介绍:采集珍爱网(仅开始学爬虫,太多方法都不会)
- 必须要有一个账号,当采集多了后会受到限制 要求通过手机App上传身份证等详细信息
- 列表页是post请求 有一个参数找不到规律,详情页面不需要登录 get请求即可

方式一:模拟登录
- 需要:珍爱网账号
- 数据:红色部分,可采集:黄色部分
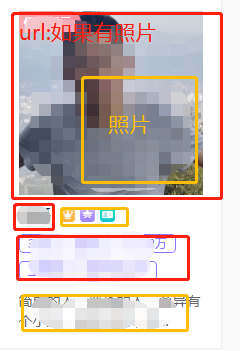
限制:
- 没有上传照片的用户的,详细页面的链接采不了
- (可以通过添加 点击-采集链接 的部分采集详页面的细信息)
采用:selenium爬取珍爱网用户信息
方式二:八爪鱼/后裔采集器+get请求
可以通过采集器采集所有信息(类似于模拟登录 模拟点击采集的原理),但图1采集的数据所在字段是乱的 图2只能整块采集(好像可以通过采集器的xpath还是什么可以处理,但我不会)
![]()

介绍:
- 珍爱网账号
- 用的MongoDB
- 通过采集器采集详细页面的url(后裔:注意设置间隔时间 和 字段检测是否登录),get采集详细信息并进行字段处理
- 采集器采集后的结果
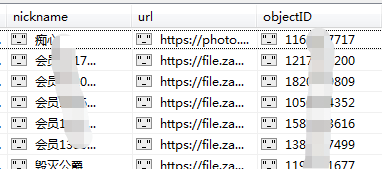
- get请求采集数据结果

- 最终结果