说明:部分内容摘自参考文献,如有侵权,联系删除
模型概念
计算量 FLOPs
- FLOPs:
floating point operations指的是浮点运算次数,理解为计算量,可以用来衡量算法/模型时间的复杂度, 单位是FLOPs。 - FLOPS:(全部大写),
Floating-point Operations Per Second,每秒所执行的浮点运算次数,理解为计算速度, 是一个衡量硬件性能/模型速度的指标,即一个芯片的算力。 - MACCs(MACs):
multiply-accumulate operations,乘-加操作次数,一次乘法+一次加法为一个MACCs,MACCs大约是FLOPs的一半。
内存访问代价 MAC(又称为访存量)
- MAC:
Memory Access Cost内存访问代价。指的是输入单个样本(一张图像),模型完成一次前向传播所发生的内存交换总量,即模型的空间复杂度,单位是Byte。
计算平台概念
- 计算平台主要有两个指标:算力 π \pi π和 带宽 β \beta β。
-
算力:计算平台每秒完成的最大浮点运算次数,单位是
FLOPS; -
带宽:计算平台一次每秒最多能搬运多少数据(每秒能完成的内存交换量),单位是
Byte/s。 -
计算强度上限 I m a x I_{max} Imax:上面两个指标相除得到计算平台的计算强度上限。它描述了单位内存交换最多用来进行多少次计算,单位是
FLOPs/Byte。
I m a x = π β I_{max} = \frac{\pi}{\beta} Imax=βπ
这里所说的“内存”是广义上的内存。对于
CPU而言指的就是真正的内存(RAM);而对于GPU则指的是显存。
- 和计算平台的两个指标相呼应,模型也有两个主要的反馈速度的间接指标:计算量
FLOPs和访存量MAC,具体含义如前所述。
- 模型的计算强度 I I I : I = F L O P s M A C I = \frac{FLOPs}{MAC} I=MACFLOPs,即计算量除以访存量后的值,表示此模型在计算过程中,每
Byte内存交换到底用于进行多少次浮点运算。单位是FLOPs/Byte。可以看到,模型计算强度越大,其内存使用效率越高。 - 模型的理论性能 P P P :我们最关心的指标,即模型在计算平台上所能达到的每秒浮点运算次数(理论值)。单位是
FLOPS or FLOP/s。Roof-line Model给出的就是计算这个指标的方法。
Roof-line Model
其实 Roof-line Model 说的是很简单的一件事:模型在一个计算平台的限制下,到底能达到多快的浮点计算速度。更具体的来说,Roof-line Model 解决的,是“计算量为A且访存量为B的模型在算力为C且带宽为D的计算平台所能达到的理论性能上限E是多少”这个问题。
Roo-fline Model参考
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-at6EVo7t-1689311923054)(media/image-20230712175046360.png)]](https://img-blog.csdnimg.cn/c8d25094cb774db7853d35b5aba54ddc.png)
-
理论上模型强度刚超过 I m a x I_{max} Imax值最好,此时能够充分利用显卡的算力,此时显卡的算力越好,计算速度越快;
-
roof-line模型只是理论值,具体模型的运行速度以实测为主;
-
模型推理时间(理论值):在不同平台上以实际测试为准
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-3P2Yhpzh-1689311923054)(media/image-20230713112904332.png)]](https://img-blog.csdnimg.cn/4c956a7674df419c8528e4cfcc509ea3.png)
一句话总结:对于访存密集型算子,推理时间跟访存量呈线性关系,而对于计算密集型算子,推理时间跟计算量呈线性关系。
按照 RoofLine 模型,在计算密集区,计算量越小,确实推理时间越小。但是在访存密集区,计算量与推理时间没关系,真正起作用的是访存量,访存量越小,推理的时间才越快。在全局上,计算量和推理时间并非具有线性关系。
yolov5及模型统计工具
pytorch模型统计工具
-
torchsummary(不推荐)
-
只对模型参数量相关指标进行统计,
-
使用方法如下:
from torchsummary import summary summary(model, (3, 224, 224)) # 只能统计参数量,不推荐使用
-
-
torchstat(推荐)
-
统计模型的参数量、计算量、访存量等指标,且会针对模型的每层指标进行打印;
-
部分指标与常见含义不同,具体会结合yolov5的指标进行介绍
-
只对常见网络层进行统计;
-
使用方法如下:
rom torchstat import stat stat(model.cpu(), (3, 384, 1280))
-
-
thop(推荐)
-
统计模型的参数量和计算量;
-
部分指标与常见含义不同,具体会结合yolov5的指标进行介绍;
-
只对常见网络层进行统计;
-
使用方法如下:
from thop import profile from thop import clever_format input = torch.randn(26, 3, 384, 1280) flops, params = profile(model.cpu(), inputs=(input,)) flops, params = clever_format([flops, params], '%.3f') print('thop flops:', flops, 'params: ', params) #计算参数量和计算量
-
yolov5m指标统计与说明
基于yolov5m检测模型进行统计,stat(model, (3, 384, 1280)), stat中加入了对SiLU的支持
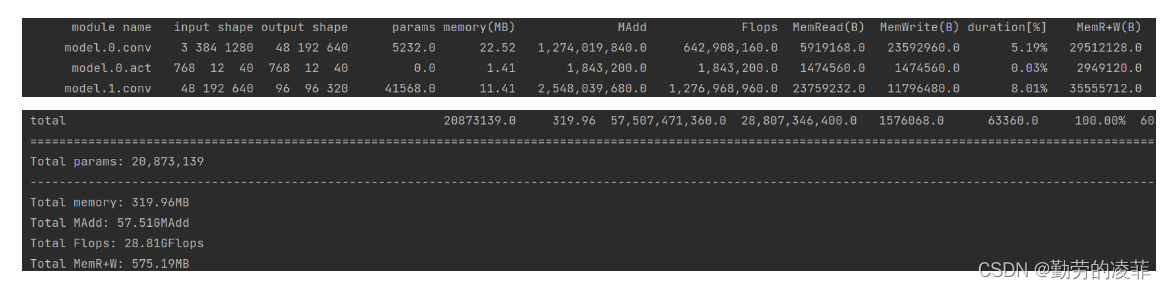
torchstat统计结果如下(Upsample Concat层不支持, 默认batchsize为1)
计算过程:
第0行卷积层的计算(每个参数为FP32占4个字节)
# 参数量
params = 卷积核参数量(卷积核为48x3x6x6 bias为True)= k*k*c_in*c_out+c_out = 6*6*3*48+48 = 5232# 访存量
memory = [(卷积核参数量+输出特征图参数量)*4/1024/1024]MB # 4是因为FP32包含4个字节= [((k*k*c_in*c_out+ cout) + H_out*W_out*c_out)*4/1024/1024]MB= [(6*6*3*48+48) + 192*640*48]*4/1024/1024 MB = 22.52MB # 乘法和加法的总的运算次数
MAdd = 乘法运算次数 + 加法运算次数 #为常说的FLOPs= 卷积的乘法运算次数 + 卷积中的加法运算次数 + 偏置加法运算次数= k*k*c_in*H_out*W_out*c_out + (k*k*c_in-1)*H_out*W_out*c_out + H_out*W_out*c_out= 6*6*3*192*640*48 + (6*6*3-1)*192*640*48 + 192*640*48= 637009920+631111680+5898240 = 1274019840# 浮点运算次数
Flops = 卷积中的乘法浮点运算 + 偏置的浮点运算 #忽略卷积的加法= k*k*c_in*H_out*W_out*c_out + H_out*W_out*c_out= 6*6*3*192*640*48 + 192*640*48= 637009920 + 5898240 = 642908160# 读内存
MemRead(B) = (输入特征图参数量 + 卷积核参数量)*4B #FP32=4Byte= (3*384*1280 + 6*6*3*48+48)*4B = 5919168 B# 写内存
MemWrite(B) = (输出特征图参数量)*4B= 48*192*640*4 = 23592960B# 持续时间占比
duration(%) = (module_endtime - module_starttime)/total_duration# 内存读写量
MemR+W(B) = MemRead + MemWrite = 5919168+23592960 = 29512128 B# TOTAL
Total params: 20873139=20.873139M # 模型的总参数量
Total memory: 319.96MB # 模型的访存量
# 1G=10^9
Total MAdd: 57.51GMAdd # 模型乘法操作和加法操作的次数 #常规意义的FLOPs,但Concat Unsample层没计算
Total Flops: 28.81GFlops # 模型浮点运算次数 非常规意义的FLOPs
Total MemR+W: 575.19MB # 根据当前的输入特征图 计算的读写内存量# 模型计算强度
I = 57.51X10^9/(319.96*1024*1024) = 179.74FLOPs/Bytes
注意:
- 以上统计是基于batchsize=1,当batchsize!=1时,除params(参数量)和duration外,其他参数都要乘以batchsize;
- 关于访存量的疑问:访存量是输入单个样本,模型完成一次前向传播过程中所发生的内存交换总量,即模型各层权重参数的内存占用与每层所输出的特征图的内存占用之和。当batchsize不为1时,每层输出的特征图内存占用肯定是batch为1的batchsize倍,但权重参数是否需要乘以batchsize呢,请各位大佬指教,后续处理都是按照乘以batchsize处理的,因为torchstat计算MemRead时乘以batchsize;
thop统计结果
flops: 747.573G params: 20.873M # 此处的flops其实是MACCs 57.51/2*26(batchsize)=747.63GFlops
yolov5自统计结果
20873139 parameters, 0 gradients, 47.9 GFLOPs # yolov5是采用thop统计的,但计算的是输入为(1, 3, 640, 640)时的指标,计算时对profile输出的FLOPsx2
平台计算强度
名词解释
- TFLOPS(teraFLOPS)等于每秒一万亿(=10^12)次的浮点运算。FLOPS(Floating-point operations per second的缩写),即每秒浮点运算次数。
- TOPS(Tera Operations Per Second的缩写),1TOPS代表处理器每秒钟可进行一万亿次(10^12)操作。
- DMIPS:Dhrystone Million Instructions executed Per Second,每秒执行百万条指令,用来计算同一秒内系统的处理能力,即每秒执行了多少百万条指令。
显卡参数
显存带宽
-
可通过该网站获取显卡详细惨https://developer.nvidia.com/zh-cn/cuda-gpus#compute, 更详细的参数请参考https://technical.city/zh/video/GeForce-RTX-3060
-
以下为RTX 3060 12G显存为例:

![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-89vxnAlZ-1689311923056)(media/image-20230713150205603.png)]](https://img-blog.csdnimg.cn/67cd4be7a93b423d8b3a4a80a59dc4ea.png)
Boost Clock
OC为overlocking 超频频率
Base Clock
核心频率. 显卡处理图像的频率大小,即显卡的核心频率越高,它处理图像的速度和效率也就更高。
Standard Memory Config
标准显存配置, 12GB的GDDR6显存类型
Memory Interface Width
显存位宽, 192-bit
内存通过量: Memory Bandwidth
显存带宽:在一定时间内可交换的数据量, 它以byte/s为单位.
根据上述指标,RTX 3060 12G显卡显存带宽 β = 360 G B / s \beta=360GB/s β=360GB/s
显存算力
-
利用Cuda runtime API 获取显卡相关信息,工具采用calc_peak_gflops.cpp
GPU count = 1 =================GPU #0================= GPU Name = NVIDIA GeForce RTX 3060 # GPU名称 Compute Capability = 8.6 # GPU算力,此处的算力指的是架构版本号 GPU SMs = 28 # SM多流处理器个数 GPU CUDA cores = 3584 # cuda 核心个数 GPU SM clock rate = 1.777 GHz # 核心频率 #base clock GPU Mem clock rate = 7.501 GHz # 显存频率 FP32 Peak Performance = 12737.536 GFLOPS # 单精度浮点峰值算力 FP16 Peak Performance = 25475.072 GFLOPS # 半精度浮点峰值算力-
GPU SM clock rate与官网的base clock不大一样,实际使用时,采用真实的base clock
-
显卡算力计算公式如下:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-rHpRjdKI-1689311923056)(media/image-20230713164728165.png)]](https://img-blog.csdnimg.cn/1feb93dff4ab45e0a4b8d1749dc2b84b.png)
算力与指令吞吐量的对应关系如下:
算力 吞吐量 3.0 3.2 3.5 3.7 192 5.0 5.2 5.3 128 6.0 64 6.1 6.2 128 7.0 7.2 7.5 64 8.0 64 8.6 128 RTx3060显卡算力手动计算结果:
peakFP32FLOPS = 1.777x28x128x2=12737.536GFLOPS 与工具计算一致
peakFP16FLOPS = 2*peakFP32FLOPS
-
显卡计算强度上限
I m a x = 算力 带宽 = 12737.536 G F L O P S 360 G B / s = 35.38 F L O P s / B y t e I_{max}=\frac{算力}{带宽}=\frac{12737.536GFLOPS}{360GB/s}=35.38FLOPs/Byte Imax=带宽算力=360GB/s12737.536GFLOPS=35.38FLOPs/Byte
计算平台 VS yolov5m
根据上述计算可以看到模型计算强度 I = 179.74 F L O P / B y t e s > 计算平台强度上限 I m a x = 35.38 F L O P s / B y t e I=179.74FLOP/Bytes > 计算平台强度上限I_{max}=35.38FLOPs/Byte I=179.74FLOP/Bytes>计算平台强度上限Imax=35.38FLOPs/Byte
因此在此机器上,该模型的计算时间取决于显卡算力;
评估模型对显卡性能需求
- 当前模型都是在显卡上部署的,未针对嵌入式平台进行优化,因此当前模型几乎都属于计算密集型,显卡的算力越高理论上推理速度越快
- 当后续在嵌入式平台使用时,一般采用算力比较低的显卡,此时需要对模型进行优化,使得模型称为访问密集型,需要关注显卡的带宽,带宽越大意味推理速度越快
参考
- 轻量级模型设计与部署总结
- Rooflline Model与深度学习模型的性能分析
- 端侧模型性能优化——Flops与访存量的坑
- 快速评估算法对GPU性能需求
- Cuda core和Tensor Core的区别
- 聊聊GPU峰值计算能力
- 快速评估算法对GPU性能要求