上文提过了 hash取余算法和hash一致性算法
一致性hash算法是为了减少节点数目发生改变时尽可能的减少数据迁移
将所有的存储节点排在首位相连的Hash环上,每个key在计算hash后会顺时针找到临近的存储节点。
而当有节点加入或退出时,仅影响该节点在hash环上顺时针相邻的节点。
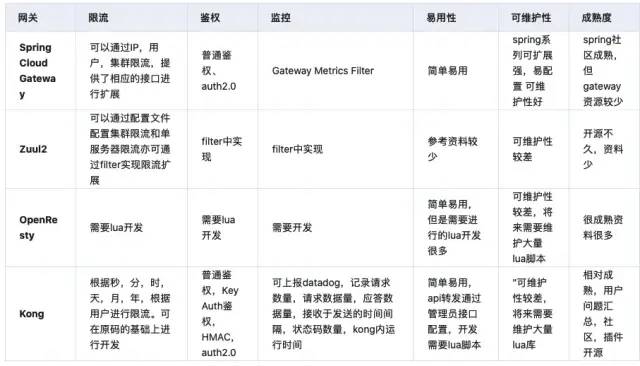
优点
加入或删除时节点,只影响Hash环中顺时针方向的相邻节点。
加入时:将相邻的节点一部分数据转移的新节点
删除时:将相邻的节点添加删除节点的数据
缺点
数据的分布与节点位置有关,而这些节点不均匀的分布在Hash换上,所以每个
redis实例存储的数据也不均匀,会造成数据倾斜
刚刚提到一致性hash算法有数据倾斜问题,为了解决这个问题便又了
hash槽分析算法。
哈希槽
哈希槽时机就是一个数组,数组【0,2^14-1】形成了哈希槽空间。
哈希槽用来解决均匀分配问题,在数据和节点之间又加了一层,把这层称为hash槽,用于管理数据和节点之间的关系,现在就相当于节点上方的是槽,槽里放的数据。
一个集群只能有16384个槽,编号0-16383,这些槽会分配给各个主节点。同时集群会记录槽与节点的关系。解决槽和节点的映射关系后,接下来
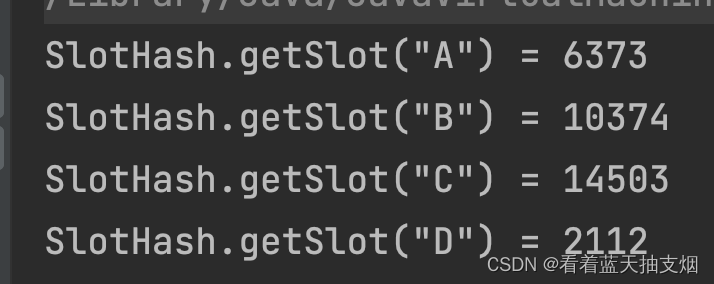
堆key进行计算求出槽位。hash_solt=CRC16(key) mod 16384。如果要增减节点,则以槽为单位移动数据,这样数据移动问题就更加简单了
为什么redis集群的最大槽数是16384个?
CRC16算法可以产生的hash值有 2^16 bit,
该算法可以产生2^16个值,那为何不用
Hash_solt=CRC16(key) mod 65536呢?
正常的心跳包数据带有节点的完整配置。
原因1: 如果槽位位65536,发送心跳消息的消息头达8k,发送心跳包过于庞大。
在心跳消息的消息头中最占空间的是myslots[CLUSTER_SOLT/8]。
当槽位为65536时,这块大小是:65536/8/1024=8kb
当槽位为16384时,这块大小是:16384/8/1024=2kb
因为每一秒钟(心跳配置间隔),redis节点需要发送一定数量的ping消息作为心跳包。如果每条消息的消息就占8kb,浪费带宽。
原因2:redis cluster节点数量超过1000个
redis集群节点越多,心跳包的消息体内携带的数据越多。如果节点超过1000个,会导致网路拥堵,因此redis作者不建议将redis cluster节点数量超过1000个。那么对于节点数在1000以内的rediscluster集群,16384个槽位够用了,没必要扩展到65536个。
原因3:槽位越小,节点少的情况下,压缩比高,容易传输
redis主节点的配置信息中他所负责的hash槽是通过一张bitmap的形式来保存的,在传输过程中会对bitmap进行压缩,
bitmap的填充率=slots / N (N表示节点数)
也就是说slots越小,填充率就会越小,压缩率就会越高,传输效率就会越高
其他
redis 集群也不能保证强一致性(C)可以保证AP。在一些特定的情况下,redis集群可能会丢掉一些被系统受到到写入请求命令。就是主机突然挂了,还没来得急同步从机。