上一节我们学会了 Rollup 构建工具的使用,相信你已经对 Rollup 的基础概念和使用有了基本的掌握。同时我们也知道,仅仅使用 Rollup 内置的打包能力很难满足项目日益复杂的构建需求。对于一个真实的项目构建场景来说,我们还需要考虑到模块打包之外的问题,比如路径别名(alias) 、全局变量注入和代码压缩等等。
可要是把这些场景的处理逻辑与核心的打包逻辑都写到一起,一来打包器本身的代码会变得十分臃肿,二来也会对原有的核心代码产生一定的侵入性,混入很多与核心流程无关的代码,不易于后期的维护。因此 ,Rollup 设计出了一套完整的插件机制,将自身的核心逻辑与插件逻辑分离,让你能按需引入插件功能,提高了 Rollup 自身的可扩展性。
那接下来,我会带你分析 Rollup 的插件机制,熟悉 Rollup 插件的完整构建阶段和工作流程,并且结合案例深入插件开发细节。Rollup 的打包过程中,会定义一套完整的构建生命周期,从开始打包到产物输出,中途会经历一些标志性的阶段,并且在不同阶段会自动执行对应的插件钩子函数(Hook)。对 Rollup 插件来讲,最重要的部分是钩子函数,一方面它定义了插件的执行逻辑,也就是"做什么";另一方面也声明了插件的作用阶段,即"什么时候做",这与 Rollup 本身的构建生命周期息息相关。
一、Rollup构建阶段
在执行 rollup 命令之后,在 cli 内部的主要逻辑简化如下:
// Build 阶段
const bundle = await rollup.rollup(inputOptions);// Output 阶段
await Promise.all(outputOptions.map(bundle.write));// 构建结束
await bundle.close();
而Rollup 内部主要经历了 Build 和 Output 两大阶段,如下图所示。

首先,Build 阶段主要负责创建模块依赖图,初始化各个模块的 AST 以及模块之间的依赖关系。下面我们用一个简单的例子来感受一下:
// src/index.js
import { a } from './module-a';
console.log(a);// src/module-a.js
export const a = 1;
然后,执行如下的构建脚本:
const rollup = require('rollup');
const util = require('util');
async function build() {const bundle = await rollup.rollup({input: ['./src/index.js'],});console.log(util.inspect(bundle));
}
build();
执行上面的代码,可以看到如下的 bundle对象信息。
{cache: {modules: [{ast: 'AST 节点信息,具体内容省略',code: 'export const a = 1;',dependencies: [],id: '/Users/code/rollup-demo/src/data.js',// 其它属性省略},{ast: 'AST 节点信息,具体内容省略',code: "import { a } from './data';\n\nconsole.log(a);",dependencies: ['/Users/code/rollup-demo/src/data.js'],id: '/Users/code/rollup-demo/src/index.js',// 其它属性省略}],plugins: {}},closed: false,// 挂载后续阶段会执行的方法close: [AsyncFunction: close],generate: [AsyncFunction: generate],write: [AsyncFunction: write]
}
从上面的信息中可以看出,目前经过 Build 阶段的 bundle 对象其实并没有进行模块的打包,这个对象的作用在于存储各个模块的内容及依赖关系,同时暴露generate和write方法,以进入到后续的 Output 阶段。
所以,真正进行打包的过程会在 Output 阶段进行,即在bundle对象的 generate或者write方法中进行。还是以上面的 demo 为例,我们稍稍改动一下构建逻辑:
const rollup = require('rollup');
async function build() {const bundle = await rollup.rollup({input: ['./src/index.js'],});const result = await bundle.generate({format: 'es',});console.log('result:', result);
}build();
重新执行项目后可以得到如下的输出:
{output: [{exports: [],facadeModuleId: '/Users/code/rollup-demo/src/index.js',isEntry: true,isImplicitEntry: false,type: 'chunk',code: 'const a = 1;\n\nconsole.log(a);\n',dynamicImports: [],fileName: 'index.js',// 其余属性省略}]
}
这里可以看到所有的输出信息,生成的output数组即为打包完成的结果。当然,如果使用 bundle.write 会根据配置将最后的产物写入到指定的磁盘目录中。
因此,对于一次完整的构建过程而言, Rollup 会先进入到 Build 阶段,解析各模块的内容及依赖关系,然后进入Output阶段,完成打包及输出的过程。对于不同的阶段,Rollup 插件会有不同的插件工作流程,接下来我们就来拆解一下 Rollup 插件在 Build 和 Output 两个阶段的详细工作流程。
二、拆解插件工作流
2.1 插件 Hook 类型
在具体讲述 Rollup 插件工作流之前,我想先给大家介绍一下不同插件 Hook 的类型,这些类型代表了不同插件的执行特点,是我们理解 Rollup 插件工作流的基础,因此有必要跟大家好好拆解一下。
通过上文的例子,相信你可以直观地理解 Rollup 两大构建阶段(Build和Output)各自的原理。可能你会有疑问,这两个阶段到底跟插件机制有什么关系呢?实际上,插件的各种 Hook 可以根据这两个构建阶段分为两类: Build Hook 与 Output Hook。
- Build Hook:在Build阶段执行的钩子函数,在这个阶段主要进行模块代码的转换、AST 解析以及模块依赖的解析,那么这个阶段的 Hook 对于代码的操作粒度一般为模块级别,也就是单文件级别。
- Ouput Hook:(官方称为Output Generation Hook),则主要进行代码的打包,对于代码而言,操作粒度一般为 chunk级别,而一个 chunk通常指很多文件打包到一起的产物。
除了根据构建阶段可以将 Rollup 插件进行分类,根据不同的 Hook 执行方式也会有不同的分类,主要包括Async、Sync、Parallel、Squential、First这五种。在实际的开发过程中,我们将接触各种各样的插件 Hook,但无论哪个 Hook 都离不开这五种执行方式。接下来,让我们具体来认识下这五个函数钩子。
Async & Sync
首先是Async和Sync钩子函数,两者其实是相对的,分别代表异步和同步的钩子函数,两者最大的区别在于同步钩子里面不能有异步逻辑,而异步钩子可以有。
Parallel
Parallel用来代表并行钩子函数。如果有多个插件实现了这个钩子的逻辑,一旦有钩子函数是异步逻辑,则并发执行钩子函数,不会等待当前钩子完成(底层使用 Promise.all)。
比如对于Build阶段的buildStart钩子,它的执行时机其实是在构建刚开始的时候,各个插件可以在这个钩子当中做一些状态的初始化操作,但其实插件之间的操作并不是相互依赖的,也就是可以并发执行,从而提升构建性能。反之,对于需要依赖其他插件处理结果的情况就不适合用 Parallel 钩子了,比如 transform。
Sequential
Sequential 指串行的钩子函数。这种 Hook 往往适用于插件间处理结果相互依赖的情况,前一个插件 Hook 的返回值作为后续插件的入参,这种情况就需要等待前一个插件执行完 Hook,获得其执行结果,然后才能进行下一个插件相应 Hook 的调用,如transform。
First
如果有多个插件实现了这个 Hook,那么 Hook 将依次运行,直到返回一个非 null 或非 undefined 的值为止。比较典型的 Hook 是 resolveId,一旦有插件的 resolveId 返回了一个路径,将停止执行后续插件的 resolveId 逻辑。
刚刚我们介绍了 Rollup 当中不同插件 Hook 的类型,实际上不同的类型是可以叠加的,Async/Sync 可以搭配后面三种类型中的任意一种,比如一个 Hook既可以是 Async 也可以是 First 类型,接着我们来具体分析一下 Rollup 当中的插件工作流程。
2.2 Build 阶段工作流
首先,我们来分析 Build 阶段的插件工作流程。对于 Build 阶段,插件 Hook 的调用流程如下图所示。
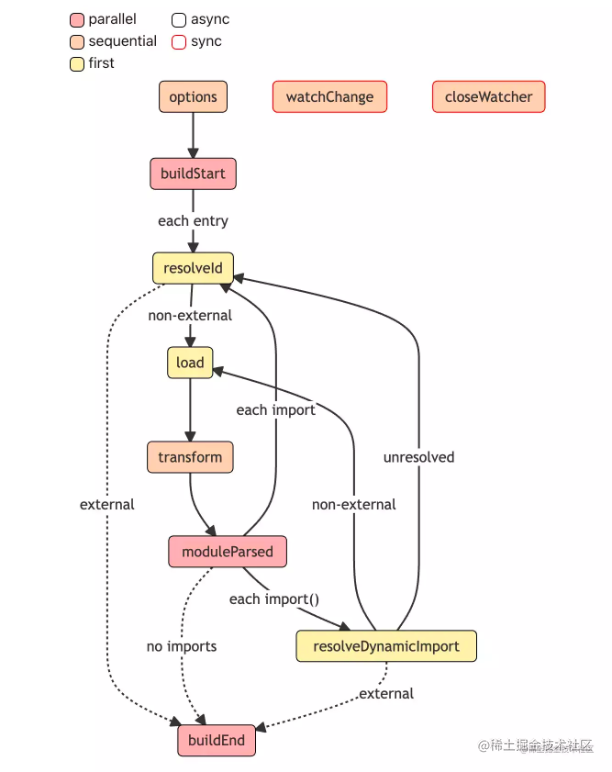
流程图的最上面声明了不同 Hook 的类型,也就是我们在上面总结的 5 种 Hook 分类,每个方块代表了一个 Hook,边框的颜色可以表示Async和Sync 类型,方块的填充颜色可以表示Parallel、Sequential 和First 类型。
接下来,我们一步步来分析 Build Hooks 的工作流程,你可以对照着图一起看。
- 首先经历 options 钩子进行配置的转换,得到处理后的配置对象。
- 随之 Rollup 会调用buildStart钩子,正式开始构建流程。
- Rollup 先进入到 resolveId 钩子中解析文件路径。(从 input 配置指定的入口文件开始)。
- Rollup 通过调用load钩子加载模块内容。
- 紧接着 Rollup 执行所有的 transform 钩子来对模块内容进行进行自定义的转换,比如 babel 转译。
- 现在 Rollup 拿到了模块内容,接下来就是进行 AST 分析,得到所有的 import 内容,调用 moduleParsed 钩子。如果是普通的 import,则执行 resolveId 钩子,继续回到步骤3;如果是动态 import,则执行 resolveDynamicImport 钩子解析路径,如果解析成功,则回到步骤4加载模块,否则回到步骤3通过 resolveId 解析路径。
- 直到所有的 import 都解析完毕,Rollup 执行buildEnd钩子,Build 阶段结束。
当然,在 Rollup 解析路径的时候,即执行resolveId或者resolveDynamicImport的时候,有些路径可能会被标记为external(翻译为排除),也就是说不参加 Rollup 打包过程,这个时候就不会进行load、transform等等后续的处理了。
在流程图最上面,不知道大家有没有注意到watchChange和closeWatcher这两个 Hook,这里其实是对应了 rollup 的watch模式。当你使用 rollup --watch 指令或者在配置文件配有watch: true的属性时,代表开启了 Rollup 的watch打包模式,这个时候 Rollup 内部会初始化一个 watcher 对象,当文件内容发生变化时,watcher 对象会自动触发watchChange钩子执行并对项目进行重新构建。在当前打包过程结束时,Rollup 会自动清除 watcher 对象调用closeWacher钩子。
2.3 Output 阶段工作流
好,接着我们来看看 Output 阶段的插件到底是如何来进行工作的。这个阶段的 Hook 相比于 Build 阶段稍微多一些,流程上也更加复杂。需要注意的是,其中会涉及的 Hook 函数比较多,可能会给你理解整个流程带来一些困扰,因此我会在 Hook 执行的阶段解释其大致的作用和意义,关于具体的使用大家可以去 Rollup 的官网自行查阅,毕竟这里的主线还是分析插件的执行流程,掺杂太多的使用细节反而不易于理解。下面我结合一张完整的插件流程图和你具体分析一下。
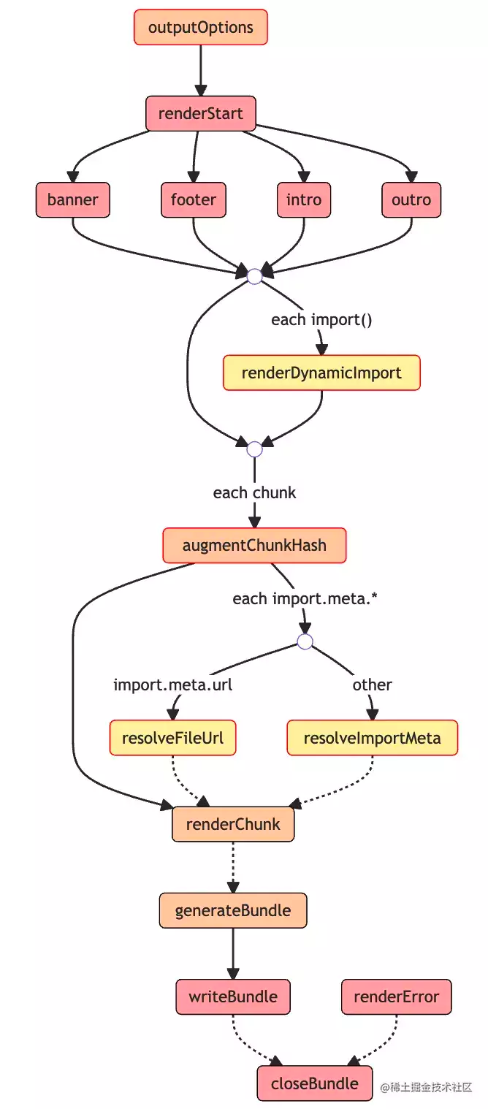
以下是关于Output 阶段工作流的说明:
- 执行所有插件的 outputOptions 钩子函数,对 output 配置进行转换。
- 执行 renderStart,并发执行 renderStart 钩子,正式开始打包。
- 并发执行所有插件的banner、footer、intro、outro 钩子(底层用 Promise.all 包裹所有的这四种钩子函数),这四个钩子功能很简单,就是往打包产物的固定位置(比如头部和尾部)插入一些自定义的内容,比如协议声明内容、项目介绍等等。
- 从入口模块开始扫描,针对动态 import 语句执行 renderDynamicImport钩子,来自定义动态 import 的内容。
- 对每个即将生成的 chunk,执行 augmentChunkHash钩子,来决定是否更改 chunk 的哈希值,在 watch 模式下即可能会多次打包的场景下,这个钩子会比较适用。
- 如果没有遇到 import.meta 语句,则进入下一步,否则执行如下的Case。对于 import.meta.url 语句调用 resolveFileUrl 来自定义 url 解析逻辑;对于其他import.meta 属性,则调用 resolveImportMeta 来进行自定义的解析。
- 接着 Rollup 会生成所有 chunk 的内容,针对每个 chunk 会依次调用插件的renderChunk方法进行自定义操作,也就是说,在这里时候可以直接操作打包产物了。
- 随后会调用 generateBundle 钩子,这个钩子的入参里面会包含所有的打包产物信息,包括 chunk (打包后的代码)、asset(最终的静态资源文件)。可以在这里删除一些 chunk 或者 asset,最终这些内容将不会作为产物输出。
- 由于rollup.rollup方法会返回一个bundle对象,这个对象是包含generate和write两个方法,两个方法唯一的区别在于后者会将代码写入到磁盘中,同时会触发writeBundle钩子,传入所有的打包产物信息,包括 chunk 和 asset,和 generateBundle钩子非常相似。不过值得注意的是,这个钩子执行的时候,产物已经输出了,而 generateBundle 执行的时候产物还并没有输出。

- 当上述的bundle的close方法被调用时,会触发closeBundle钩子,到这里 Output 阶段正式结束。
到这里,我们终于梳理完了 Rollup 当中完整的插件工作流程,从一开始在构建生命周期中对两大构建阶段的感性认识,到现在插件工作流的具体分析,不禁感叹 Rollup 看似简单,实则内部细节繁杂。
三、常用 Hook
实际上开发 Rollup 插件就是在编写一个个 Hook 函数,你可以理解为一个 Rollup 插件基本就是各种 Hook 函数的组合。
1,路径解析: resolveId
resolveId 钩子一般用来解析模块路径,为Async + First类型即异步优先的钩子。这里我们拿官方的 alias 插件 来说明,这个插件用法演示如下:
// rollup.config.js
import alias from '@rollup/plugin-alias';
module.exports = {input: 'src/index.js',output: {dir: 'output',format: 'cjs'},plugins: [alias({entries: [// 将把 import xxx from 'module-a' // 转换为 import xxx from './module-a'{ find: 'module-a', replacement: './module-a.js' },]})]
};
插件的代码简化后如下:
export default alias(options) {// 获取 entries 配置const entries = getEntries(options);return {// 传入三个参数,当前模块路径、引用当前模块的模块路径、其余参数resolveId(importee, importer, resolveOptions) {// 先检查能不能匹配别名规则const matchedEntry = entries.find((entry) => matches(entry.find, importee));// 如果不能匹配替换规则,或者当前模块是入口模块,则不会继续后面的别名替换流程if (!matchedEntry || !importerId) {// return null 后,当前的模块路径会交给下一个插件处理return null;}// 正式替换路径const updatedId = normalizeId(importee.replace(matchedEntry.find, matchedEntry.replacement));// 每个插件执行时都会绑定一个上下文对象作为 this// 这里的 this.resolve 会执行所有插件(除当前插件外)的 resolveId 钩子return this.resolve(updatedId,importer,Object.assign({ skipSelf: true }, resolveOptions)).then((resolved) => {// 替换后的路径即 updateId 会经过别的插件进行处理let finalResult: PartialResolvedId | null = resolved;if (!finalResult) {// 如果其它插件没有处理这个路径,则直接返回 updateIdfinalResult = { id: updatedId };}return finalResult;});}}
}
从这里你可以看到 resolveId 钩子函数的一些常用使用方式,它的入参分别是当前模块路径、引用当前模块的模块路径、解析参数,返回值可以是 null、string 或者一个对象,下面我们分情况讨论一下。
- 返回值为 null 时,会默认交给下一个插件的 resolveId 钩子处理。
- 返回值为 string 时,则停止后续插件的处理。这里为了让替换后的路径能被其他插件处理,特意调用了 this.resolve 来交给其它插件处理,否则将不会进入到其它插件的处理。
- 返回值为一个对象,也会停止后续插件的处理,不过这个对象就可以包含更多的信息了,包括解析后的路径、是否被 enternal、是否需要 tree-shaking 等等,不过大部分情况下返回一个 string 就够用了。
2,load
load 为Async + First类型,即异步优先的钩子,和resolveId类似。它的作用是通过 resolveId 解析后的路径来加载模块内容。这里,我们以官方的 image 插件 为例来介绍一下 load 钩子的使用。源码简化后如下所示:
const mimeTypes = {'.jpg': 'image/jpeg',// 后面图片类型省略
};export default function image(opts = {}) {const options = Object.assign({}, defaults, opts);return {name: 'image',load(id) {const mime = mimeTypes[extname(id)];if (!mime) {// 如果不是图片类型,返回 null,交给下一个插件处理return null;}// 加载图片具体内容const isSvg = mime === mimeTypes['.svg'];const format = isSvg ? 'utf-8' : 'base64';const source = readFileSync(id, format).replace(/[\r\n]+/gm, '');const dataUri = getDataUri({ format, isSvg, mime, source });const code = options.dom ? domTemplate({ dataUri }) : constTemplate({ dataUri });return code.trim();}};
}
从中可以看到,load 钩子的入参是模块 id,返回值一般是 null、string 或者一个对象:
- 如果返回值为 null,则交给下一个插件处理;
- 如果返回值为 string 或者对象,则终止后续插件的处理,如果是对象可以包含 SourceMap、AST 等。
3,代码转换: transform
transform 钩子也是非常常见的一个钩子函数,为Async + Sequential类型,也就是异步串行钩子,作用是对加载后的模块内容进行自定义的转换。我们以官方的 replace 插件为例,这个插件的使用方式如下:
// rollup.config.js
import replace from '@rollup/plugin-replace';module.exports = {input: 'src/index.js',output: {dir: 'output',format: 'cjs'},plugins: [// 将会把代码中所有的 __TEST__ 替换为 1replace({__TEST__: 1})]
};
事实上,transform的内部实现也并不是很复杂,主要通过字符串替换来实现,核心逻辑简化如下:
import MagicString from 'magic-string';export default function replace(options = {}) {return {name: 'replace',transform(code, id) {// 省略一些边界情况的处理// 执行代码替换的逻辑,并生成最后的代码和 SourceMapreturn executeReplacement(code, id);}}
}function executeReplacement(code, id) {const magicString = new MagicString(code);// 通过 magicString.overwrite 方法实现字符串替换if (!codeHasReplacements(code, id, magicString)) {return null;}const result = { code: magicString.toString() };if (isSourceMapEnabled()) {result.map = magicString.generateMap({ hires: true });}// 返回一个带有 code 和 map 属性的对象return result;
}
transform 钩子的入参分别为模块代码、模块 ID,返回一个包含 code(代码内容) 和 map(SourceMap 内容) 属性的对象,当然也可以返回 null 来跳过当前插件的 transform 处理。需要注意的是,当前插件返回的代码会作为下一个插件 transform 钩子的第一个入参,实现类似于瀑布流的处理。
4,Chunk 级代码修改: renderChunk
这里我们继续以 replace插件举例,在这个插件中,也同样实现了 renderChunk 钩子函数:
export default function replace(options = {}) {return {name: 'replace',transform(code, id) {// transform 代码省略},renderChunk(code, chunk) {const id = chunk.fileName;// 省略一些边界情况的处理// 拿到 chunk 的代码及文件名,执行替换逻辑return executeReplacement(code, id);},}
}
可以看到这里 replace 插件为了替换结果更加准确,在 renderChunk 钩子中又进行了一次替换,因为后续的插件仍然可能在 transform 中进行模块内容转换,进而可能出现符合替换规则的字符串。
这里我们把关注点放到 renderChunk 函数本身,可以看到有两个入参,分别为 chunk 代码内容、chunk 元信息,返回值跟 transform 钩子类似,既可以返回包含 code 和 map 属性的对象,也可以通过返回 null 来跳过当前钩子的处理。
5,generateBundle
generateBundle 也是异步串行的钩子,你可以在这个钩子里面自定义删除一些无用的 chunk 或者静态资源,或者自己添加一些文件。这里我们以 Rollup 官方的html插件来具体说明,这个插件的作用是通过拿到 Rollup 打包后的资源来生成包含这些资源的 HTML 文件,源码简化后如下所示:
export default function html(opts: RollupHtmlOptions = {}): Plugin {// 初始化配置return {name: 'html',async generateBundle(output: NormalizedOutputOptions, bundle: OutputBundle) {// 省略一些边界情况的处理// 1. 获取打包后的文件const files = getFiles(bundle);// 2. 组装 HTML,插入相应 meta、link 和 script 标签const source = await template({ attributes, bundle, files, meta, publicPath, title});// 3. 通过上下文对象的 emitFile 方法,输出 html 文件const htmlFile: EmittedAsset = {type: 'asset',source,name: 'Rollup HTML Asset',fileName};this.emitFile(htmlFile);}}
}
相信从插件的具体实现中,你也能感受到这个钩子的强大作用了。入参分别为output 配置、所有打包产物的元信息对象,通过操作元信息对象你可以删除一些不需要的 chunk 或者静态资源,也可以通过 插件上下文对象的emitFile方法输出自定义文件。
好,常用的 Rollup 钩子我们就先介绍到这里,相信这些知识点已经足够你应付大多数的构建场景了。顺便说一句,大家在后面的章节可以了解到,Vite 的插件机制也是基于 Rollup 来实现的,像上面介绍的这些常用钩子在 Vite 当中也随处可见,因此,掌握了这些常用钩子,也相当于给 Vite 插件的学习做下了很好的铺垫。