数据集的准备
第一个渠道是歌曲:
- 在网易云下载音乐,下载后的音乐格式为ncm,需要将ncm格式转换为mp3格式。
- 对mp3格式的音乐进行去除伴奏和和音等,保留其纯净的人声,我使用的工具是UVR5(链接:),需要对同一首音乐进行两次提取,第一次提取是为了去除伴奏,第二次提取是为了去除和音等,两次提取对UVR5工具参数设置如下。

- 在提取人声之后,音乐里面还会包含空白的片段,这回影响模型的训练效果,所以需要进行切片的操作,以切除空白的片段。切片的界面如下。
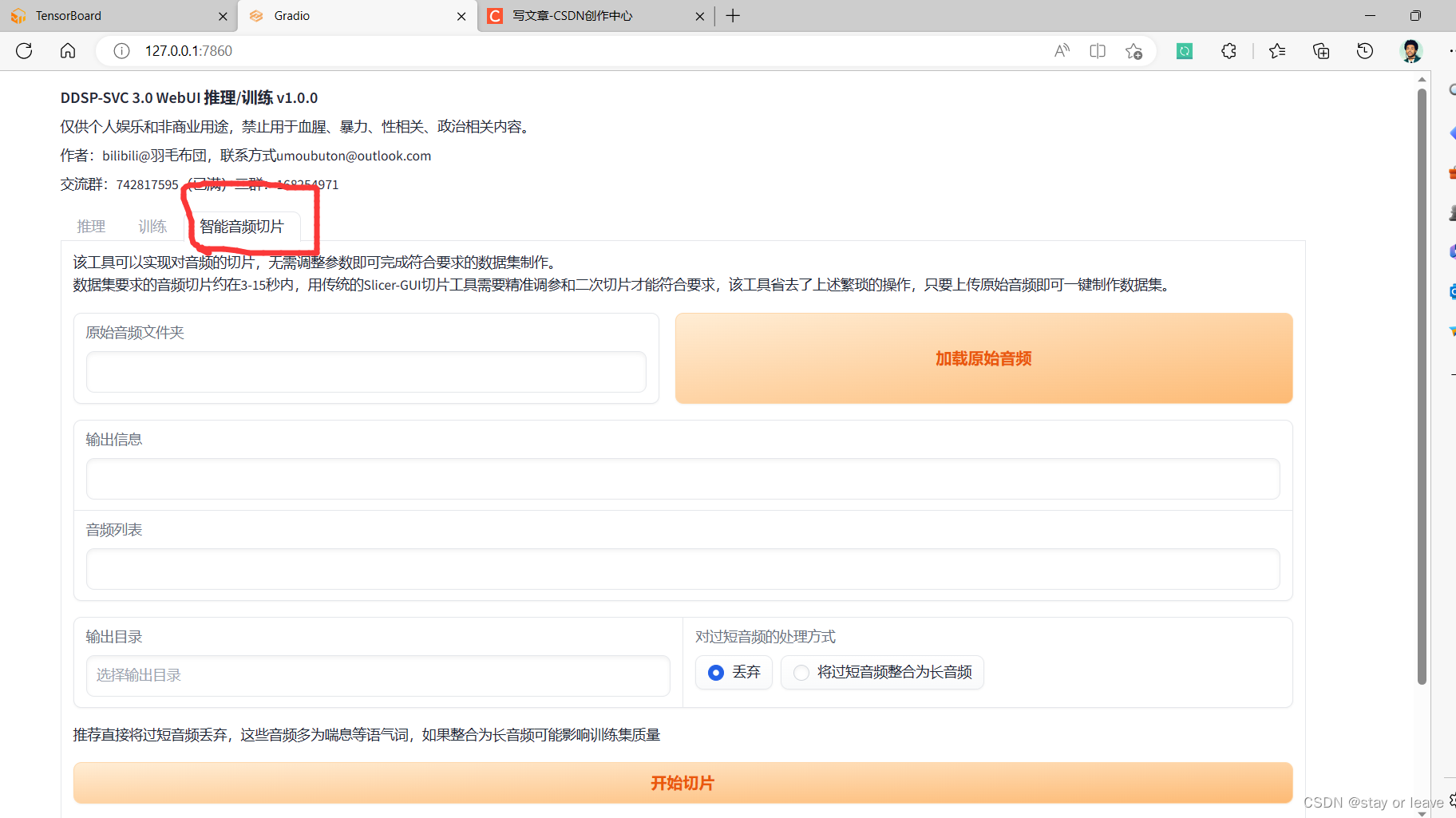
- 以上操作顺利完成后,就能从音乐中切除人声片段了。
第二个渠道是演讲:
- 操作步骤和渠道是音乐是一样的,但要注意去除非目标人声的其他人声。
模型的训练
- 模型的推理界面如下。
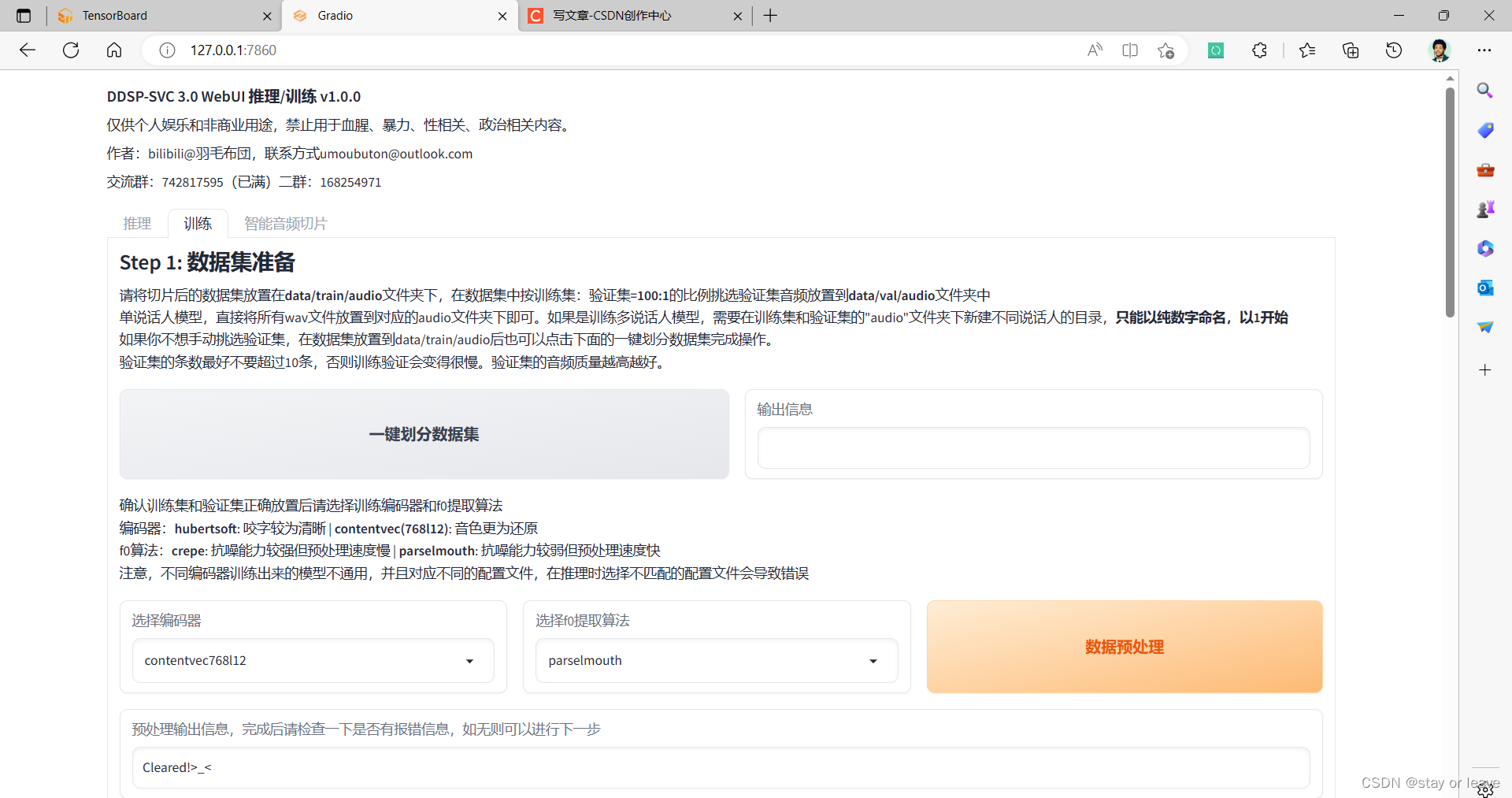
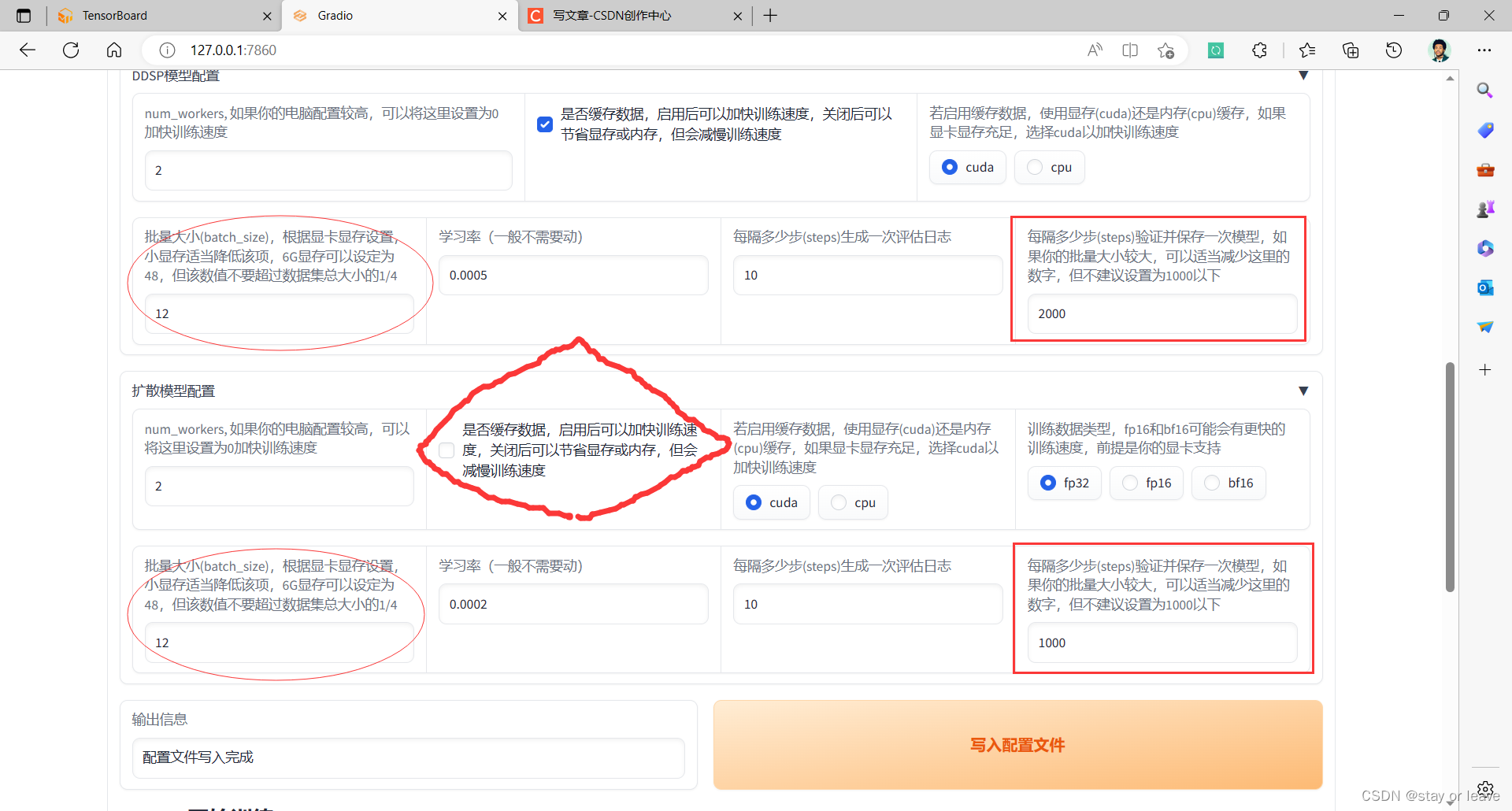
- 对DDSP模型训练参数的解释:对于椭圆参数,若报错显存不足,则向下调整。对于矩形参数,2000代表每训练2000个step(应该是batch_size) 后,保存训练得到的权值文件,并且计算该权值文件在验证机上的损失。
- 对于扩散模型训练参数解释:对于椭圆参数,若报错显存不足,则向下调整。对于矩形参数,2000代表每训练2000个step(应该是batch_size) 后,保存训练得到的权值文件,并且计算该权值文件在验证机上的损失。对于菱形参数,若batch_size已经较小时,显存不足的问题还是出现,则关闭缓存功能,可有效解决该问题。
模型的推理