文章目录
- 1. Resources
- 2.Data processing process
- 3.Virtual network and public ip address
- 4. Kubernetes services
- 5. Yaml file
first , we enter the homepage of microsoft azure, and we can see a lot of servicse provided by the microsoft azure ,

1. Resources
account -> subscription-> resources group-> resources
Each account corresponds to one subscription, multiple resource groups under a subscription, and multiple resources in the resource group
(one thing we need to know is that there are several factors we have to divide all the resources to different group , such as environment(prod, dev , non-prod and so on ),BU(THA , VNM,sgp, hkg, jp and so on ), project and so on )
common kinds of resources :
-
virtual network , public network ,


-
disk , virtual machine ,

-
storage accounts(gen 2 (Azure data lake storage )(is for collecting data, which is from the Data factory(ADF Azure data factory ) )) , sql databases(the same as storage accounts ,but the different point is that the data is from data bricks, there are two databases , sql server and Azure Synapse Analytics (DW)) ,



-
data bricks(data bricks is a company and also is a service provide by this company , and the service is based on the platform of the azure , namely , Azure integrates with Data Bricks ) , data factory(ADF, to process the data and add the processed data to the sql databases
) ,


-
network security group

-
acr(azure container register, this resource is dedicated to storing images, and is to facilitate the deployment of the project on the platform of aks)
-
aks (azure kubernetes )

2.Data processing process
Data processing process diagram
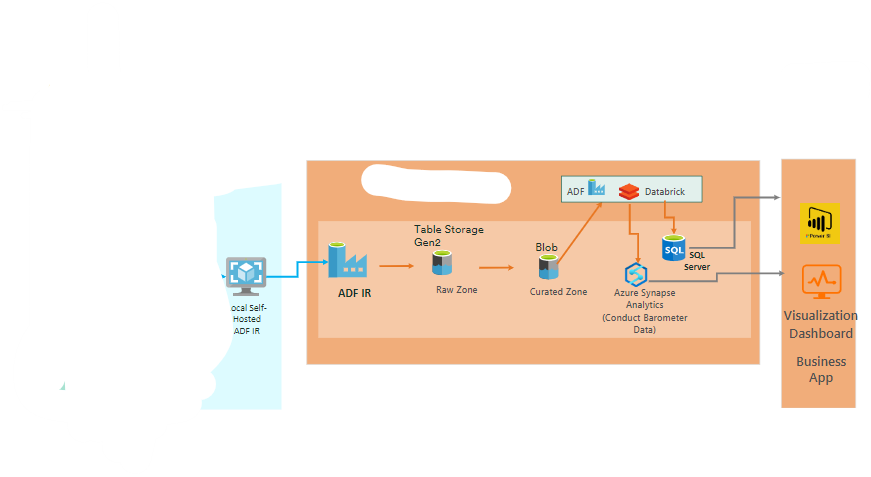
the data come from different country 's database or project
or anything else , and we use tools to ingest the data to the gen2 , there are two tools we mainly used , ingest real-time data with Kafka and get batched data through the Data Factory, and the data will go through the gen2 and then go the data bricks(there are sparks or some things to process the data ) , and then the data will get to the database(two of them ) , and finally the data will be used by some visualization tools to turn it into more valuable picture information
3.Virtual network and public ip address
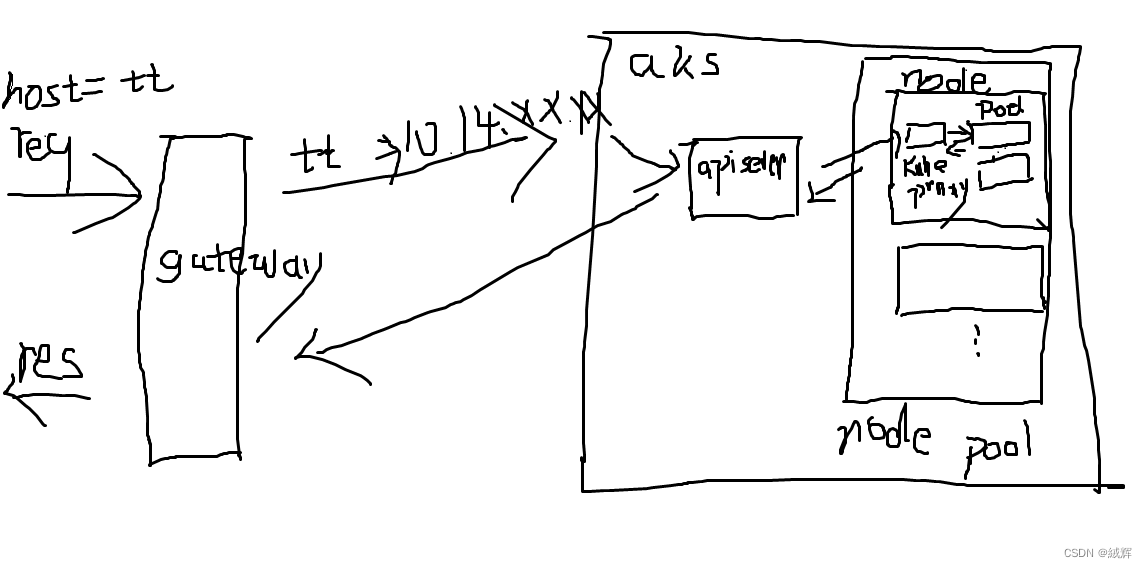
from the picture above , we know that the request from public get to the gateway and the gateway have a table
, the table have already stored the key value, the key is the host , and the value is the virtual network 's ip,
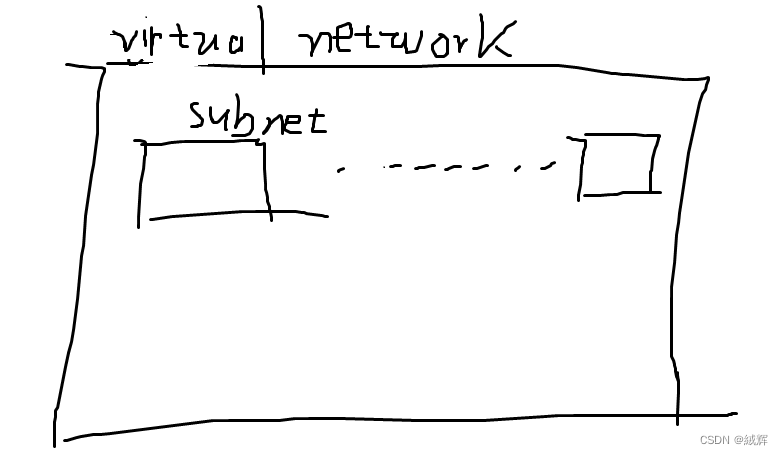
and we should know the thing that a virtual network we apply for is divided into subnet ,
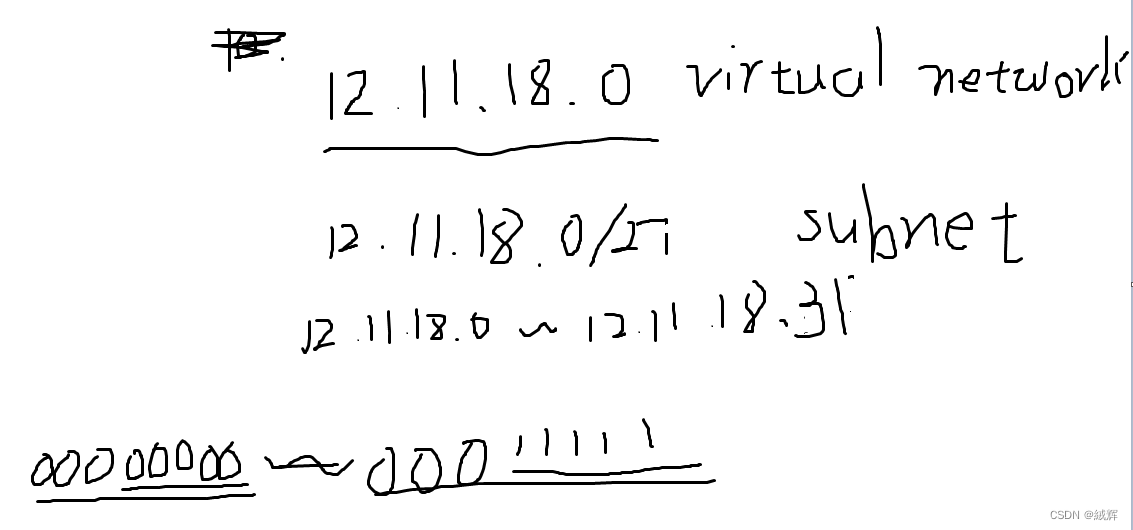
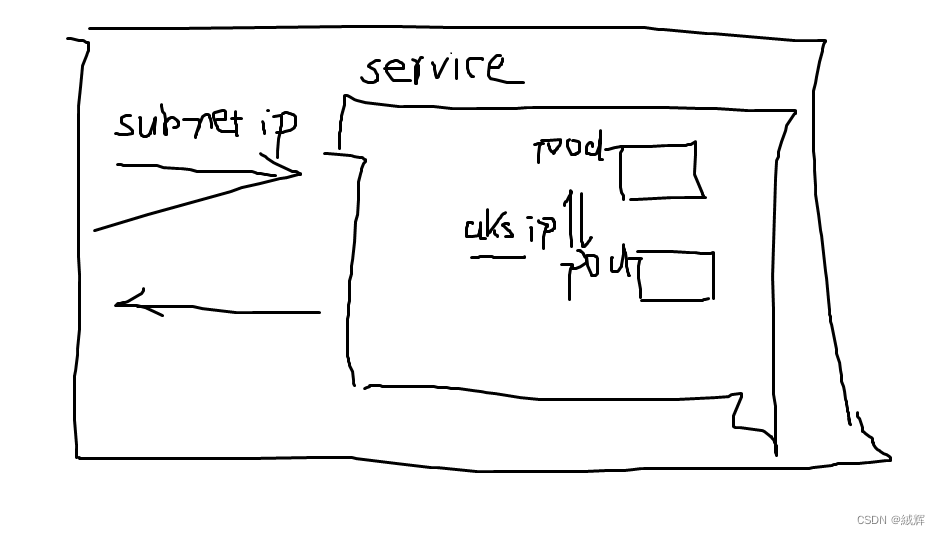
and then we know the request through gateway and turn to aks , and will get the service by the ip , and there come to another point is that the service we deploy in aks hava two ip address , the first one provided by aks for the communication between pod and pod , the second one is the subnet IP from the virtual network we applied for on the Azure platform , these ip address can be recognized by gateway , thus we need two ip address in one service .
and the gateway has a public ip address .
4. Kubernetes services

there are some factors push us to divide the space of the aks .
namespace -> service -> nodepool -> node -> pod

as we know , azure kubernetes have lots of aks cluster , and if we enter the internal of the cluster , we can see lots of node ,and we can get their status ,
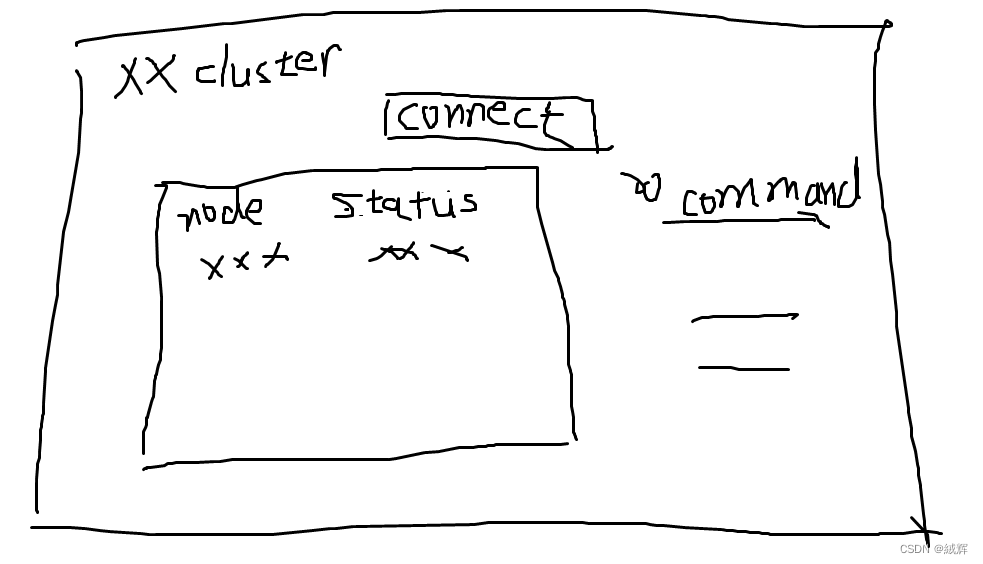
we can point the connect button ,and use powershell or bash to connect to the cluster , and do some operations , .
the learning of operations cancan see my other published articles。
5. Yaml file
Official website demo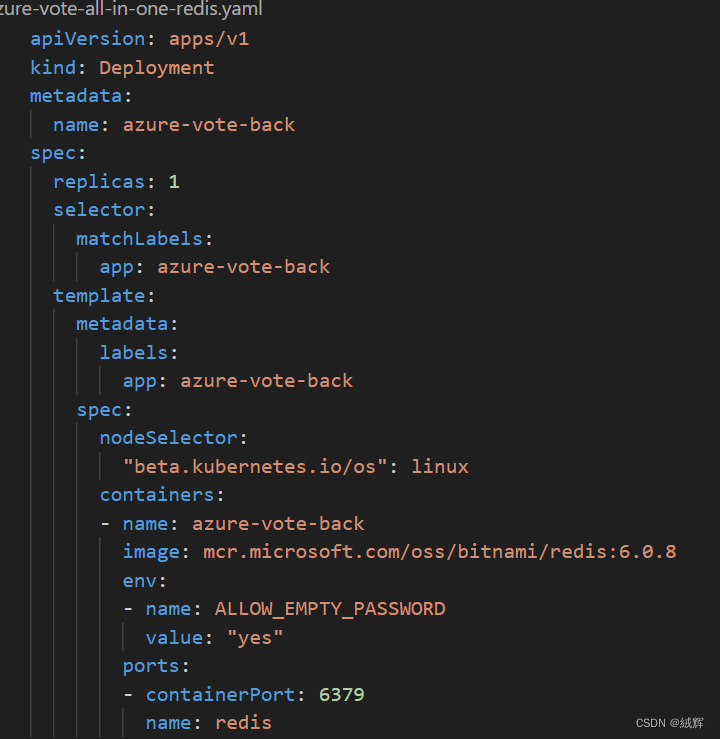
replicas: Number of replicas
#if there is dev environment , the value
# normally will be 1 .
#else the value will be 2 or 3
#based on the requirement
image : the image's address in acr
kind: the type of the resource
# there two type specical type
# cluster (without subnet ip address )
# loadbalaced has subnet ip address
port: the azure port of application
target port : the origin port of application