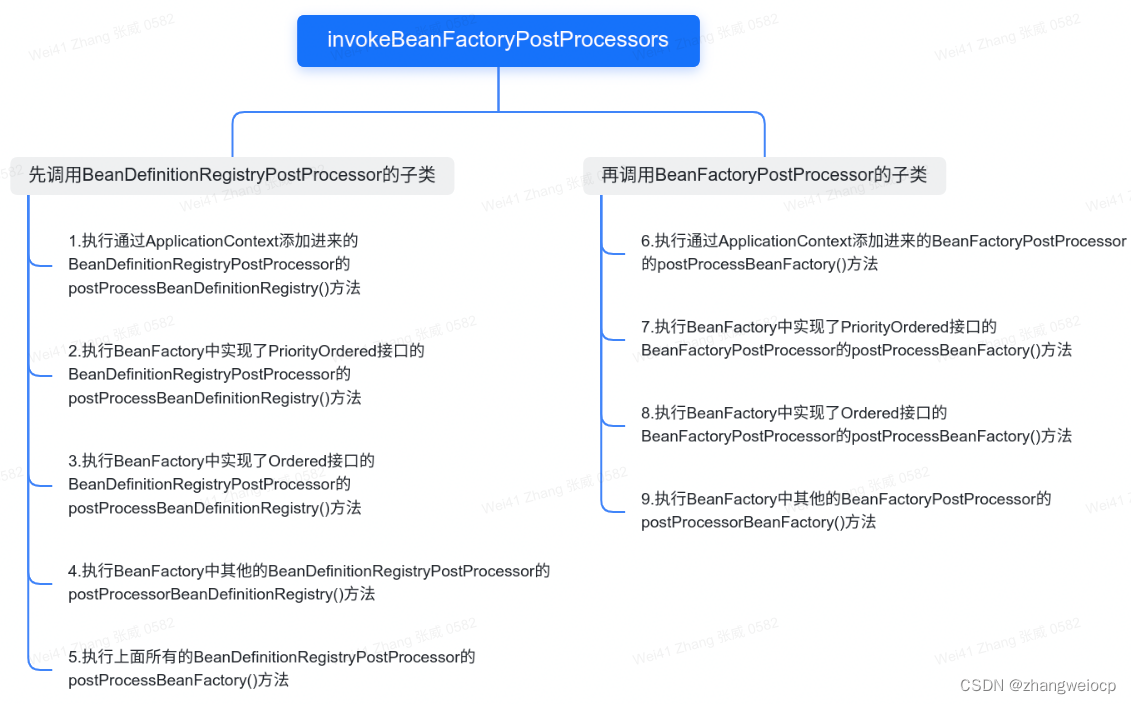
大家好,长短期记忆网络(LSTM)是RNN的一种变体,RNN由于梯度消失的原因只能有短期记忆,LSTM网络通过精妙的门控制将短期记忆与长期记忆结合起来,并且一定程度上解决了梯度消失的问题。本文将参照notebook演示如何训练一个长短期记忆网络模型,并且快速对比它与其他模型的性能。
获取数据
选取一个数据流:
import matplotlib.pyplot as plt
from microprediction import MicroReader# 初始化MicroReader
reader = MicroReader()# 获取一个数据流名称的列表
stream_names = reader.get_stream_names()# 从列表中选择第一个数据流
stream = stream_names[50]# 或者硬连接它...
stream = 'yarx_vlty_2_mo.json'# 获取历史数据(返回一个值的列表)
history = reader.get_lagged_values(name=stream)# 绘制历史数据
plt.plot(history[:30])
plt.xlabel("Time")
plt.ylabel("Value")
plt.title(f"Historical Data for '{stream}'")
plt.show()整理训练数据
现在需要将它变成PyTorch的回归数据格式,这是我们需要的模板代码,建议保存备用。
import numpy as np
import torchdef create_sequences(data, seq_length):xs, ys = [], []for i in range(len(data) - seq_length - 1):x = data[i:(i + seq_length)]y = data[i + seq_length]xs.append(x)ys.append(y)return np.array(xs), np.array(ys)这个函数的目的是为了生成用于训练和测试时间序列预测模型的输入-输出对,输入-输出对是通过在时间序列数据上滑动一个给定长度(seq_length)的窗口来创建的。对于每次迭代,它通过从索引i到索引i+seq_length切片数据来创建一个输入序列x,然后通过选择索引i+seq_length处的数据点来创建相应的目标值y。
分离和转换
PyTorch需要张量格式,而不是numpy,因此进行转换:
# 将数据分成训练集和测试集
train_size = int(len(y) * 0.8)
X_train, X_test = X[:train_size], X[train_size:]
y_train, y_test = y[:train_size], y[train_size:]# 转换为PyTorch张量
X_train = torch.from_numpy(X_train).float()
y_train = torch.from_numpy(y_train).float()
X_test = torch.from_numpy(X_test).float()
y_test = torch.from_numpy(y_test).float()定义模型
这段代码定义了一个名为LSTM的PyTorch自定义nn.Module类,它代表了时间序列预测的长短期记忆(LSTM)神经网络模型。
import torch.nn as nnclass LSTM(nn.Module):def __init__(self, input_size, hidden_size, num_layers, output_size):super(LSTM, self).__init__()self.hidden_size = hidden_sizeself.num_layers = num_layersself.lstm = nn.LSTM(input_size, hidden_size, num_layers, batch_first=True)self.fc = nn.Linear(hidden_size, output_size)def forward(self, x):h0 = torch.zeros(self.num_layers, x.size(0), self.hidden_size)c0 = torch.zeros(self.num_layers, x.size(0), self.hidden_size)out, _ = self.lstm(x, (h0, c0))out = self.fc(out[:, -1, :])return out-
input_size:每个时间步骤的输入特征数。 -
hidden_size:每个LSTM层中的隐藏单元数。 -
num_layers:堆叠的LSTM层数。 -
output_size:输出的大小(例如,预测值的数量)。
由于有单变量目标,使用的代码如下:
# 初始化LSTM模型
input_size = 1
hidden_size = 50
num_layers = 1
output_size = 1
model = LSTM(input_size, hidden_size, num_layers, output_size)# 设置训练参数
learning_rate = 0.01
num_epochs = 100# 定义损失函数和优化器
criterion = nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)# 训练模型
for epoch in range(num_epochs):outputs = model(X_train.unsqueeze(-1)).squeeze() # Add .squeeze() hereoptimizer.zero_grad()loss = criterion(outputs, y_train)loss.backward()optimizer.step()if (epoch + 1) % 10 == 0:print(f"Epoch [{epoch+1}/{num_epochs}], Loss: {loss.item():.4f}")X_train.unsqueeze(-1)将一个额外的维度添加到X_train张量中,使其具有形状(batch,sequence,feature),因为LSTM模型期望以这种格式输入张量。
model(X_train.unsqueeze(-1))将重塑后的X_train张量通过LSTM模型,生成输出预测。输出张量的形状为(batch,output_size)。在这里squeeze()会从输出张量中删除任何大小为1的维度,从而简化后续计算。
optimizer.zero_grad()在开始新的优化迭代之前重置了模型参数的梯度,因为在PyTorch中默认情况下梯度会累积,如果不将其清零,则会导致在后续迭代中出现不正确的梯度计算。
测试
由于只需要计算,所以不需要梯度,在本文的实例中,测试损失为0.0092。让我们将其与学习时的训练损失进行比较:
Epoch [10/100], Loss: 0.0283
Epoch [20/100], Loss: 0.0184
Epoch [30/100], Loss: 0.0163
Epoch [40/100], Loss: 0.0132
Epoch [50/100], Loss: 0.0104
Epoch [60/100], Loss: 0.0101
Epoch [70/100], Loss: 0.0097
Epoch [80/100], Loss: 0.0094
Epoch [90/100], Loss: 0.0090
Epoch [100/100], Loss: 0.0086比较的结果显示,thinking_fast_and_slow模型不如我们训练的LSTM。