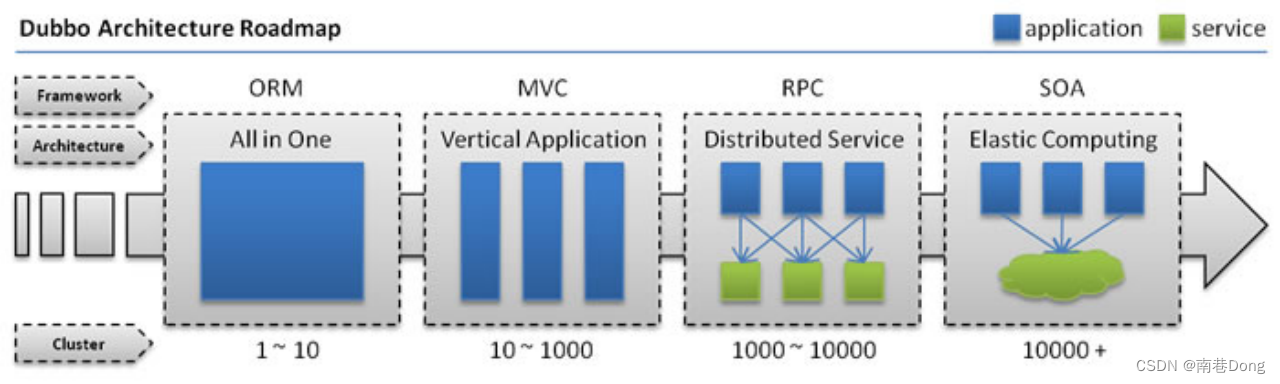
Dubbo是什么?
Dubbo是阿里巴巴开源的基于 Java 的高性能 RPC 分布式服务框架,现已成为 Apache 基金会孵化项目。
面试官问你如果这个都不清楚,那下面的就没必要问了。
官网:http://dubbo.apache.org
为什么要用Dubbo?
因为是阿里开源项目,国内很多互联网公司都在用,已经经过很多线上考验。内部使用了 Netty、Zookeeper,保证了高性能高可用性。dubbo现在已经升级3.X版本,和2.X版本区别很大
使用 Dubbo 可以将核心业务抽取出来,作为独立的服务,逐渐形成稳定的服务中心,可用于提高业务复用灵活扩展,使前端应用能更快速的响应多变的市场需求。
下面这张图可以很清楚的诠释,最重要的一点是,分布式架构可以承受更大规模的并发流量。
下面是 Dubbo 的服务治理图

Dubbo架构
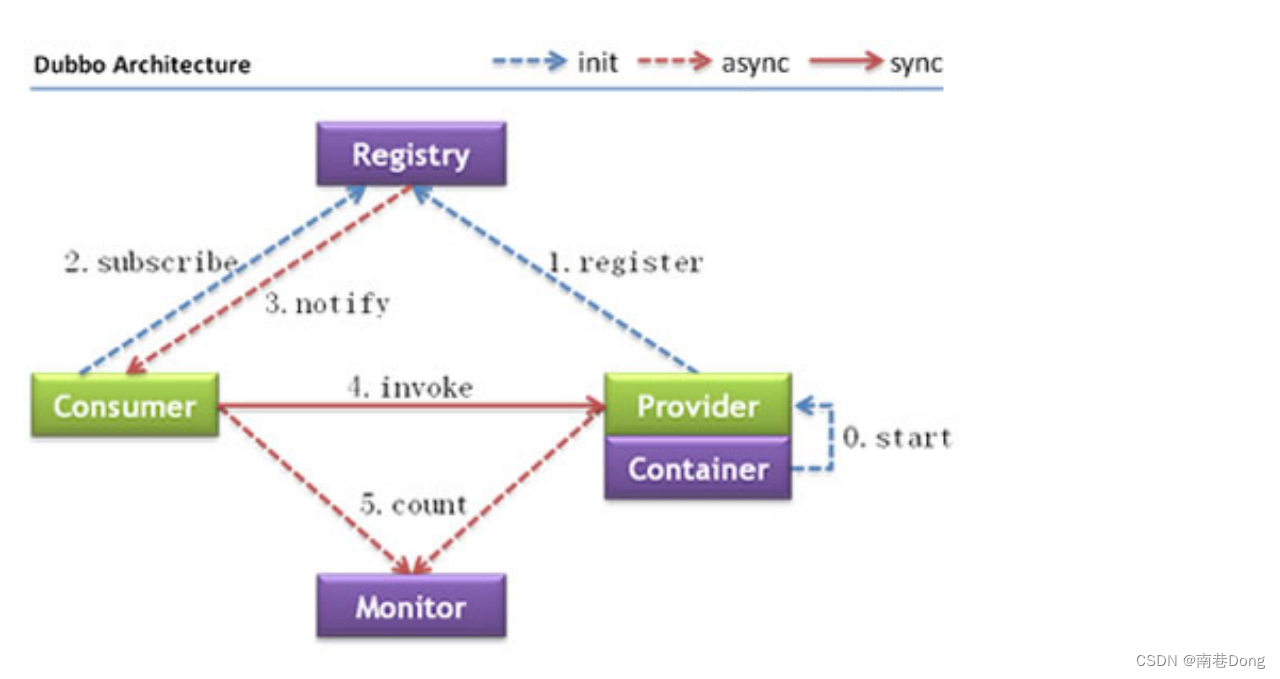
节点角色说明
节点 角色说明
Provider 暴露服务的服务提供方
Consumer 调用远程服务的服务消费方
Registry 服务注册与发现的注册中心
Monitor 统计服务的调用次数和调用时间的监控中心
Container 服务运行容器
dubbo工作原理
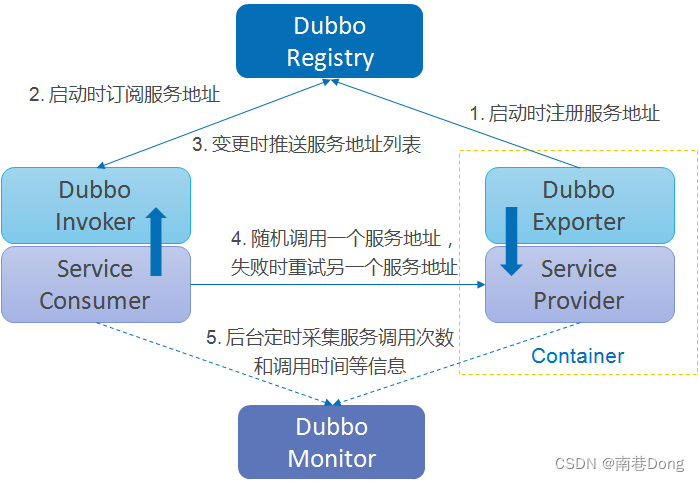
服务容器负责启动,加载,运行服务提供者。
服务提供者在启动时,向注册中心注册自己提供的服务。
服务消费者在启动时,向注册中心订阅自己所需的服务。
注册中心返回服务提供者地址列表给消费者,如果有变更,注册中心将基于长连接推送变更数据给消费者。
服务消费者,从提供者地址列表中,基于软负载均衡算法,选一台提供者进行调用,如果调用失败,再选另一台调用。
服务消费者和提供者,在内存中累计调用次数和调用时间,定时每分钟发送一次统计数据到监控中心。
Dubbo 架构具有以下几个特点,分别是连通性、健壮性、伸缩性、以及向未来架构的升级性。
连通性
注册中心负责服务地址的注册与查找,相当于目录服务,服务提供者和消费者只在启动时与注册中心交互,注册中心不转发请求,压力较小
监控中心负责统计各服务调用次数,调用时间等,统计先在内存汇总后每分钟一次发送到监控中心服务器,并以报表展示
服务提供者向注册中心注册其提供的服务,并汇报调用时间到监控中心,此时间不包含网络开销
服务消费者向注册中心获取服务提供者地址列表,并根据负载算法直接调用提供者,同时汇报调用时间到监控中心,此时间包含网络开销
注册中心,服务提供者,服务消费者三者之间均为长连接,监控中心除外
注册中心通过长连接感知服务提供者的存在,服务提供者宕机,注册中心将立即推送事件通知消费者
注册中心和监控中心全部宕机,不影响已运行的提供者和消费者,消费者在本地缓存了提供者列表
注册中心和监控中心都是可选的,服务消费者可以直连服务提供者
健状性
监控中心宕掉不影响使用,只是丢失部分采样数据
数据库宕掉后,注册中心仍能通过缓存提供服务列表查询,但不能注册新服务
注册中心对等集群,任意一台宕掉后,将自动切换到另一台
注册中心全部宕掉后,服务提供者和服务消费者仍能通过本地缓存通讯
服务提供者无状态,任意一台宕掉后,不影响使用
服务提供者全部宕掉后,服务消费者应用将无法使用,并无限次重连等待服务提供者恢复
伸缩性
注册中心为对等集群,可动态增加机器部署实例,所有客户端将自动发现新的注册中心
服务提供者无状态,可动态增加机器部署实例,注册中心将推送新的服务提供者信息给消费者
升级性
当服务集群规模进一步扩大,带动IT治理结构进一步升级,需要实现动态部署,进行流动计算,现有分布式服务架构不会带来阻力。下图是未来可能的一种架构:
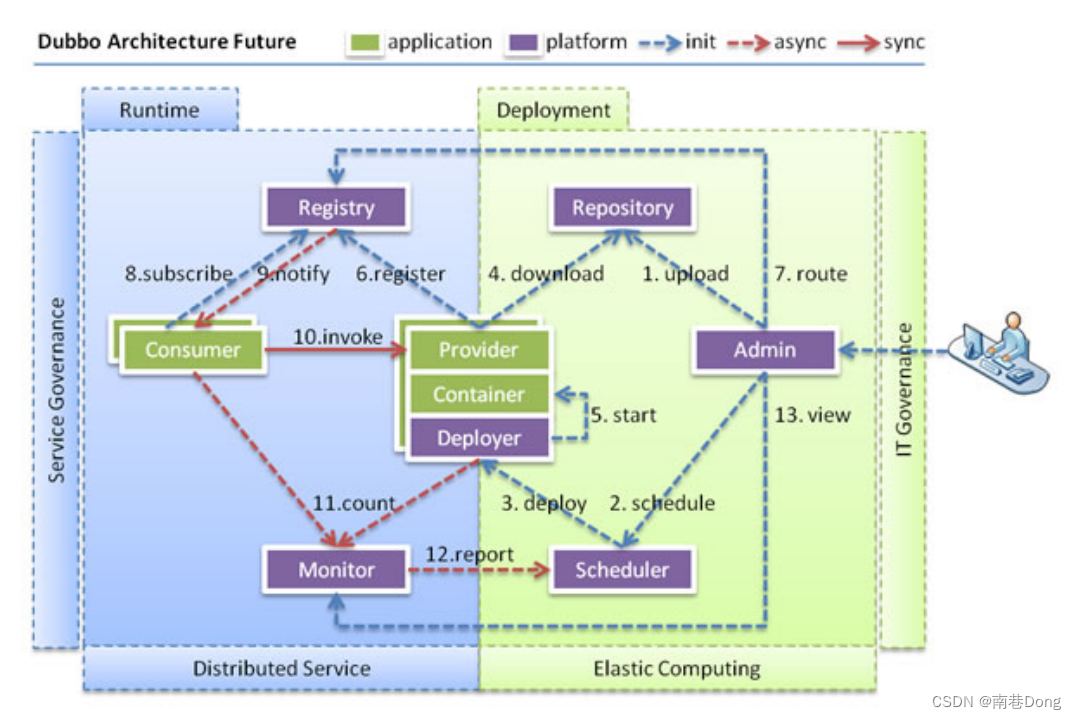
节点角色说明
节点 角色说明
Deployer 自动部署服务的本地代理
Repository 仓库用于存储服务应用发布包
Scheduler 调度中心基于访问压力自动增减服务提供者
Admin 统一管理控制台
Registry 服务注册与发现的注册中心
Monitor 统计服务的调用次数和调用时间的监控中心
Dubbo 和spring cloud区别
通信方式:Dubbo使用的是RPC通信,Spring Cloud使用的是HTTP RestFul方式
注册中心:Dubbo使用Zookeeper(官方推荐),还有Redis、Multicast、Simple注册中心,但不推荐,
Spring Cloud使用的是Spring Cloud Netflix Eureka
监控:Dubbo使用的是Dubbo-monitor,Spring Cloud使用的是Spring Boot admin
断路器:Dubbo在断路器这方面还不完善,Spring Cloud使用的是Spring Cloud Netflix Hystrix
分布式配置、网关服务、服务跟踪、消息总线、批量任务等
dubbo都支持什么协议,推荐用哪种?
dubbo://(推荐、默认)
Dubbo 缺省协议采用单一长连接和 NIO 异步通讯,适合于小数据量大并发的服务调用,以及服务消费者机器数远大于服务提供者机器数的情况。
反之,Dubbo 缺省协议不适合传送大数据量的服务,比如传文件,传视频等,除非请求量很低。
特性
缺省协议,使用基于 mina 1.1.7 和 hessian 3.2.1 的 tbremoting 交互。
连接个数:单连接
连接方式:长连接
传输协议:TCP
传输方式:NIO 异步传输
序列化:Hessian 二进制序列化
适用范围:传入传出参数数据包较小(建议小于100K),消费者比提供者个数多,单一消费者无法压满提供者,尽量不要用 dubbo 协议传输大文件或超大字符串。
适用场景:常规远程服务方法调用
rmi://
RMI 协议采用 JDK 标准的 java.rmi.* 实现,采用阻塞式短连接和 JDK 标准序列化方式。
注意:如果正在使用 RMI 提供服务给外部访问,同时应用里依赖了老的 common-collections 包 2 的情况下,存在反序列化安全风险 3。
特性
连接个数:多连接
连接方式:短连接
传输协议:TCP
传输方式:同步传输
序列化:Java 标准二进制序列化
适用范围:传入传出参数数据包大小混合,消费者与提供者个数差不多,可传文件。
适用场景:常规远程服务方法调用,与原生RMI服务互操作
hessian://
Hessian 协议用于集成 Hessian 的服务,Hessian 底层采用 Http 通讯,采用 Servlet 暴露服务,Dubbo 缺省内嵌 Jetty 作为服务器实现。
Dubbo 的 Hessian 协议可以和原生 Hessian 服务互操作,即:
提供者用 Dubbo 的 Hessian 协议暴露服务,消费者直接用标准 Hessian 接口调用
或者提供方用标准 Hessian 暴露服务,消费方用 Dubbo 的 Hessian 协议调用。
特性
连接个数:多连接
连接方式:短连接
传输协议:HTTP
传输方式:同步传输
序列化:Hessian二进制序列化
适用范围:传入传出参数数据包较大,提供者比消费者个数多,提供者压力较大,可传文件。
适用场景:页面传输,文件传输,或与原生hessian服务互操作
http://
基于 HTTP 表单的远程调用协议,采用 Spring 的 HttpInvoker 实现 1
特性
连接个数:多连接
连接方式:短连接
传输协议:HTTP
传输方式:同步传输
序列化:表单序列化
适用范围:传入传出参数数据包大小混合,提供者比消费者个数多,可用浏览器查看,可用表单或URL传入参数,暂不支持传文件。
适用场景:需同时给应用程序和浏览器 JS 使用的服务
webservice://
基于 WebService 的远程调用协议,基于 Apache CXF 1 的 frontend-simple 和 transports-http 实现 2。
可以和原生 WebService 服务互操作,即:
提供者用 Dubbo 的 WebService 协议暴露服务,消费者直接用标准 WebService 接口调用,
或者提供方用标准 WebService 暴露服务,消费方用 Dubbo 的 WebService 协议调用。
特性
连接个数:多连接
连接方式:短连接
传输协议:HTTP
传输方式:同步传输
序列化:SOAP 文本序列化
适用场景:系统集成,跨语言调用
thrift://
当前 dubbo 支持 1的 thrift 协议是对 thrift 原生协议 2 的扩展,在原生协议的基础上添加了一些额外的头信息,比如 service name,magic number 等。
使用 dubbo thrift 协议同样需要使用 thrift 的 idl compiler 编译生成相应的 java 代码,后续版本中会在这方面做一些增强。
memcached://
redis://
rest://
服务之间的调用是阻塞的吗
默认是同步等待结果阻塞的,支持异步调用。
Dubbo 是基于 NIO 的非阻塞实现并行调用,客户端不需要启动多线程即可完成并行调用多个远程服务,相对多线程开销较小,异步调用会返回一个 Future 对象
同步调用
同步调用是一种阻塞式的调用方式,即 Consumer 端代码一直阻塞等待,直到 Provider 端返回为止;
通常,一个典型的同步调用过程如下:
Consumer 业务线程调用远程接口,向 Provider 发送请求,同时当前线程处于阻塞状态;
Provider 接到 Consumer 的请求后,开始处理请求,将结果返回给 Consumer;
Consumer 收到结果后,当前线程继续往后执行。
这里有 2 个问题:
Consumer 业务线程是怎么进入阻塞状态的?
Consumer 收到结果后,如果唤醒业务线程往后执行的?
其实,Dubbo 的底层 IO 操作都是异步的。Consumer 端发起调用后,得到一个 Future 对象。对于同步调用,业务线程通过Future#get(timeout),阻塞等待 Provider 端将结果返回;timeout则是 Consumer 端定义的超时时间。当结果返回后,会设置到此 Future,并唤醒阻塞的业务线程;当超时时间到结果还未返回时,业务线程将会异常返回。
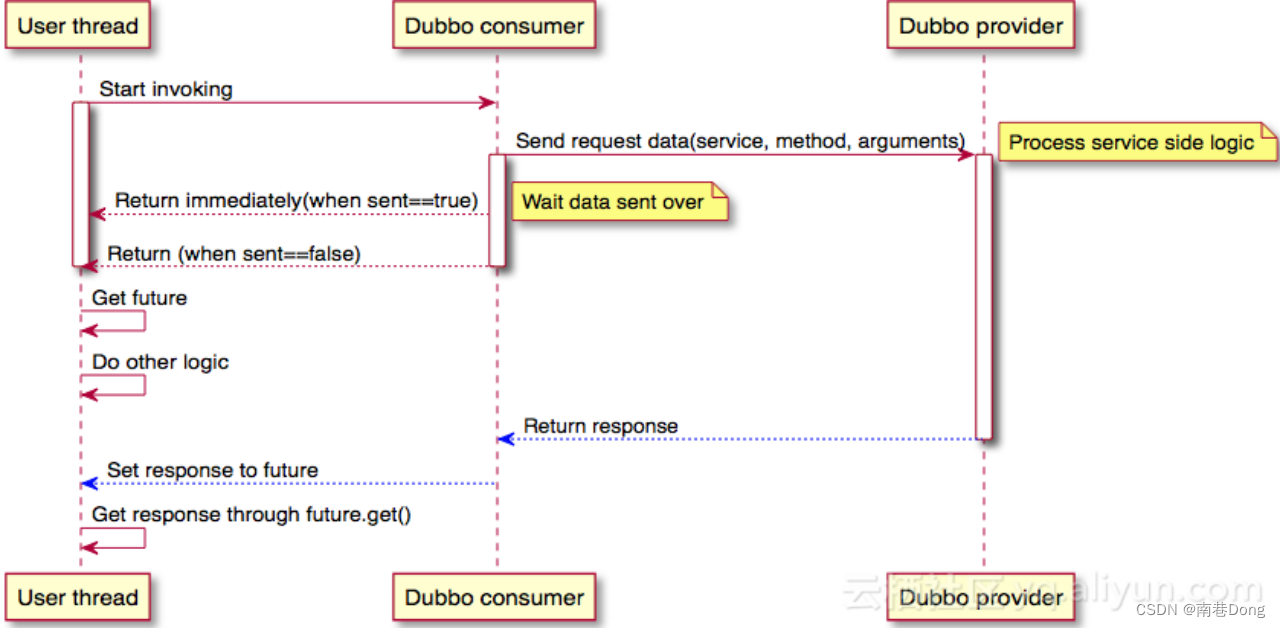
异步调用
基于 Dubbo 底层的异步 NIO 实现异步调用,对于 Provider 响应时间较长的场景是必须的,它能有效利用 Consumer 端的资源,相对于 Consumer 端使用多线程来说开销较小。
异步调用,对于 Provider 端不需要做特别的配置。下面的例子中,Provider 端接口定义如下:
public interface AsyncService {
String goodbye(String name);
}
Consumer 配置
<dubbo:reference id=“asyncService” interface=“com.alibaba.dubbo.samples.async.api.AsyncService”>
<dubbo:method name=“goodbye” async=“true”/>
</dubbo:reference>
需要异步调用的方法,均需要使用 dubbo:method/标签进行描述。
Consumer 端发起调用
AsyncService service = …;
String result = service.goodbye(“samples”);// 这里的返回值为空,请不要使用
Future future = RpcContext.getContext().getFuture();
… // 业务线程可以开始做其他事情
result = future.get(); // 阻塞需要获取异步结果时,也可以使用 get(timeout, unit) 设置超时时间
Dubbo Consumer 端发起调用后,同时通过RpcContext.getContext().getFuture()获取跟返回结果关联的Future对象,然后就可以开始处理其他任务;当需要这次异步调用的结果时,可以在任意时刻通过future.get(timeout)来获取。
一些特殊场景下,为了尽快调用返回,可以设置是否等待消息发出:
sent=“true” 等待消息发出,消息发送失败将抛出异常;
sent=“false” 不等待消息发出,将消息放入 IO 队列,即刻返回。
默认为fase。配置方式如下:
<dubbo:method name=“goodbye” async=“true” sent=“true” />
如果你只是想异步,完全忽略返回值,可以配置 return=“false”,以减少 Future 对象的创建和管理成本:
<dubbo:method name=“goodbye” async=“true” return=“false”/>
此时,RpcContext.getContext().getFuture()将返回null。
整个异步调用的时序图如下:
Dubbo默认使用什么注册中心,还有别的选择吗?
推荐使用 Zookeeper 作为注册中心,还有 Redis、Multicast、Simple 注册中心,但不推荐
Dubbo的注册中心有好多种,包括Multicast、Zookeeper、Redis、Simple等。Dubbo官方推荐使用Zookeeper注册中心,我所使用过的也只是Zookeeper注册中心。
首先介绍一下Zookeeper:
ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,是Google的Chubby一个开源的实现,是Hadoop和Hbase的重要组件。它是一个为分布式应用提供一致性服务的软件,提供的功能包括:配置维护、域名服务、分布式同步、组服务等。
建议使用dubbo-2.3.3以上版本的zookeeper注册中心客户端
nacos作为注册中心,nacos在升级到2.X版本后,更加友好支持应用级注册和元数据中心
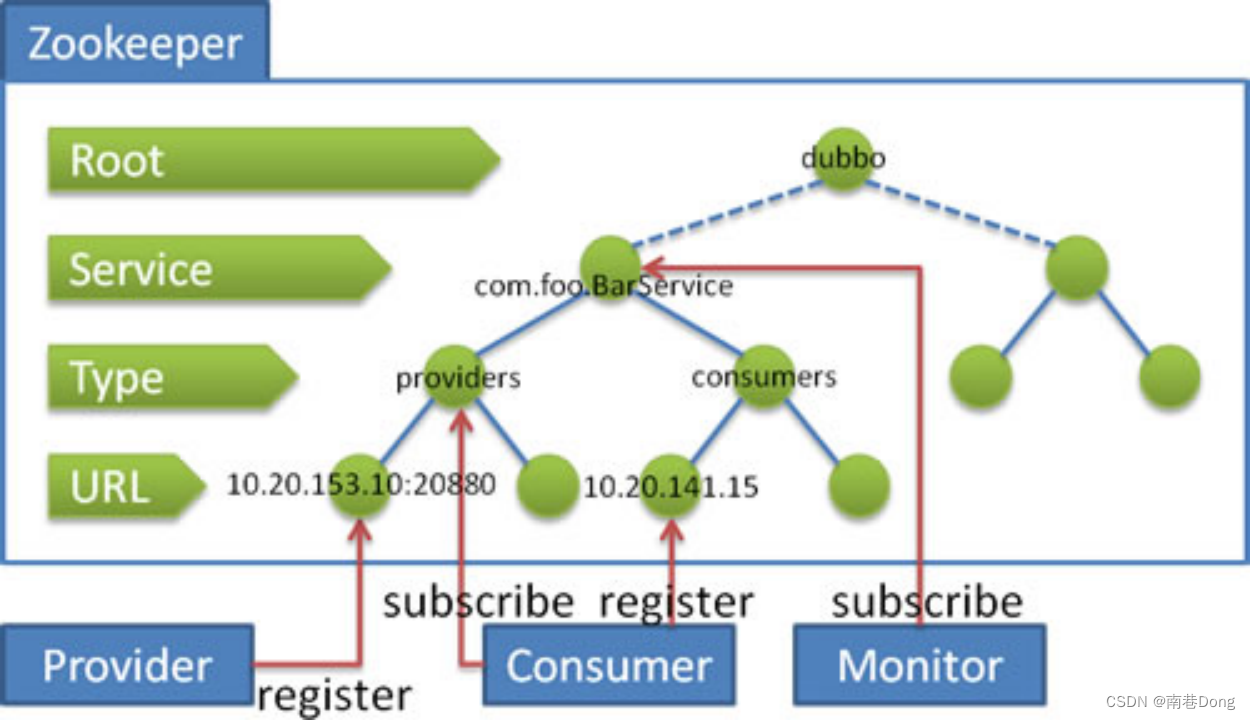
流程说明:
服务提供者启动时
向/dubbo/com.foo.BarService/providers目录下写入自己的URL地址。
服务消费者启动时
订阅/dubbo/com.foo.BarService/providers目录下的提供者URL地址。
并向/dubbo/com.foo.BarService/consumers目录下写入自己的URL地址。
监控中心启动时
订阅/dubbo/com.foo.BarService目录下的所有提供者和消费者URL地址。
支持以下功能:
当提供者出现断电等异常停机时,注册中心能自动删除提供者信息。
当注册中心重启时,能自动恢复注册数据,以及订阅请求。
当会话过期时,能自动恢复注册数据,以及订阅请求。
当设置<dubbo:registry check=“false” />时,记录失败注册和订阅请求,后台定时重试。
可通过<dubbo:registry username=“admin” password=“1234” />设置zookeeper登录信息。
可通过<dubbo:registry group=“dubbo” />设置zookeeper的根节点,不设置将使用无根树。
支持号通配符<dubbo:reference group="" version=“*” />,可订阅服务的所有分组和所有版本的提供者。
Dubbo序列化
在Dubbo RPC中,同时支持多种序列化方式,默认hessian:
(1)dubbo序列化,阿里尚不成熟的java序列化实现。
(2)hessian2序列化:hessian是一种跨语言的高效二进制的序列化方式,但这里实际不是原生的hessian2序列化,而是阿里修改过的hessian lite,它是dubbo RPC默认启用的序列化方式。
(3)json序列化:目前有两种实现,一种是采用的阿里的fastjson库,另一种是采用dubbo中自已实现的简单json库,一般情况下,json这种文本序列化性能不如二进制序列化。
(4)java序列化:主要是采用JDK自带的java序列化实现,性能很不理想
服务提供者能实现失效踢出是什么原理?
服务失效踢出基于 Zookeeper 的临时节点原理
服务上线怎么不影响旧版本
当一个接口实现,出现不兼容升级时,可以用版本号过渡,版本号不同的服务相互间不引用。
在低压力时间段,先升级一半提供者为新版本
再将所有消费者升级为新版本
然后将剩下的一半提供者升级为新版本
<dubbo:service interface=“com.foo.BarService” version=“1.0.0” />
<dubbo:service interface=“com.foo.BarService” version=“2.0.0” />
<dubbo:reference id=“barService” interface=“com.foo.BarService” version=“1.0.0” />
<dubbo:reference id=“barService” interface=“com.foo.BarService” version=“2.0.0” />
不区分版本:(2.2.0以上版本支持)
<dubbo:reference id=“barService” interface=“com.foo.BarService” version=“*” />
如何解决服务调用链过长的问题?
Dubbo 可以使用 Pinpoint 和 Apache Skywalking(Incubator) 实现分布式服务追踪,当然还有其他很多方案
zipkin为分布式链路调用监控系统,聚合各业务系统调用延迟数据,达到链路调用监控跟踪
dubbo核心配置
dubbo:service/
dubbo:reference/
dubbo:protocol/
dubbo:registry/
dubbo:application/
dubbo:provider/
dubbo:consumer/
dubbo:method/
provider
<dubbo:application name="xixi_provider" />
<!-- 使用multicast广播注册中心暴露服务地址
<dubbo:registry address="multicast://224.5.6.7:1234" />-->
<!-- 使用zookeeper注册中心暴露服务地址 -->
<-- <dubbo:registry protocol=“zookeeper” address=“${zookeeper.address}” check=“false” file=“dubbo.properties” /> -->
<dubbo:registry address=“zookeeper://127.0.0.1:2181” />
<dubbo:protocol name=“dubbo” port=“20880” />
<dubbo:service interface=“com.unj.dubbotest.provider.DemoService” ref=“demoService” version=“1.0” timeout=“5000”/>
consumer
<dubbo:application name="hehe_consumer" />
<!-- 使用zookeeper注册中心暴露服务地址 -->
<dubbo:registry address="zookeeper://127.0.0.1:2181" />
<!-- 生成远程服务代理,可以像使用本地bean一样使用demoService -->
<dubbo:reference id="demoService" interface="com.unj.dubbotest.provider.DemoService" url="${study.dubbo.url}" version="1.0" timeout="20000" check="false"/>
同一个服务多个注册的情况下可以直连某一个服务吗?
可以直连,修改配置即可,也可以通过telnet直接某个服务
服务注册与发现的流程图

集群容错
在集群调用失败时,Dubbo 提供了多种容错方案,缺省为 failover 重试。
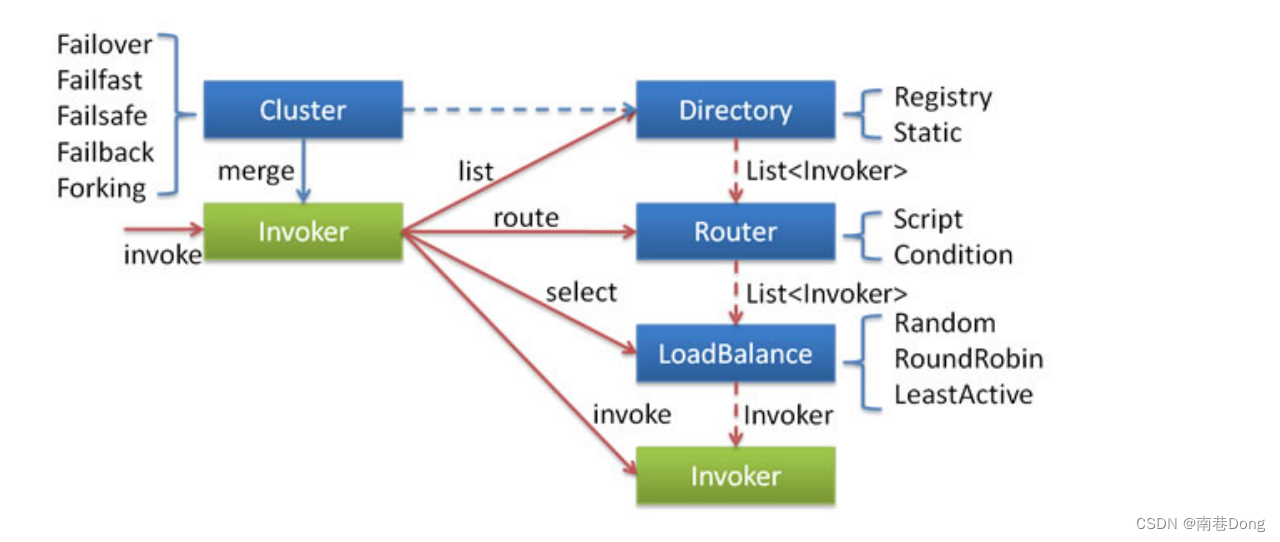
各节点关系:
这里的 Invoker 是 Provider 的一个可调用 Service 的抽象,Invoker 封装了 Provider 地址及 Service 接口信息
Directory 代表多个 Invoker,可以把它看成 List ,但与 List 不同的是,它的值可能是动态变化的,比如注册中心推送变更
Cluster 将 Directory 中的多个 Invoker 伪装成一个 Invoker,对上层透明,伪装过程包含了容错逻辑,调用失败后,重试另一个
Router 负责从多个 Invoker 中按路由规则选出子集,比如读写分离,应用隔离等
LoadBalance 负责从多个 Invoker 中选出具体的一个用于本次调用,选的过程包含了负载均衡算法,调用失败后,需要重选
- 集群容错模式
可以自行扩展集群容错策略,参见:集群扩展
- Failover Cluster
失败自动切换,当出现失败,重试其它服务器 1。通常用于读操作,但重试会带来更长延迟。可通过 retries=“2” 来设置重试次数(不含第一次)。
重试次数配置如下:
<dubbo:service retries=“2” />
或
<dubbo:reference retries=“2” />
或
dubbo:reference
<dubbo:method name=“findFoo” retries=“2” />
</dubbo:reference>
- Failfast Cluster
快速失败,只发起一次调用,失败立即报错。通常用于非幂等性的写操作,比如新增记录。
- Failsafe Cluster
失败安全,出现异常时,直接忽略。通常用于写入审计日志等操作。
- Failback Cluster
失败自动恢复,后台记录失败请求,定时重发。通常用于消息通知操作。
- Forking Cluster
并行调用多个服务器,只要一个成功即返回。通常用于实时性要求较高的读操作,但需要浪费更多服务资源。可通过 forks=“2” 来设置最大并行数。
- Broadcast Cluster
广播调用所有提供者,逐个调用,任意一台报错则报错 2。通常用于通知所有提供者更新缓存或日志等本地资源信息。
说一下dubbo的调用过程
调用过程图:
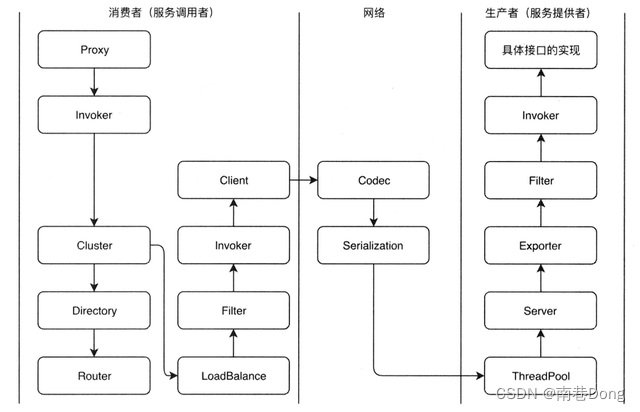
1.Proxy持有一个Invoker对象,使用Invoker调用
2.之后通过Cluster进行负载容错,失败重试
3.调用Directory获取远程服务的Invoker列表
4.负载均衡用户配置了路由规则,则根据路由规则过滤获取到的Invoker列表用户没有配置路由规则或配置路由后还有很多节点,则使用LoadBalance方法做负载均衡,选用一个可以调用的Invoker
5.经过一个一个过滤器链,通常是处理上下文、限流、计数等。
6.会使用Client做数据传输
7.私有化协议的构造(Codec)8.进行序列化
9.服务端收到这个Request请求,将其分配到ThreadPool中进行处理
10.Server来处理这些Request
11.根据请求查找对应的Exporter
12.之后经过一个服务提供者端的过滤器链
13.然后找到接口实现并真正的调用,将请求结果返回
注册中心挂了,consumer还能不能调用provider?
可以的,启动 dubbo 时,消费者会从 zookeeper 拉取注册的生产者的地址接口等数据,缓存在本地。
每次调用时,按照本地存储的地址进行调用。provider才调用不通
怎么实现动态感知服务下线的呢?
服务订阅通常有 pull 和 push 两种方式:
pull 模式需要客户端定时向注册中心拉取配置;
push 模式采用注册中心主动推送数据给客户端;
DubboZookeeper注册中心采用是事件通知与客户端拉取方式。服务第一次订阅的时候将会拉取对应目录下全量数据,然后在订阅的节点注册一个 watcher。一旦目录节点下发生任何数据变化,Zookeeper将会通过 watcher 通知客户端。客户端接到通知,将会重新拉取该目录下全量数据,并重新注册 watcher。利用这个模式,Dubbo服务就可以就做到服务的动态发现。
注意:Zookeeper提供了“心跳检测”功能,它会定时向各个服务提供者发送一个请求(实际上建立的是一个 socket 长连接),如果长期没有响应,服务中心就认为该服务提供者已经“挂了”,并将其剔除。
dubbo负载均衡怎么实现?
客户端使用MockClusterInvoker对象调用远程服务。默认情况下,MockClusterInvoker对象将调用远程服务的任务委托给FailoverClusterInvoker。FailoverClusterInvoker通过select方法选择合适的服务。select方法的入参包括负载均衡对象,InvokerWrapper对象集合等,其中每个服务对应一个InvokerWrapper对象,InvokerWrapper对象是对远程调用服务的包装类。
服务调用是阻塞的吗?
默认是阻塞的,可以异步调用,没有返回值的可以这么做。
dubbo安全机制方面如何解决?
dubbo 通过 token 令牌防止用户绕过注册中心直连,然后在注册中心管理授权,dubbo 提供了黑白名单,控制服务所允许的调用方。
Dubbo SPI 和 Java SPI 区别?
JDK 标准的 SPI 会一次性加载所有的扩展实现,如果有的扩展很耗时,但也没用上,很浪费资源。所以只希望加载某个的实现,就不现实了
DUBBO SPI:
1、 对 Dubbo 进行扩展,不需要改动 Dubbo 的源码
2、 延迟加载,可以一次只加载自己想要加载的扩展实现。
3、 增加了对扩展点 IOC 和 AOP 的支持,一个扩展点可以直接 setter 注入其它扩展点。
4、 Dubbo 的扩展机制能很好的支持第三方 IoC 容器,默认支持 Spring Bean。
Dubbo 的整体架构设计有哪些分层?
接口服务层(Service):该层与业务逻辑相关,根据 provider 和 consumer 的业务设计对应的接口和实现
配置层(Config):对外配置接口,以 ServiceConfig 和 ReferenceConfig 为中心
服务代理层(Proxy):服务接口透明代理,生成服务的客户端 Stub 和 服务端的 Skeleton,以 ServiceProxy 为中心,扩展接口为 ProxyFactory
服务注册层(Registry):封装服务地址的注册和发现,以服务 URL 为中心,扩展接口为 RegistryFactory、Registry、RegistryService
路由层(Cluster):封装多个提供者的路由和负载均衡,并桥接注册中心,以Invoker 为中心,扩展接口为 Cluster、Directory、Router和LoadBlancce
监控层(Monitor):RPC调用次数和调用时间监控,以 Statistics 为中心,扩展接口为 MonitorFactory、Monitor和MonitorService
远程调用层(Protocal):封装 RPC 调用,以 Invocation 和 Result 为中心,扩展接口为 Protocal、Invoker和Exporter
信息交换层(Exchange):封装请求响应模式,同步转异步。以 Request 和 Response 为中心,扩展接口为 Exchanger、ExchangeChannel、ExchangeClient和ExchangeServer
网络传输层(Transport):抽象 mina 和 netty 为统一接口,以 Message 为中心,扩展接口为Channel、Transporter、Client、Server和Codec
数据序列化层(Serialize):可复用的一些工具,扩展接口为Serialization、 ObjectInput、ObjectOutput和ThreadPool
Dubbo 的使用场景有哪些?
1、 透明化的远程方法调用:就像调用本地方法一样调用远程方法,只需简单配置,没有任何API侵入。
2、 软负载均衡及容错机制:可在内网替代 F5 等硬件负载均衡器,降低成本,减少单点。
3、 服务自动注册与发现:不再需要写死服务提供方地址,注册中心基于接口名查询服务提供者的IP地址,并且能够平滑添加或删除服务提供者。
Dubbo服务降级,失败重试怎么做?
可以通过dubbo:reference 中设置mock=“return null”。mock的值也可以修改为true,然后在跟接口同一个路径下实现一个Mock类,命名规则是"接口名称+Mock"后缀。然后在Mock类里实现自己的降级逻辑。
dubbo支持哪些系列化方式?
1. hessian2:跨语言的高效二进制序列化方式。但这里实际不是原生的hessian2序列化,而是阿里修改过的,它是dubbo RPC默认启用的序列化方式。
2. avro:将数据结构或对象转化成便于存储或传输的格式。Avro设计之初就用来支持数据密集型应用,适合于远程或本地大规模数据的存储和交换。
3. fastjson:一个Java语言编写的高性能功能完善的JSON库。它采用一种“假定有序快速匹配”的算法,把JSON Parse的性能提升到极致,是目前Java语言中最快的JSON库。Fastjson接口简单易用,已经被广泛使用在缓存序列化、协议交互、Web输出、Android客户端等多种应用场景。
4. fst:重新实现的 Java 快速对象序列化的开发包。序列化速度更快(2-10倍)、体积更小,而且兼容 JDK 原生的序列化。
5. gson:一个简单的基于Java的库,用于将Java对象序列化为JSON,反之亦然。 它是由Google开发的一个开源库。
6. jdk:JDK自带序列化。
7. kryo:一个快速高效的Java对象图形序列化框架,主要特点是性能、高效和易用。该项目用来序列化对象到文件、数据库或者网络。
8. protobuf: Google 的语言中立、平台中立、可扩展的结构化数据序列化机制。
9. protostuff:一个 java 序列化库,内置支持向前向后兼容性(模式演变)和验证。
dubbo注册发现流程?
1、首先服务的提供者启动服务到注册中心注册,包括各种ip端口信息,Dubbo会同时注册该项目提供的远程调用的方法
2、服务的消费者(使用者)注册到注册中心,订阅发现
3、当有新的远程调用方法注册到注册中心时,注册中心会通知服务的消费者有哪些新的方法,如何调用
4、RPC调用:服务的调用者就无需知道ip和端口号,只需要服务名称就可以调用到服务提供者的方法
外传
😜 原创不易,如若本文能够帮助到您的同学
🎉 支持我:关注我+点赞👍+收藏⭐️
📝 留言:探讨问题,看到立马回复
💬 格言:己所不欲勿施于人 扬帆起航、游历人生、永不言弃!🔥