相关背景:
- 本篇文章是基于爬虫实践课程–分析Ajax请求并抓取今日头条街拍美图
-
其实我最开始也只想在CSDN上面找一篇文章看看结果都是分析没有实操,没办法最后只能自己写了,本篇文章里面的问题也是我遇到的问题。
操作过程:
1.首先对今日头条的数据进行分析,我们可以轻易发现其中的图片内容是Ajax请求的,那么接下来我们打开Network中的Fetch/XHR,将今日头条的图片往下滑动加载新的图片,我们发现下拉过程中出现很多list打开这个我没有找到任何有用的数据继续下拉,出现search如下图开头的加载数据,打开他的响应,发现里面全是我们要找的图片的地址。

找到该条数据的负载里面的内容等会在写params的时候会用
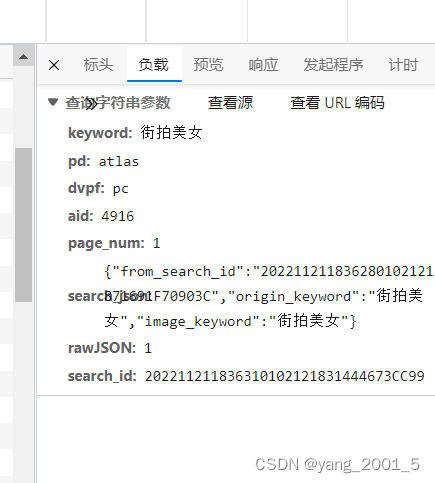
2.接下来就是用python将数据爬下来
首先导入接下来需要用到的包
import requests
import json
import os我们建一个类beauty_girl并且写入url,header,params私有属性,这里需要注意,header里面需要加入cookie,不加拿不到我们想要的数据。
class beauty_girl:def __init__(self,num):self.url='https://so.toutiao.com/search?'self.params={'keyword':'街拍美图','pd':'atlas','dvpf':'pc','aid':'4916','page_num':num,'search_json':'{"from_search_id": "202211211241230102121871694D7238FE", "origin_keyword": "街拍美图", "image_keyword": "街拍美图","_signal": "aHR0cHM6Ly9zZjMtdHRjZG4tdG9zLnBzdGF0cC5jb20vaW1nL3Rvcy1jbi1pLXF2ajJscTQ5azAvMzI1YjA4MGI4OTA2NDYyNGJhNWIyNmI1NWU4ZmEyMTF+Y3MuanBlZw=="}','rawJSON':'1','search_id':'202211211241260102121871694D72393D'}self.headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/106.0.0.0 Safari/537.36','Cookie': 'msToken=fZ_kL6EYm65nmgLwajl7FuHJoMFlW1OpYK06fMov5og4dbrVGPDhm0LakLrv8pToPIjQmXmM_CmNIoeJnmwk_XaHcGQJ0VM3D3gt-w_oB5Y=; tt_webid=7146370447167997471; ttwid=1%7CNetI5FlsXWvIT6_sze0TpHWyERC-LY-h_x0FO6s4fTw%7C1669005678%7C9a1ac1000023e9cc9f0a0ff99b47f8217233a935f22268e6b5ed5ee1027afe31; _tea_utm_cache_4916=undefined; _S_WIN_WH=1536_754; _S_DPR=1.25; _S_IPAD=0; MONITOR_WEB_ID=7146370447167997471'}3.写入获取响应数据的方法,当正常访问时返回响应数据,不能访问时返回None
def get_resp_data(self):resp=requests.get(url=self.url,headers=self.headers,params=self.params)if resp.status_code==200:return resp.textelse:return None4.写入获取url并且保存图片的方法
def get_url_set(self,data_list):#对json数据进行分析拿到有url的列表数据dict_data=json.loads(data_list)['rawData']['data']print(dict_data)for data in dict_data:#获取每张图片的urlnew_url=data['img_url']#给每个图片命名name=new_url.split('/')[-1]#拿到图片数据resp=requests.get(url=new_url,headers=self.headers).content#保存with open('./今日头条/'+name,'wb') as fp:fp.write(resp)print(new_url,'保存成功')5.写一个启动方法
def run(self):#检查该层是否存在今日头条这个文件夹if not os.path.exists('./今日头条'):os.mkdir('./今日头条')resp=self.get_resp_data()print(resp)self.get_url_set(resp)6.运行代码,说一下那个4,是我随便填的,代表我要获取网页加载4次的图片,自己想要多少图片自己填。
if __name__ == '__main__':for num in range(4):r1=beauty_girl(num)r1.run()总结:
没什么好总结的总结的这篇文章本来就是哥们写着玩的,里面的东西也不难纯属哥们自娱自乐
下面是代码总结:
import requests
import json
import osclass beauty_girl:def __init__(self,num):self.url='https://so.toutiao.com/search?'self.params={'keyword':'街拍美图','pd':'atlas','dvpf':'pc','aid':'4916','page_num':num,'search_json':'{"from_search_id": "202211211241230102121871694D7238FE", "origin_keyword": "街拍美图", "image_keyword": "街拍美图","_signal": "aHR0cHM6Ly9zZjMtdHRjZG4tdG9zLnBzdGF0cC5jb20vaW1nL3Rvcy1jbi1pLXF2ajJscTQ5azAvMzI1YjA4MGI4OTA2NDYyNGJhNWIyNmI1NWU4ZmEyMTF+Y3MuanBlZw=="}','rawJSON':'1','search_id':'202211211241260102121871694D72393D'}self.headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/106.0.0.0 Safari/537.36','Cookie': 'msToken=fZ_kL6EYm65nmgLwajl7FuHJoMFlW1OpYK06fMov5og4dbrVGPDhm0LakLrv8pToPIjQmXmM_CmNIoeJnmwk_XaHcGQJ0VM3D3gt-w_oB5Y=; tt_webid=7146370447167997471; ttwid=1%7CNetI5FlsXWvIT6_sze0TpHWyERC-LY-h_x0FO6s4fTw%7C1669005678%7C9a1ac1000023e9cc9f0a0ff99b47f8217233a935f22268e6b5ed5ee1027afe31; _tea_utm_cache_4916=undefined; _S_WIN_WH=1536_754; _S_DPR=1.25; _S_IPAD=0; MONITOR_WEB_ID=7146370447167997471'}def get_resp_data(self):resp=requests.get(url=self.url,headers=self.headers,params=self.params)if resp.status_code==200:return resp.textelse:return Nonedef get_url_set(self,data_list):#对json数据进行分析拿到有url的列表数据dict_data=json.loads(data_list)['rawData']['data']print(dict_data)for data in dict_data:#获取每张图片的urlnew_url=data['img_url']#给每个图片命名name=new_url.split('/')[-1]#拿到图片数据resp=requests.get(url=new_url,headers=self.headers).content#保存with open('./今日头条/'+name,'wb') as fp:fp.write(resp)print(new_url,'保存成功')def run(self):#检查该层是否存在今日头条这个文件夹if not os.path.exists('./今日头条'):os.mkdir('./今日头条')resp=self.get_resp_data()print(resp)self.get_url_set(resp)if __name__ == '__main__':for num in range(4):r1=beauty_girl(num)r1.run()