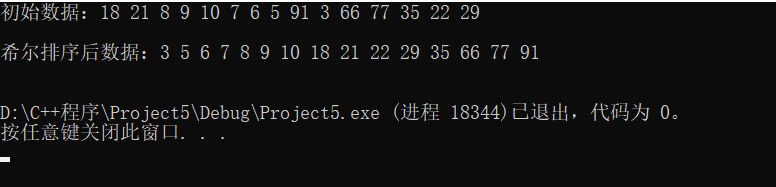
希尔排序:
希尔排序(Shell Sort,又称缩小增量法)是一种分组插入排序方法。
排序思想:
① 先取一个正整数d1(d1<n)作为第一个增量,将全部n个记录分成d1组,把所有相隔d1的记录放在一组中,即对于每个k(k=1, 2, … d1),R[k], R[d1+k], R[2d1+k] , …分在同一组中,在各组内进行直接插入排序。这样一次分组和排序过程称为一趟希尔排序;
② 取新的增量d2<d1,重复①的分组和排序操作;直至所取的增量di=1为止,即所有记录放进一个组中排序为止。
注意: 一般第一次去元素个数的一半,然后以后的每一次都取上一次的一半。
说明: 算法最后一趟对所有数据进行了直接插入排序,所以结果一定是正确的。
图示排序过程说明:

注意: 对于d=1的一趟,排序前的数据已将近正序!
说明: 一开始取d=5(取的元素个数的一半),然后以后的每一次取得的都是上一次的一半
说明: 比如说,上面的d=5的时候,以初始序列为例,9、4一组,8、3一组,7、2一组,6、1一组,5、0一组。;;;;;;再比如,当d=2的时候,以初始序列为例,9、7、5、3、1为一组,8、6、4、2、0为一组。

先给出一趟希尔排序的算法,类似直接插入排序。
void shell_pass(Sqlist *L, int d)/* 对顺序表L进行一趟希尔排序, 增量为d */{ int i, j ;for (i=d+1; i<=L->length; i++){ L->R[0]=L->R[i] ; /* 设置监视哨兵 */j=i-d ;while (j>0&<(L->R[0].key, L->R[j].key) ){ L->R[j+d]=L->R[j] ; j=j-d ; }L->R[j+d]=L->R[0] ;}}void straight_insert_sort(Sqlist *L){ int i, j ;for (i=2; i<=L->length; i++){ L->R[0]=L->R[i]; j=i-1; /* 设置哨兵 */while( LT(L->R[0].key, L->R[j].key) ){ L->R[j+1]=L->R[j];j--;} /* 查找插入位置 */L->R[j+1]=L->R[0]; /* 插入到相应位置 */}
}然后在根据增量数组dk进行希尔排序。
void shell_sort(Sqlist *L, int dk[], int t)/* 按增量序列dk[0 … t-1],对顺序表L进行希尔排序 */{ int m ;for (m=0; m<=t; m++)shll_pass(L, dk[m]) ;}
希尔排序可提高排序速度,原因是:
◆ 分组后n值减小,n²更小,而T(n)=O(n²),所以T(n)从总体上看是减小了;
◆ 关键字较小的记录跳跃式前移,在进行最后一趟增量为1的插入排序时,序列已基本有序。
希尔排序的时间复杂度约为O(n1.3)。