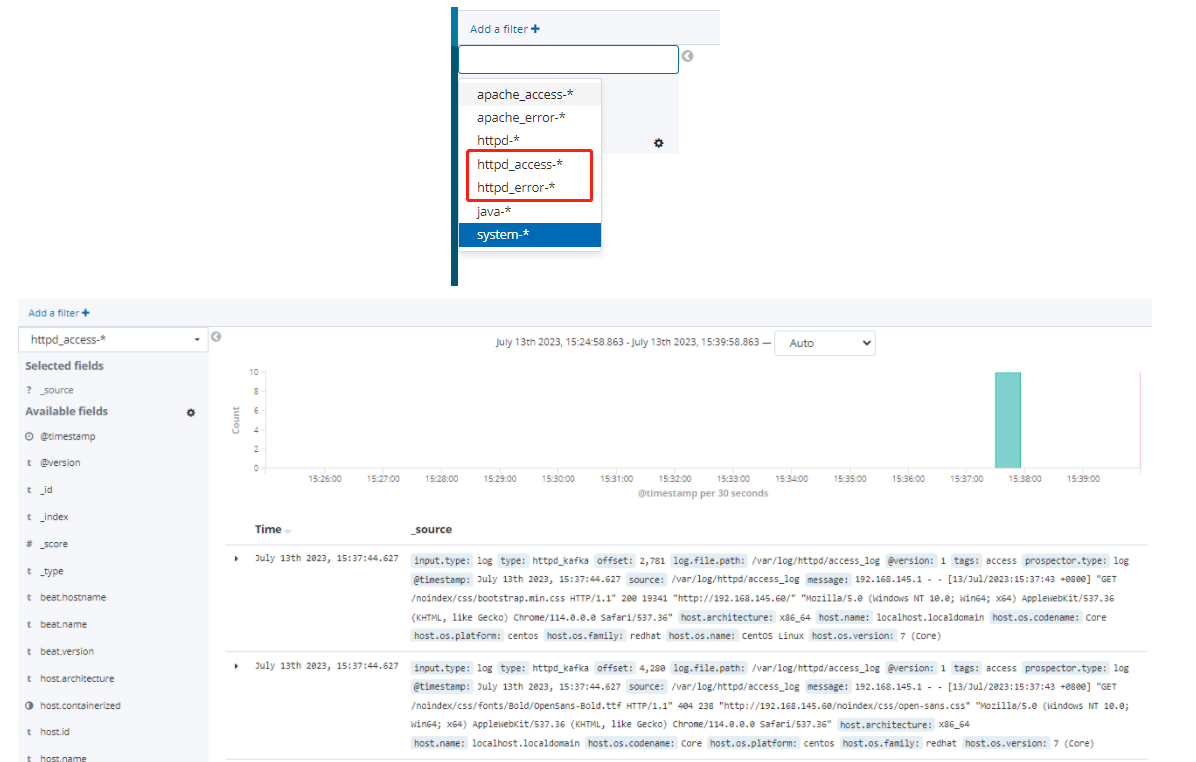
现有村落间道路的统计数据表中,列出了有可能建设成标准公路的若干条道路的成本,求使每个村落都有公路连通所需要的最低成本。
输入格式:
输入数据包括城镇数目正整数N(≤1000)和候选道路数目M(≤3N);随后的M行对应M条道路,每行给出3个正整数,分别是该条道路直接连通的两个城镇的编号以及该道路改建的预算成本。为简单起见,城镇从1到N编号。
输出格式:
输出村村通需要的最低成本。如果输入数据不足以保证畅通,则输出−1,表示需要建设更多公路。
输入样例:
6 15
1 2 5
1 3 3
1 4 7
1 5 4
1 6 2
2 3 4
2 4 6
2 5 2
2 6 6
3 4 6
3 5 1
3 6 1
4 5 10
4 6 8
5 6 3
输出样例:
12
根据题意,图的边数大概是顶点数的3倍,所以是稀疏图,又因为此题是求解最小生成树问题,所以最好选择Kruskal算法。具体代码实现如下:
#include<stdio.h>
#include<stdlib.h>#define MaxVertexNum 1000 /* 最大顶点数设为1000 */
typedef int Vertex; /* 用顶点下标表示顶点,为整型 */
typedef int WeightType; /* 边的权值设为整型 */
typedef char DataType; /* 顶点存储的数据类型设为字符型 *//* 边的定义 */
typedef struct ENode *PtrToENode;
struct ENode{Vertex V1, V2; /* 有向边<V1, V2> */WeightType Weight; /* 权重 */
};
typedef PtrToENode Edge;/* 邻接点的定义 */
typedef struct AdjVNode *PtrToAdjVNode;
struct AdjVNode{Vertex AdjV; /* 邻接点下标 */WeightType Weight; /* 边权重 */PtrToAdjVNode Next; /* 指向下一个邻接点的指针 */
};/* 顶点表头结点的定义 */
typedef struct Vnode{PtrToAdjVNode FirstEdge;/* 边表头指针 */
} AdjList[MaxVertexNum]; /* AdjList是邻接表类型 *//* 图结点的定义 */
typedef struct GNode *PtrToGNode;
struct GNode{ int Nv; /* 顶点数 */int Ne; /* 边数 */AdjList G; /* 邻接表 */
};
typedef PtrToGNode LGraph; /* 以邻接表方式存储的图类型 */LGraph BuildGraph();
int Kruskal( LGraph Graph, LGraph MST );int main()
{LGraph graph,mst;int cost;graph = BuildGraph();cost = Kruskal(graph,mst);printf("%d\n",cost);return 0;
}LGraph CreateGraph( int VertexNum )
{ /* 初始化一个有VertexNum个顶点但没有边的图 */Vertex V;LGraph Graph;Graph = (LGraph)malloc( sizeof(struct GNode) ); /* 建立图 */Graph->Nv = VertexNum;Graph->Ne = 0;/* 初始化邻接表头指针 *//* 注意:这里默认顶点编号从0开始,到(Graph->Nv - 1) */for (V=0; V<Graph->Nv; V++)Graph->G[V].FirstEdge = NULL;return Graph;
}void InsertEdge( LGraph Graph, Edge E )
{PtrToAdjVNode NewNode;/* 插入边 <V1, V2> *//* 为V2建立新的邻接点 */NewNode = (PtrToAdjVNode)malloc(sizeof(struct AdjVNode));NewNode->AdjV = E->V2;NewNode->Weight = E->Weight;/* 将V2插入V1的表头 */NewNode->Next = Graph->G[E->V1].FirstEdge;Graph->G[E->V1].FirstEdge = NewNode;/* 若是无向图,还要插入边 <V2, V1> *//* 为V1建立新的邻接点 */NewNode = (PtrToAdjVNode)malloc(sizeof(struct AdjVNode));NewNode->AdjV = E->V1;NewNode->Weight = E->Weight;/* 将V1插入V2的表头 */NewNode->Next = Graph->G[E->V2].FirstEdge;Graph->G[E->V2].FirstEdge = NewNode;
}LGraph BuildGraph()
{LGraph Graph;Edge E;Vertex V;int Nv, i;scanf("%d", &Nv); /* 读入顶点个数 */Graph = CreateGraph(Nv); /* 初始化有Nv个顶点但没有边的图 */ scanf("%d", &(Graph->Ne)); /* 读入边数 */if ( Graph->Ne != 0 ) { /* 如果有边 */ E = (Edge)malloc( sizeof(struct ENode) ); /* 建立边结点 */ /* 读入边,格式为"起点 终点 权重",插入邻接表中 */for (i=0; i<Graph->Ne; i++) {scanf("%d %d %d", &E->V1, &E->V2, &E->Weight); /* 注意:这里默认顶点编号从0开始,到(Graph->Nv - 1) */E->V1--;E->V2--;InsertEdge( Graph, E );}}return Graph;
}/*-------------------- 顶点并查集定义 --------------------*/
typedef int ElementType;
typedef Vertex ElementType; /* 默认元素可以用非负整数表示 */
typedef Vertex SetName; /* 默认用根结点的下标作为集合名称 */
typedef ElementType SetType[MaxVertexNum]; /* 假设集合元素下标从0开始 */void InitializeVSet( SetType S, int N )
{ /* 初始化并查集 */ElementType X;for ( X=0; X<N; X++ ) S[X] = -1;
}void Union( SetType S, SetName Root1, SetName Root2 )
{ /* 这里默认Root1和Root2是不同集合的根结点 *//* 保证小集合并入大集合 */if ( S[Root2] < S[Root1] ) { /* 如果集合2比较大 */S[Root2] += S[Root1]; /* 集合1并入集合2 */S[Root1] = Root2;}else { /* 如果集合1比较大 */S[Root1] += S[Root2]; /* 集合2并入集合1 */S[Root2] = Root1;}
}SetName Find( SetType S, ElementType X )
{ /* 默认集合元素全部初始化为-1 */if ( S[X] < 0 ) /* 找到集合的根 */return X;elsereturn S[X] = Find( S, S[X] ); /* 路径压缩 */
}bool CheckCycle( SetType VSet, Vertex V1, Vertex V2 )
{ /* 检查连接V1和V2的边是否在现有的最小生成树子集中构成回路 */Vertex Root1, Root2;Root1 = Find( VSet, V1 ); /* 得到V1所属的连通集名称 */Root2 = Find( VSet, V2 ); /* 得到V2所属的连通集名称 */if( Root1==Root2 ) /* 若V1和V2已经连通,则该边不能要 */return false;else { /* 否则该边可以被收集,同时将V1和V2并入同一连通集 */Union( VSet, Root1, Root2 );return true;}
}
/*-------------------- 并查集定义结束 --------------------*//*-------------------- 边的最小堆定义 --------------------*/
void PercDown( Edge ESet, int p, int N )
{/* 将N个元素的边数组中以ESet[p]为根的子堆调整为关于Weight的最小堆 */int Parent, Child;struct ENode X;X = ESet[p]; /* 取出根结点存放的值 */for( Parent=p; (Parent*2+1)<N; Parent=Child ) {Child = Parent * 2 + 1;if( (Child!=N-1) && (ESet[Child].Weight>ESet[Child+1].Weight) )Child++; /* Child指向左右子结点的较小者 */if( X.Weight <= ESet[Child].Weight ) break; /* 找到了合适位置 */else /* 下滤X */ESet[Parent] = ESet[Child];}ESet[Parent] = X;
}void InitializeESet( LGraph Graph, Edge ESet )
{ /* 将图的边存入数组ESet,并且初始化为最小堆 */Vertex V;PtrToAdjVNode W;int ECount;/* 将图的边存入数组ESet */ECount = 0;for ( V=0; V<Graph->Nv; V++ )for ( W=Graph->G[V].FirstEdge; W; W=W->Next )if ( V < W->AdjV ) { /* 避免重复录入无向图的边,只收V1<V2的边 */ESet[ECount].V1 = V;ESet[ECount].V2 = W->AdjV;ESet[ECount++].Weight = W->Weight;}/* 初始化为最小堆 */for ( ECount=Graph->Ne/2; ECount>=0; ECount-- )PercDown( ESet, ECount, Graph->Ne );
}void Swap(Edge edge1,Edge edge2)
{struct ENode temp;temp = *edge1;*edge1 = *edge2;*edge2 = temp;
}int GetEdge( Edge ESet, int CurrentSize )
{ /* 给定当前堆的大小CurrentSize,将当前最小边位置弹出并调整堆 *//* 将最小边与当前堆的最后一个位置的边交换 */Swap( &ESet[0], &ESet[CurrentSize-1]);/* 将剩下的边继续调整成最小堆 */PercDown( ESet, 0, CurrentSize-1 );return CurrentSize-1; /* 返回最小边所在位置 */
}
/*-------------------- 最小堆定义结束 --------------------*//* 邻接表存储 - Kruskal最小生成树算法 */
int Kruskal( LGraph Graph, LGraph MST )
{ /* 将最小生成树保存为邻接表存储的图MST,返回最小权重和 */WeightType TotalWeight;int ECount, NextEdge;SetType VSet; /* 顶点数组 */Edge ESet; /* 边数组 */InitializeVSet( VSet, Graph->Nv ); /* 初始化顶点并查集 */ESet = (Edge)malloc( sizeof(struct ENode)*Graph->Ne );InitializeESet( Graph, ESet ); /* 初始化边的最小堆 *//* 创建包含所有顶点但没有边的图。注意用邻接表版本 */MST = CreateGraph(Graph->Nv);TotalWeight = 0; /* 初始化权重和 */ECount = 0; /* 初始化收录的边数 */NextEdge = Graph->Ne; /* 原始边集的规模 */while ( ECount < Graph->Nv-1 ) { /* 当收集的边不足以构成树时 */NextEdge = GetEdge( ESet, NextEdge ); /* 从边集中得到最小边的位置 */if (NextEdge < 0) /* 边集已空 */break;/* 如果该边的加入不构成回路,即两端结点不属于同一连通集 */if ( CheckCycle( VSet, ESet[NextEdge].V1, ESet[NextEdge].V2 )==true ) {/* 将该边插入MST */InsertEdge( MST, ESet+NextEdge );TotalWeight += ESet[NextEdge].Weight; /* 累计权重 */ECount++; /* 生成树中边数加1 */}}if ( ECount < Graph->Nv-1 )TotalWeight = -1; /* 设置错误标记,表示生成树不存在 */return TotalWeight;
}当然此题也可以选择Prim算法,不过时间复杂度相对要高不少,具体代码实现如下:
#include<stdio.h>
#include<stdlib.h>#define MaxVertexNum 1000 //最大顶点数设为1000
#define INFINITY 65535 //∞设为双字节无符号整数的最大值65535typedef int Vertex; //用顶点下标表示顶点,为整型
typedef int WeightType; //边的权值设为整型
typedef char DataType; //顶点存储的数据类型设为字符型/*边的定义*/
typedef struct ENode *PtrToENode;
struct ENode{Vertex V1,V2; //有向边<V1,V2>WeightType Weight; //权重
};
typedef PtrToENode Edge;/* 图的邻接矩阵表示法 */
/*图结点的定义*/
typedef struct GNode1 *PtrToGNode1;
struct GNode1{int Nv; //顶点数int Ne; //边数WeightType G[MaxVertexNum][MaxVertexNum]; //邻接矩阵
};
typedef PtrToGNode1 MGraph; //以邻接矩阵存储的图类型 /* 图的邻接表表示法 */
/* 邻接点的定义 */
typedef struct AdjVNode *PtrToAdjVNode;
struct AdjVNode{Vertex AdjV; /* 邻接点下标 */WeightType Weight; /* 边权重 */PtrToAdjVNode Next; /* 指向下一个邻接点的指针 */
};/* 顶点表头结点的定义 */
typedef struct Vnode{PtrToAdjVNode FirstEdge;/* 边表头指针 */
} AdjList[MaxVertexNum]; /* AdjList是邻接表类型 *//* 图结点的定义 */
typedef struct GNode2 *PtrToGNode2;
struct GNode2{ int Nv; /* 顶点数 */int Ne; /* 边数 */AdjList G; /* 邻接表 */
};
typedef PtrToGNode2 LGraph; /* 以邻接表方式存储的图类型 */#define TRUE 1
#define FALSE 0
#define ERROR -1MGraph BuildGraph1();
int Prim( MGraph Graph, LGraph MST );int main()
{ MGraph graph;LGraph mst;int cost;graph = BuildGraph1();cost = Prim(graph,mst);printf("%d\n",cost);return 0;
}/* 图的邻接矩阵表示法 */
MGraph CreateGraph1(int VertexNum)
{/*初始化一个有VertexNum个顶点但没有边的图*/Vertex V,W;MGraph Graph;Graph = (MGraph)malloc(sizeof(struct GNode1)); //建立图Graph->Nv = VertexNum;Graph->Ne = 0;/*初始化邻接矩阵*///注意:这里默认顶点编号从0开始,到(Graph->Nv-1) for(V=0; V<Graph->Nv; V++){for(W=0; W<Graph->Nv; W++){Graph->G[V][W] = INFINITY;}}return Graph;} void InsertEdge1(MGraph Graph,Edge E)
{/*插入边<V1,V2>*/Graph->G[E->V1][E->V2] = E->Weight;//若是无向图,还要插入<V2,V1>Graph->G[E->V2][E->V1] = E->Weight;
}MGraph BuildGraph1()
{MGraph Graph;Edge E;Vertex V;int Nv,i;scanf("%d",&Nv); //读入顶点个数Graph = CreateGraph1(Nv); //初始化有Nv个顶点但没有边的图scanf("%d",&(Graph->Ne)); //读入边数if( Graph->Ne != 0){ //如果有边 E = (Edge)malloc(sizeof(struct ENode));/*读入边,格式为"起点 终点 权重",插入邻接矩阵*/for(i=0; i<Graph->Ne; i++){scanf("%d %d %d",&E->V1,&E->V2,&E->Weight);/* 注意:这里默认顶点编号从0开始,到(Graph->Nv - 1) */E->V1--;E->V2--;InsertEdge1(Graph,E);} }return Graph;
}/* 图的邻接表表示法 */
LGraph CreateGraph2( int VertexNum )
{ /* 初始化一个有VertexNum个顶点但没有边的图 */Vertex V;LGraph Graph;Graph = (LGraph)malloc( sizeof(struct GNode2) ); /* 建立图 */Graph->Nv = VertexNum;Graph->Ne = 0;/* 初始化邻接表头指针 *//* 注意:这里默认顶点编号从0开始,到(Graph->Nv - 1) */for (V=0; V<Graph->Nv; V++)Graph->G[V].FirstEdge = NULL;return Graph;
}void InsertEdge2( LGraph Graph, Edge E )
{PtrToAdjVNode NewNode;/* 插入边 <V1, V2> *//* 为V2建立新的邻接点 */NewNode = (PtrToAdjVNode)malloc(sizeof(struct AdjVNode));NewNode->AdjV = E->V2;NewNode->Weight = E->Weight;/* 将V2插入V1的表头 */NewNode->Next = Graph->G[E->V1].FirstEdge;Graph->G[E->V1].FirstEdge = NewNode;/* 若是无向图,还要插入边 <V2, V1> *//* 为V1建立新的邻接点 */NewNode = (PtrToAdjVNode)malloc(sizeof(struct AdjVNode));NewNode->AdjV = E->V1;NewNode->Weight = E->Weight;/* 将V1插入V2的表头 */NewNode->Next = Graph->G[E->V2].FirstEdge;Graph->G[E->V2].FirstEdge = NewNode;
}/* 邻接矩阵存储 - Prim最小生成树算法 */
Vertex FindMinDist( MGraph Graph, WeightType dist[] )
{ /* 返回未被收录顶点中dist最小者 */Vertex MinV, V;WeightType MinDist = INFINITY;for (V=0; V<Graph->Nv; V++) {if ( dist[V]!=0 && dist[V]<MinDist) {/* 若V未被收录,且dist[V]更小 */MinDist = dist[V]; /* 更新最小距离 */MinV = V; /* 更新对应顶点 */}}if (MinDist < INFINITY) /* 若找到最小dist */return MinV; /* 返回对应的顶点下标 */else return ERROR; /* 若这样的顶点不存在,返回-1作为标记 */
}int Prim( MGraph Graph, LGraph MST )
{ /* 将最小生成树保存为邻接表存储的图MST,返回最小权重和 */WeightType dist[MaxVertexNum], TotalWeight;Vertex parent[MaxVertexNum], V, W;int VCount;Edge E;/* 初始化。默认初始点下标是0 */for (V=0; V<Graph->Nv; V++) {/* 这里假设若V到W没有直接的边,则Graph->G[V][W]定义为INFINITY */dist[V] = Graph->G[0][V];parent[V] = 0; /* 暂且定义所有顶点的父结点都是初始点0 */ }TotalWeight = 0; /* 初始化权重和 */VCount = 0; /* 初始化收录的顶点数 *//* 创建包含所有顶点但没有边的图。注意用邻接表版本 */MST = CreateGraph2(Graph->Nv);E = (Edge)malloc( sizeof(struct ENode) ); /* 建立空的边结点 *//* 将初始点0收录进MST */dist[0] = 0;VCount ++;parent[0] = -1; /* 当前树根是0 */while (1) {V = FindMinDist( Graph, dist );/* V = 未被收录顶点中dist最小者 */if ( V==ERROR ) /* 若这样的V不存在 */break; /* 算法结束 *//* 将V及相应的边<parent[V], V>收录进MST */E->V1 = parent[V];E->V2 = V;E->Weight = dist[V];InsertEdge2( MST, E );TotalWeight += dist[V];dist[V] = 0;VCount++;for( W=0; W<Graph->Nv; W++ ) /* 对图中的每个顶点W */if ( dist[W]!=0 && Graph->G[V][W]<INFINITY ) {/* 若W是V的邻接点并且未被收录 */if ( Graph->G[V][W] < dist[W] ) {/* 若收录V使得dist[W]变小 */dist[W] = Graph->G[V][W]; /* 更新dist[W] */parent[W] = V; /* 更新树 */}}} /* while结束*/if ( VCount < Graph->Nv ) /* MST中收的顶点不到|V|个 */TotalWeight = ERROR;return TotalWeight; /* 算法执行完毕,返回最小权重和或错误标记 */
}