文章目录
- AQS(AbstractQueuedSynchronizer)
- AQS实现原理
- AQS操作重点方法
- Java并发容器JUC(java.util.concurrent)
- ConcurrentHashMap
- CopyOnWriteArrayList
AQS(AbstractQueuedSynchronizer)
AbstractQueuedSynchronizer (AQS)是Java并发包中的一个核心类,这个类在java.util.concurrent.locks包下面。AQS是一个用来构建锁和同步器的框架,使用AQS能简单且高效的构造出同步器,是JUC中核心的组件。抽象同步队列是JVC其他锁实现的基础
AQS实现原理
在类中维护一个
state变量,然后还维护一个队列,以及获取锁,释放锁的方法
当线程创建后,先判断state的值,如果为0,则没有线程使用,将state=1,执行完成后将state=0,期间如果有其他的线程访问,state=1的话,将其他的线程放入到队列中
state由于是多线程共享变量,所以必须定义成volatile,用来保证state的可见性,同时虽然volatile能保证可见性,但不能保证原子性,所以AQS提供了对state的原子操作方法,保证了线程安全。
AQS中实现的FIFO队列是双向链表实现的 可以通过
getState(),setState(),compareAndSetState进行操作 分别时获取锁状态,设置锁状态,使用CAS机制设置状态
AQS操作重点方法
acquire:表示一定能获取锁
tryAcquire:尝试获取锁,如果获取锁成功,那么tryAcquire(arg)为false,说明已经获取锁,不用参与排队,也就是不用再执行后续判断条件,直接返回。
addWaiter:尝试获取锁失败后,将当前线程封装到一个Node对象中,添加到队尾,并返回Node节
acquireQueued:将线程添加到队列后,以自旋的方式去获取锁
release:释放锁
tryRelease:释放锁,将state值进行修改为0
unparkSuccessor:唤醒节点的后继者(如果存在)
AQS的锁模式分为:独占和共享
独占锁:每次只能有一个线程持有锁,比如
ReentrantLock就是以独占方式实 现的互斥锁。 共 享 锁 : 允 许 多 个 线 程 同 时 获 取 锁 , 并 发 访 问 共 享 资 源 , 比 如
ReentrantReadWriteLock。
Java并发容器JUC(java.util.concurrent)
JDK提供的大部分容器都在这个包中
里面的集合主要有:
ConcurrentHashMap: 线程安全的HashMapCopyOnWriteArrayList: 线程安全的List,在读多写少的场合性能非常好,远远好于Vector。ConcurrentLinkedQueue: 高效的并发队列,使用链表实现。可以看做一个线程安全的LinkedList,这是一个非阻塞队列。BlockingQueue: 这是一个接口,JDK 内部通过链表、数组等方式实现了这个接口。表示阻塞队列,非常适合用于作为数据共享的通道。ConcurrentSkipListMap: 跳表的实现。这是一个Map,使用跳表的数据结构进行快速查找。
ConcurrentHashMap
在学习
HashMap的时候知道了HashMap不是线程安全的,如果要实现线程安全,需要使用一个全局的锁来同步不同线程间的并发访问,所以非常影响性能,所有就有了ConcurrentHashMap,无论是读还是写,都能保证很高的性能,在读操作时几乎不需要加锁,在写操作时通过锁分段技术只对所操作的的段加锁而不影响客户端对其他段的访问。
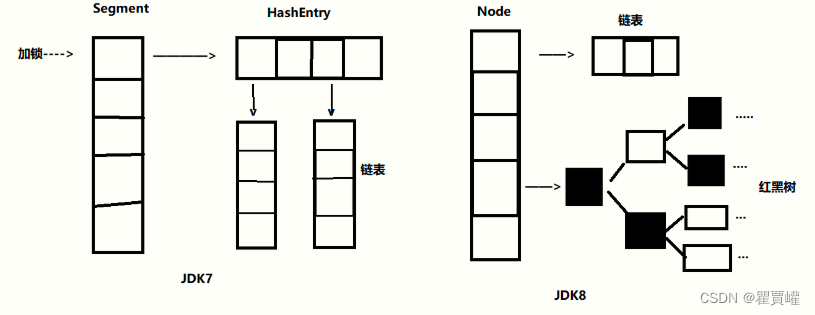
JDK8之前的的底层采用分段的数组+链表实现,JDK8之后底层数据结构和HashMap8的一样,数组+链表/红黑树。
线程安全的实现的方式是,在JDK8之前
ConcurrentHashMap对整个桶数组进行了分割(Segment,分段锁),每一把锁只锁一部分容器中的内容;在JDK8及之后放弃了Segment的理念,直接采用数组+链表/红黑树。
在JDK7及之前:
一个
ConcurrentHashMap里包含一个Segment数组,这个数组大小一旦初始化就不能改变。默认大小为16,也就是默认可以支持16个线程并发。ConcurrentHashMap是由Segment数组和HashEntry数组组成,Segment继承了ReentrantLock,所以Segment是一种可重入锁,HashEntry用于存储键值对数据。一个Segment包含一个HashEntry数组,一个HashEntry包含链表结构。每个Segment守护一个HashEntry数组里面的元素,如果要对数据并发写入会被阻塞,不同的Segment的写入可以并发执行的。
在JDK8及之后
ConcurrentHashMap取消了Segment分段锁,采用Node+CAS+Synchronized来保证安全。底层数据结构是数组+链表+红黑树。在这个版本中,Synchronized只锁定当前链表或红黑树的首节点,这样只要hash不冲突,就不会产生并发,就不会影响其他Node的读写,效率大幅提升。
ConcurrentHashMap不支持存储null键和null值,为了消除歧义 原因:无法分辨是key没找到的null还是有key值的null,在多线程里面这是模糊不清的
放弃分段锁的原因
加入多个分段锁浪费内存空间。
生产环境中, map 在放入时竞争同一个锁的概率非常小,分段锁反而会造成更新等操作的长时间等待。
因此jdk8放弃了分段锁而是用了Node锁,减低锁的粒度,提高性能,并使用CAS操作来确保Node的一些操作的原子性,取代了锁。put时首先通过哈市找到对应链表后,查看是否第一个Node,如果是,直接用CAS原则插入,无需加锁,如果不是链表第一个Node,则直接用链表第一个Node加锁,这里加的锁是synchronized
CopyOnWriteArrayList
CopyOnWriteArrayList是线程安全的列表实现类,在操作时使用了一种特殊的方式来保证线程的安全即,写时复制。
在它进行写操作时,会将原来的数据复制一份,然后在该副本上进行操作,最后将副本重新赋值给CopyOnWriteArrayList实例的成员变量。使用这种写操作可以保证读操作的并发性,因为在写操作期间,读操作仍然访问的是原始数据,不会受到写操作的影响
由于CopyOnWriteArrayList采用了大量的内存复制来保证线程安全,因此写操作的性能较低,适用于读多写少的场景。同时,CopyOnWriteArrayList也不适用于需要实时反映最新数据的场景,因为写入操作的结果需要等待写操作完成之后才能被其他线程看到。
总的来说
CopyOnWriteArrayList在读操作频繁、写操作较少、数据量不大的情况下,可以提供比较好的并发性能和线程安全性。
使用
ArrayList:线程不安全,在高并发情况下可能会出现问题
使用Vector可以解决线程安全问题,还有Collections中的synchronizedList可以解决
使用Vector效率低,原因是get()方法也加了锁,读操作多的情况下,效率低。
使用CopyOnWriteArrayList:
可以在读的时候不加锁,写的时候加锁,提高读的效率。实现过程在进行add,set等修改操作时,先将数据进行备份,对备份数据进行修改,之后将修改后的数据赋值给原数组。
源码分析
CopyOnWriteArrayList 读取操作的实现
读取操作没有任何同步控制和锁操作,理由就是内部数组array不会发生修改,只会被另外一个array替换,因此可以保证数据安全。// The array, accessed only via getArray/setArray. private transient volatile Object[] array;public E get ( int index){return get(getArray(), index);}@SuppressWarnings("unchecked")private E get (Object[]a,int index){return (E) a[index];}final Object[] getArray () {return array;}CopyOnWriteArrayList 写入操作的实现
CopyOnWriteArrayList写入操作add()方法在添加集合的时候加了锁,保证了同步,避免了多线程写的时候会copy出多个副本出来。/**Appends the specified element to the end of this list.* @param e element to be appended to this list* @return {@code true} (as specified by {@link Collection#add})*/public boolean add (E e){final ReentrantLock lock = this.lock;lock.lock();//加锁try {Object[] elements = getArray();int len = elements.length;Object[] newElements = Arrays.copyOf(elements, len + 1);//拷贝新数组newElements[len] = e;setArray(newElements);return true;} finally {lock.unlock();//释放锁}}