目录
一 TiKV架构和作用
二 数据持久化
1 RocksDB:写入
写入过程
第一步 :WAL 写日志 (磁盘日志)
第二步:写MemTable (内存中)
第三步 : 转存为immutable MemTable(内存中)
第四步: 刷盘 (从内存写磁盘)
RocksDB 写入磁盘
2 RocksDB 查询
查询过程
布隆过滤器
3 RocksDB 列簇CF Column Families
- TiKV架构和作用
- TiKV持久化和读取
- TiKV如何提供MVCC和分布式事务支持
- TiKV基于Raft算法的分布式一致性
- TiKV的Coprocessor
一 TiKV架构和作用

二 数据持久化
TiKV数据持久化是靠集成在内部的rocksdb,在tikv中有两个rocksdb实例的,一个负责存储KV ,另一个负责存储 raft log 也就是复制日志
tikv 没有选择直接将数据 存储在磁盘上,而是将数据存储在一个成熟的存储引擎中 rocksdb
rocksdb 在tikv中就是负责数据落地,是一款非常优秀开源的单机的数据存储引擎,可以满足我们单机存储数据的需求,
你可以认为rocksdb 是一个很大的map ,其中存储了key value的键值数据

1 RocksDB:写入

写入过程
通过一次数据写入了解数据写入全流程 比如要写(1,'Tom')这条数据到users表中
第一步 :WAL 写日志 (磁盘日志)
首先写数据之前先写日志, 即WAL机制( write ahead log)日志先写,WAL日志有两个,循环覆盖使用。
目的:先写日志是为了防止掉电内存数据丢失 ,crash recovery的能力 。当掉电时内存数据丢失,但是wal日志中还存在数据的操作日志,可以重读日志把数据恢复出来( crash safe)
相关参数 sync_log = true设置为true时 ,直接调用操作系统的fsync写入到磁盘中,不会经过操作系统的缓存。
第二步:写MemTable (内存中)
然后再写入到 MemTable ,MemTable是内存中的数据结构,一般采用跳跃表 /搜索树保证数据的有序性。
MemTable 同时服务于读和写 ,最新写入的数据在MemTable,即MemTable中的数据永远是最新的。 读的话也是从MemTable中读。
第三步 : 转存为immutable MemTable(内存中)
当数据追加到MemTable到达一定数量之后 即参数 write_buffer_size 设置大小后 ,就会转存到 immutable MemTable中 。
之后rocksdb重新开辟一个MemTable。 Immutable Memtable 这样就形成了 , Immutable Memtable 就是需要刷到磁盘的文件,所以 Immutable Memtable就是Memtable刷新到磁盘中 成为SST( SSD table)的一个中间状态。
为什么要有 Immutable Memtable ?
如果直接从 Memtable 刷新到磁盘 会有IO等待,客户端写入会有阻塞 。引入 Immutable Memtable是为了防止写阻塞的。
第四步: 刷盘 (从内存写磁盘)
Immutable Memtable有一个就会刷到磁盘。
如果刷盘较慢,当 Immutable Memtable 如果达到5个 就会触发流控 write stall 。write stall 是rocksdb的一个自我保护机制,客户端写入太快了,刷磁盘速度跟不上,就会出现限速,即写入MemTable的速度限制起来,从客户端的现象来看就是写入变慢了,通过日志可以看到现象。
如何解决:优化存储 或者 调高触发write stall 的参数值。
RocksDB 写入磁盘

磁盘中的文件是分层组织的,每一层 Level 1 Level 2.. Level n
Level 0 比较特殊, Level 0就是 Immutable Memtable的一个复刻,内容都是是相同的,如果Level 0的文件达到 达到四个之后,就会触发compaction,每一层都会切割成一个一个的SST Table,就是咱们说的SST 文件,这里的每个SST 文件都是键值对,是按照Key排序的。
如果需要查找某个key,就会用二分查找法查找SST文件,如果在这个文件中则返回,如果不在则查找另一个文件。
SST文件是如何形成?
Level 0写满4个以后,就会往Level 1合并,合并的时候会压缩并按照key排序。当Level 0又写满4个,会重复上面的步骤。当Level 1达到256M之后就会往Level 2合并。
所以Level 0 的SST文件的大小 = immutable Table = MemTable = write_buffer_size
Level1 SST文件大小 = 4*write_buffer_size?
写入总结:
写日志(wal),写MemTable后一次写入就算完成了,其余的都是在后台完成。这样写入就会很快速,只需要一次磁盘IO 和内存IO 。相比于B+数 ,需要多次磁盘IO 找到数据位置。这样就将随机写转换为顺序写。
对于删除,更新操作:
不去实际删除实际的数据 ,只需要在memTable 中写入delete key = 123;更新操作同理。所以rocksdb对写入非常优化,每次写入不需要定位原来的数据在哪里,只需要把操作放到memTable 即可
2 RocksDB 查询
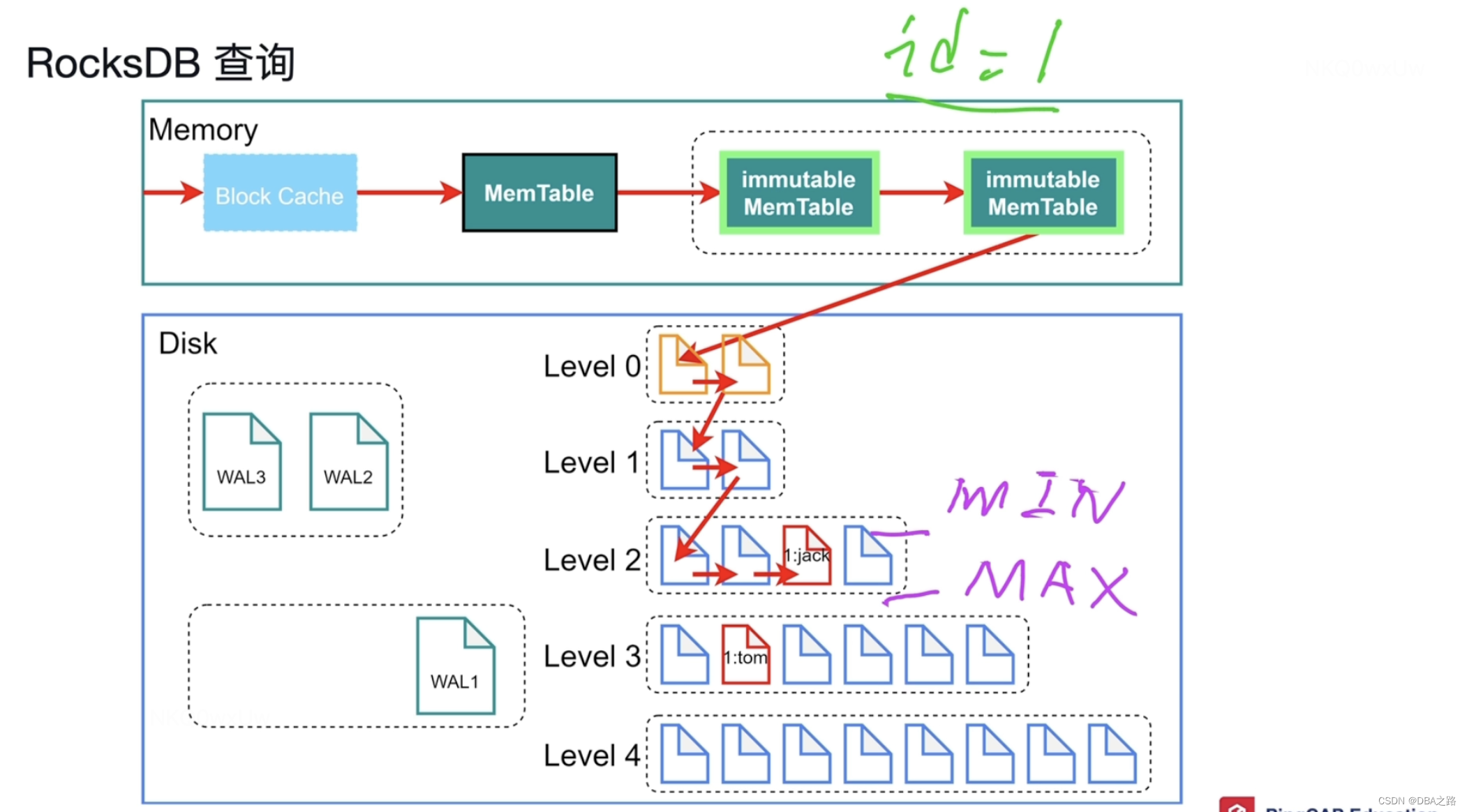
查询过程
相比于b+树来说 RocksDB查询会比较复杂 。
但是对于查询操作,就比较复杂,需要依次访问 blockCache -->MEMTable--> Immutable -->MEMTable,
blockCache 存储最近最常读的数据,如果数据在blockCache就直接从内存中读取返回,如果不在blockCache中 就继续往下找 MEMTable ,如果还是没有命中 继续找 Immutable MEMTable,如果还是没有命中继续向下找Level 0,因为新的数据永远在老的数据上面,所以查找到后可以直接返回
具体到某个SST文件 怎么读取 会把KEY 按最小值和最大值排序,如果在这个区间 读取,如果不在 继续想下层查找
布隆过滤器
1978年发明
可以帮你判断这个集合中的元素是否存在 ,
如果布隆过滤器说这key在这个文件中,那么这个key 不一定在这个文件中。
如果布隆过滤器说这key不在这个文件中,那么这个key 一定不在这个文件中。
3 RocksDB 列簇CF Column Families
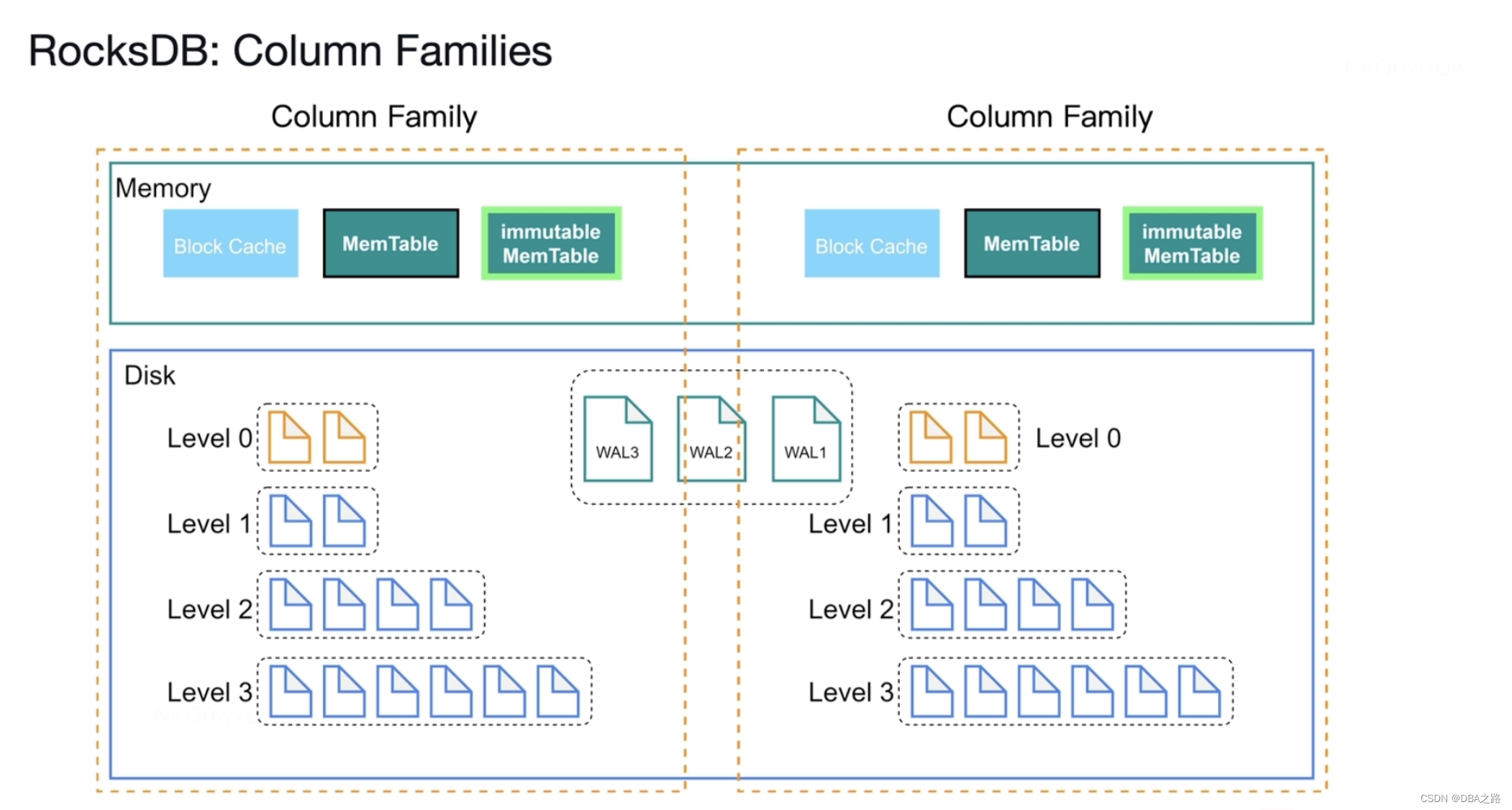
作用:可以将不同的表分开存储 ,RocksDB的数据分片技术。
写入的时候可以指定写入到那个列簇
如果写入的时候不指定列簇 默认的叫default 列簇
write (CF1,id name,age)
write (CF1,id addr,tel)
WAL日志不分,共享一份WAL日志
CF 是分布式事务和 ??的基础,先了解这个概念