法一: crosstab
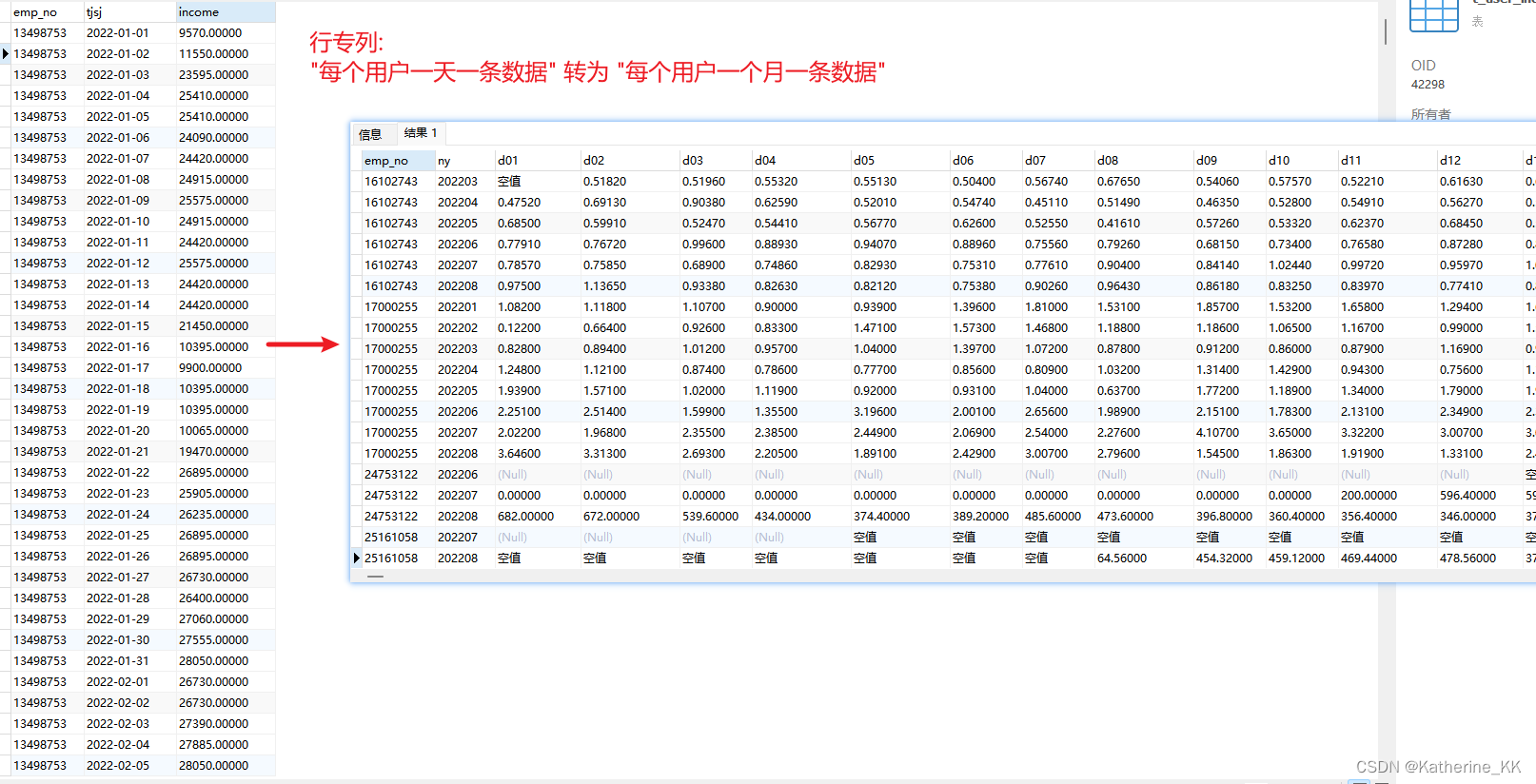
原表(左)及现实结果表(右)展示:
第一步: 安装扩展
create extension tablefunc;** 否则后续会报错
错误: 函数 crosstab(unknown, unknown) 不存在
第二步: 对表进行空值处理(此处将空值填写为字符串'空值')
update t_user_income set income='空值' where income is null;目的: 有效区分哪些数据 "原表里是空值" 及 "原表没有该行数据"
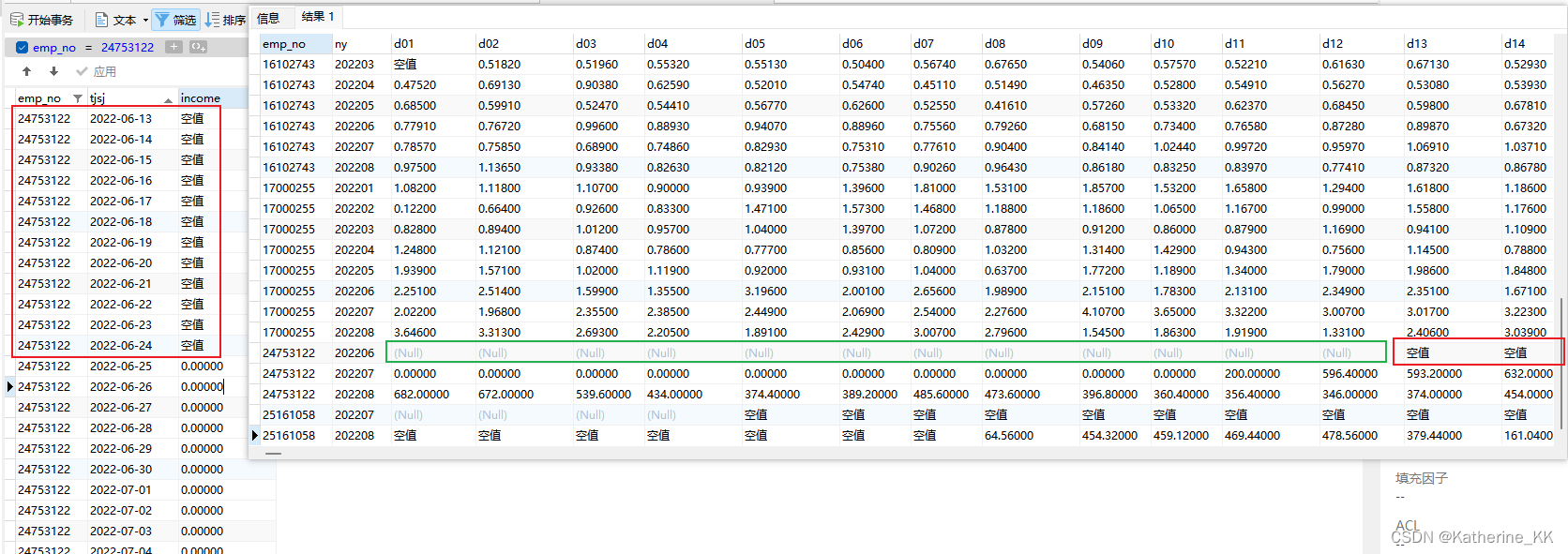
以员工号:24753122 6月份数据为例(左图红框):
6月1-12日原表中没有数据,
6月13日有该记录但为空值(判空处理前为NULL)
处理结果为右图:
结果表能轻易得出, 绿框表示原本无数据, 红框为有记录但income值为NULL
** 如不需区分可直接跳过这一步
第三步: 行专列(crosstab函数)
select (regexp_split_to_array(id,','))[1] as emp_no, --转为数组并取[1]员工编号(regexp_split_to_array(id,','))[2] as ny, --转为数组并取[2]年月D01,D02,D03,D04,D05,D06,D07,D08,D09,D10,D11,D12,D13,D14,D15,D16,D17,D18,D19,D20,D21,D22,D23,D24,D25,D26,D27,D28,D29,D30,D31 --日期from( select * from crosstab('select concat_ws('','',emp_no,to_char(tjsj,''yyyymm'')) as id, to_char(tjsj,''dd'') as tjsj, income::varchar from t_user_income order by 1','select distinct to_char(tjsj,''dd'') as tjsj from t_user_income order by 1')as ct(id varchar(50000),D01 varchar(500),D02 varchar(500),D03 varchar(500),D04 varchar(500),D05 varchar(500),D06 varchar(500),D07 varchar(500),D08 varchar(500),D09 varchar(500),D10 varchar(500),D11 varchar(500),D12 varchar(500),D13 varchar(500),D14 varchar(500),D15 varchar(500),D16 varchar(500),D17 varchar(500),D18 varchar(500),D19 varchar(500),D20 varchar(500),D21 varchar(500),D22 varchar(500),D23 varchar(500),D24 varchar(500),D25 varchar(500),D26 varchar(500),D27 varchar(500),D28 varchar(500),D29 varchar(500),D30 varchar(500),D31 varchar(500)))border by emp_no, ny第三步拆解:
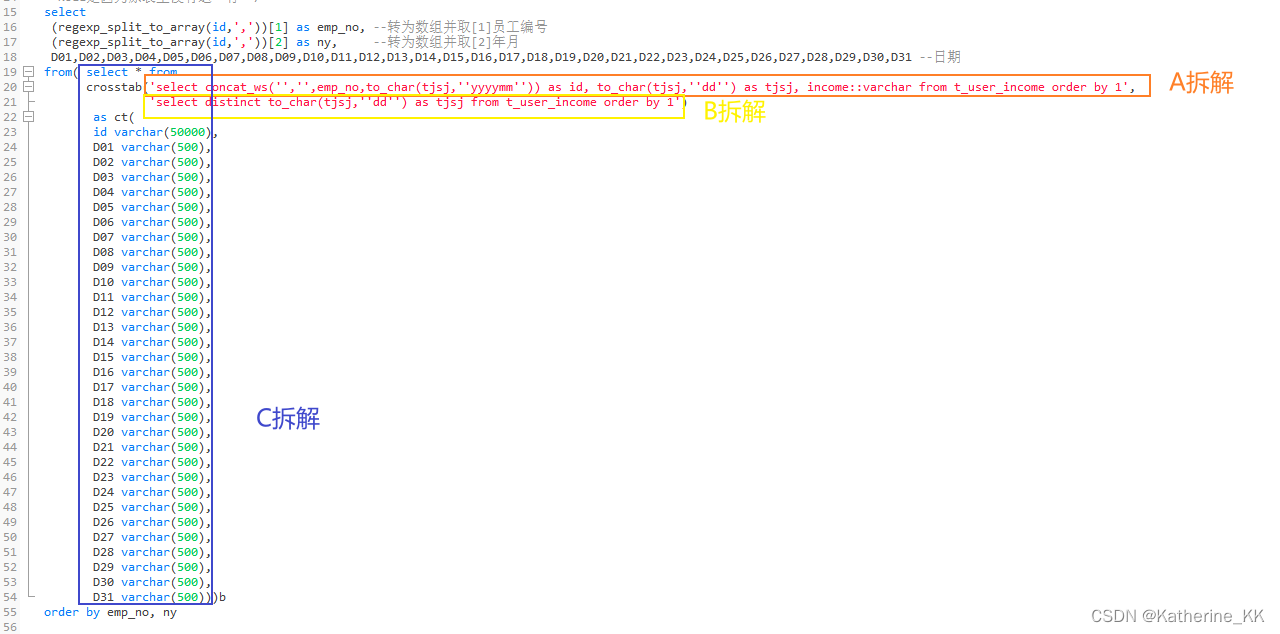
A拆解 :
select concat_ws(',',emp_no,to_char(tjsj,'yyyymm')) as id, to_char(tjsj,'dd') as tjsj, income::varchar from t_user_income order by 11- 选择要转置的列: (SELECT 列名[对应红框], 列名[对应绿框], 值[对应橙框] FROM TABLE):
此处为
列名 [ 红框 ]: concat_ws(',',emp_no,to_char(tjsj,'yyyymm')) as id
列名 [ 绿框 ]: to_char(tjsj,'dd') as tjsj
值 [ 橙框 ]: income::varchar
左侧是A运行结果, 对应右侧的结果集
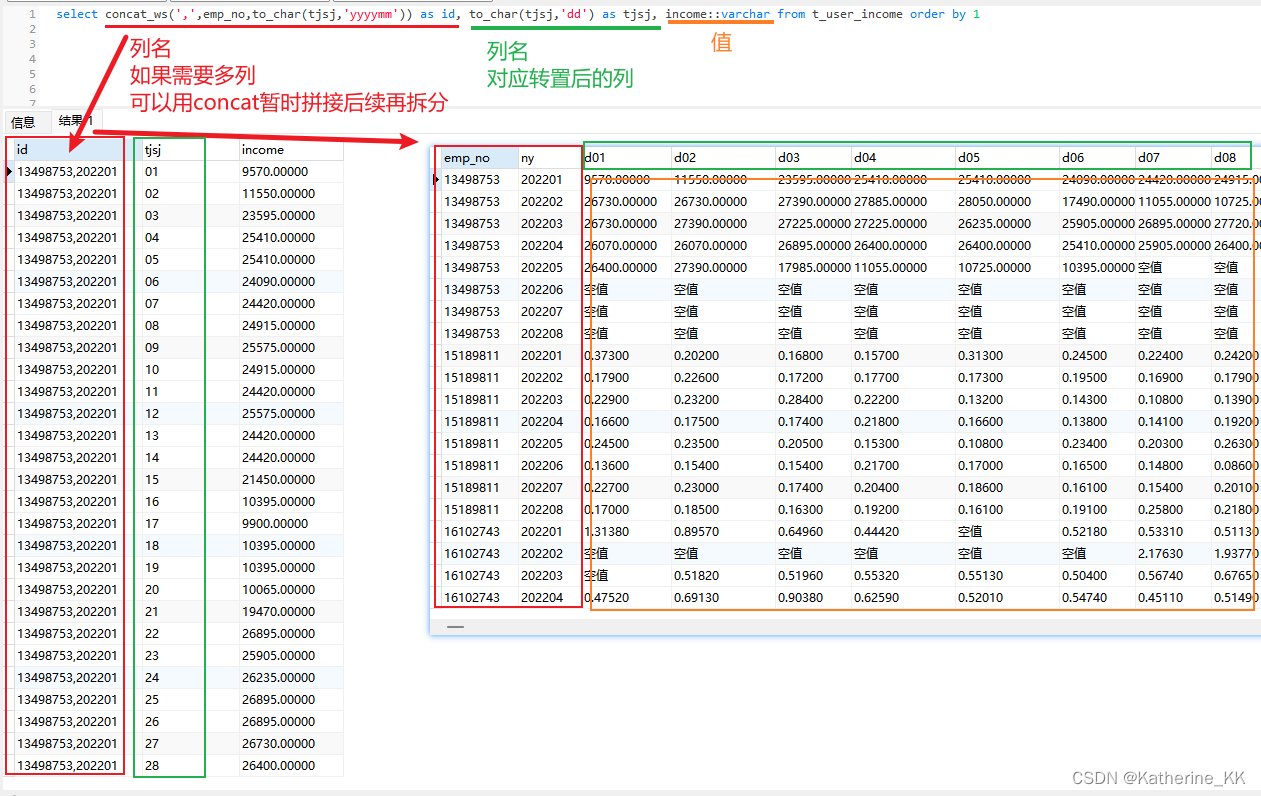
2- 值: 数据类型必须一致
因此此处income提前转为varchar
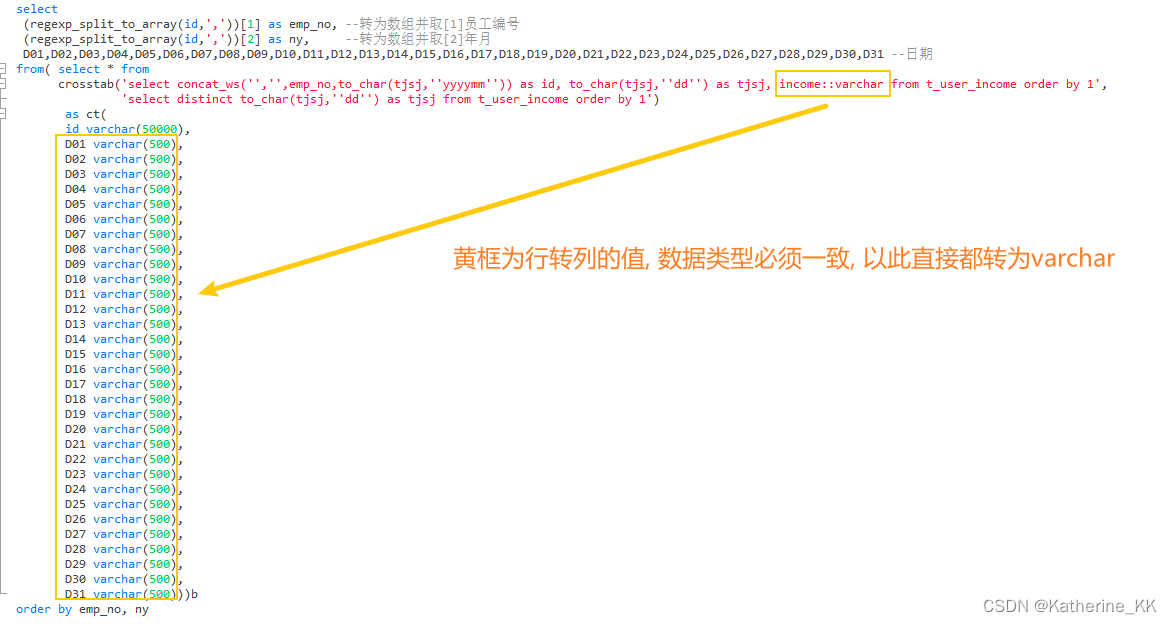
B拆解
select distinct to_char(tjsj,'dd') as tjsj from t_user_income order by 11- SELECT 列名[转置的列] FROM TABLE
2- 结果行必须与结果展示的列一致
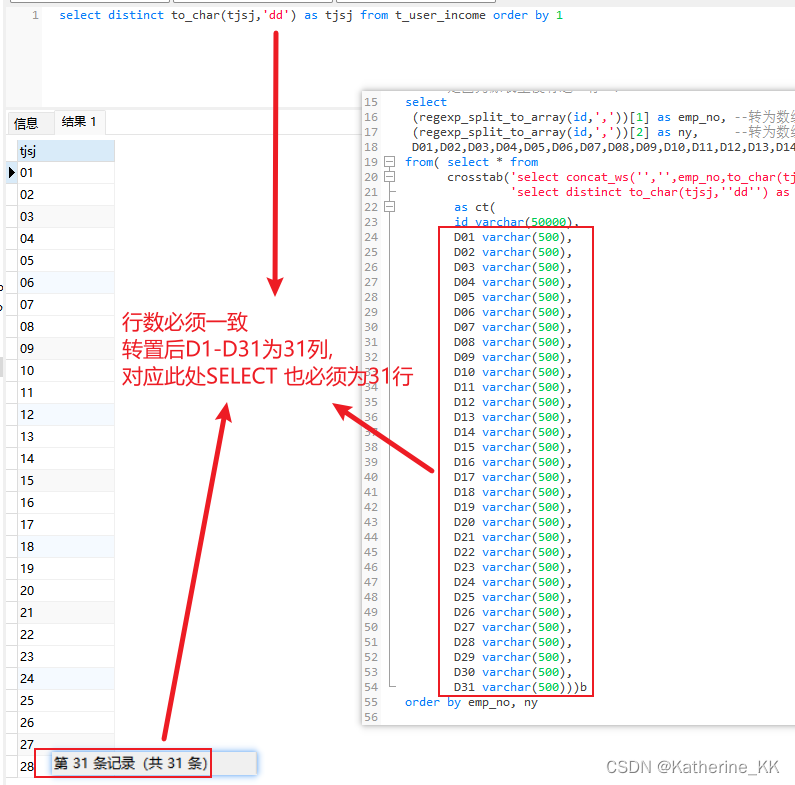
C拆解

可见C步骤后 ID列不是我们最终想要的结果, 因此在最外嵌套一层把ID列拆成emp_no 及 ny列即可
(regexp_split_to_array(id,','))[1] as emp_no, --转为数组并取[1]员工编号(regexp_split_to_array(id,','))[2] as ny, --转为数组并取[2]年月法二: 模块 - 利用INSERT
N天后补充
法三: CASE WHEN
例一
原表(左)及现实结果表(右)展示:

第一步: 先按照科目分开, 符合条件的设置分数,不符合的给置零
select name as '姓名',(case course when '语文' then score else 0 end) as '语文',(case course when '数学' then score else 0 end) as '数学',(case course when '英语' then score else 0 end) as '英语'
from course_score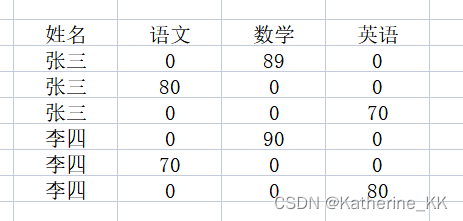
第二步: 然后再按照名字group by ,对分数求max
select name as '姓名',max(语文) as '语文',max(数学) as '数学',max(英语) as '英语'
from (select name as '姓名',(case course when '语文' then score else 0 end) as '语文',(case course when '数学' then score else 0 end) as '数学',(case course when '英语' then score else 0 end) as '英语'from course_score) s
group by name;例二 (crosstab方法的例子)
select emp_no,ny,
max(D01) as D01,
max(D02) as D02,
max(D03) as D03,
max(D04) as D04,
max(D05) as D05,
max(D06) as D06,
max(D07) as D07,
max(D08) as D08,
max(D09) as D09,
max(D10) as D10,
max(D11) as D11,
max(D12) as D12,
max(D13) as D13,
max(D14) as D14,
max(D15) as D15,
max(D16) as D16,
max(D17) as D17,
max(D18) as D18,
max(D19) as D19,
max(D20) as D20,
max(D21) as D21,
max(D22) as D22,
max(D23) as D23,
max(D24) as D24,
max(D25) as D25,
max(D26) as D26,
max(D27) as D27,
max(D28) as D28,
max(D29) as D29,
max(D30) as D30,
max(D31) as D31
from(select emp_no,to_char(tjsj, 'yyyymm') as ny,case when to_char(tjsj,'dd')='01' then income::varchar else 0::varchar end as D01,case when to_char(tjsj,'dd')='02' then income::varchar else 0::varchar end as D02,case when to_char(tjsj,'dd')='03' then income::varchar else 0::varchar end as D03,case when to_char(tjsj,'dd')='04' then income::varchar else 0::varchar end as D04,case when to_char(tjsj,'dd')='05' then income::varchar else 0::varchar end as D05,case when to_char(tjsj,'dd')='06' then income::varchar else 0::varchar end as D06,case when to_char(tjsj,'dd')='07' then income::varchar else 0::varchar end as D07,case when to_char(tjsj,'dd')='08' then income::varchar else 0::varchar end as D08,case when to_char(tjsj,'dd')='09' then income::varchar else 0::varchar end as D09,case when to_char(tjsj,'dd')='10' then income::varchar else 0::varchar end as D10,case when to_char(tjsj,'dd')='11' then income::varchar else 0::varchar end as D11,case when to_char(tjsj,'dd')='12' then income::varchar else 0::varchar end as D12,case when to_char(tjsj,'dd')='13' then income::varchar else 0::varchar end as D13,case when to_char(tjsj,'dd')='14' then income::varchar else 0::varchar end as D14,case when to_char(tjsj,'dd')='15' then income::varchar else 0::varchar end as D15,case when to_char(tjsj,'dd')='16' then income::varchar else 0::varchar end as D16,case when to_char(tjsj,'dd')='17' then income::varchar else 0::varchar end as D17,case when to_char(tjsj,'dd')='18' then income::varchar else 0::varchar end as D18,case when to_char(tjsj,'dd')='19' then income::varchar else 0::varchar end as D19,case when to_char(tjsj,'dd')='20' then income::varchar else 0::varchar end as D20,case when to_char(tjsj,'dd')='21' then income::varchar else 0::varchar end as D21,case when to_char(tjsj,'dd')='22' then income::varchar else 0::varchar end as D22,case when to_char(tjsj,'dd')='23' then income::varchar else 0::varchar end as D23,case when to_char(tjsj,'dd')='24' then income::varchar else 0::varchar end as D24,case when to_char(tjsj,'dd')='25' then income::varchar else 0::varchar end as D25,case when to_char(tjsj,'dd')='26' then income::varchar else 0::varchar end as D26,case when to_char(tjsj,'dd')='27' then income::varchar else 0::varchar end as D27,case when to_char(tjsj,'dd')='28' then income::varchar else 0::varchar end as D28,case when to_char(tjsj,'dd')='29' then income::varchar else 0::varchar end as D29,case when to_char(tjsj,'dd')='30' then income::varchar else 0::varchar end as D30,case when to_char(tjsj,'dd')='31' then income::varchar else 0::varchar end as D31from t_user_income)a group by emp_no,nyorder by emp_no,ny文档来源:
PostgreSQL: Documentation: 11: F.38. tablefunc