文章目录
- nvidia-smi指令
- 动态刷新GPU信息
- 显存占用高,但是CPU使用率低
- 回头再看
nvidia-smi指令
命令位置:
所以Path中添加环境变量:
C:\Program Files\NVIDIA Corporation\NVSMI
试验一哈:
要注意的点:
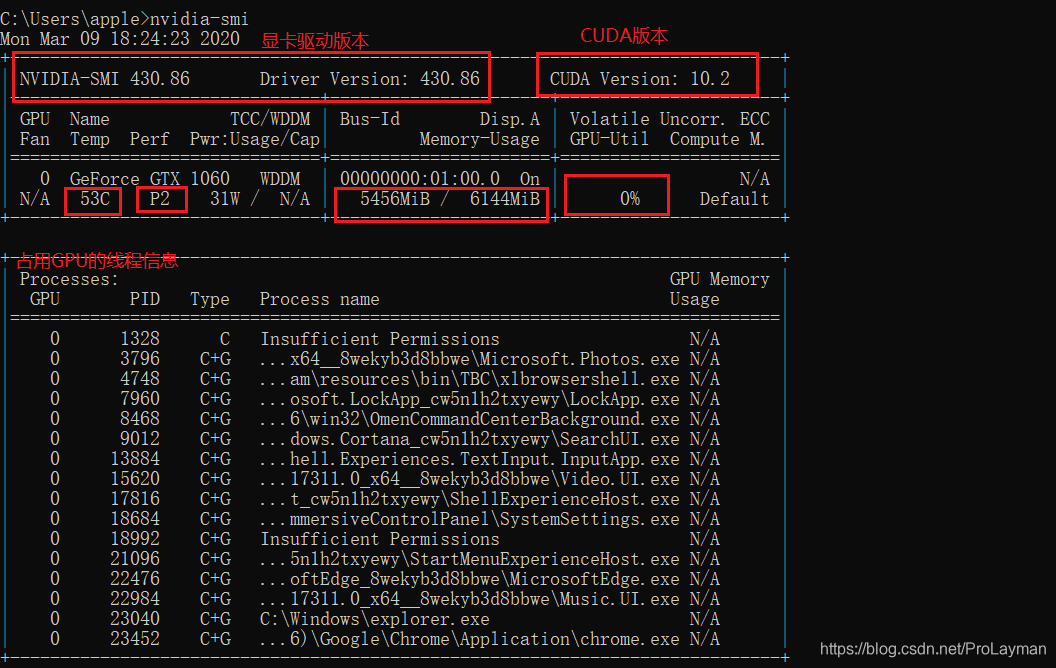
- Driver Version和CUDA Version不是一回事
- CUDA Version实际是环境变量中Path配置的,如果一台机器同时装了多个CUDA,那么这里的CUDA Version显示的是Path中靠前的CUDA版本(和nvcc -V的显示是一样的)
- 下方的GPU使用信息网上有很多资料,但是比较靠谱的资料是去官网查手册,这里不再赘述,只挑几个比较重要的说一下:
- Temp = Temperature,温度
- Perf = Performance,性能,P0-P12,由低到高
- Memory / Usage ,其实下方的数据是“已经使用的显存/总显存”
- GPU-Util,GPU使用率
- 下方的Processes显示的使用GPU的线程信息:GPU序号,线程ID,线程名,GPU显存使用量
- N/A可以理解为无法显示,并不是无限大的意思
动态刷新GPU信息
nvidia-smi -l # L小写字母,不是1
每隔一秒刷新一次GPU信息(执行一次nvidia-smi的结果)
后面可以加上自定义的秒数,如:
nvidia-smi -l 5 # 每隔5秒刷新一次
还有更细粒度的:
nvidia-smi -lms # 每隔1ms刷新一次,( L小写字母,不是1)
当然也可以自定义毫秒数:
nvidia-smi -lms 500 # 每隔500毫秒刷新一次
个人经验,500ms刷新一次比较适合。
PS:nvidia-smi的用法可以nvidia-smi -h查看:

显存占用高,但是CPU使用率低
如之前的图中:
显存占用率:5456MiB/6144MiB = 88.80%
GPU利用率(GPU-Util):0%
(即使100ms刷新一次也捕捉不到GPU利用率的提高)
PS:
这里先补充一个知识,回想一下CPU和内存的关系,同理,GPU和显存的关系同。上图的场景类比于CPU与内存即:内存快占满,但CPU使用率很低,eg:
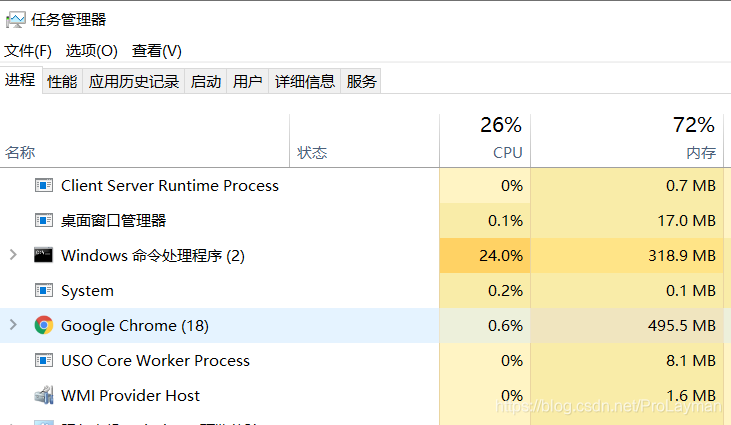
如Java中while(true)创建对象,内存会爆,但是CPU使用率并不高。
上述显卡显存占用率高,GPU利用率低的情况出现在笔记本跑深度学习时,最初以为是显存太低的缘故(load一个batch_size((一次训练的图片数))的数据即过载),换在16G显存的服务器中跑,同样出现该问题: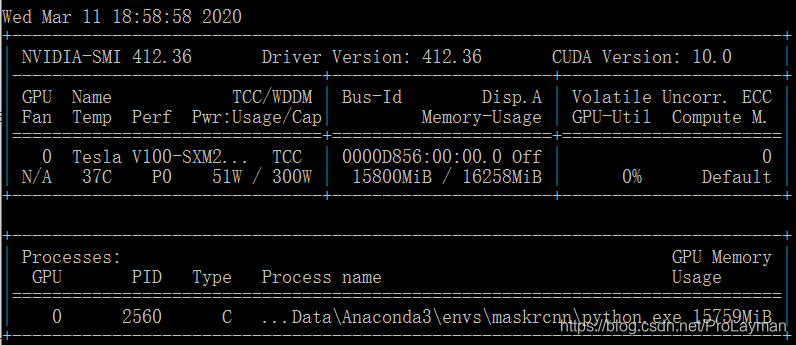
修改batch_size(一次训练的图片数)大小,无效,改大改小(最小到1)都不行。
怎么解决呢?
答:
试了n多的方法,终于找到原因:
训练的原始图片大小为3024 * 4032,实际大小为2-3M,太大了。。。
如果解释为什么,则先了解一个背景知识,类似于CPU与内存的关系,在GPU工作流水线中,也是按照显存准备数据——GPU拿数据运算——显存准备数据——GPU拿数据运算 …的方式工作的。如果图片的分辨率太大,即使一张图片(batch_size为1)放入显存,也直接爆了,GPU利用率当然也无从谈起,外在表现就是显存几乎占满,但同时GPU等不到数据,一直空闲。解决方法是将图片分辨率改小就OK了。
回头再看
回头再看,这个问题的解决思路是应该是这样的:
-
确认代码在GPU上跑了
有两个方法: -
项目下单独建测试文件test.py or 运行项目的训练模型
import os
from tensorflow.python.client import device_lib
os.environ["TF_CPP_MIN_LOG_LEVEL"] = "99"if __name__ == "__main__":print(device_lib.list_local_devices())
运行文件,可以看到输出GPU硬件信息。
或者直接运行项目的训练模型,因为项目的TensorFlow调用了GPU,也会输出类似上面测试代码的运行效果——输出的GPU信息(猜测是TensorFlow内部也有类似上面的打印GPU信息的代码),此时(必须正在运行TensorFLow代码)查看nvidia-smi的线程信息会有python.exe():
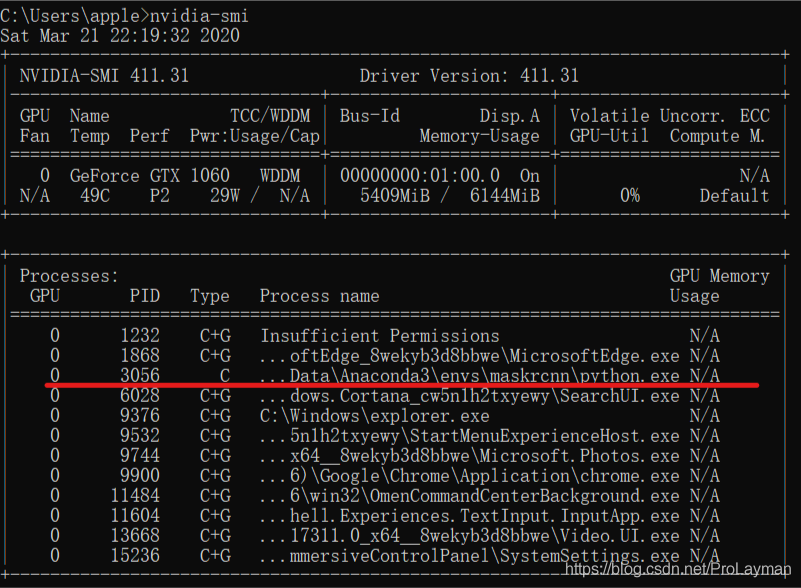
好,已经能够确定TensorFlow调用了GPU跑代码。
② 观察显存和GPU利用率
一定要使用动态刷新nvidia-smi命令,因为有时GPU利用率是跳跃式变化的,同时尽量关
闭其他使用GPU的程序,单独观察tensorflow利用情况。
- 显存占用低,GPU利用率低
很明显,这是因为batch_size太小,显存没完全利用,GPU没有喂饱,尝试增大batch_size - 显存占用高,GPU利用率低
大概率batch_size太高,即显存成为bottle_neck,GPU一直在等显存的数据此时尝试逐步减小batch_size,观察GPU利用率。如果batch_size已经为1,问题依旧,则考虑是不是单张图片分辨率太大的问题。
![[数组]移除元素](/images/no-images.jpg)