪个更优的问题。这和InnoDB 存储引擎好还是MyISAM 存储引擎好这个问题的答案是一样的, It all depends 。

5.4.3 B+树索引的分裂
在5.3 节中介绍B+树的分裂是最为简单的一种情况,这和数据库中B+树索引的情况可能略有不同。此外5.3 节页没有涉及并发,而这才是B+树索引实现最为困难的部分。
B+树索引页的分裂并不总是从页的中间记录开始,这样可能会导致页空间的浪费。
InnoDB 存储引擎的Page Header 中有以下几个部分用来保存插入的顺序信息:
-
PAGE_LAST_INSERT
-
PAGE_DIRECTION
-
PAGE_N_DIRECTION
通过这些信息, InnoDB 存储引擎可以决定是向左还是向右进行分裂,同时决定将分裂点记录为哪一个。若插入是随机的,则取页的中间记录作为分裂点的记录,这和之前介绍的相同。若往同一方向进行插入的记录数量为5,并且目前已经定位(cursor) 到的记录(InnoDB 存储引擎插入时,首先需要进行定位,定位到的记录为待插入记录的前一条记录)之后还有3 条记录,则分裂点的记录为定位到的记录后的第三条记录,否则分裂点记录就是待插人的记录。
* 5.4.4 B+树索引的管理
-
索引管理
索引的创建和删除可以通过两种方法,一种是ALTER TABLE, 另一种是CREATE/DROP INDEX 。通过ALTER TABLE 创建索引的语法为:
alter table tbl_name | add {index|key} {index_name} {index_type} (index_col_name,...) [index_option]...alter table tbl_name drop primary key |drop {index|key} index_name CREATE/DROP INDEX 的语法同样很简单:
create [unique] index index_name [index_type] on tbl_name(index_col_name,...)drop index index_name on tbl_name; 命令SHOW INDEX 展现结果中每列的含义。
- Table:索引所在的表名。
- Non_unique:非唯一的索引,可以看到primary key 是0,因为必须是唯一的。
- Key_name:索引的名字,用户可以通过这个名字来执行DROP INDEX 。
- Seq_in_index:索引中该列的位置,如果看联合索引idx_a_c 就比较直观了。
- Column_name:索引列的名称。
- Collation:列以什么方式存储在索引中。可以是A 或NULL 。B+树索引总是A,即排序的。如果使用了Heap 存储引擎,并且建立了Hash 索引,这里就会显示NULL 了。因为Hash 根据Hash 桶存放索引数据,而不是对数据进行排序。
- Cardinality:非常关键的值,表示索引中唯一值的数目的估计值。Cardinality 表的行数应尽可能接近1 ,如果非常小,那么用户需要考虑是否可以删除此索引。
- Sub_part:是否是列的部分被索引。如果看idx_b 这个索引,这里显示100,表示只对b 列的前100 字符进行索引。如果索引整个列,则该字段为NULL 。
- Packed:关键字如何被压缩。如果没有被压缩,则为NULL。
- Null:是否索引的列含有NULL 值。可以看到idx_b 这里为Yes,因为定义的列b允许NULL 值。
- Index_ type:索引的类型。InnoDB 存储引擎只支持B+树索引,所以这里显示的都是BTREE 。
- Comment: 注释。
Cardinality 值非常关键,优化器会根据这个值来判断是否使用这个索引。但是这个值并不是实时更新的,即并非每次索引的更新都会更新该值,因为这样代价太大了。因此这个值是不太准确的,只是一个大概的值。如果需要更新索引Cardinality 的信息,可以使用ANALYZE TABLE 命令。
Cardinality 为NULL,在某些情况下可能会发生索引建立了却没有用到的情况。或者对两条基本一样的语句执行EXPLAIN, 但是最终出来的结果不一样:一个使用索引,另外一个使用全表扫描。这时最好的解决办法就是做一次ANALYZE TABLE 的操作。因此我建议在一个非高峰时间,对应用程序下的几张核心表做ANALYZE TABLE 操作,这能使优化器和索引更好地为你工作。
-
Fast Index Creation
MySQL 5.5 版本之前(不包括5.5) 存在的一个普遍被人诉病的问题是MySQL 数据库对于索引的添加或者删除的这类DDL 操作, MySQL 数据库的操作过程为:
-
首先创建一张新的临时表,表结构为通过命令ALTER TABLE 新定义的结构。
-
然后把原表中数据导入到临时表。
-
接着删除原表。
-
最后把临时表重名为原来的表名。
可以发现,若用户对于一张大表进行索引的添加和删除操作,那么这会需要很长的时间。更关键的是,若有大量事务需要访问正在被修改的表,这意味着数据库服务不可用。而这对于Microsoft SQL Server 或Oracle 数据库的DBA 来说, MySQL 数据库的索引维护始终让他们感觉非常痛苦。
lnnoDB 存储引擎从InnoDB 1.0.x 版本开始支持一种称为Fast Index Creation (快速索引创建)的索引创建方式——简称FIC 。
对于辅助索引的创建, InnoDB 存储引擎会对创建索引的表加上一个S锁。在创建的过程中,不需要重建表,因此速度较之前提高很多,并且数据库的可用性也得到了提高。删除辅助索引操作就更简单了, InnoDB 存储引擎只需更新内部视图,并将辅助索引的空间标记为可用,同时删除MySQL 数据库内部视图上对该表的索引定义即可。
这里需要特别注意的是,临时表的创建路径是通过参数tmpdir 进行设置的。用户必须保证tmpdir 有足够的空间可以存放临时表,否则会导致创建索引失败。
由于FIC 在索引的创建的过程中对表加上了S 锁,因此在创建的过程中只能对该表进行读操作,若有大量的事务需要对目标表进行写操作,那么数据库的服务同样不可用。此外, FIC 方式只限定于辅助索引,对于主键的创建和删除同样需要重建一张表。
-
-
Online Schema Change
Online Schema Change (在线架构改变,简称OSC) 最早是由Facebook 实现的一种在线执行DDL 的方式,并广泛地应用千Facebook 的MySQL 数据库。所谓“在线”是指在事务的创建过程中,可以有读写事务对表进行操作,这提高了原有MySQL 数据库在DDL 操作时的并发性。
Facebook 采用PHP 脚本来现实OSC, 而并不是通过修改InnoDB 存储引擎源码的方式。OSC 最初由Facebook 的员工Vamsi Ponnekanti 开发。此外, OSC 借鉴了开源社区之前的工具The openarkkit toolkit oak-online-alter-table 。实现osc 步骤如下:
- init ,即初始化阶段,会对创建的表做一些验证工作,如检查表是否有主键,是否存在触发器或者外键等。
- createCopyTable,创建和原始表结构一样的新表。
- alterCopyTable: 对创建的新表进行ALTER TABLE 操作,如添加索引或列等。
- createDeltasTable,创建deltas 表,该表的作用是为下一步创建的触发器所使用。之后对原表的所有DML 操作会被记录到createDeltasTable 中。
- create Triggers, 对原表创建INSERT 、UPDATE、DELETE 操作的触发器。触发操作产生的记录被写入到deltas 表。
- startSnpshotXact,开始OSC 操作的事务。
- selectTablelntoOutfile,将原表中的数据写入到新表。为了减少对原表的锁定时间,这里通过分片(chunked) 将数据输出到多个外部文件,然后将外部文件的数据导人到copy 表中。分片的大小可以指定,默认值是500 000 。
- dropNCindexs,在导入到新表前,删除新表中所有的辅助索引。
- loadCopyTable,将导出的分片文件导入到新表。
- replayChanges,将OSC 过程中原表DML 操作的记录应用到新表中,这些记录被保存在deltas 表中。
- recreateNCindexes,重新创建辅助索引。
- replayChanges,再次进行DML 日志的回放操作,这些日志是在上述创建辅助索引中过程中新产生的日志。
- swap Tables,将原表和新表交换名字,整个操作需要锁定2 张表,不允许新的数据产生。由于改名是一个很快的操作,因此阻塞的时间非常短。
上述只是简单介绍了OSC 的实现过程,实际脚本非常复杂,仅osc 的PHP 核心代码就有2200 多行,用到的MySQL InnoDB 的知识点非常多,建议DBA 和数据库开发人员尝试进行阅读,这有助于更好地理解InnoDB 存储引擎的使用。
由于osc 只是一个PHP 脚本,因此其有一定的局限性。例如其要求进行修改的表一定要有主键,且表本身不能存在外键和触发器。此外,在进行OSC 过程中,允许
SET sql_ bin_ log=0,因此所做的操作不会同步slave 服务器,可能导致主从不一致的情况。 -
Online DDL
虽然FIC 可以让InnoDB 存储引擎避免创建临时表,从而提高索引创建的效率。但正如前面小节所说的,索引创建时会阻塞表上的DML 操作。OSC 虽然解决了上述的部分问题,但是还是有很大的局限性。MySQL 5.6 版本开始支持Online DDL (在线数据定义)操作,其允许辅助索引创建的同时,还允许其他诸如INSERT、UPDATE、DELETE这类DML 操作,这极大地提高了MySQL 数据库在生产环境中的可用性。
此外,不仅是辅助索引,以下这几类DDL 操作都可以通过“在线”的方式进行操作:
-
辅助索引的创建与删除
-
改变自增长值
-
添加或删除外键约束
-
列的重命名
通过新的ALTER TABLE 语法,用户可以选择索引的创建方式。
ALTER TABLE tbl_name | ADD {INDEX|KEY} [index_name] [index_type] (index_col_name, ...) [index_option] ... ALGORITHM [=] {DEFAULT|INPLACE|COPY} LOCK [=] {DEFAULT|NONE|SHARED|EXCLUSIVE} ALGORITHM 指定了创建或删除索引的算法, COPY 表示按照MySQL5.1 版本之前的工作模式,即创建临时表的方式。INPLACE 表示索引创建或删除操作不需要创建临时表。DEFAULT 表示根据参数old_alter_ table 来判断是通过INPLACE 还是COPY 的算法,该参数的默认值为OFF,表示采用INPLACE 的方式。
LOCK 部分为索引创建或删除时对表添加锁的情况,可有的选择为:
(1)NONE
执行索引创建或者删除操作时,对目标表不添加任何的锁,即事务仍然可以进行读写操作,不会收到阻塞。因此这种模式可以获得最大的并发度。
(2)SHARE
这和之前的FIC 类似,执行索引创建或删除操作时,对目标表加上一个S 锁。对千并发地读事务,依然可以执行,但是遇到写事务,就会发生等待操作。如果存储引擎不支持SHARE 模式,会返回一个错误信息。
(3)EXCLUSIVE
在EXCLUSIVE 模式下,执行索引创建或删除操作时,对目标表加上一个X锁。读写事务都不能进行,因此会阻塞所有的线程,这和COPY 方式运行得到的状态类似,但是不需要像COPY 方式那样创建一张临时表。
(4)DEFAULT
DEFAULT 模式首先会判断当前操作是否可以使用NONE 模式,若不能,则判断是否可以使用SHARE 模式,最后判断是否可以使用EXCLUSIVE 模式。也就是说DEFAULT 会通过判断事务的最大并发性来判断执行DDL 的模式。
InnoDB 存储引擎实现Online DDL 的原理是在执行创建或者删除操作的同时,将INSERT 、UPDATE 、DELETE 这类DML 操作日志写入到一个缓存中。待完成索引创建后再将重做应用到表上,以此达到数据的一致性。这个缓存的大小由参数
innodb_online_alter_log_max_size控制,默认的大小为128MB。若用户更新的表比较大,并且在创建过程中伴有大量的写事务,如遇到innodb_online_alter_log_max_size的空间不能存放日志时,会抛出类似如下的错误:Error:1799SQLSTATE:HYOOO(ER INNODB ONLINE LOG TOO BIG) 对于这个错误,用户可以调大参数
innodb_online_alter_log_max_size,以此获得更大的日志缓存空间。此外,还可以设置ALTER TABLE 的模式为SHARE,这样在执行过程中不会有写事务发生,因此不需要进行DML 日志的记录。 需要特别注意的是,由于Online DDL 在创建索引完成后再通过重做日志达到数据库的最终一致性,这意味着在索引创建过程中, SQL 优化器不会选择正在创建中的索引。
-
* 5.5 Cardinality 值
* 5.5.1 什么是Cardinality
并不是在所有的查询条件中出现的列都需要添加索引。对于什么时候添加B+树索引,一般的经验是,在访问表中很少一部分时使用B+树索引才有意义。
怎样查看索引是否是高选择性的呢?可以通过SHOW INDEX结果中的列Cardinality来观察。Cardinality 值非常关键,表示索引中不重复记录数量的预估值。同时需要注意的是, Cardinality 是一个预估值,而不是一个准确值,基本上用户也不可能得到一个准确的值。在实际应用中, Cardinality/n_rows_in_table应尽可能地接近1 。
5.5.2 lnnoDB 存储引擎的Cardinality统计
- 建立索引的前提是列中的数据具有高选择性
- 对Cardinality的统计在存储引擎层进行
- 对Cardinality的统计通过采样(Sample)完成
- 在lnnoDB 存储引擎中, Cardinality 统计信息的更新发生在两个操作中: INSERT和UPDATE
- 默认InnoDB 存储引擎对8个叶子节点(Leaf Page) 进行采样,统计Cardinality值
- 当执行SQL 语句
ANALYZE TABLE、SHOW TABLE STATUS、SHOW INDEX以及访问INFORMATION_SCHEMA架构下的表TABLES 和STATISTICS时会导致lnnoDB 存储引擎去重新计算索引的Cardinality值
上一小节介绍了Cardinality的重要性,并且告诉读者Cardinality表示选择性。建立索引的前提是列中的数据是高选择性的,这对数据库来说才具有实际意义。然而数据库是怎样来统计Cardinality信息的呢?因为MySQL数据库中有各种不同的存储引擎,而每种存储引擎对于B+树索引的实现又各不相同,所以对Cardinality 的统计是放在存储引擎层进行的。
此外需要考虑到的是,在生产环境中,索引的更新操作可能是非常频繁的。如果每次索引在发生操作时就对其进行Cardinality 的统计,那么将会给数据库带来很大的负担。另外需要考虑的是,如果一张表的数据非常大,如一张表有50G 的数据,那么统计一次Cardinality 信息所需要的时间可能非常长。这在生产环境下,也是不能接受的。因此,数据库对于Cardinality 的统计都是通过采样(Sample) 的方法来完成的。
在lnnoDB 存储引擎中, Cardinality 统计信息的更新发生在两个操作中: INSERT和UPDATE。根据前面的叙述,不可能在每次发生INSERT 和UPDATE 时就去更新Cardinality 信息,这样会增加数据库系统的负荷,同时对于大表的统计,时间上也不允许数据库这样去操作。因此, InnoDB 存储引擎内部对更新Cardinality 信息的策略为:
- 表中1/16 的数据已发生过变化。
- stat_modified_counter > 2 000 000 000 。
第一种策略为自从上次统计Cardinality 信息后,表中1/16 的数据已经发生过变化,这时需要更新Cardinality 信息。第二种情况考虑的是,如果对表中某一行数据频繁地进行更新操作,这时表中的数据实际并没有增加,实际发生变化的还是这一行数据,则第一种更新策略就无法适用这这种情况。故在InnoDB 存储引擎内部有一个计数器stat_modified_ counter, 用来表示发生变化的次数,当stat_modified_ counter 大于2 000 000 000 时,则同样需要更新Cardinality 信息。
接着考虑InnoDB 存储引擎内部是怎样来进行Cardinality 信息的统计和更新操作的呢?同样是通过采样的方法。默认InnoDB 存储引擎对8 个叶子节点(Leaf Page) 进行采样。采样的过程如下:
- 取得B+树索引中叶子节点的数量,记为A 。
- 随机取得B+树索引中的8 个叶子节点。统计每个页不同记录的个数,即为P1,P2, …,P8
- 根据采样信息给出Cardinality 的预估值: Cardinality= (P1+ P2+ …+ P8) *A/8 。
通过上述的说明可以发现,在InnoDB 存储引擎中, Cardinality 值是通过对8个叶子节点预估而得的,不是一个实际精确的值。再者,每次对Cardinality 值的统计,都是通过随机取8个叶子节点得到的,这同时又暗示了另一个Cardinality 现象,即每次得到的Cardinality 值可能是不同的。
当然,有一种情况可能使得用户每次观察到的索引Cardinality 值都是一样的,那就是表足够小,表的叶子节点数小于或者等千8 个。这时即使随机采样,也总是会采样到这些页,因此每次得到的Cardinality值是相同的。
在InnoDB 1.2 版本之前,可以通过参数innodb_stats_sample_pages用来设置统计Cardnality时每次采样页的数量,默认值为8 。同时,参数innodb_stats_method用来判断如何对待索引中出现的NULL 值记录。该参数默认值为nulls_equal,表示将NULL 值记录视为相等的记录。其有效值还有nulls_unequal,nulls_ignored,分别表示将NULL值记录视为不同的记录和忽略NULL值记录。例如某页中索引记录为NULL 、NULL 、1 、2 、2 、3 、3 、3,在参数innodb_stats_ method的默认设置下,该页的Cardinality 为4;若参数innodb_stats_method 为nulls_unequal,则该页的Caridinality 为5;若参数innodb_stats_method为nulls_ignored,则Cardinality 为3。
当执行SQL 语句ANALYZE TABLE 、SHOW TABLE STATUS、SHOW INDEX以及访问INFORMATION_SCHEMA 架构下的表TABLES 和STATISTICS 时会导致lnnoDB 存储引擎去重新计算索引的Cardinality值。若表中的数据量非常大,并且表中存在多个辅助索引时,执行上述这些操作可能会非常慢。虽然用户可能并不希望去更新Cardinality 值。
InnoDB1.2 版本提供了更多的参数对Cardinality 统计进行设置,这些参数如表5-3 所示。
表5-3 InnoDB 1.2 新增参数
| 参数 | 说明 |
|---|---|
| innodb_stats_persistent | 是否将命令 ANALYZE TABLE计算得到的 Cardinality值存放到磁盘上。若是,则这样做的好处是可以减少重新计算每个索引的 Cardinality值,例如当 MySQL数据库重启时。此外,用户也可以通过命令 CREATE TABLE和 ALTER TABLE的选项 STATS_PERSISTENT来对每张表进行控制。默认值:OFF |
| innodb_stats_on_metadata | 当通过命令 SHOW TABLE STATUS、 SHOW INDEX及访问INFORMATION_SCHEMA架构下的表 TABLES和 STATISTICS时,是否需要重新计算索引的 Cardinality值。默认值:OFF |
| innodb_stats_persistent_sample_pages | 若参数 innodb_stats_persistent设置为ON,该参数表示 ANALYZE TABLE更新Cardinality值时每次采样页的数量。默认值:20 |
| innodb_stats_transient_sample_pages | 该参数用来取代之前版本的参数 innodb_stats_sample_pages,表示每次采样页的数量。默认值为:8 |
5.6 B+树索引的使用
5.6.1 不同应用中B+树索引的使用
在实际的生产环境使用中,每个DBA 和开发人员,还是需要根据自己的具体生产环境来使用索引,并观察索引使用的情况,判断是否需要添加索引。不要盲从任何人给你的经验意见,Think Different。
根据第1章的介绍,用户已经知道数据库中存在两种类型的应用, OLTP 和OLAP应用。在OLTP 应用中,查询操作只从数据库中取得一小部分数据,一般可能都在10 条记录以下,甚至在很多时候只取1 条记录,如根据主键值来取得用户信息,根据订单号取得订单的详细信息,这都是典型OLTP 应用的查询语句。在这种情况下, B+ 树索引建立后,对该索引的使用应该只是通过该索引取得表中少部分的数据。这时建立B+树索引才是有意义的,否则即使建立了,优化器也可能选择不使用索引。
对于OLAP 中的复杂查询,要涉及多张表之间的联接操作,因此索引的添加依然是有意义的。但是,如果联接操作使用的是Hash Join, 那么索引可能又变得不是非常重要了,所以这需要DBA 或开发人员认真并仔细地研究自己的应用。不过在OLAP 应用中,通常会需要对时间字段进行索引,这是因为大多数统计需要根据时间维度来进行数据的筛选。
* 5.6.2 联合索引
联合索引是指对表上的多个列进行索引。前面讨论的情况都是只对表上的一个列进行索引。联合索引的创建方法与单个索引创建的方法一样,不同之处仅在于有多个索引列。
那么何时需要使用联合索引呢?在讨论这个问题之前,先来看一下联合索引内部的结果。从本质上来说,联合索引也是一棵B+树,不同的是联合索引的键值的数量不是1,而是大于等于2 。接着来讨论两个整型列组成的联合索引,假定两个键值的名称分别为a、b,如图5-22 所示。

从图5-22 可以观察到多个键值的B+树情况。其实和之前讨论的单个键值的B+树并没有什么不同,键值都是排序的,通过叶子节点可以逻辑上顺序地读出所有数据,就上面的例子来说,即(1,1) 、(1,2) 、(2,1) 、(2,4) 、(3,1) 、(3,2) 。数据按(a,b)的顺序进行了存放。
因此,对于查询SELECT * FROM TABLE WHERE a=xxx and b=xxx,显然是可以使用(a, b) 这个联合索引的。对于单个的a 列查询SELECT * FROM TABLE WHERE a = xxx,也可以使用这个(a, b) 索引。但对于b 列的查询SELECT * FROM TABLEWHERE b=xxx ,则不可以使用这棵B+树索引。可以发现叶子节点上的b 值为1 、2 、1 、4 、1 、2,显然不是排序的,因此对于b 列的查询使用不到(a, b) 的索引。
联合索引的第二个好处是已经对第二个键值进行了排序处理。例如,在很多情况下应用程序都需要查询某个用户的购物情况,并按照时间进行排序,最后取出最近三次的购买记录,这时使用联合索引可以避免多一次的排序操作,因为索引本身在叶子节点已经排序了。
#===========准备表==============
create table buy_log(userid int unsigned not null,buy_date date
);insert into buy_log values
(1,'2009-01-01'),
(2,'2009-01-01'),
(3,'2009-01-01'),
(1,'2009-02-01'),
(3,'2009-02-01'),
(1,'2009-03-01'),
(1,'2009-04-01');alter table buy_log add key(userid);
alter table buy_log add key(userid,buy_date);#===========验证==============
mysql> show create table buy_log;
| buy_log | CREATE TABLE `buy_log` (`userid` int(10) unsigned NOT NULL,`buy_date` date DEFAULT NULL,KEY `userid` (`userid`),KEY `userid_2` (`userid`,`buy_date`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 |#可以看到possible_keys在这里有两个索引可以用,分别是单个索引userid与联合索引userid_2,但是优化器最终选择了使用的key是userid因为该索引的叶子节点包含单个键值,所以理论上一个页能存放的记录应该更多
mysql> explain select * from buy_log where userid=2;
+----+-------------+---------+------+-----------------+--------+---------+-------+------+-------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+---------+------+-----------------+--------+---------+-------+------+-------+
| 1 | SIMPLE | buy_log | ref | userid,userid_2 | userid | 4 | const | 1 | |
+----+-------------+---------+------+-----------------+--------+---------+-------+------+-------+
row in set (0.00 sec)#接着假定要取出userid为1的最近3次的购买记录,用的就是联合索引userid_2了,因为在这个索引中,在userid=1的情况下,buy_date都已经排序好了
mysql> explain select * from buy_log where userid=1 order by buy_date desc limit 3;
+--+-----------+-------+----+---------------+--------+-------+-----+----+------------------------+
|id|select_type|table |type|possible_keys | key |key_len|ref |rows| Extra |
+--+-----------+-------+----+---------------+--------+-------+-----+----+------------------------+
| 1|SIMPLE |buy_log|ref |userid,userid_2|userid_2| 4 |const| 4 |Using where; Using index|
+--+-----------+-------+----+---------------+--------+-------+-----+----+------------------------+
row in set (0.00 sec)#ps:如果extra的排序显示是Using filesort,则意味着在查出数据后需要二次排序(如下查询语句,没有先用where userid=3先定位范围,于是即便命中索引也没用,需要二次排序)
mysql> explain select * from buy_log order by buy_date desc limit 3;
+--+-----------+-------+-----+-------------+--------+-------+----+----+---------------------------+
|id|select_type| table |type |possible_keys|key |key_len|ref |rows|Extra |
+--+-----------+-------+-----+-------------+--------+-------+----+----+---------------------------+
| 1|SIMPLE |buy_log|index| NULL |userid_2| 8 |NULL| 7 |Using index; Using filesort|
+--+-----------+-------+-----+-------------+--------+-------+----+----+---------------------------+#对于联合索引(a,b),下述语句可以直接使用该索引,无需二次排序
select ... from table where a=xxx order by b;#然后对于联合索引(a,b,c)来首,下列语句同样可以直接通过索引得到结果
select ... from table where a=xxx order by b;
select ... from table where a=xxx and b=xxx order by c;#但是对于联合索引(a,b,c),下列语句不能通过索引直接得到结果,还需要自己执行一次filesort操作,因为索引(a,c)并未排序
select ... from table where a=xxx order by c;* 5.6.3 覆盖索引
InnoDB 存储引擎支持覆盖索引(covering index,或称索引覆盖),即从辅助索引中就可以得到查询的记录,而不需要查询聚集索引中的记录。使用覆盖索引的一个好处是辅助索引不包含整行记录的所有信息,故其大小要远小于聚集索引,因此可以减少大量的IO 操作。
注意:覆盖索引技术最早是在InnoDB Plugin 中完成并实现。这意味着对于InnoDB 版本小于1.0 的,或者MySQL 数据库版本为5.0 或以下的, InnoDB 存储引挛不支持覆盖索引特性。
对于InnoDB 存储引擎的辅助索引而言,由于其包含了主键信息,因此其叶子节点存放的数据为(primary key1, primary key2, …, key1, key2, …)。例如,下列语句都可仅使用一次辅助联合索引来完成查询:
SELECT key2 FROM table WHERE key1=xxx;
SELECT primary key2,key2 FROM table WHERE key1=xxx;
SELECT primary key1,key2 FROM table WHERE key1=xxx;
SELECT primary key1,primary key2, key2 FROM table WHERE key1=xxx; 覆盖索引的另一个好处是对某些统计问题而言的。还是对于上一小节创建的表buy_log,要进行如下的查询:
SELECT COUNT(*) FROM buy_log; lnnoDB 存储引擎并不会选择通过查询聚集索引来进行统计。由于buy_log 表上还有辅助索引,而辅助索引远小于聚集索引,选择辅助索引可以减少IO 操作,故优化器的选择为如图5-26 所示。

图5-26 COUNT(*)操作的执行计划
通过图5-26 可以看到, possible_keys 列为NULL,但是实际执行时优化器却选择了userid 索引,而列Extra 列的Using index 就是代表了优化器进行了覆盖索引操作。
此外,在通常情况下,诸如(a, b) 的联合索引,一般是不可以选择列b 中所谓的查询条件。但是如果是统计操作,并且是覆盖索引的,则优化器会进行选择,如下述语句:
SELECT COUNT(*) FROM buy_log
WHERE buy_date>='2011-01-01' AND buy_date<'2011-02-01' 表buy_log 有(userid, buy_date) 的联合索引,这里只根据列b 进行条件查询,一般情况下是不能进行该联合索引的,但是这句SQL 查询是统计操作,并且可以利用到覆盖索引的信息,因此优化器会选择该联合索引,其执行计划如图5-27 所示。

图5-27 利用覆盖索引执行统计操作
从图5-27 中可以发现列possible_keys 依然为NULL,但是列key 为userid_2, 即表示(userid, buy_date) 的联合索引。在列Extra 同样可以发现Using index 提示,表示为覆盖索引。
* 5.6.4 优化器选择不使用索引的情况
在某些情况下,当执行EXPLAIN命令进行SQL 语句的分析时,会发现优化器并没有选择索引去查找数据,而是通过扫描聚集索引,也就是直接进行全表的扫描来得到数据。这种情况多发生于范围查找、JOIN 链接操作等情况下。例如:
SELECT * FROM orderdetails WHERE orderid > 10000 and orderid < 102000; 上述这句SQL 语句查找订单号大于10000 的订单详悄,通过命令SHOW INDEX FROM orderdetails,可观察到的索引如图5-28 所示。

图5-28 表orderdetails 的索引详情
可以看到表orderdetails 有(OrderlD,ProductlD) 的联合主键,此外还有对于列OrderID的单个索引。上述这句SQL 显然是可以通过扫描OrderID 上的索引进行数据的查找。然而通过EXPLAIN 命令,用户会发现优化器并没有按照OrderlD 上的索引来查找数据,如图5-29 所示。

图5-29 上述范围查询的SQL 执行计划
在possible_keys 一列可以看到查询可以使用PRIMARY 、OrderID 、OrdersOrder_Details 三个索引,但是在最后的索引使用中,优化器选择了PRIMARY 聚集索引,也就是表扫描(table scan) ,而非OrderID 辅助索引扫描(index scan) 。
这是为什么呢?原因在于用户要选取的数据是整行信息,而OrderID 索引不能覆盖到我们要查询的信息,因此在对OrderlD 索引查询到指定数据后,还需要一次书签访问来查找整行数据的信息。虽然OrderID 索引中数据是顺序存放的,但是再一次进行书签查找的数据则是无序的,因此变为了磁盘上的离散读操作。如果要求访问的数据量很小,则优化器还是会选择辅助索引,但是当访问的数据占整个表中数据的蛮大一部分时(一般是20 %左右),优化器会选择通过聚集索引来查找数据。因为之前已经提到过,顺序读要远远快于离散读。
因此对于不能进行索引覆盖的情况,优化器选择辅助索引的情况是,通过辅助索引查找的数据是少量的。这是由当前传统机械硬盘的特性所决定的,即利用顺序读来替换随机读的查找。若用户使用的磁盘是固态硬盘,随机读操作非常快,同时有足够的自信来确认使用辅助索引可以带来更好的性能,那么可以使用关键字FORCE INDEX来强制使用某个索引,如:
SELECT * FROM orderdetails FORCE INDEX (OrderID) WHERE orderid > 10000 and orderid < 102000; 这时的执行计划如图5-30 所示。

图5-30 强制使用辅助索引
* 5.6.5 索引提示
MySQL 数据库支持索引提示(INDEX HINT) ,显式地告诉优化器使用哪个索引。个人总结以下两种情况可能需要用到INDEX HINT:
- MySQL 数据库的优化器错误地选择了某个索引,导致SQL 语句运行的很慢。这种情况在最新的MySQL 数据库版本中非常非常的少见。优化器在绝大部分情况下工作得都非常有效和正确。这时有经验的DBA 或开发人员可以强制优化器使用某个索引,以此来提高SQL 运行的速度。
- 某SQL 语句可以选择的索引非常多,这时优化器选择执行计划时间的开销可能会大于SQL 语句本身。例如,优化器分析Range 查询本身就是比较耗时的操作。这时DBA 或开发人员分析最优的索引选择,通过Index Hint 来强制使优化器不进行各个执行路径的成本分析,直接选择指定的索引来完成查询。
在MySQL 数据库中Index Hint 的语法如下:
tbl_name [[AS] alias] [index_hint_list]
index_hint_list:
index_hint [, index_hint] ...
index_hint:
USE {INDEX|KEY}
[{FOR {JOIN|ORDER BY|GROUP BY}] ([index_list])
| GNORE {INDEX|KEY}
[{FOR {JOIN|ORDER BY|GROUP BY}] (index_list)
I FORCE ( INDEX IKEY )
[{FOR {JOIN|ORDER BY|GROUP BY}] (index_list)
index_list:
index_name [, index_ name]... 接着来看一个例子,首先根据如下代码创建测试表t,并填充相应数据。
CREATE TABLE t (a INT,b INT,KEY(a),KEY(b)
)ENGINE=INNODB;INSERT INTO t SELECT 1, 1;
INSERT INTO t SELECT 1, 2;
INSERT INTO t SELECT 2, 3;
INSERT INTO t SELECT 2, 4;
INSERT INTO t SELECT 1, 2; 然后执行如下的SQL 语句:
SELECT * FROM t WHERE a = 1 AND b = 2; 通过EXPLAIN 命令得到如图5-31 所示的执行计划。

图5-31 SQL 语句的执行计划
图5-31 中的列possible_keys 显示了上述SQL 语句可使用的索引为a, b,而实际使用的索引为列key 所示, 同样为a, b。也就是MySQL 数据库使用a, b两个索引来完成这一个查询。列Extra提示的Using intersect(b, a) 表示根据两个索引得到的结果进行求交的数学运算,最后得到结果。
如果我们使用USE INDEX的索引提示来使用a这个索引,如:
SELECT * FROM t USE INDEX(a) WHERE a = 1 AND b = 2; 那么得到的结果如图5-32 所示。

图5-32 使用USE INDEX 后的执行计划
可以看到,虽然我们指定使用a 索引,但是优化器实际选择的是通过表扫描的方式。因此, USE INDEX 只是告诉优化器可以选择该索引,实际上优化器还是会再根据自己的判断进行选择。而如果使用FORCE INDEX 的索引提示,如:
SELECT * FROM t FORCE INDEX(a) WHERE a = 1 AND b = 2; 则这时的执行计划如图5-33 所示。

图5-33 使用FORCE INDEX 后的执行计划
可以看到,这时优化器的最终选择和用户指定的索引是一致的。因此,如果用户确定指定某个索引来完成查询,那么最可靠的是使用FORCE INDEX,而不是USE INDEX 。
* 5.6.6 Multi-Range Read 优化
MySQL5.6 版本开始支持Multi-Range Read (MRR) 优化。Multi-Range Read优化的目的就是为了减少磁盘的随机访问,并且将随机访问转化为较为顺序的数据访问,这对于IO-bound类型的SQL查询语句可带来性能极大的提升。Multi-Range Read 优化可适用于range,ref,eq_ref类型的查询。
MRR 优化有以下几个好处:
-
MMR使数据访问变得较为顺序。在查询辅助索引时,首先根据得到的查询结果,按照主键进行排序,并按照主键排序的顺序进行书签查找。
-
减少缓冲池中页被替换的次数。
-
批量处理对键值的查询操作。
对于lnnoDB和MylSAM存储引擎的范围查询和JOIN查询操作,MRR 的工作方式如下:
-
将查询得到的辅助索引键值存放于一个缓存中,这时缓存中的数据是根据辅助索引键值排序的。
-
将缓存中的键值根据RowID进行排序。
-
根据RowID的排序顺序来访问实际的数据文件。
此外,若InnoDB存储引擎或者MyISAM存储引擎的缓冲池不是足够大,即不能存放下一张表中的所有数据,此时频繁的离散读操作还会导致缓存中的页被替换出缓冲池,然后又不断地被读入缓冲池。若是按照主键顺序进行访问,则可以将此重复行为降为最低。如下面这句SQL 语句:
SELECT * FROM salaries WHERE salary>10000 AND salary<40000; salary 上有一个辅助索引idx_s,因此除了通过辅助索引查找键值外,还需要通过书签查找来进行对整行数据的查询。当不启用Multi-Range Read 特性时,看到的执行计划如图5-34 所示。

若启用Mulit-Range Read 特性,则除了会在列Extra看到Using index condition 外,还会看见Using MRR 选项,如图5-35 所示。

而在实际的执行中会体会到两个的执行时间差别非常巨大,如表5-4 所示。

在书籍作者的笔记本电脑上,上述两句语句的执行时间相差10倍之多。可见Multi-Range Read 将访问数据转化为顺序后查询性能得到提高。
注意:上述测试都是在MySQL 数据库启动后直接执行SQL 查询语句,此时需确保缓冲池中没有被预热,以及需要查询的数据并不包含在缓冲池中。
此外, Multi-Range Read 还可以将某些范围查询,拆分为键值对,以此来进行批量的数据查询。这样做的好处是可以在拆分过程中,直接过滤一些不符合查询条件的数据,例如:
SELECT * FROM t WHERE key_part1 >= 1000 AND key_part1 < 2000 AND key_part2 = 10000; 表t 有(key_part1, key_part2) 的联合索引,因此索引根据key_part1,key_part2的位置关系进行排序。若没有Multi-Read Range,此时查询类型为Range,SQL 优化器会先将key_part1 大于1000 且小于2000 的数据都取出,即使key_part2 不等于1000 。待取出行数据后再根据key_part2 的条件进行过滤。这会导致无用数据被取出。如果有大批的数据且其key_part2 不等于1000,则启用Mulit-Range Read 优化会使性能有巨大的提升。
倘若启用了Multi-Range Read 优化,优化器会先将查询条件进行拆分,然后再进行数据查询。就上述查询语句而言,优化器会将查询条件拆分为(1000, 1000), (1001,1000), (1002, 1000), …,(1999, 1000) ,最后再根据这些拆分出的条件进行数据的查询。
可以来看一个实际的例子,查询如下:
SELECT * FROM salariesWHERE(from_date between '1986-01-01' AND '1995-01-01')AND (salary between 38000 and 40000); 若启用了Multi-Range Read 优化,则执行计划如图5-36 所示。

表salaries 上有对于salary 的索引idx_s,在执行上述SQL 语句时,因为启用了Multi-Range Read 优化,所以会对查询条件进行拆分,这样在列Extra 中可以看到Using MRR选项。
是否启用Multi-Range Read 优化可以通过参数optimizer_switch 中的标记(flag) 来控制。当mrr 为on 时,表示启用Multi-Range Read 优化。mrr_cost_based 标记表示是否通过cost based的方式来选择是否启用mrr。若将mrr 设为on,mrr_cost_based设为off,则总是启用Multi-Range Read 优化。例如,下述语句可以将Multi-Range Read 优化总是设为开启状态:
mysql> SET @@optimizer_switch='mrr=on,mrr_cost_based=off';
Query OK,0 rows affected (0.00 sec) 参数read_md_buffer_size用来控制键值的缓冲区大小,当大于该值时,则执行器对已经缓存的数据根据RowID 进行排序,并通过RowlD来取得行数据。该值默认为256K:

* 5.6.7 Index Condition Pushdown (ICP) 优化
和Multi-Range Read 一样, Index Condition Pushdown同样是MySQL5.6 开始支持的一种根据索引进行查询的优化方式。
- 之前的MySQL 数据库版本不支持Index Condition Pushdown,当进行索引查询时,首先根据索引来查找记录,然后再根据WHERE 条件来过滤记录。
- 在支持Index Condition Pushdown 后,MySQL 数据库会在取出索引的同时,判断是否可以进行WHERE 条件的过滤,也就是将WHERE 的部分过滤操作放在了存储引擎层。在某些查询下,可以大大减少上层SQL层对记录的索取(fetch) ,从而提高数据库的整体性能。
Index Condition Pushdown 优化支持range、ref、eq_ref、ref_or_null类型的查询,当前支持MylSAM和InnoDB存储引擎。当优化器选择Index Condition Pushdown 优化时,可在执行计划的列Extra 看到Using index condition 提示。
注意:NDB Cluster 存储引擎支持Engine Condition Pushdown 优化。不仅可以进行“Index" 的Condition Pushdown,也可以支持非索引的Condition Pushdown,不过这是由其引擎本身的特性所决定的。另外在MySQL 5.1 版本中NDB Cluster存储引辈就开始支持Engine Condition Pushdown 优化。
假设某张表有联合索引(zip_code,last_name,firset_name) ,并且查询语句如下:
SELECT * FROM peopleWHERE zipcode = '95054'AND last_name LIKE '%etrunia%' AND address LIKE '%Main Street%'; 对于上述语句, MySQL 数据库可以通过索引来定位zipcode 等于95054 的记录,但是索引对WHERE 条件的lastname LIKE ‘%etrunia%’ AND address LIKE ‘%MainStreet%’ 没有任何帮助。若不支持Index Condition Pushdown 优化,则数据库需要先通过索引取出所有zipcode 等于95 054 的记录,然后再过滤WHERE 之后的两个条件。
若支持Index Condition Pushdown 优化,则在索引取出时,就会进行WHERE条件的过滤,然后再去获取记录。这将极大地提高查询的效率。当然, WHERE 可以过滤的条件是要该索引可以覆盖到的范围。来看下面的SQL 语句:
SELECT * FROM salariesWHERE(from_date between '1986-01-01' AND '1995-01-01')AND (salary between 38000 and 40000);
可以看到列Extra 有Using index condition 的提示。但是为什么这里的idx_s 索引会使用Index Condition Pushdown 优化呢?因为这张表的主键是(emp_no,from_date) 的联合索引,所以idx_s索引中包含了from_date 的数据,故可使用此优化方式。
表5-5 对比了在MySQL 5.5 和MySQL 5.6 中上述SQL 语句的执行时间,并且同时比较开启MRR 后的执行时间。

上述的执行时间的比较同样是不对缓冲池做任何的预热操作。可见Index ConditionPushdown 优化可以将查询效率在原有MySQL 5.5 版本的技术上提高23% 。而再同时启用Mulit-Range Read 优化后,性能还能有400%的提升!
5.7 哈希算法
5.7.1 哈希表
哈希表(Hash Table)也称散列表,由直接寻址表改进而来。我们先来看直接寻址表。当关键字的全域U比较小时,直接寻址是一种简单而有效的技术。假设某应用要用到一个动态集合,其中每个元素都有一个取自全域U={0, 1, …, m-1}的关键字。同时假设没有两个元素具有相同的关键字。
用一个数组(即直接寻址表) T [0… m-1] 表示动态集合,其中每个位置(或称槽或桶)对应全域U 中的一个关键字。图5-38 说明了这个方法,槽k 指向集合中一个关键字为K 的元素。如果该集合中没有关键字为k的元素,则T [k] =NULL 。

图5-38 直接寻址表
直接寻址技术存在一个很明显的问题,如果域U 很大,在一台典型计算机的可用容拭的限制下,要在机器中存储大小为U 的一张表T 就有点不实际,甚至是不可能的。如果实际要存储的关键字集合K 相对于U来说很小,那么分配给T的大部分空间都要浪费掉。
因此,哈希表出现了。在哈希方式下,该元素处于h (k) 中,即利用哈希函数h,根据关键字k计算出槽的位置。函数h将关键字域U映射到哈希表T [0… m-1] 的槽位上(此处的m不是一个很大的数),如图5-39 所示。
哈希表技术很好地解决了直接寻址遇到的问题,但是这样做有一个小问题,如图5-39 所示的两个关键字可能映射到同一个槽上。一般将这种情况称之为发生了碰撞(collision)。在数据库中一般采用最简单的碰撞解决技术,这种技术被称为链接法(chaining) 。

图5-39 哈希表
在链接法中,把散列到同一槽中的所有元素都放在一个链表中,如图5-40 所示。槽j 中有一个指针,它指向由所有散列到j 的元素构成的链表的头;如果不存在这样的元素,则j 中为NULL 。

图5-40 通过链表法解决碰撞的哈希表
最后要考虑的是哈希函数。哈希函数h 必须可以很好地进行散列。最好的情况是能避免碰撞的发生。即使不能避免,也应该使碰撞在最小程度下产生。一般来说,都将关键字转换成自然数,然后通过除法散列、乘法散列或全域散列来实现。数据库中一般采用除法散列的方法。
在哈希函数的除法散列法中,通过取k除以m的余数,将关键字k映射到m个槽的某一个去,即哈希函数为:
h(k) = k mod m
5.7.2 lnnoDB 存储引擎中的哈希算法
InnoDB 存储引擎使用哈希算法来对字典进行查找,其冲突机制采用链表方式,哈希函数采用除法散列方式。对于缓冲池页的哈希表来说,在缓冲池中的Page页都有一个chain 指针,它指向相同哈希函数值的页。而对于除法散列, m 的取值为略大于2倍的缓冲池页数量的质数。例如:当前参数innodb_buffer_pool_size 的大小为10M,则共有640 个16KB 的页。对于缓冲池页内存的哈希表来说,需要分配640x2=1280 个槽,但是由于1280 不是质数,需要取比1280 略大的一个质数,应该是1399,所以在启动时会分配1399 个槽的哈希表,用来哈希查询所在缓冲池中的页。
那么InnoDB 存储引擎的缓冲池对于其中的页是怎么进行查找的呢?上面只是给出了一般的算法,怎么将要查找的页转换成自然数呢?
其实也很简单, InnoDB 存储引擎的表空间都有一个space_id,用户所要查询的应该是某个表空间的某个连续16KB 的页,即偏移量offset。lnnoDB 存储引擎将space_id 左移20 位,然后加上这个space_id 和offset,即关键字K=space_ id<<20+space_id+offset,然后通过除法散列到各个槽中去。
5.7.3 自适应哈希索引
自适应哈希索引采用之前讨论的哈希表的方式实现。不同的是,这仅是数据库自身创建并使用的,DBA本身并不能对其进行干预。自适应哈希索引经哈希函数映射到一个哈希表中,因此对于字典类型的查找非常快速,如SELECT * FROM TABLE WHERE index_col='xxx'。但是对于范围查找就无能为力了。通过命令SHOW ENGINE INNODB STATUS 可以看到当前自适应哈希索引的使用状况,如:

现在可以看到自适应哈希索引的使用信息了,包括自适应哈希索引的大小、使用情况、每秒使用自适应哈希索引搜索的情况。需要注意的是,哈希索引只能用来搜索等值的查询,如:
SELECT * FROM TABLE WHERE index_col = 'xxx' 而对于其他查找类型,如范围查找,是不能使用哈希索引的。因此,这里出现了non-hash searches/s 的情况。通过hash searches:non-hash searches 可以大概了解使用哈希索引后的效率。
由于自适应哈希索引是由InnoDB存储引擎自己控制的,因此这里的这些信息只供参考。不过可以通过参数innodb_adaptive_hash_index来禁用或启动此特性,默认为开启。
5.8 全文检索
5.8.1 概述
通过前面章节的介绍,已经知道B+树索引的特点,可以通过索引字段的前缀(prefix) 进行查找。例如,对于下面的查询B+树索引是支持的:
SELECT * FROM blog WHERE content like 'xxx%' 上述SQL 语句可以查询博客内容以XXX 开头的文章,并且只要content 添加了B+树索引,就能利用索引进行快速查询。然而实际这种查询不符合用户的要求,因为在更多的情况下,用户需要查询的是博客内容包含单词xxx 的文章,即:
SELECT * FROM blog WHERE content like '%xxx%' 根据B+树索引的特性,上述SQL 语句即便添加了B+树索引也是需要进行索引的扫描来得到结果。类似这样的需求在互联网应用中还有很多。例如,搜索引擎需要根据用户输入的关键字进行全文查找,电子商务网站需要根据用户的查询条件,在可能需要在商品的详细介绍中进行查找,这些都不是B+树索引所能很好地完成的工作。
全文检索(Full-Text Search) 是将存储于数据库中的整本书或整篇文章中的任意内容信息查找出来的技术。它可以根据需要获得全文中有关章、节、段、句、词等信息,也可以进行各种统计和分析。
在之前的MySQL 数据库中, InnoDB 存储引擎并不支持全文检索技术。大多数的用户转向MyISAM 存储引擎,这可能需要进行表的拆分,并将需要进行全文索引的数据存储为MyISAM 表。这样的确能够解决逻辑业务的需求,但是却丧失了InnoDB 存储引擎的事务性,而这在生产环境应用中同样是非常关键的。
从InnoDB 1.2.x 版本开始, InnoDB 存储引擎开始支持全文检索,其支持MyISAM存储引擎的全部功能,并且还支持其他的一些特性,这些将在后面的小节中进行介绍。
* 5.8.2 倒排索引
全文检索通常使用倒排索引(inverted index) 来实现。倒排索引同B+树索引一样,也是一种索引结构。它在辅助表(auxiliary table) 中存储了单词与单词自身在一个或多个文档中所在位置之间的映射。这通常利用关联数组实现,其拥有两种表现形式:
- inverted file index,其表现形式为 {单词,单词所在文档的 ID}
- full inverted index,其表现形式为 {单词,(单词所在文档的ID,在具体文档中的位置)}
例如,对于下面这个例子,表t 存储的内容如表5-6 所示。

Documentld 表示进行全文检索文档的Id,Text 表示存储的内容,用户需要对存储的这些文档内容进行全文检索。例如,查找出现过Some 单词的文档Id,又或者查找单个文档中出现过两个Some单词的文档Id,等等。
对于inverted file index 的关联数组,其存储的内容如表5-7所示。

可以看到单词code 存在于文档1和4中,单词 days存在与文档3和6中。之后再要进行全文查询就简单了,可以直接根据 Documents得到包含查询关键字的文档。对于 inverted file index,其仅存取文档 Id,而 full inverted index存储的是对(pair),即(DocumentId,Position),因此其存储的倒排索引如表 5-8所示。

full inverted index 还存储了单词所在的位置信息,如code 这个单词出现在(1 : 6),即文档1 的第6 个单词为code。相比之下, full inverted index 占用更多的空间,但是能更好地定位数据,并扩充一些其他的搜索特性。
5.8.3 lnnoDB 全文检索
InnoDB 存储引擎从1.2.x 版本开始支持全文检索的技术,其采用full inverted index的方式。在InnoDB 存储引擎中,将(Documentld, Position) 视为一个“ilist”。因此在全文检索的表中,有两个列,一个是word 字段,另一个是ilist 字段,并且在word 字段上有设有索引。此外,由于InnoDB 存储引擎在ilist 字段中存放了Position 信息,故可以进行Proximity Search,而MyISAM 存储引擎不支持该特性。
正如之前所说的那样,倒排索引需要将word 存放到一张表中,这个表称为Auxiliary Table (辅助表)。在InnoDB 存储引擎中,为了提高全文检索的并行性能,共有6 张Auxiliary Table,目前每张表根据word的Latin编码进行分区。
Auxiliary Table 是持久的表,存放于磁盘上。然而在InnoDB 存储引擎的全文索引中,还有另外一个重要的概念FTS Index Cache (全文检索索引缓存),其用来提高全文检索的性能。
FTS Index Cache 是一个红黑树结构,其根据(word, ilist) 进行排序。这意味着插入的数据已经更新了对应的表,但是对全文索引的更新可能在分词操作后还在FTS Index Cache 中, Auxiliary Table 可能还没有更新。InnoDB 存储引擎会批量对Auxiliary Table进行更新,而不是每次插入后更新一次Auxiliary Table。当对全文检索进行查询时,Auxiliary Table 首先会将在FTS Index Cache 中对应的word 字段合并到Auxiliary Table中,然后再进行查询。这种merge 操作非常类似之前介绍的Insert Buffer 的功能,不同的是Insert Buffer 是一个持久的对象,并且其是B+树的结构。然而FTS Index Cache 的作用又和Insert Buffer 是类似的,它提高了InnoDB 存储引擎的性能,并且由于其根据红黑树排序后进行批量插入,其产生的Auxiliary Table 相对较小。
InnoDB 存储引擎允许用户查看指定倒排索引的Auxiliary Table 中分词的信息,可以通过设置参数innodb_ft_aux_table 来观察倒排索引的Auxiliary Table 。下面的SQL 语句设置查看test 架构下表fts_a 的Auxiliary Table:

在上述设置完成后,就可以通过查询information_schema 架构下的表INNODB_FT_INDEX_TABLE 得到表fts_a 中的分词信息。
对于其他数据库,如Oracle 11g, 用户可以选择手工在事务提交时,或者固定间隔时间时将倒排索引的更新刷新到磁盘。对于lnnoDB 存储引擎而言,其总是在事务提交时将分词写入到FTS Index Cache,然后再通过批量更新写入到磁盘。虽然InnoDB 存储引擎通过一种延时的、批量的写入方式来提高数据库的性能,但是上述操作仅在事务提交时发生。
当数据库关闭时,在FTS Index Cache 中的数据库会同步到磁盘上的Auxiliary Table中。然而,如果当数据库发生宕机时,一些FTS Index Cache 中的数据库可能未被同步到磁盘上。那么下次重启数据库时,当用户对表进行全文检索(查询或者插入操作)时,lnnoDB 存储引擎会自动读取未完成的文档,然后进行分词操作,再将分词的结果放入到FTS Index Cache 中。
参数innodb_ft_cache_size 用来控制FTS Index Cache 的大小,默认值为32M 。当该缓存满时,会将其中的(word, ilist) 分词信息同步到磁盘的Auxiliary Table 中。增大该参数可以提高全文检索的性能,但是在宕机时,未同步到磁盘中的索引信息可能需要更长的时间进行恢复。
FTS Document ID 是另外一个重要的概念。在lnnoDB 存储引擎中,为了支持全文检索,必须有一个列与word 进行映射,在InnoDB 中这个列被命名为FTS_DOC_ID,其类型必须是BIGINT UNSIGNED NOT NULL,并且InnoDB 存储引擎自动会在该列上加入一个名为FTS_DOC_ID_INDEX 的Unique Index 。上述这些操作都由lnnoDB 存储引擎自已完成,用户也可以在建表时自动添加FTS_DOC_ID,以及相应的Unique Index 。由于列名为FTS_DOC_ID 的列具有特殊意义,因此创建时必须注意相应的类型,否则MySQL 数据库会抛出错误。
文档中分词的插入操作是在事务提交时完成,然而对于删除操作,其在事务提交时,不删除磁盘Auxiliary Table 中的记录,而只是删除FTS Cache Index 中的记录。对于Auxiliary Table 中被删除的记录, InnoDB 存储引擎会记录其FTS Document ID,并将其保存在DELETED auxiliary table 中。在设置参数innodb_ft_ aux_table 后,用户同样可以访问information_schema 架构下的表INNODB_FT_DELETED 来观察删除的FTSDocument ID 。
由于文档的DML 操作实际并不删除索引中的数据,相反还会在对应的DELETED表中插入记录,因此随着应用程序的允许,索引会变得非常大,即使索引中的有些数据已经被删除,查询也不会选择这类记录。为此, InnoDB 存储引擎提供了一种方式,允许用户手工地将已经删除的记录从索引中彻底删除,该命令就是OPTIMIZE TABLE 。因为OPTIMIZE TABLE 还会进行一些其他的操作,如Cardinality 的重新统计,若用户希望仅对倒排索引进行操作,那么可以通过innodb_optimize_fulltext_only进行设置。
若被删除的文档非常多,那么OPTIMIZE TABLE 操作可能需要占用非常多的时间,这会影响应用程序的并发性,并极大地降低用户的响应时间。用户可以通过参数innodb_ft_num_word_optimize 来限制每次实际删除的分词数量。该参数的默认值为2000。
stopword 列表(stopword list) 是本小节最后阐述的一个概念,其表示该列表中的word 不需要对其进行索引分词操作。例如,对于the 这个单词,由千其不具有具体的意义,因此将其视为stopword。InnoDB 存储引擎有一张默认的stopword 列表,其在information_schema 架构下,表名为INNODB_FT_DEFAULT_STOPWORD, 默认共有36 个stopword。此外用户也可以通过参数innodb_ft_server_stopword _table 来自定义stopword 列表。
当前lnnoDB 存储引擎的全文检索还存在以下的限制:
-
每张表只能有一个全文检索的索引。
-
由多列组合而成的全文检索的索引列必须使用相同的字符集与排序规则。
-
不支持没有单词界定符(delimiter) 的语言,如中文、日语、韩语等。
5.8.4 全文检索
MySQL 数据库支持全文检索(Full-Text Search) 的查询,其语法为:
MATCH(col1,col2,...) AGAINST(expr[search_modifier])
search_modifier:
{IN NATURAL LANGUAGE MODE| IN NATURAL LANGUAGE MODE WITH QUERY EXPANSION| IN BOOLEAN MODE| WITH QUERY EXPANSION
} MySQL 数据库通过MATCH() … AGAINST() 语法支持全文检索的查询, MATCH 指定了需要被查询的列, AGAINST 指定了使用何种方法去进行查询。下面将对各种查询模式进行详细的介绍。
-
Natural Language
全文检索通过MATCH 函数进行查询,默认采用Natural Language 模式,其表示查询带有指定word 的文档。对于5.8.3 小节中创建的表fts_a, 查询body 字段中带有Pease的文档,若不使用全文索引技术,则允许使用下述SQL 语句:
SELECT * FROM fts_a WHERE body LIKE '%Pease%'显然上述SQL 语句不能使用B+树索引。若采用全文检索技术,可以用下面的SQL语句进行查询:

由于NATURAL LANGUAGE MODE 是默认的全文检索查询模式,因此用户可以省略查询修饰符,即上述SQL 语句可以写为:
SELECT FROM fts_a WHERE MATCH(body) AGAINST ('Porridge'); 观察上述SQL 语句的查询计划,可得:

可以看到,在type 这列显示了fulltext, 即表示使用全文检索的倒排索引,而key 这列显示了idx_fts, 表示索引的名字。可见上述查询使用了全文检索技术。同时,若表没有创建倒排索引,则执行MATCH 函数会抛出类似如下错误:

在WHERE 条件中使用MATCH 函数,查询返回的结果是根据相关性(Relevance) 进行降序排序的,即相关性最高的结果放在第一位。相关性的值是一个非负的浮点数字, 0 表示没有任何的相关性。根据MySQL 官方的文档可知,其相关性的计算依据以下四个条件:
- word 是否在文档中出现。
- word 在文档中出现的次数。
- word 在索引列中的数量。
- 多少个文档包含该word 。
对于上述查询,由于Porridge 在文档2 中出现了两次,因而具有更高的相关性,故第一个显示。
对于InnoDB 存储引擎的全文检索,还需要考虑以下的因素:
- 查询的word 在stopword 列中,忽略该字符串的查询。
- 查询的word 的字符长度是否在区间[innodb_ft_min_token_size,innodb_ft_max_token_size]内。
参数innodb_ft_min_token_size 和innodb_ft_max_token_size 控制lnnoDB 存储引擎查询字符的长度,当长度小于innodb_ft_min_token_size,或者长度大于innodb_ft_max_token_size 时,会忽略该词的搜索。在InnoDB 存储引擎中,参数innodb_ft_min_token_size 的默认值为3,参数innodb_ft_max_token_size 的默认值为84 。
-
Boolean
MySQL 数据库允许使用IN BOOLEAN MODE 修饰符来进行全文检索。当使用该修饰符时,查询字符串的前后字符会有特殊的含义,例如下面的语句要求查询有字符串Pease 但没有hot 的文档,其中+和-分别表示这个单词必须出现,或者一定不存在。

Boolean 全文检索支持以下几种操作符:
- +表示该word必须存在。
- -表示该word必须被排除。
- (no operator)表示该word是可选的,但是如果出现,其相关性会更高
- @distance表示查询的多个单词之间的距离是否在 distance之内, distance的单位是字节。这种全文检索的查询也称为Proximity Search。如 MATCH(body) AGAINST(‘“Pease pot”@30’ IN BOOLEAN MODE)表示字符串 Pease和pot之间的距离需在30字节内。
- >表示出现该单词时增加相关性。
- <表示出现该单词时降低相关性。
- ~表示允许出现该单词,但是出现时相关性为负(全文检索查询允许负相关性)。
- 表示以该单词开头的单词,如lik,表示可以是lik、like,又或者 likes。
- "表示短语。
接着将根据上述的操作符及之前创建的表fts_a 来进行具体的介绍。下面的SQL 语句返回有pease 又有hot 的文档:


可以看到文档1中单词Pease 和pot 的距离为22 字节,因此第一条@30的查询可以返回结果,而之后@10 的条件不能返回任何结果。如:

上述SQL 语句查询根据是否有单词like 或pot 进行相关性统计,并且出现单词pot后相关性需要增加。文档4 虽然出现两个like 单词,但是没有pot,因此相关性没有文档1和5高。
下面的查询增加了“<some" 的条件,最后得到的结果:


-
Query Expansion
MySQL 数据库还支持全文检索的扩展查询。这种查询通常在查询的关键词太短,用户需要implied knowledge (隐含知识)时进行。例如,对于单词database 的查询,用户可能希望查询的不仅仅是包含database 的文档,可能还指那些包含MySQL、Oracle、DB2 、RDBMS的单词。而这时可以使用Query Expansion 模式来开启全文检索的implied knowledge。
通过在查询短语中添加WITH QUERY EXPANSION 或IN NATURAL LANGUAGE MODE WITH QUERY EXPANSION 可以开启blind query expansion (又称为automatic relevance feedback) 。该查询分为两个阶段。
-
第一阶段:根据搜索的单词进行全文索引查询。
-
第二阶段:根据第一阶段产生的分词再进行一次全文检索的查询。
由于Query Expansion 的全文检索可能带来许多非相关性的查询,因此在使用时,用户可能需要非常谨慎。
-
5.9 小结
本章介绍了一些常用的数据结构,如二分查找树、平衡树、B+树、直接寻址表和哈希表,以及InnoDB1.2 版本开始支持的全文索引。从数据结构的角度切人数据库中常见的B+树索引和哈希索引的使用,并从内部机制上讨论了使用上述索引的环境和优化方法。