文章目录
- 前言
- 源码实现
- MuGo的输入数据
- 模型的搭建
- 模型的训练
- 参考链接
- 结语
前言
自从AlphaGo横空出世,战胜李世石后,AI围棋如雨后春笋一般遍地开花。阅读DeepMind的论文有时还是隔靴搔痒,只有钻到代码里,才能一探究竟。于是,我选择了相对比较容易上手的MuGo作为研究起点。研究AlphaGo/AlphaZero实现原理,一方面是出于对AI围棋的兴趣,另一方面顺带加深对tensorflow等框架的了解。
源码实现
MuGo的代码不多,源文件一共8个。
| 文件名 | 介绍 |
|---|---|
| features.py | 特征平面定义 |
| go.py | 棋盘设置,各种判断,如落子合法性,气的计算 |
| load_data_sets.py | 加载棋谱文件 |
| main.py | 主程序,接收命令行参数,完成预处理、训练、对弈三大功能 |
| policy.py | 神经网络即策略网络的搭建 |
| sgf_wrapper.py | sgf棋谱文件解析 |
| strategies.py | MCTS结构定义,Player定义 |
| utils.py | 辅助函数,如棋盘坐标转换 |
MuGo的输入数据
在features.py文件中,MuGo一共定义了十多个特征平面作为神经网络的输入:
| 特征 | 说明 | 取值数 |
|---|---|---|
| 落子颜色 | Player stones; 对手. 自己; 空 | 3 |
| Ones | 全1的特征平面,让神经网络借此知道棋盘边界 | 1 |
| 当前落子回合数 | How many turns since a move played | 8 |
| 棋子的气 | 棋子的气数 | 8 |
| 对方将被提子数 | 多少棋子将被吃掉 | 8 |
| 自方将被提子数 | 多少己方的棋子将被吃掉 | 8 |
| 落子后的气 | Number of liberties after this move played | 8 |
| 是否为征子 | Whether a move is a successful ladder cap | 1 |
| 是否为逃征子 | Whether a move is a successful ladder escape | 1 |
| 是否为合法落子 | 合法落子不能填自己的眼,也不能被对手提掉 | 1 |
| Zeros | 全0的平面 | 1 |
模型的搭建
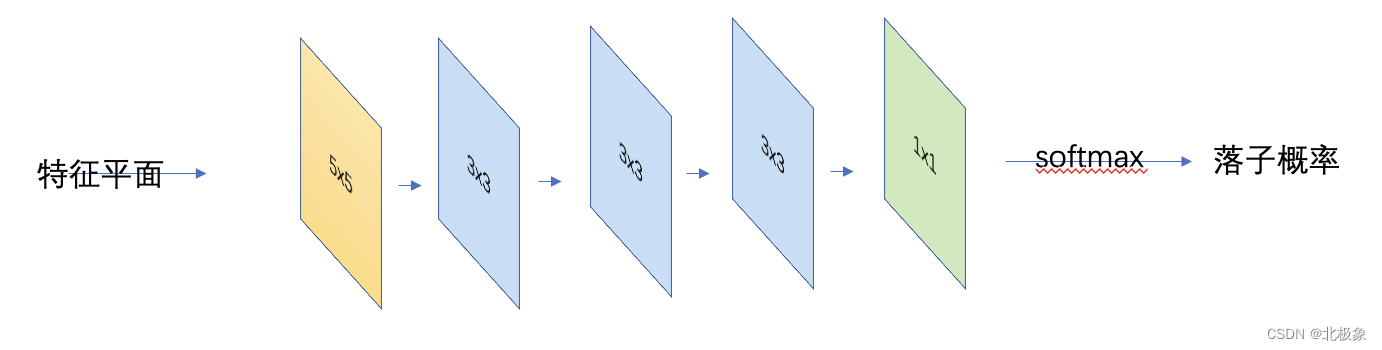
整个网络通过五个卷积层,输出落子概率。
log_likelihood_cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=logits, labels=y))train_step = tf.compat.v1.train.AdamOptimizer(1e-4).minimize(log_likelihood_cost, global_step=global_step)
was_correct = tf.equal(tf.argmax(logits, 1), tf.argmax(y, 1))
accuracy = tf.reduce_mean(tf.cast(was_correct, tf.float32))
优化函数为softmax_cross_entropy_with_logits()。
模型的训练
def train(self, training_data, batch_size=32):num_minibatches = training_data.data_size // batch_sizefor i in range(num_minibatches):batch_x, batch_y = training_data.get_batch(batch_size)_, accuracy, cost = self.session.run([self.train_step, self.accuracy, self.log_likelihood_cost],feed_dict={self.x: batch_x, self.y: batch_y})self.training_stats.report(accuracy, cost)avg_accuracy, avg_cost, accuracy_summaries = self.training_stats.collect()global_step = self.get_global_step()print("Step %d training data accuracy: %g; cost: %g" % (global_step, avg_accuracy, avg_cost))if self.training_summary_writer is not None:activation_summaries = self.session.run(self.activation_summaries,feed_dict={self.x: batch_x, self.y: batch_y})self.training_summary_writer.add_summary(activation_summaries, global_step)self.training_summary_writer.add_summary(accuracy_summaries, global_step)
获得某个局面position下的落子概率:
def run(self, position):'Return a sorted list of (probability, move) tuples'processed_position = features.extract_features(position, features=self.features)probabilities = self.session.run(self.output, feed_dict={self.x: processed_position[None, :]})[0]return probabilities.reshape([go.N, go.N])
参考链接
- MuGo源码地址
结语
本文还在写作中,TODO