前言
最近犀牛书看了将近一半,对JavaScript算是有了个大概的了解,于是考虑写一些简单的脚本做个练习
思路
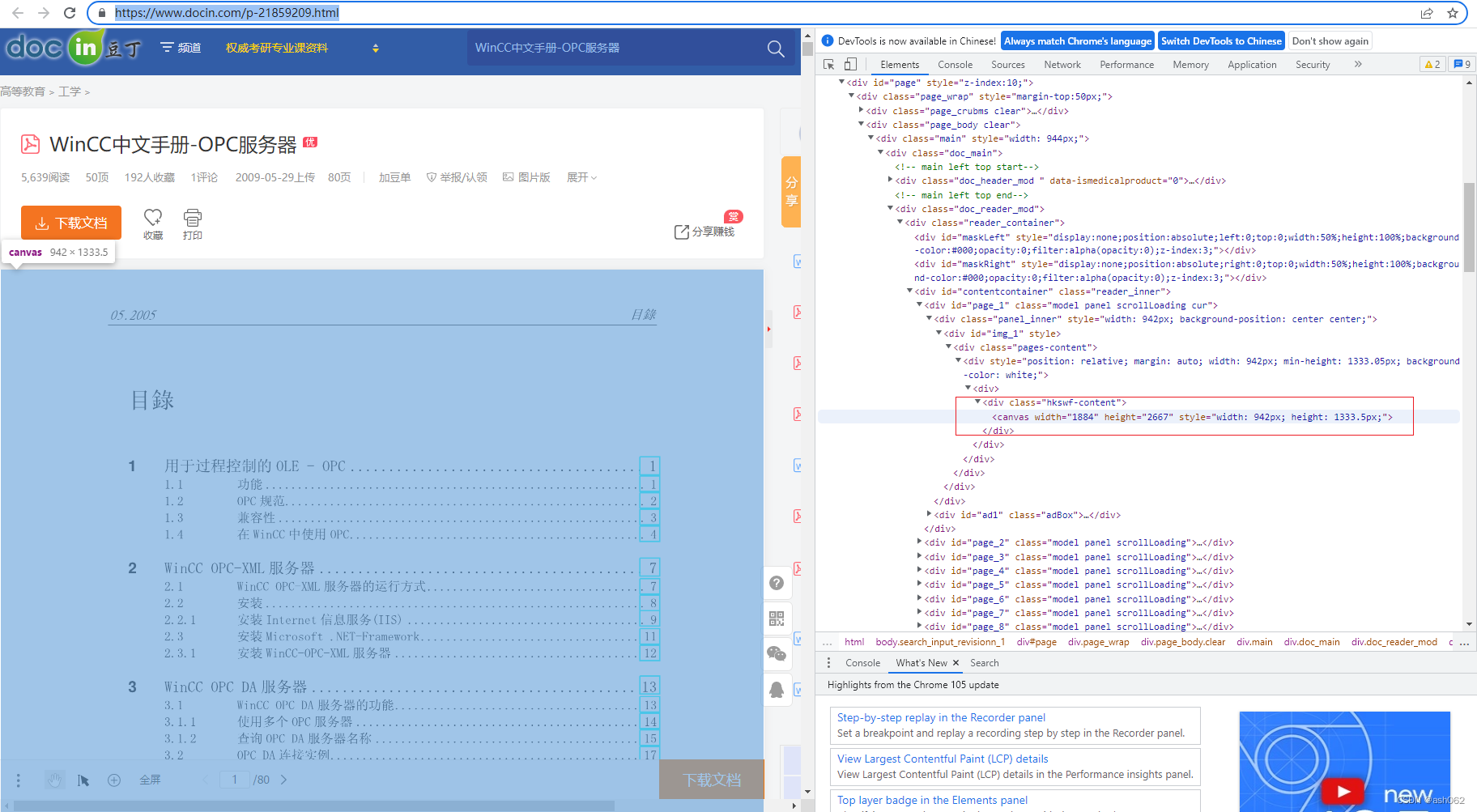
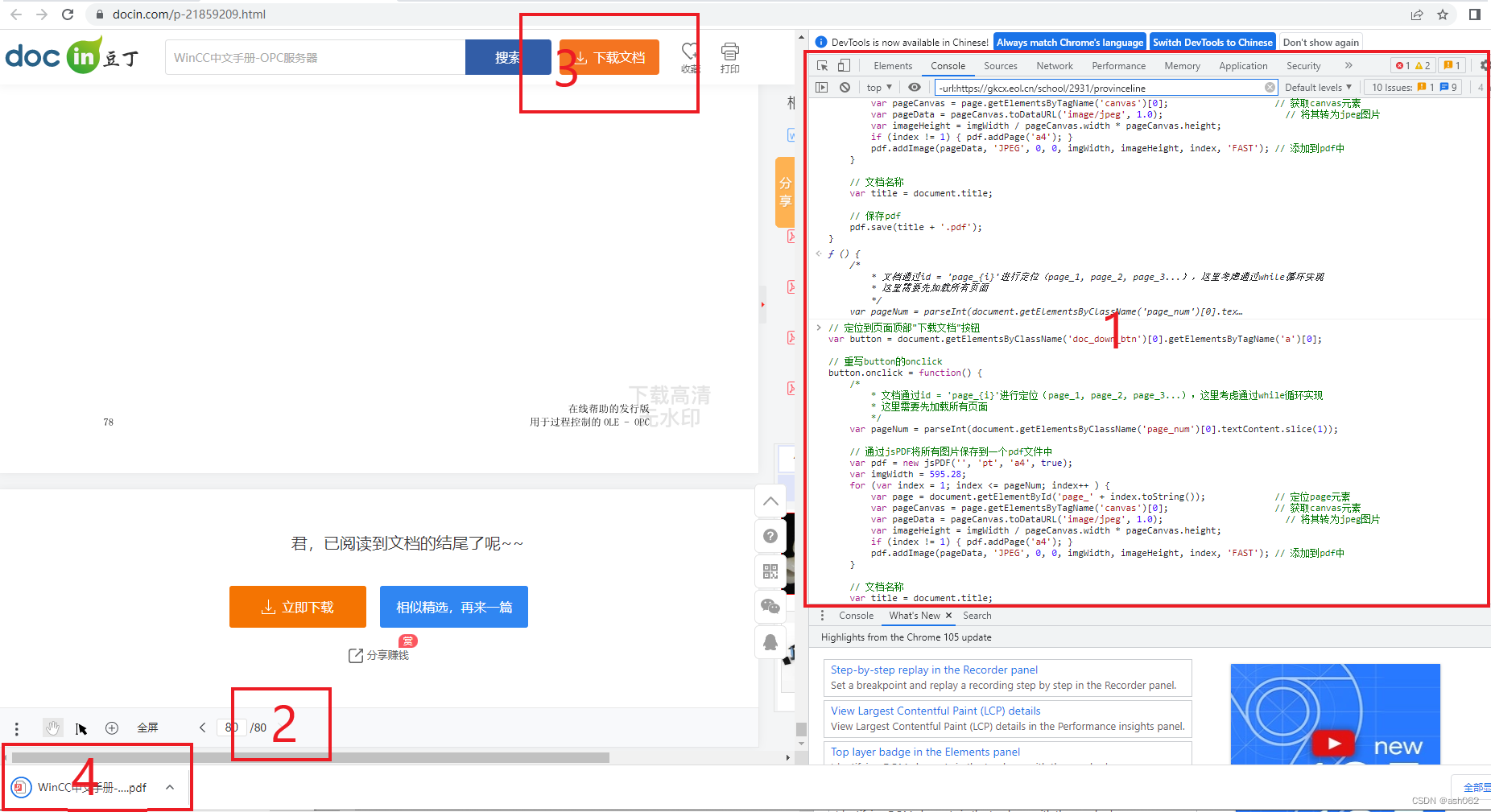
在豆丁网随便找篇文档(测试文档),通过F12查看网页结构,可以看到文档的每一页实际位于id = page_i的canvas元素内,此外,不难发现对于某一页来说,如果该页没有出现在浏览器中,则其内的canvas元素不会加载。因此具体思路如下:
1、通过底部工具栏的<span class='page_num'>确定文档页数
2、手动加载全部文档,考虑这一步比较麻烦,把底部工具栏的下一页重写为将文档缓慢滚动到底部
3、通过引入jsPDF将各canvas元素转为图片拼接
4、重写文档顶部“文档下载”按钮进行下载
代码
// 加载jsPDF
var script_jsPDF = document.createElement('script');
script_jsPDF.type = 'text/javascript';
script_jsPDF.src = 'https://cdnjs.cloudflare.com/ajax/libs/jspdf/1.0.272/jspdf.debug.js';
document.body.appendChild(script_jsPDF);// 重写下一页按钮为缓慢滚动文档
var nextPage = document.getElementById('nextPage');nextPage.onclick = function() {window.scrollTo(0, 0); // 滚动到文档顶部setInterval(function() { scrollBy(0, 300) }, 300); // 缓慢滚动使文档加载
}// 定位到页面顶部"下载文档"按钮
var button = document.getElementsByClassName('doc_down_btn')[0];// 重写button的onclick
button.onclick = function() {/** 文档通过id = 'page_{i}'进行定位(page_1, page_2, page_3...),这里考虑通过while循环实现* 这里需要先加载所有页面*/var pageNum = parseInt(document.getElementsByClassName('page_num')[0].textContent.slice(1));// 通过jsPDF将所有图片保存到一个pdf文件中var pdf = new jsPDF('', 'pt', 'a4', true);var imgWidth = 595.28;for (var index = 1; index <= pageNum; index++ ) {var page = document.getElementById('page_' + index.toString()); // 定位page元素var pageCanvas = page.getElementsByTagName('canvas')[0]; // 获取canvas元素var pageData = pageCanvas.toDataURL('image/jpeg', 1.0); // 将其转为jpeg图片var imageHeight = imgWidth / pageCanvas.width * pageCanvas.height;if (index != 1) { pdf.addPage('a4'); }pdf.addImage(pageData, 'JPEG', 0, 0, imgWidth, imageHeight, index, 'FAST'); // 添加到pdf中}// 文档名称var title = document.title;// 保存pdfpdf.save(title + '.pdf');
}操作
1、F12打开浏览器开发工具,切换到控制台(console),把上面代码粘贴进去
2、单击下一页,待网页到底部后单击顶部工具栏的“下载文档”即可完成下载