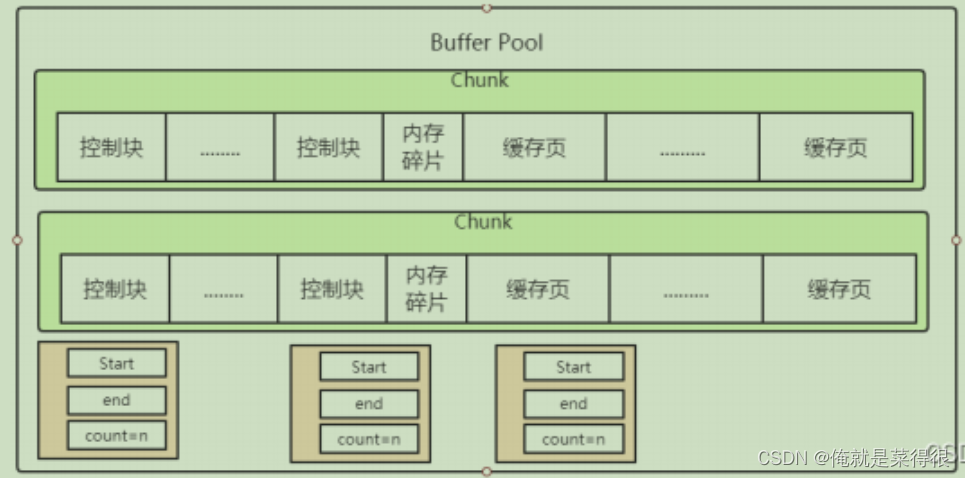
第1讲 计算机回答问题、写诗难吗?
- ChatGPT是基于语言模型的自然语言处理系统。
- 让计算机回答问题并不是一件高不可攀的事情,在今天,让它做得比人好是完全能够办得到的。
- 我们让ChatGPT做的事情,核心有两个,一个是理解自然语言,明白人的意图;另一个是产生自然语言的文本,满足人的要求。
第2讲 ChatGPT的本质是什么?
- 语言模型不是逻辑框架,不是生物学的反馈系统,而是由数学公式构建的模型。
- 今天对于语言模型参数的统计并不是简单的数数,而是要用很复杂的机器学习方法反复计算。
第3讲 语言模型是如何进化的?
语言模型的发展大致经历了三个阶段:
- 上个世纪90年代之前,当时贾里尼克等人用它解决了语音识别的问题。
- 90年代后,语言模型加入了语法和语义信息,还出现了自适应的语言模型。
- 2010年前后,Google开发了深度学习的工具Google大脑,能够更有效地利用计算资源,也让模型计算出的概率越来越准确。
第4讲 ChatGPT的能力边界在哪?
语言模型能做的事情可以分为三类:
- 信息形式转换。这是将信息从一种形式转换为另一种形式,无论是语音识别还是机器翻译,都属于这一类。
- 根据要求产生文本。今天ChatGPT做的主要工作,像回答问题、回复邮件、书写简单的段落,都属于这一类。
- 信息精简,把更多的信息精简为较少的信息。为一篇长文撰写摘要,按照要求进行数据分析,分析上市公司的财报,都属于这方面的工作。
第5讲 ChatGPT的回答从哪里来?
- 利用语言模型回答问题,不是一个问题对一个答案这样简单的匹配,而是对于问题给出多个答案,然后根据答案的概率排序,返回一个最可能的答案。
- 简而言之,回答问题也好、写作短文也好,ChatGPT的答案都基于它对现有事实的抽取和整合,或者说归纳总结。
第6讲 ChatGPT有哪些固有缺陷?
- ChatGPT的缺陷有些是可以改进解决的,有些则是ChatGPT固有的问题,甚至是今天机器学习方法固有的问题,要解决是很难的。
- 语言模型进化到今天,虽然进步了很多,但依然是一个利用已有的信息预测其他信息的模型,这个性质没有改变。
- 通过人为调高或者调低一些参数来控制ChatGPT的输出结果是很难的,人工干预可能导致更大的不公平。
第7讲 ChatGPT需要什么资源?
训练语言模型的三个限制,分别是数据、算力和算法:
- 数据:训练语言模型所需的数据量是极其庞大的。不是每个企业都能得到所有的这些数据。
- 算力:随着时间的推移,人们对人工智能的要求也在不断提高,需要的算力也在不断增加。
- 算法:除了算力之外,基础的自然语言处理技术,也就是算法,也是实现ChatGPT这些产品必不可少的条件。
第8讲 今天人工智能的边界在哪里?
- 无论是什么样的计算机,都只能解决世界上很小一部分问题。
- ChatGPT的边界是人工智能的边界,而人工智能的边界是数学的边界,数学是有边界的。
- 计算能力增加,原来可以计算的问题会算得更快,瞬间解决,但是不可算的还是不可算。
第9讲 ChatGPT为什么会被热炒?
- 如果ChatGPT这件事是一个方向,早一天、晚一天开始这方面的工作差别不大,毕竟追赶别人比自己在前面摸黑探索要快得多。
- 实事求是地讲,ChatGPT既不像很多人讲的那么神奇,也没有那么可怕,但也不是毫无用途。
第10讲 ChatGPT能替代什么人?
- ChatGPT能取代人吗,或者说能抢人的饭碗么吗?简单的答案是—"能’。但是它只会抢特定人的饭碗,而不是所有的人。
- 会被ChatGPT取代的人有三个特点:从事不费体力的工作,不动脑子的工作,或者不产出信息的工作。
- 越是到了各种智能工具不断涌现,做事情越来越便利的时候,从事创造性的工作也就越来越重要。
第11讲 理性看待ChatGPT
- 从投资的角度来说,技术发展带来投资的可能性,但是,当人们对一项技术炒得过热时,其实已经不是投资它的好机会了。
- 从从业的角度来说,做好本职工作的回报一定是最高的。
- 对于普通人,可以对新技术和未来有所期待,但不要觉得自己的好运气从此来了,然后放弃自己擅长的事情,去不擅长的领域寻找什么机会。
第12讲 还有哪些人工智能和科技值得关注?
在ChatGPT之外,还有一些值得关注的人工智能技术和应用:
- 多任务人工智能:GPT-3是所谓以数量实现质量的代表,而多任务的人工智能则是以质量取代数量。
- 生物和医学应用:深度学习在生物和医学上的应用是人工智能行业一个值得关注的应用领域。