深度学习框架Tensorflow2系列
注:大家觉得博客好的话,别忘了点赞收藏呀,本人每周都会更新关于人工智能和大数据相关的内容,内容多为原创,Python Java Scala SQL 代码,CV NLP 推荐系统等,Spark Flink Kafka Hbase Hive Flume等等~写的都是纯干货,各种顶会的论文解读,一起进步。
这个系列主要和大家分享深度学习框架Tensorflow2的各种api,从基础开始。
#博学谷IT学习技术支持#
文章目录
- 深度学习框架Tensorflow2系列
- 前言
- 一、文本分类任务实战
- 二、数据集介绍
- 三、CNN模型解读
- 四、实战代码
- 1.数据预处理
- 2.定义模型
- 3.模型训练
- 总结
前言
通过CNN文本分类实战案例,学习Tensorflow2中一些API
一、文本分类任务实战
任务介绍:
数据集构建:影评数据集进行情感分析(分类任务)
词向量模型:加载训练好的词向量或者自己训练都可以
序列网络模型:训练RNN模型进行识别
二、数据集介绍
训练和测试集都是比较简单的电影评价数据集,标签为0和1的二分类,表示对电影的喜欢和不喜欢

三、CNN模型解读

通过不同尺度的卷积核[(2,3,4),word_dim] 来提取单词的特征,再进行max_pooling得到一个特征值,最后把所有尺度得到的特征值拼接在一起后,通过全连接进行分类。
四、实战代码
1.数据预处理
这里直接加载默认数据集,通过pad_sequences进行截断和填充操作
得到训练集和测试集大小都为(25000,300)
各25000个样本,每个样本长度为300
(25000, 300)
(25000, 300)
import warnings
warnings.filterwarnings("ignore")
import numpy as np
import matplotlib.pyplot as plt
from tensorflow import keras
from tensorflow.keras import layers
from tensorflow.keras.preprocessing.sequence import pad_sequencesnum_features = 3000
sequence_length = 300
embedding_dimension = 100
(x_train, y_train), (x_test, y_test) = keras.datasets.imdb.load_data(num_words=num_features)
x_train = pad_sequences(x_train, maxlen=sequence_length)
x_test = pad_sequences(x_test, maxlen=sequence_length)
print(x_train.shape)
print(x_test.shape)
print(y_train.shape)
print(y_test.shape)
2.定义模型
# 多种卷积核,相当于单词数
filter_sizes=[3,4,5]
def convolution():inn = layers.Input(shape=(sequence_length, embedding_dimension, 1))#3维的cnns = []for size in filter_sizes:conv = layers.Conv2D(filters=64, kernel_size=(size, embedding_dimension),strides=1, padding='valid', activation='relu')(inn)#需要将多种卷积后的特征图池化成一个特征pool = layers.MaxPool2D(pool_size=(sequence_length-size+1, 1), padding='valid')(conv)cnns.append(pool)# 将得到的特征拼接在一起outt = layers.concatenate(cnns)model = keras.Model(inputs=inn, outputs=outt)return modeldef cnn_mulfilter():model = keras.Sequential([layers.Embedding(input_dim=num_features, output_dim=embedding_dimension,input_length=sequence_length),layers.Reshape((sequence_length, embedding_dimension, 1)),convolution(),layers.Flatten(),layers.Dense(10, activation='relu'),layers.Dropout(0.2),layers.Dense(1, activation='sigmoid')])model.compile(optimizer=keras.optimizers.Adam(),loss=keras.losses.BinaryCrossentropy(),metrics=['accuracy'])return modelmodel = cnn_mulfilter()
model.summary()
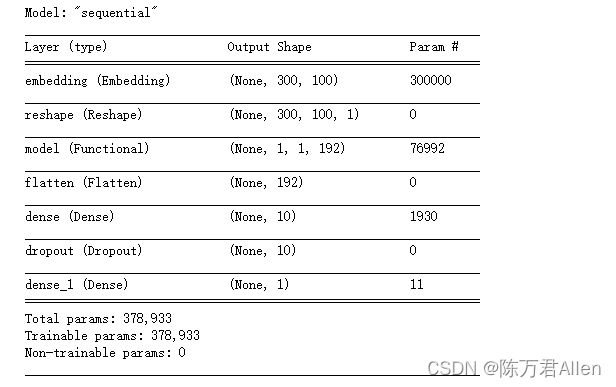
得到的模型结构如上图,其中192来自3种不同卷积核通过max_pooling之后相加得到的结果(64*3=192),每种卷积卷积之后得到一个向量,通过max_pooling之后得到一个特征值,每种卷积核设置filters=64所有最终一个卷积核得到64个值。
3.模型训练
deom级别测试代码
history = model.fit(x_train, y_train, batch_size=64, epochs=5, validation_split=0.1)
plt.plot(history.history['accuracy'])
plt.plot(history.history['val_accuracy'])
plt.legend(['training', 'valiation'], loc='upper left')
plt.show()
总结
通过CNN文本分类任务代码案例实战,学习Tensorflow2的各种api。